文章目錄
- 首先介紹跟蹤:
- 淺析 SORT
- SORT 部分原理:
- SORT 代碼實作+解讀:
- DeepSORT 深入解讀
- IOU 匹配流程圖
- yolo 的總體思想歸納:
- YOLO V5 使用 GIOU Loss 作為 bounding box 的損失,
- 2:資料標注與預處理
- 為什么要使用預訓練模型?
- 檢測:
- 全部代碼介紹
- 總結
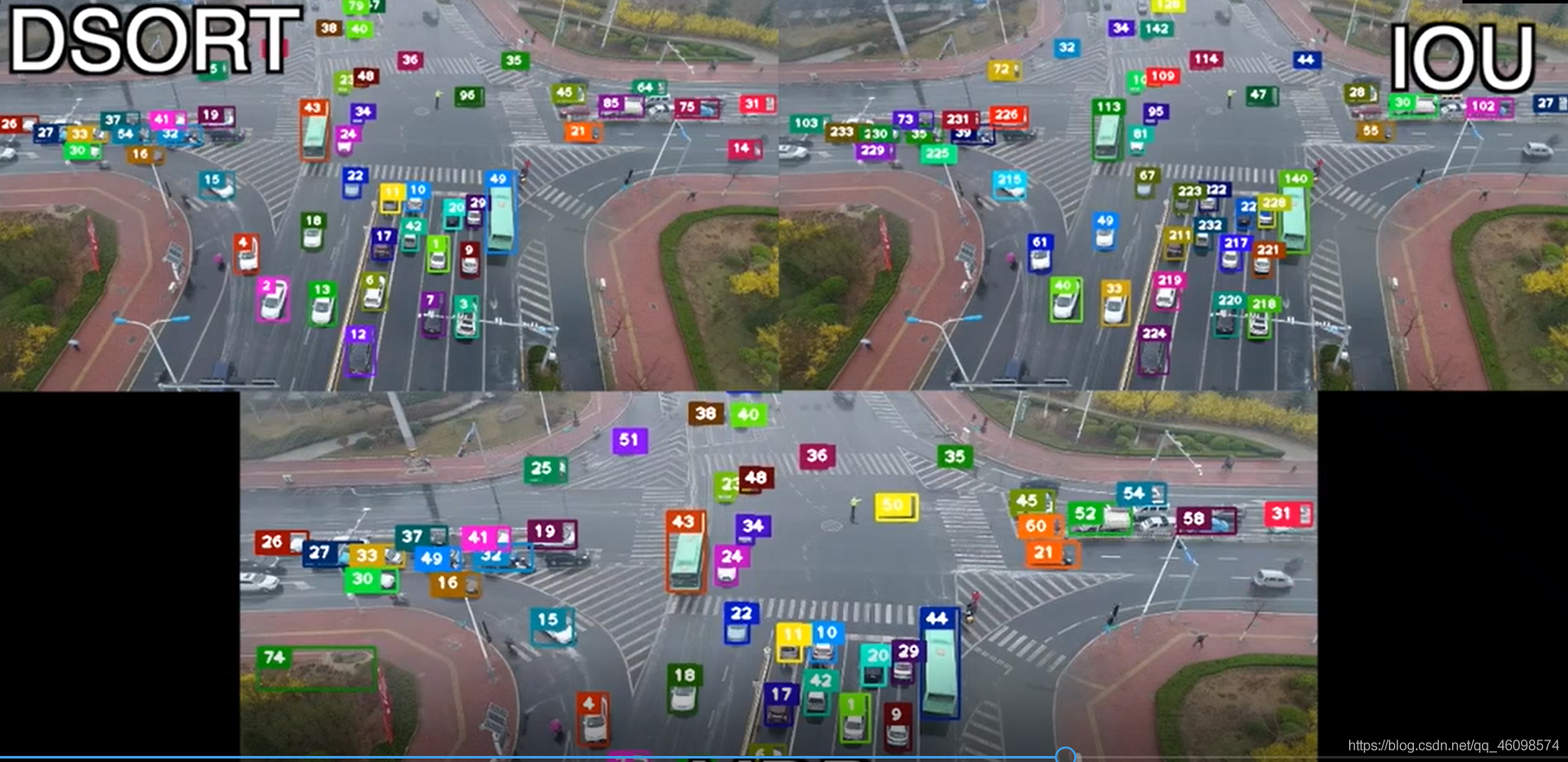

首先介紹跟蹤:
目標跟蹤又分為單目標跟蹤和多目標跟蹤
單目標跟蹤在視頻的初始幀畫面上框出單個目標,預測后續幀中該目標的大小與位置,典型演算法有 Mean shift(用卡爾曼濾波、粒子濾波進行狀態預測)、TLD(基于在線學習的跟蹤)、KCF(基于相關性濾波)等,
像 Opencv 等庫內置了許多跟蹤演算法,KCF 是一種很經典的單目標跟蹤演算法,速度不是很快,但是精度不錯,但是他也
多目標追蹤不像單目標追蹤一樣先在初始幀上框出單個目標,而是追蹤多個目標的大小和位置,且每一幀中目標的數量和位置都可能變化,此外,多目標的追蹤中還存在下列問題:
處理新目標的出現和老目標的消失;
跟蹤目標的運動預測和相似度判別,即上一幀與下一幀目標的匹配;
跟蹤目標之間的重疊和遮擋處理;
跟蹤目標丟失一段時間后再重新出現的再識別,
針對這樣的情況,有哪些解決方法呢?下面來綜合敘述,
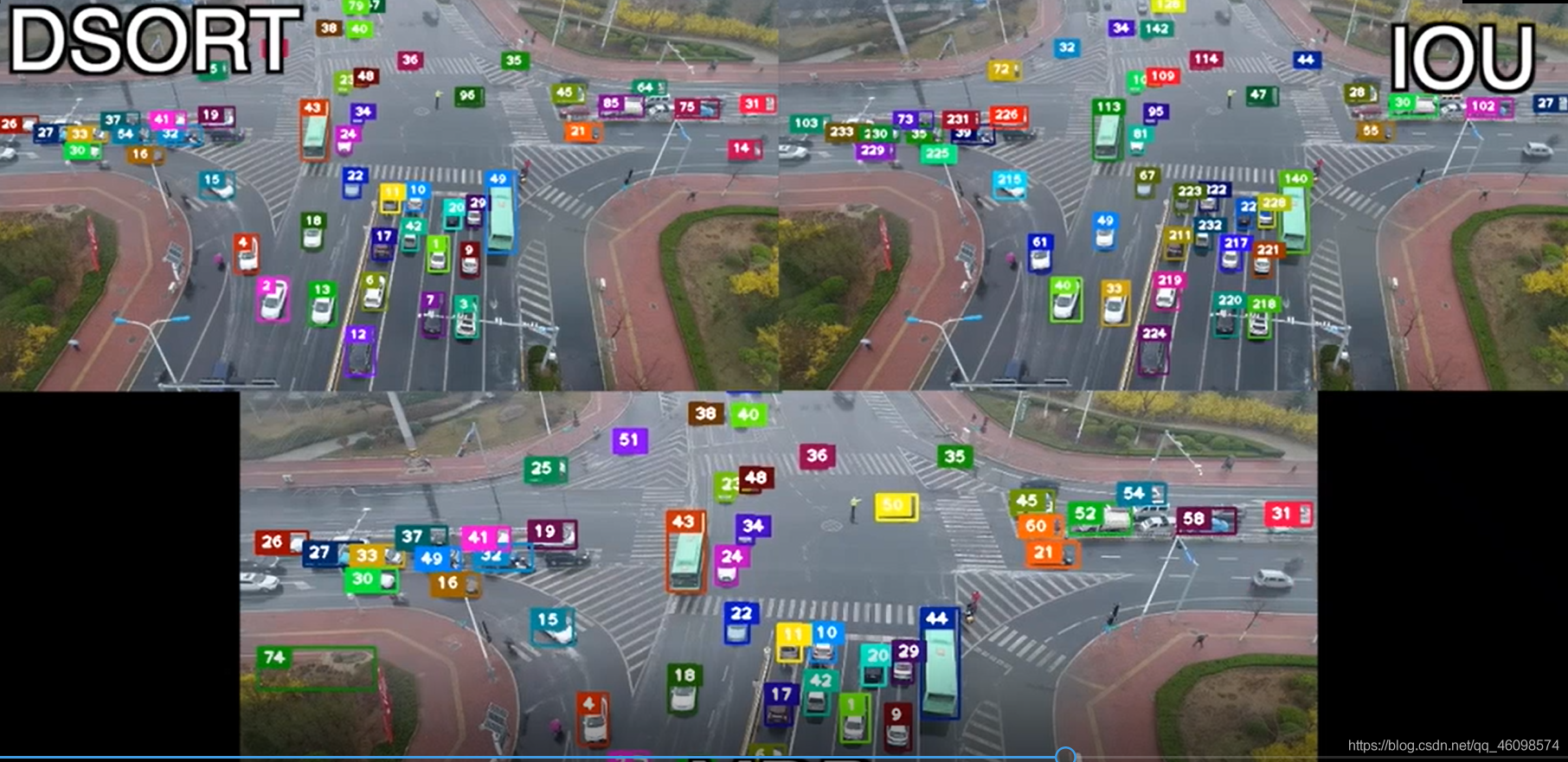
淺析 SORT
SORT 部分原理:
在跟蹤之前,對所有目標已經完成檢測,實作了特征建模程序,1 第一幀進來時,以檢測到的目標初始化并創建新的跟蹤器,標注 id,2 后面幀進來時,先到卡爾曼濾波器中得到由前面幀 box 產生的狀態預測和協方差預測,求跟蹤器所有目標狀態預測與本幀檢測的 box 的 IOU,通過匈牙利指派演算法得到 IOU 最大的唯一匹配(資料關聯部分),再去掉匹配值小于 iou_threshold 的匹配對,3 用本幀中匹配到的目標檢測 box 去更新卡爾曼跟蹤器,計算卡爾曼增益、狀態更新和協方差更新,并將狀態更新值輸出,作為本幀的跟蹤 box,對于本幀中沒有匹配到的目標重新初始化跟蹤器,
其中,卡爾曼跟蹤器聯合了歷史跟蹤記錄,調節歷史 box 與本幀 box 的殘差,更好的匹配跟蹤 id,
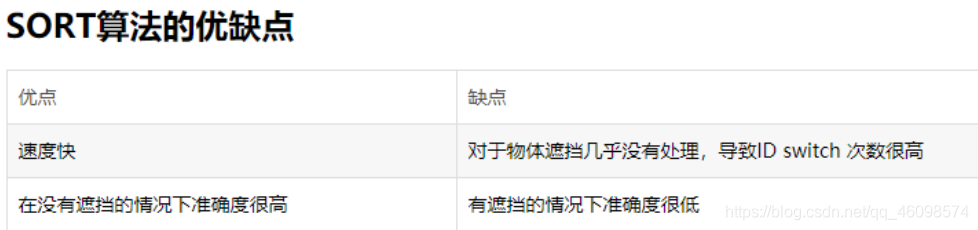
SORT 的貢獻主要有三:
利用強大的 CNN 檢測器的檢測結果來進行多目標跟蹤
使用基于卡爾曼濾波(Kalman filter)與匈牙利演算法(Hungarian algorithm)的方法來進行跟蹤
開源了代碼,為 MOT 領域提供一個新的 baseline
SORT 將這種二階段匹配演算法改進為了一階段方法,并且可以在線跟蹤,
具體而言,SORT 引入了線性速度模型與卡爾曼濾波來進行位置預測,在無合適匹配檢測框的情況下,使用運動模型來預測物體的位置,
SORT 代碼實作+解讀:
from __future__ import print_function
from numba import jit #是python的一個JIT庫,通過裝飾器來實作運行時的加速
import os.path
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches #用于繪制常見影像(如矩形,橢圓,圓形,多邊形)
from skimage import io
from sklearn.utils.linear_assignment_ import linear_assignment
import glob
import time
import argparse
from filterpy.kalman import KalmanFilter #filterpy包含了一些常用濾波器的庫
