?YOLOv5
yolov5專案地址
https://github.com/ultralytics/yolov5
yolov5漢化版專案地址
https://github.com/wudashuo/yolov5

?實驗環境介紹
yolov5-3.1相關requirements
CPU:i5-8300H
GPU:GTX1060
?TACO資料集
資料集介紹
TACO專案地址
https://github.com/pedropro/TACO
TACO是野外廢物的不斷增長的影像資料集,它包含在不同環境下拍攝的垃圾的影像:樹林,道路和海灘,這些影像根據分層分類法進行手動標記和分段,以訓練和評估物件檢測演算法,當前,影像托管在Flickr上,我們有一個服務器正在收集更多影像和批注@ tacodataset.org

為方便起見,注釋以COCO格式提供,在此處檢查元資料:http : //cocodataset.org/#format-data
TACO仍然相對較小,但仍在增長,敬請關注!
資料集下載
Github下載
TACO專案地址
專案地址[4]下載
https://momodel.cn/explore/5f0e734c95faedbb53ab3b26?type=app
Baidu AI Studio優質資料集征集 下載
http://ai.baidu.com/forum/topic/show/959190
往下拉可以找到TACO資料集
資料集鏈接:https://aistudio.baidu.com/aistudio/datasetdetail/71124
!非官方發布不確保資料可靠性與純凈性
?資料集格式轉換
由于TACO提供的標簽為coco格式(所有資訊存放在annotations.json檔案中),專案首先需要將相關標簽轉換為yolo格式
pycocotools安裝
先要安裝pycocotools
直接pip安裝會缺少VC環境

參考以下鏈接安裝VC環境
https://blog.csdn.net/qq_37705280/article/details/111053515
之后在conda環境中
pip install pycocotools
coco格式資料集轉換yolo格式
對于TACO資料集的處理主要可分為以下兩個程序:
(1)由于TACO提供的標簽為coco型別(所有資訊存放在annotations.json檔案中),專案首先需要將相關標簽轉換為yolo型別,與此同時,考慮到本文僅對相關網路模型進行初探和個人硬體設備的欠缺,該專案僅挑選出滿足要求的垃圾物件進行相關實驗,上述操作的相關代碼可以參考以下博客提供的代碼進行修改,該代碼可以作為模板用于滿足自定義化coco格式轉yolo格式需求,
https://www.jianshu.com/p/8ddd8f3fdf73
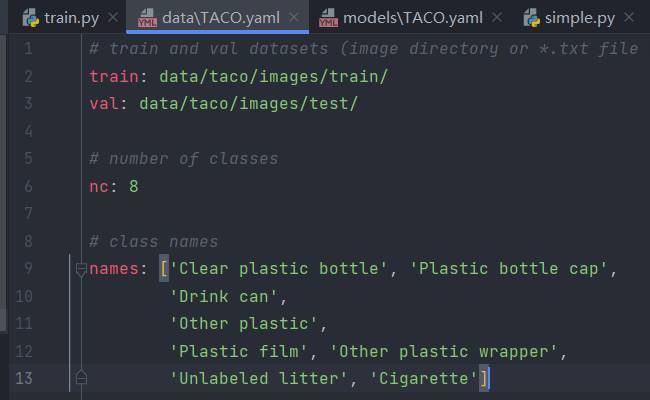
經初步統計,符合要求的垃圾型別(共8類)及其原編號如下所示:
'Clear plastic bottle': 5
'Plastic bottle cap': 7
'Drink can': 12
'Other plastic': 29
'Plastic film': 36
'Other plastic wrapper': 39
'Unlabeled litter': 58
'Cigarette': 59
中文版:
透明塑料瓶:5
塑料瓶蓋:7
飲料罐:12
其他塑料:29
塑料薄膜:36
其他塑料包裝:39
無標簽垃圾:58
香煙:59
對于coco格式轉yolo格式需求,其主要需完成以下三項任務:
- 存盤生成的標簽和影像分別至兩個檔案目錄中,同時標簽和影像的檔案命名要求一致
- 將目標物件原標簽集合遞增順序映射至{0-7}空間
- 由于原始標簽中位置資訊為