@jit #用了jit裝飾器,可加速for回圈的計算
def iou(bb_test,bb_gt):
"""
Computes IOU between two bboxes in the form [x1,y1,x2,y2]
"""
xx1 = np.maximum(bb_test[0], bb_gt[0])
yy1 = np.maximum(bb_test[1], bb_gt[1])
xx2 = np.minimum(bb_test[2], bb_gt[2])
yy2 = np.minimum(bb_test[3], bb_gt[3])
w = np.maximum(0., xx2 - xx1)
h = np.maximum(0., yy2 - yy1)
wh = w * h
o = wh / ((bb_test[2]-bb_test[0])*(bb_test[3]-bb_test[1]) #IOU=(bb_test和bb_gt框相交部分面積)/(bb_test框面積+bb_gt框面積 - 兩者相交面積)
+ (bb_gt[2]-bb_gt[0])*(bb_gt[3]-bb_gt[1]) - wh)
return(o)
def convert_bbox_to_z(bbox): #將bbox由[x1,y1,x2,y2]形式轉為 [框中心點x,框中心點y,框面積s,寬高比例r]^T
"""
Takes a bounding box in the form [x1,y1,x2,y2] and returns z in the form
[x,y,s,r] where x,y is the centre of the box and s is the scale/area and r is
the aspect ratio
"""
w = bbox[2]-bbox[0]
h = bbox[3]-bbox[1]
x = bbox[0]+w/2.
y = bbox[1]+h/2.
s = w*h #scale is just area
r = w/float(h)
return np.array([x,y,s,r]).reshape((4,1)) #將陣列轉為4行一列形式,即[x,y,s,r]^T
def convert_x_to_bbox(x,score=None): #將[x,y,s,r]形式的bbox,轉為[x1,y1,x2,y2]形式
"""
Takes a bounding box in the centre form [x,y,s,r] and returns it in the form
[x1,y1,x2,y2] where x1,y1 is the top left and x2,y2 is the bottom right
"""
w = np.sqrt(x[2]*x[3]) #w=sqrt(w*h * w/h)
h = x[2]/w #h=w*h/w
if(score==None): #如果檢測框不帶置信度
return np.array([x[0]-w/2.,x[1]-h/2.,x[0]+w/2.,x[1]+h/2.]).reshape((1,4)) #回傳[x1,y1,x2,y2]
else: #如果加測框帶置信度
return np.array([x[0]-w/2.,x[1]-h/2.,x[0]+w/2.,x[1]+h/2.,score]).reshape((1,5)) #回傳[x1,y1,x2,y2,score]
class KalmanBoxTracker(object):
"""
This class represents the internel state of individual tracked objects observed as bbox.
"""
count = 0
def __init__(self,bbox):
"""
Initialises a tracker using initial bounding box. 使用初始邊界框初始化跟蹤器
"""
#define constant velocity model #定義勻速模型
self.kf = KalmanFilter(dim_x=7, dim_z=4) #狀態變數是7維, 觀測值是4維的,按照需要的維度構建目標
self.kf.F = np.array([[1,0,0,0,1,0,0],[0,1,0,0,0,1,0],[0,0,1,0,0,0,1],[0,0,0,1,0,0,0],[0,0,0,0,1,0,0],[0,0,0,0,0,1,0],[0,0,0,0,0,0,1]])
self.kf.H = np.array([[1,0,0,0,0,0,0],[0,1,0,0,0,0,0],[0,0,1,0,0,0,0],[0,0,0,1,0,0,0]])
self.kf.R[2:,2:] *= 10.
self.kf.P[4:,4:] *= 1000. #give high uncertainty to the unobservable initial velocities 對未觀測到的初始速度給出高的不確定性
self.kf.P *= 10. # 默認定義的協方差矩陣是np.eye(dim_x),將P中的數值與10, 1000相乘,賦值不確定性
self.kf.Q[-1,-1] *= 0.01
self.kf.Q[4:,4:] *= 0.01
self.kf.x[:4] = convert_bbox_to_z(bbox) #將bbox轉為 [x,y,s,r]^T形式,賦給狀態變數X的前4位
self.time_since_update = 0
self.id = KalmanBoxTracker.count
KalmanBoxTracker.count += 1
self.history = []
self.hits = 0
self.hit_streak = 0
self.age = 0
def update(self,bbox):
"""
Updates the state vector with observed bbox.
"""
self.time_since_update = 0
self.history = []
self.hits += 1
self.hit_streak += 1
self.kf.update(convert_bbox_to_z(bbox))
def predict(self):
"""
Advances the state vector and returns the predicted bounding box estimate.
"""
if((self.kf.x[6]+self.kf.x[2])<=0):
self.kf.x[6] *= 0.0
self.kf.predict()
self.age += 1
if(self.time_since_update>0):
self.hit_streak = 0
self.time_since_update += 1
self.history.append(convert_x_to_bbox(self.kf.x))
return self.history[-1]
def get_state(self):
"""
Returns the current bounding box estimate.
"""
return convert_x_to_bbox(self.kf.x)
def associate_detections_to_trackers(detections,trackers,iou_threshold = 0.3): #用于將檢測與跟蹤進行關聯
"""
Assigns detections to tracked object (both represented as bounding boxes)
Returns 3 lists of matches, unmatched_detections and unmatched_trackers
"""
if(len(trackers)==0): #如果跟蹤器為空
return np.empty((0,2),dtype=int), np.arange(len(detections)), np.empty((0,5),dtype=int)
iou_matrix = np.zeros((len(detections),len(trackers)),dtype=np.float32) # 檢測器與跟蹤器IOU矩陣
for d,det in enumerate(detections):
for t,trk in enumerate(trackers):
iou_matrix[d,t] = iou(det,trk) #計算檢測器與跟蹤器的IOU并賦值給IOU矩陣對應位置
matched_indices = linear_assignment(-iou_matrix) # 參考:https://blog.csdn.net/herr_kun/article/details/86509591 加上負號是因為linear_assignment求的是最小代價組合,而我們需要的是IOU最大的組合方式,所以取負號
unmatched_detections = [] #未匹配上的檢測器
for d,det in enumerate(detections):
if(d not in matched_indices[:,0]): #如果檢測器中第d個檢測結果不在匹配結果索引中,則d未匹配上
unmatched_detections.append(d)
unmatched_trackers = [] #未匹配上的跟蹤器
for t,trk in enumerate(trackers):
if(t not in matched_indices[:,1]): #如果跟蹤器中第t個跟蹤結果不在匹配結果索引中,則t未匹配上
unmatched_trackers.append(t)
#filter out matched with low IOU 過濾掉那些IOU較小的匹配對
matches = [] #存放過濾后的匹配結果
for m in matched_indices: #遍歷粗匹配結果
if(iou_matrix[m[0],m[1]]<iou_threshold): #m[0]是檢測器ID, m[1]是跟蹤器ID,如它們的IOU小于閾值則將它們視為未匹配成功
unmatched_detections.append(m[0])
unmatched_trackers.append(m[1])
else:
matches.append(m.reshape(1,2)) #將過濾后的匹配對維度變形成1x2形式
if(len(matches)==0): #如果過濾后匹配結果為空,那么回傳空的匹配結果
matches = np.empty((0,2),dtype=int)
else: #如果過濾后匹配結果非空,則按0軸方向繼續添加匹配對
matches = np.concatenate(matches,axis=0)
return matches, np.array(unmatched_detections), np.array(unmatched_trackers) #其中跟蹤器陣列是5列的(最后一列是ID)
class Sort(object):
def __init__(self,max_age=1,min_hits=3):
"""
Sets key parameters for SORT
"""
self.max_age = max_age
self.min_hits = min_hits
self.trackers = []
self.frame_count = 0
def update(self,dets): #輸入的是檢測結果[x1,y1,x2,y2,score]形式
"""
Params:
dets - a numpy array of detections in the format [[x1,y1,x2,y2,score],[x1,y1,x2,y2,score],...]
Requires: this method must be called once for each frame even with empty detections. #每一幀都得呼叫一次,即便檢測結果為空
Returns the a similar array, where the last column is the object ID. #回傳相似的陣列,最后一列是目標ID
NOTE: The number of objects returned may differ from the number of detections provided. #回傳的目標數量可能與提供的檢測數量不同
"""
self.frame_count += 1 #幀計數
#get predicted locations from existing trackers.