{top_x, top_y, width, height},專案需要將其轉換為{center_x, center_y, width, height}格式,并將其數值進行歸一化操作
參考專案地址[4]中的cocotoyolo.py
直接把cocotoyolo.py放在GitHub上下載的dataset根目錄下運行
自動完成資料集格式轉換與圖片重命名
并且放在分別放在images labels目錄下

驗證資料集格式轉換是否成功
coco格式轉換為yolo格式后可根據專案地址[4]中的transfertest.py查看是否轉換成功
測驗情況如下
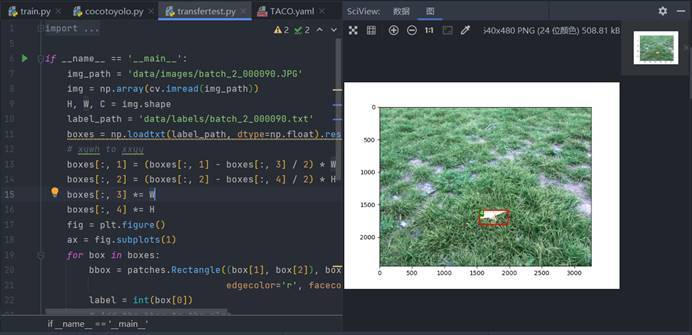
轉換成功
?樣本劃分
此前訓練都是參考YOLOv5 實作目標檢測(訓練自己的資料集實作貓貓識別)
其中用來分train、val、test的makeTxt.py是針對xml檔案的
而這次的資料集是coco格式的 轉換為yolo格式后為txt
此次train與test分類參考專案地址[4]中的sample.py
修改引數如下
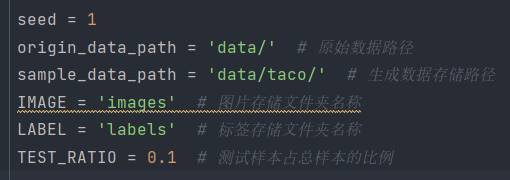
data/images存放了所有訓練圖片
data/labels存放了所有label
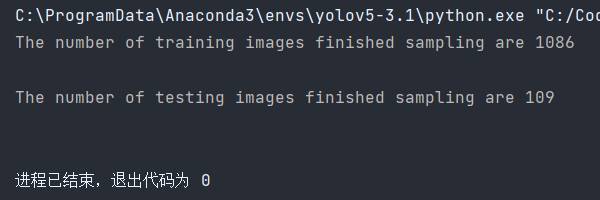
生成的后的train與test存放在data/taco下

?訓練引數配置
其余配置如下
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# --weights(?)指定權重,如果不加此引數會默認使用COCO預訓的yolov5s.pt,--weights''則會隨機初始化權重
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
# --cfg 指定模型檔案
parser.add_argument('--cfg', type=str, default='models/TACO.yaml', help='model.yaml path')
# parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
# --data(?)指定資料檔案
parser.add_argument('--data', type=str, default='data/TACO.yaml', help='data.yaml path')
# --hyp 指定超引數檔案
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
# --epochs(?)指定epoch數,默認300
parser.add_argument('--epochs', type=int, default=300)
# --batch-size(?)指定batch大小,默認16,官方推薦越大越好,用你GPU能承受最大的batch size,可簡寫為 --batch
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs')
# --img-size 指定訓練圖片大小,默認640,可簡寫為 --img
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
# --name 指定結果檔案名,默認result.txt
# --name 訓練結果存放名,默認exp
parser.add_argument('--name', default='', help='renames experiment folder exp{N} to exp{N}_{name} if supplied')