trks = np.zeros((len(self.trackers),5)) # 根據當前所有卡爾曼跟蹤器的個數創建二維零矩陣,維度為:卡爾曼跟蹤器ID個數x 5 (這5列內容為bbox與ID)
to_del = [] #存放待洗掉
ret = [] #存放最后回傳的結果
for t,trk in enumerate(trks): #回圈遍歷卡爾曼跟蹤器串列
pos = self.trackers[t].predict()[0] #用卡爾曼跟蹤器t 預測 對應物體在當前幀中的bbox
trk[:] = [pos[0], pos[1], pos[2], pos[3], 0]
if(np.any(np.isnan(pos))): #如果預測的bbox為空,那么將第t個卡爾曼跟蹤器洗掉
to_del.append(t)
trks = np.ma.compress_rows(np.ma.masked_invalid(trks)) #將預測為空的卡爾曼跟蹤器所在行洗掉,最后trks中存放的是上一幀中被跟蹤的所有物體在當前幀中預測的非空bbox
for t in reversed(to_del): #對to_del陣列進行倒序遍歷
self.trackers.pop(t) #從跟蹤器中洗掉 to_del中的上一幀跟蹤器ID
matched, unmatched_dets, unmatched_trks = associate_detections_to_trackers(dets,trks) #對傳入的檢測結果 與 上一幀跟蹤物體在當前幀中預測的結果做關聯,回傳匹配的目標矩陣matched, 新增目標的矩陣unmatched_dets, 離開畫面的目標矩陣unmatched_trks
#update matched trackers with assigned detections
for t,trk in enumerate(self.trackers): # 對卡爾曼跟蹤器做遍歷
if(t not in unmatched_trks): #如果上一幀中的t還在當前幀畫面中(即不在當前預測的離開畫面的矩陣unmatched_trks中)
d = matched[np.where(matched[:,1]==t)[0],0] #說明卡爾曼跟蹤器t是關聯成功的,在matched矩陣中找到與其關聯的檢測器d
trk.update(dets[d,:][0]) #用關聯的檢測結果d來更新卡爾曼跟蹤器(即用后驗來更新先驗)
#create and initialise new trackers for unmatched detections #對于新增的未匹配的檢測結果,創建并初始化跟蹤器
for i in unmatched_dets: #新增目標
trk = KalmanBoxTracker(dets[i,:]) #將新增的未匹配的檢測結果dets[i,:]傳入KalmanBoxTracker
self.trackers.append(trk) #將新創建和初始化的跟蹤器trk 傳入trackers
i = len(self.trackers)
for trk in reversed(self.trackers): #對新的卡爾曼跟蹤器集進行倒序遍歷
d = trk.get_state()[0] #獲取trk跟蹤器的狀態 [x1,y1,x2,y2]
if((trk.time_since_update < 1) and (trk.hit_streak >= self.min_hits or self.frame_count <= self.min_hits)):
ret.append(np.concatenate((d,[trk.id+1])).reshape(1,-1)) # +1 as MOT benchmark requires positive
i -= 1
#remove dead tracklet
if(trk.time_since_update > self.max_age):
self.trackers.pop(i)
if(len(ret)>0):
return np.concatenate(ret)
return np.empty((0,5))
def parse_args():
"""Parse input arguments."""
parser = argparse.ArgumentParser(description='SORT demo')
parser.add_argument('--display', dest='display', help='Display online tracker output (slow) [False]',action='store_true')
args = parser.parse_args()
return args
if __name__ == '__main__':
# all train
sequences = ['PETS09-S2L1','TUD-Campus','TUD-Stadtmitte','ETH-Bahnhof','ETH-Sunnyday','ETH-Pedcross2','KITTI-13','KITTI-17','ADL-Rundle-6','ADL-Rundle-8','Venice-2']
args = parse_args()
display = args.display
phase = 'train'
total_time = 0.0
total_frames = 0
colours = np.random.rand(32,3) #used only for display
if(display):
if not os.path.exists('mot_benchmark'):
print('\n\tERROR: mot_benchmark link not found!\n\n Create a symbolic link to the MOT benchmark\n (https://motchallenge.net/data/2D_MOT_2015/#download). E.g.:\n\n $ ln -s /path/to/MOT2015_challenge/2DMOT2015 mot_benchmark\n\n')
exit()
plt.ion() #用于動態繪制顯示影像
fig = plt.figure()
if not os.path.exists('output'):
os.makedirs('output')
for seq in sequences:
mot_tracker = Sort() #create instance of the SORT tracker 創建Sort 跟蹤實體
seq_dets = np.loadtxt('data/%s/det.txt'%(seq),delimiter=',') #load detections #加載檢測結果
with open('output/%s.txt'%(seq),'w') as out_file:
print("Processing %s."%(seq))
for frame in range(int(seq_dets[:,0].max())): #確定視頻序列總幀數,并進行for回圈
frame += 1 #detection and frame numbers begin at 1 #由于視頻序列幀數是從1開始的,因此加1
dets = seq_dets[seq_dets[:,0]==frame,2:7] #提取檢測結果中的[x1,y1,w,h,score]到dets
dets[:,2:4] += dets[:,0:2] #convert to [x1,y1,w,h] to [x1,y1,x2,y2] 將dets中的第2,3列的數加上第0,1列的數后賦值給2,3列;
total_frames += 1 #總幀數累計
if(display): #如果要求顯示結果
ax1 = fig.add_subplot(111, aspect='equal')
fn = 'mot_benchmark/%s/%s/img1/%06d.jpg'%(phase,seq,frame) #原影像路徑名
im =io.imread(fn) #加載影像
ax1.imshow(im) #顯示影像
plt.title(seq+' Tracked Targets')
start_time = time.time()
trackers = mot_tracker.update(dets) #sort跟蹤器更新
cycle_time = time.time() - start_time #sort跟蹤器耗時
total_time += cycle_time #sort跟蹤器總共耗費時間
for d in trackers:
print('%d,%d,%.2f,%.2f,%.2f,%.2f,1,-1,-1,-1'%(frame,d[4],d[0],d[1],d[2]-d[0],d[3]-d[1]),file=out_file) #列印: frame,ID,x1,y1,x2,y2,1,-1,-1,-1
if(display): #如果顯示,將目標檢測框畫上
d = d.astype(np.int32)