# --device 指定訓練設備,如 --device 0, 1, 2, 3
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
# --local_rank 分布式訓練引數,不要自己修改!
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--logdir', type=str, default='runs/', help='logging directory')
# --workers 指定dataloader的workers數量,默認8
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
opt = parser.parse_args()
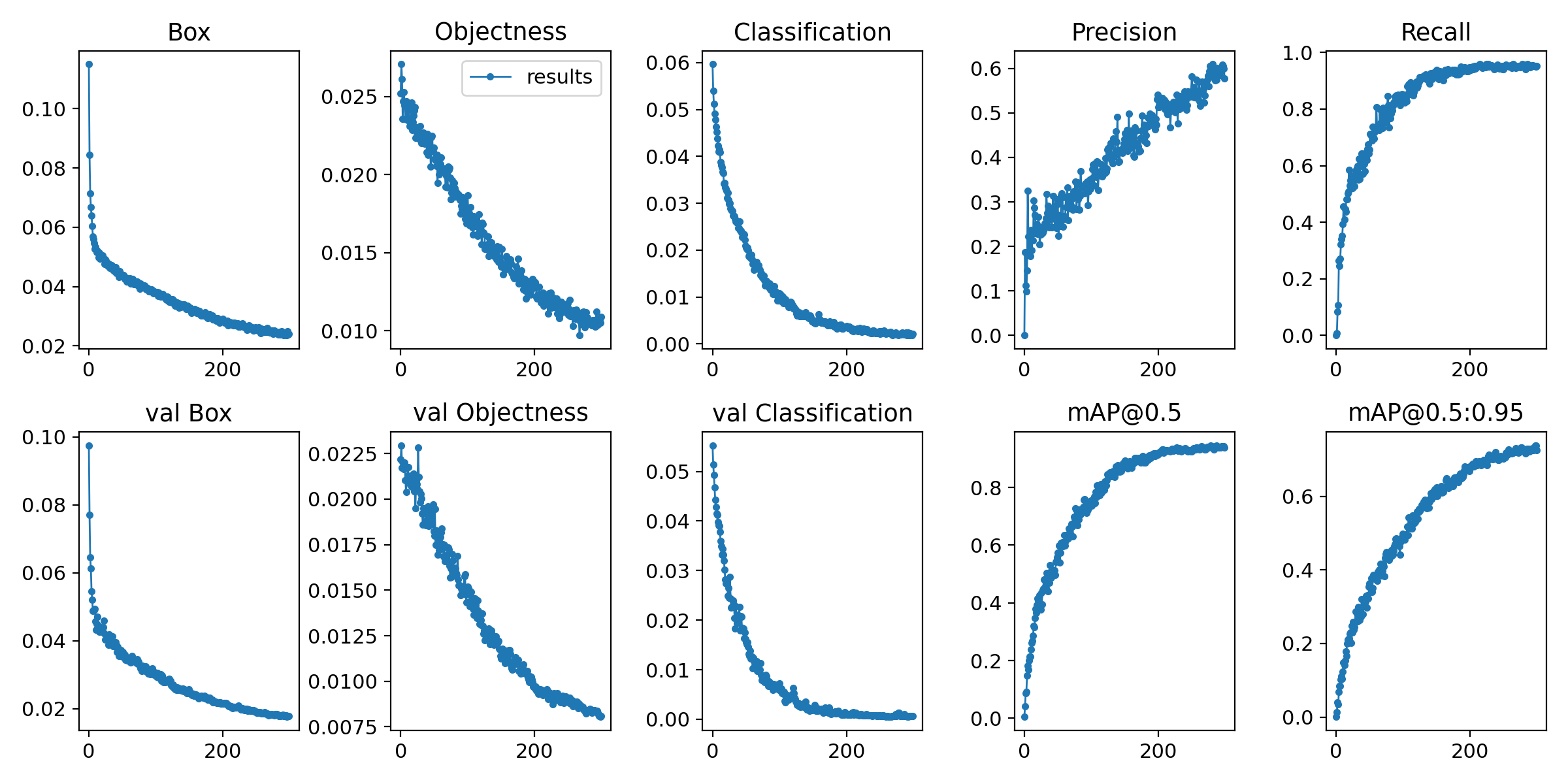
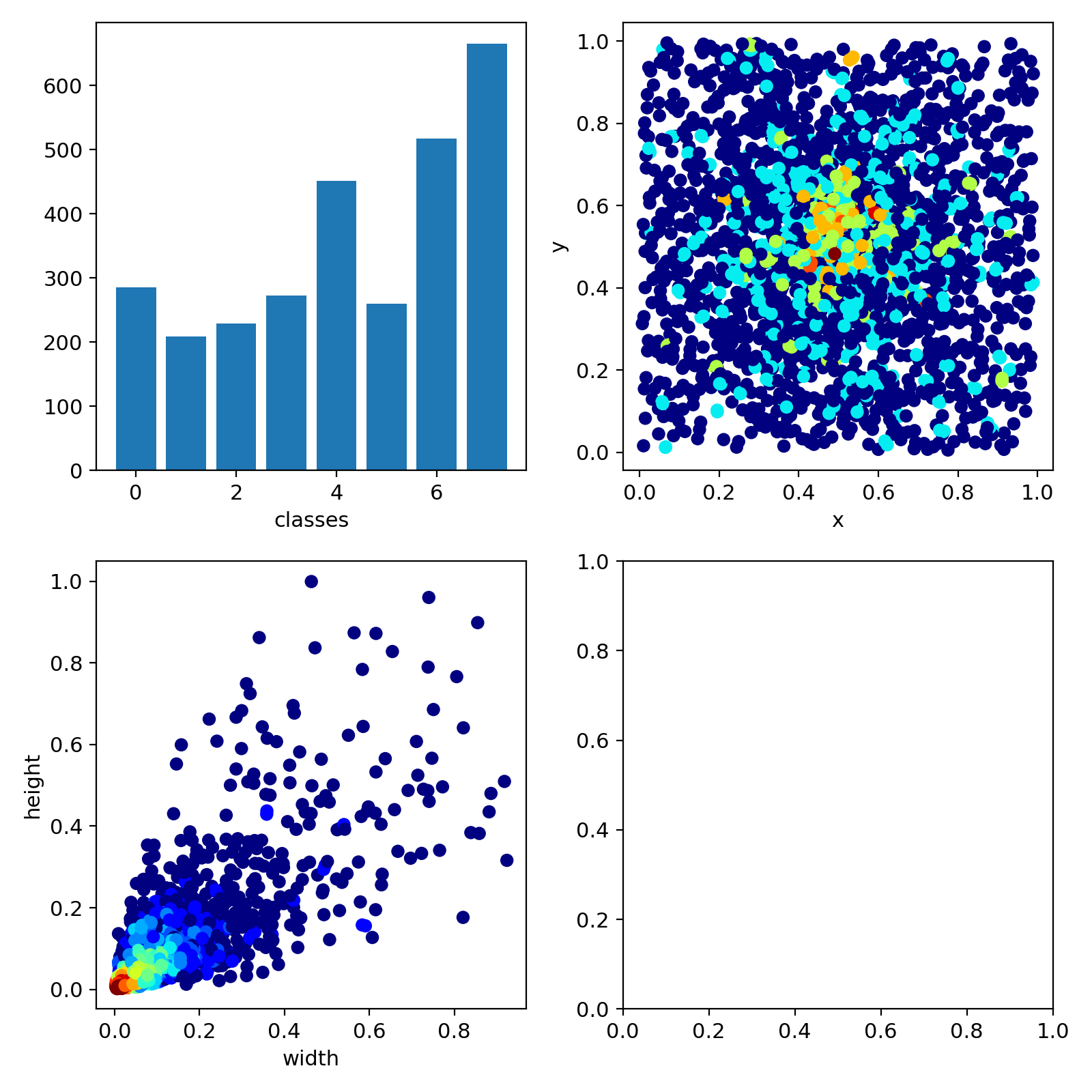
?訓練結果
迭代300次后結果如下圖
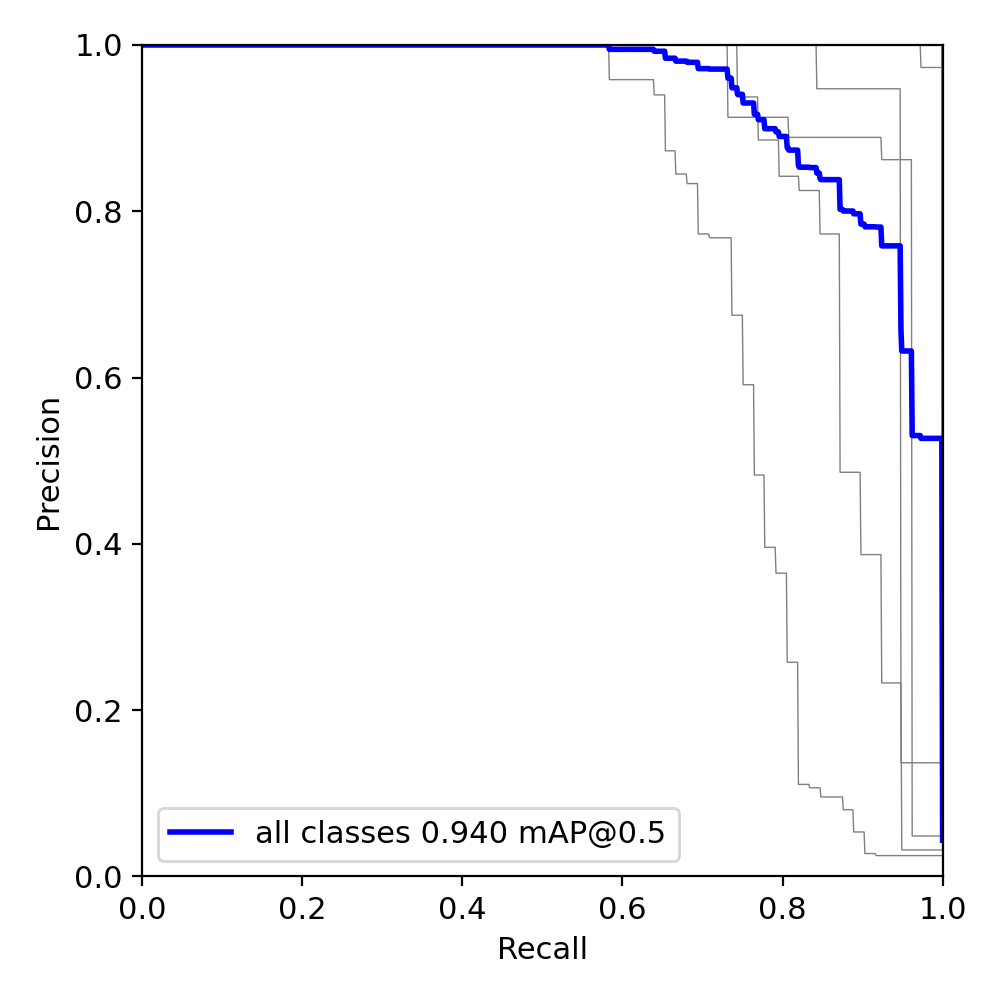
?檢測結果
選取部分訓練圖片放入inference/images目錄下
修改yolov5專案中detect.py部分引數
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 選用訓練的權重,可用根目錄下的yolov5s.pt,也可用runs/train/exp/weights/best.pt
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp0/weights/best.pt', help='model.pt path(s)')
# 檢測資料,可以是圖片/視頻路徑,也可以是'0'(電腦自帶攝像頭),也可以是rtsp等視頻流
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
# 網路輸入圖片大小
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
# 置信度閾值,檢測到的物件屬于特定類(狗,貓,香蕉,汽車等)的概率
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