ax1.add_patch(patches.Rectangle((d[0],d[1]),d[2]-d[0],d[3]-d[1],fill=False,lw=3,ec=colours[d[4]%32,:]))
ax1.set_adjustable('box-forced')
if(display):
fig.canvas.flush_events()
plt.draw()
ax1.cla()
print("Total Tracking took: %.3f for %d frames or %.1f FPS"%(total_time,total_frames,total_frames/total_time))
if(display):
print("Note: to get real runtime results run without the option: --display")
DeepSORT 深入解讀


一年之后,原團隊發布了 SORT 的續作 DeepSORT,到現在都有很多人在用這個跟蹤器,
整體框架沒有大改,還是延續了卡爾曼濾波加匈牙利演算法的思路,在這個基礎上增加了 Deep Association Metric,Deep Association Metric 其實就是在大型行人重識別網路上學習的一個行人鑒別網路,目的是區分出不同的行人,個人感覺很類似于典型的行人重識別網路,輸出行人圖片,輸出一組向量,通過比對兩個向量之間的距離,來判斷兩副輸入圖片是否是同一個行人,
此外還加入了外觀資訊(Appearance Information)以實作較長時間遮擋的目標跟蹤,
跟蹤流程延續上作,在卡爾曼濾波的預測結果的基礎上,繼續使用了匈牙利演算法進行目標分配,但在這個程序中加入了運動資訊和外觀資訊,這個說起來簡單,實作起來比較復雜,感興趣的讀者可以細看論文和代碼,在這里就不贅述了,
其他方面沒有太多變化,還是使用了標準的卡爾曼濾波和固定速度模型等來進行預測,
最終實作了較好的跟蹤效果,并且能夠實時運行(40FPS),
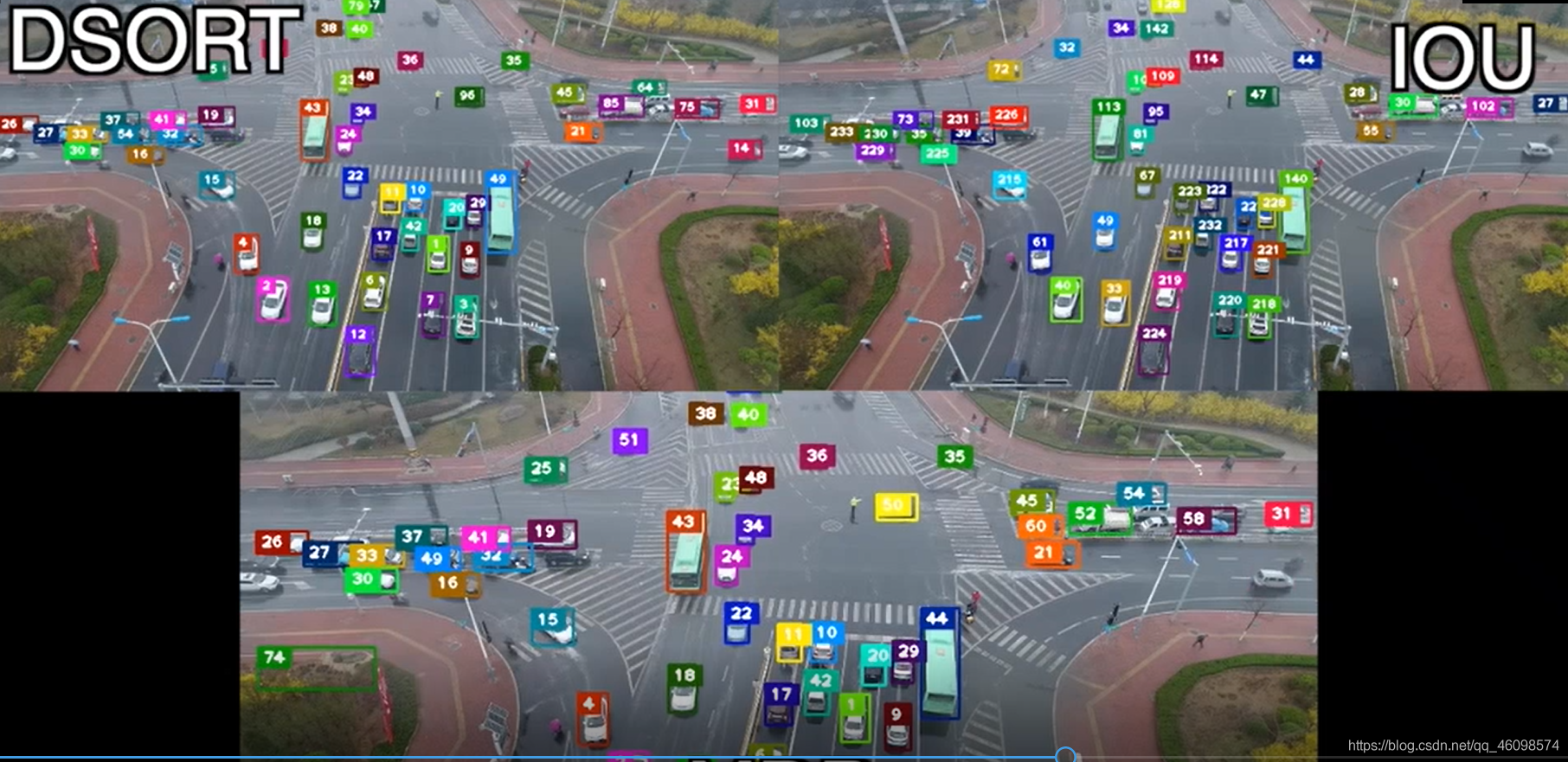
IOU 匹配流程圖
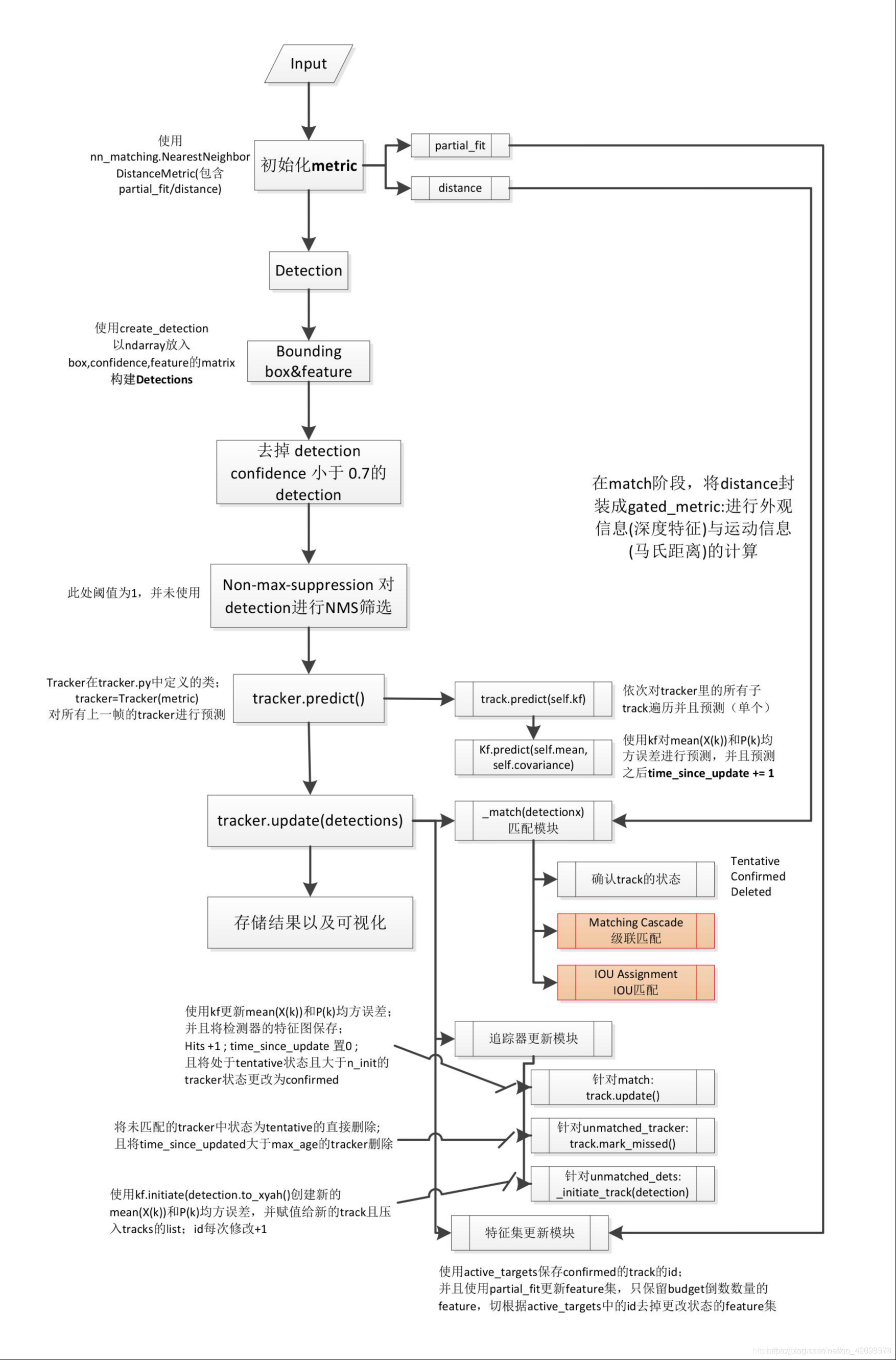
作者代碼也以檢測結果為輸入:bounding box、confidence、feature ,conf 主要用于進行一部分的檢測框的篩選;bounding box 與 feature(ReID)用于后面與跟蹤器的 match 計算;首先是預測模塊,會對跟蹤器使用卡爾曼濾波器進行預測,作者在這里使用的是卡爾曼濾波器的勻速運動和線性觀測模型(意味著只有四個量且在初始化時會使用檢測器進行恒值初始化),其次是更新模塊,其中包括匹配,追蹤器更新與特征集更新,在更新模塊的部分,根本的方法還是使用 IOU 來進行匈牙利演算法的匹配
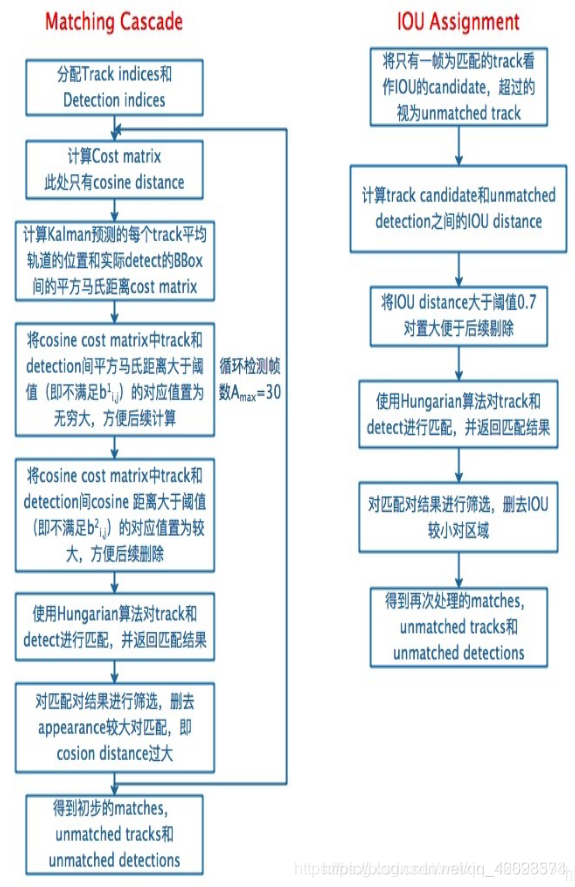
1.使用級聯匹配演算法:
針對每一個檢測器都會分配一個跟蹤器,每個跟蹤器會設定一個 time_since_update 引數,如果跟蹤器完成匹配并進行更新,那么引數會重置為 0,否則就會+1,實際上,級聯匹配換句話說就是不同優先級的匹配,在級聯匹配中,會根據這個引數來對跟蹤器分先后順序,引數小的先來匹配,引數大的后匹配,也就是給上一幀最先匹配的跟蹤器高的優先權,給好幾幀都沒匹配上的跟蹤器降低優先權(慢慢放棄),至于使用級聯匹配的目的,我參考一下博客②里的解釋:
當一個目標長時間被遮擋之后,kalman 濾波預測的不確定性就會大大增加,狀態空間內的可觀察性就會大大降低,假如此時兩個追蹤器競爭同一個檢測結果的匹配權,往往遮擋時間較長的那條軌跡的馬氏距離更小,使得檢測結果更可能和遮擋時間較長的那條軌跡相關聯,這種不理想的效果往往會破壞追蹤的持續性,這么理解吧,假設本來協方差矩陣是一個正態分布,那么連續的預測不更新就會導致這個正態分布的方差越來越大,那么離均值歐氏距離遠的點可能和之前分布中離得較近的點獲得同樣的馬氏距離值,所以,作者使用了級聯匹配來對更加頻繁出現的目標賦予優先權,當然同樣也有弊端:可能導致一些新產生的軌跡被連接到了一些舊的軌跡上,但這種情況較少,
2.添加馬氏距離與余弦距離:
實際上是針對運動資訊與外觀資訊的計算,兩個名詞聽著較為陌生,而實際上換句話解釋,馬氏距離就是“加強版的歐氏距離”,它實際上是規避了歐氏距離中對于資料特征方差不同的風險,在計算中添加了協方差矩陣,其目的就是進行方差歸一化,從而使所謂的“距離”更加符合資料特征以及實際意義,馬氏距離是對于差異度的衡量中,的一種距離度量方式,而不同于馬氏距離,余弦距離則是一種相似度度量方式,前者是針對于位置進行區分,而后者則是針對于方向,換句話說,我們使用余弦距離的時候,可以用來衡量不同個體在維度之間的差異,而一個個體中,維度與維度的差異我們卻不好判斷,此時我們可以使用馬氏距離進行彌補,從而在整體上可以達到一個相對于全面的差異性衡量,而我們之所以要進行差異性衡量,根本目的也是想比較檢測器與跟蹤器的相似程度,優化度量方式,也可以更好地完成匹配,
3.添加深度學習特征:
這一部分也就是 ReID 的模塊,也是 deepsort 的亮點之一,deepsort 在對于 sort 的改進中加入了一個深度學習的特征提取網路,網路結構部分各位看官可以移步論文,作者將所有 confirmed 的追蹤器(其中一個狀態)每次完成匹配對應的 detection 的 feature map 存盤進一個 list,存盤的數量作者使用 budget 超引數(100 幀)進行限制(我認為如果實時性效果不好的話,可以調低這個引數加快速度),從而我們在每次匹配之后都會更新這個 feature map 的 list,比如去除掉一些已經出鏡頭的目標的特征集,保留最新的特征將老的特征 pop 掉等等,這個特征集在進行余弦距離計算的時候將會發揮作用,實際上,在當前幀,會計算第 i 個物體跟蹤的所有 Feature 向量和第 j 個物體檢測之間的最小余弦距離,
4.IOU 與匈牙利演算法匹配:
這個方法是在 sort 中被提出的,又是比較陌生的名詞,我接著“換句話說”,實際上匈牙利演算法可以理解成“盡量多”的一種思路,比如說 A 檢測器可以和 a,c 跟蹤器完成匹配(與 a 匹配置信度更高),但是 B 檢測器只能和 a 跟蹤器完成匹配,那在演算法中,就會讓 A 與 c 完成匹配,B 與 a 完成匹配,而降低對于置信度的考慮,所以演算法的根本目的并不是在于匹配的準不準,而是在于盡量多的匹配上,這也就是在 deepsort 中作者添加級聯匹配與馬氏距離與余弦距離的根本目的,因為僅僅使用匈牙利演算法進行匹配特別容易造成 ID switch,就是一個檢測框 id 不停地進行更換,缺乏準確性與魯棒性,那什么是匹配的置信度高呢,其實在這里,作者使用的是 IOU 進行衡量,計算檢測器與跟蹤器的 IOU,將這個作為置信度的高低(比較粗糙),
還有一些超引數,我也已經在代碼流程的部分明確講解了,這些超引數或進行閾值的作用,或進行回圈次數的限定,不斷幫助演算法完成最優匹配與追蹤器更新,之后,將未匹配的追蹤器 delete,將未匹配的檢測器初始化,將匹配的追蹤器使用對應的檢測器進行賦值,作為輸出,進入下次回圈,
Deepsort 代碼解讀
另一篇寫的很棒的 Deepsort 原理解讀:https://blog.csdn.net/sgfmby1994/article/details/98517210
yolo 的總體思想歸納:
首先,將輸入圖片壓縮到 416×416,通過特征提取網路(Darknet53 without FC layer)對輸入影像提取特征得到大小一定的特征圖,比如 13×13,然后將輸入影像分成 13×13 個網格(grid cells),接著如果 GT 中某個目標的中心坐標落在哪個 grid cell 中,那么就由該 grid cell 來預測該目標,每個 grid cell 都會預測 3 個邊界框,預測得到的輸出特征圖共有三個維度,第三個維度是深度,
Yolov3 輸出了三個不同尺度的特征圖,采用多尺度對不同大小的目標進行檢測,越精細的 grid cell 就可以檢測出越精細的物體,三個尺度的深度都是 255(3×(5+80)),
根據圖來說明程序:
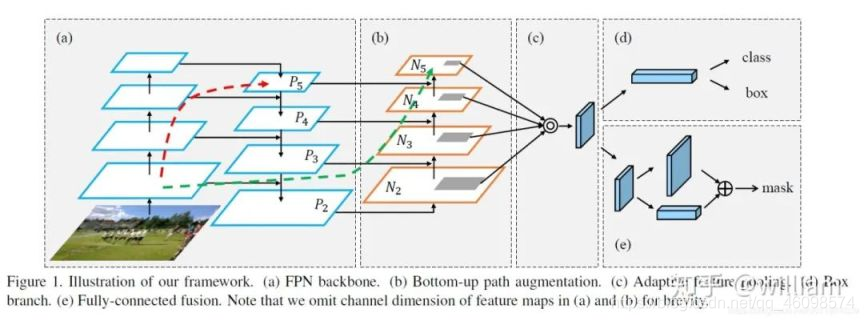
流程:首先輸入尺寸 416×416,然后進入 darknet 特征提取網路,右邊圖(不算分支,也是左邊圖虛線中內容),其中經過五次下采樣,還是用了殘差結構,目的是使網路結構在很深的情況下,仍能收斂,繼續訓練下去,然后到左邊圖,虛線中輸出的尺寸是 13×13,然后在經過 DBL 特征提取,以及最后藍色的卷積(我猜是用來代替全連接分類的),輸出第一個尺度 13×13,
接著用虛線輸出的特征圖經過 DBL 后的 13×13 的特征圖上采樣后與倒數第二次下采樣的結果相加,二者都為 26×26,然后在進行和尺度一同樣的后續操作,
最后是 26×26 的特征圖上采樣后與倒數第三次下采樣的特征圖相加,即還為 26×26,在進行后續操作,
總的來說會輸出 3 個不同尺度的特征圖,每個尺度的特征圖負責預測不同大小的目標,每個特征圖對應 3 種 anchor 大小不同的負責預測目標,最初影像還被分成 13×13 個網格,目標落在哪個網格中,哪個網格就負責預測目標,一個網格對應 3 個 anchor(anchor 的尺寸根據特征圖相對于原圖的比例等比縮小),