# 做nms的iou閾值
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
# 檢測的設備,cpu;0(表示一個gpu設備cuda:0);0,1,2,3(多個gpu設備),值為空時,訓練時默認使用計算機自帶的顯卡或CPU
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 是否展示檢測之后的圖片/視頻,默認False
parser.add_argument('--view-img', action='store_true', help='display results')
# 是否將檢測的框坐標以txt檔案形式保存,默認False
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
# 是否將檢測的labels以txt檔案形式保存,默認False
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
# CSDN上的代碼少了這個引數會報錯
# AttributeError: 'Namespace' object has no attribute 'save_dir'
parser.add_argument('--save-dir', type=str, default='inference/output', help='directory to save results')
# 設定只保留某一部分類別,如0或者0 2 3
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
# 進行nms是否也去除不同類別之間的框,默認False
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
# 推理的時候進行多尺度,翻轉等操作(TTA)推理
parser.add_argument('--augment', action='store_true', help='augmented inference')
# 如果為True,則對所有模型進行strip_optimizer操作,去除pt檔案中的優化器等資訊,默認為False
parser.add_argument('--update', action='store_true', help='update all models')
# 檢測結果所存放的路徑,默認為runs/detect
# parser.add_argument('--project', default='runs/detect', help='save results to project/name')
# 檢測結果所在檔案夾的名稱,默認為exp
# parser.add_argument('--name', default='exp', help='save results to project/name')
# 若現有的project/name存在,則不進行遞增
# parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()

output如下





后續測驗其他真實外景garbage照片
?參考及參考
[1] https://www.jianshu.com/p/76813ecfbb88
[2] https://www.jianshu.com/p/8ddd8f3fdf73
[3] https://blog.csdn.net/qq_37705280/article/details/111053515
[4] https://blog.csdn.net/oJiWuXuan/article/details/107558286
?專案地址匯總
yolov5
[1] https://github.com/ultralytics/yolov5
yolov5漢化版
[2] https://github.com/wudashuo/yolov5
TACO
[3] https://github.com/pedropro/TACO
開源的目標檢測框架YOLOv5初探:用于垃圾物件的目標檢測
[4] https://momodel.cn/explore/5f0e734c95faedbb53ab3b26?type=app
?轉載請注明出處
本文作者:雙份濃縮馥芮白
原文鏈接:https://www.cnblogs.com/Flat-White/p/14671718.html
著作權所有,如需轉載請注明出處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/277627.html
標籤:其他
上一篇:hello world!goodbye world~
下一篇:面試現場,斬獲大廠offer