預測時,yolov3 采用多個獨立的邏輯分類器來計算屬于特定標簽的可能性,在計算分類損失時,它對每個標簽使用二元交叉熵損失,降低了計算的復雜度,
YOLOv3 和 YOLOv5 整體思想類似,不過 YOLOV5 增加了 PaNet 等 tricks,以及 Mossiac 等大量資料增強,
YOLO V5 使用 GIOU Loss 作為 bounding box 的損失,
YOLO V5 使用二進制交叉熵和 Logits 損失函式計算類概率和目標得分的損失,同時我們也可以使用 fl _ gamma 引數來激活 Focal loss 計算損失函式,
在 YOLO V5 中,中間/隱藏層使用了 Leaky ReLU 激活函式,最后的檢測層使用了 Sigmoid 形激活函式,
YOLOv3/YOLOv5 訓練教程:
以 github Ultralytics 作者的 Yolov3 和 Yolo v5 為例子,可以很迅速的訓練資料:1:配置環境 pip install -U -r requirements.txt
2:資料標注與預處理
將我們的 XML 檔案放至 Annotations
將我們的圖片放到 images
然后就可以轉換 Annotations 為 Yolo 的訓練格式,百度有很多,這里要注意看一下代碼,有的地方需要修改,
并切分訓練驗證集,代碼也給了,Voc_Labels.py 請看看代碼,沒怎么寫注釋,
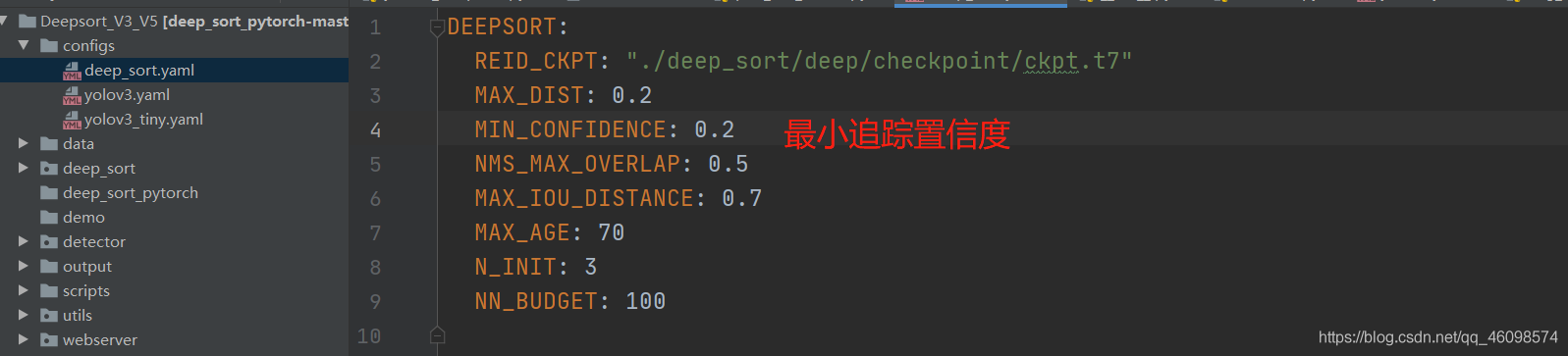
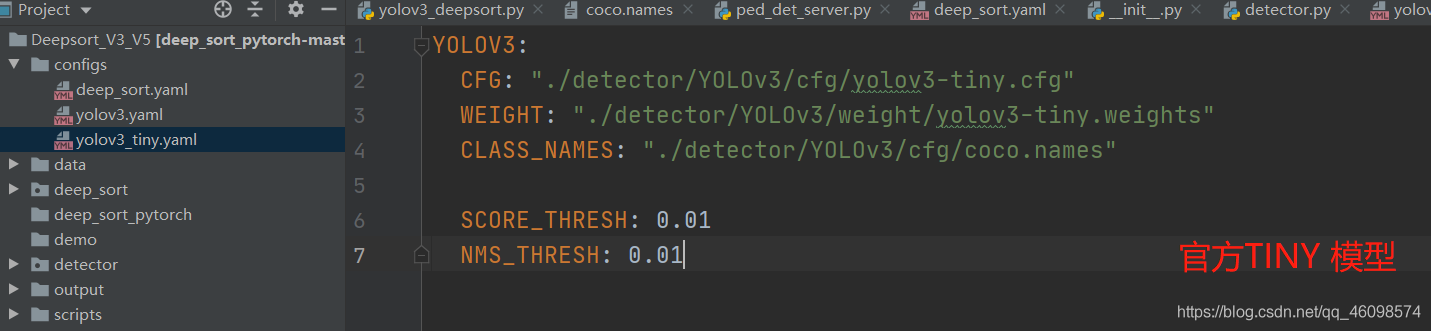
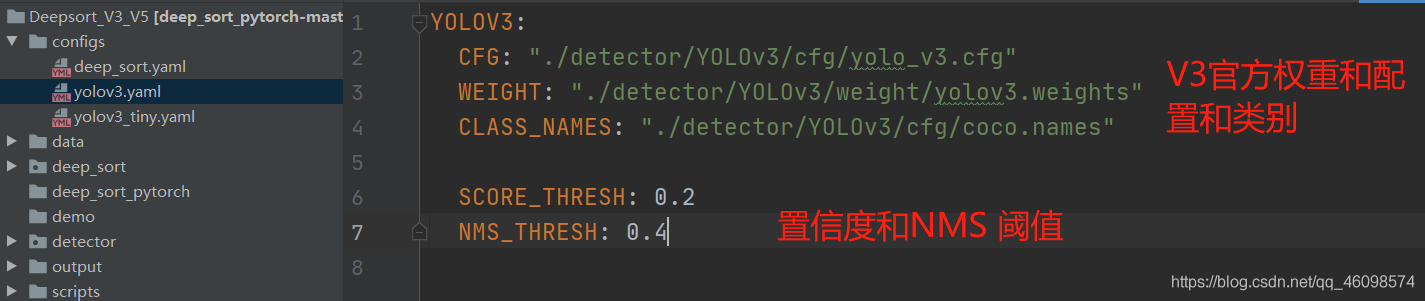
接下來撰寫 data/檔案夾的 yaml 檔案(可以新建):
在上面我們做好資料預處理后,就可以開始訓練了,上面的一些處理步驟,每個人都可能不同,不過大體上思路是一致的,
接下來我們可以進行預訓練,下載官方的預訓練模型:yolov5s yolov5m yolov5l yolov5x 來 我在我的 github 中方了 yolov5s,比較小,只有 25mb,專門為移動端考慮了,真好,
當然也可以不使用預訓練模型,使用與否,在總時間上是差不多的,不過
為什么要使用預訓練模型?
作者已盡其所能設計了基準模型,我們可以在自己的資料集上使用預訓練模型,而不是從頭構建模型來解決類似的自然語言處理問題,
盡管仍然需要進行一些微調,但它已經為我們節省了大量的時間:通常是每個損失下降更快和計算資源節省,
加快梯度下降的收斂速度
更有可能獲得一個低模型誤差,或者低泛化誤差的模型
降低因未初始化或初始化不當導致的梯度消失或者梯度爆炸問題,此情況會導致模型訓練速度變慢,崩潰,直至失敗,
其中隨機初始化,可以打破對稱性,從而保證不同的隱藏單元可以學習到不同的東西
接下來開始訓練:
python train.py --data data/smoke.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 10 --epochs 100
我們–data data/smoke.yaml 中就是在 smoke.yaml 中撰寫的訓練代碼路徑和類別等 data,通過這個獲取訓練的圖片和 label 標簽等,
然后-cfg models/yolov5s.yaml 和 --weights weights/yolov5s.pt 是獲取配置和預訓練模型權重
batch-size 10 大家都懂,default 是 16,大家可以改成 16,在 yolov5s 中模型參施不多,百萬左右,所以顯存消耗不多,我的配置很差,顯存 4g,在使用 yolov5m 中以及不能調到 16,
會報 cuda out of memory 報錯,就把 batch size 降低就行,
然后最后是 epoch,這個也不用解釋,我在使用 yolov5m 訓練 5k 張圖片在 100epoch 中花費 了 24 小時,一個 epoch13 分鐘,
訓練程序中,會慢慢在 runs 中生成 tensorboard,可視化損失下降
當然也可以在本地稍微看看
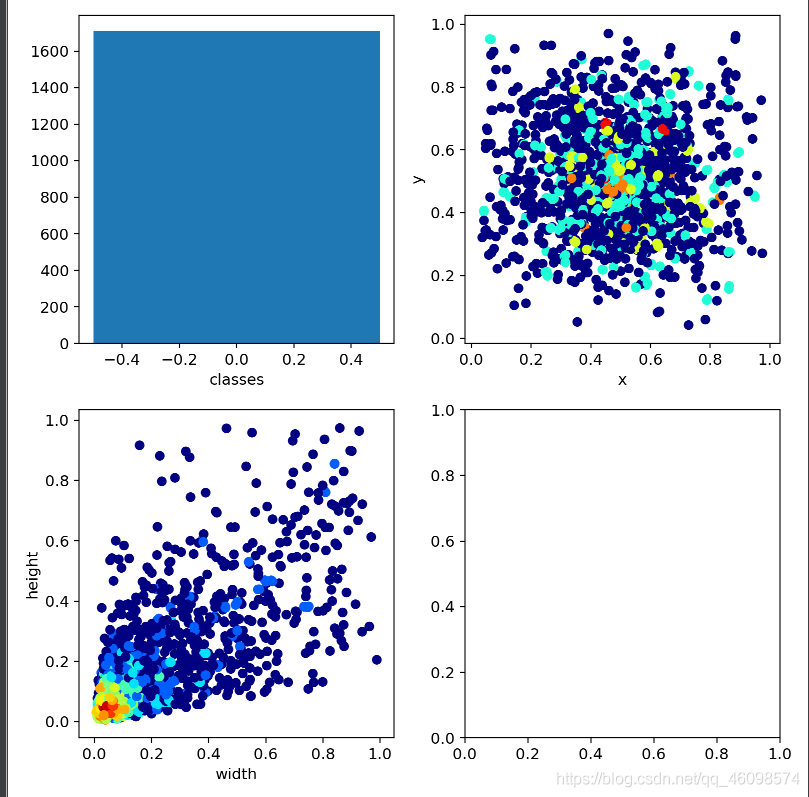
這幅圖中,我們的類別只有 1 個,第三幅圖顯示了我們資料中的寬高比,歸一化后,普遍在 0.1 左右,說明資料確實很小,也會面臨模糊問題,導致資料質量降低,
檢測:
運行 detect.py 即可

全部代碼介紹
來回顧一下代碼:
驗證腳本
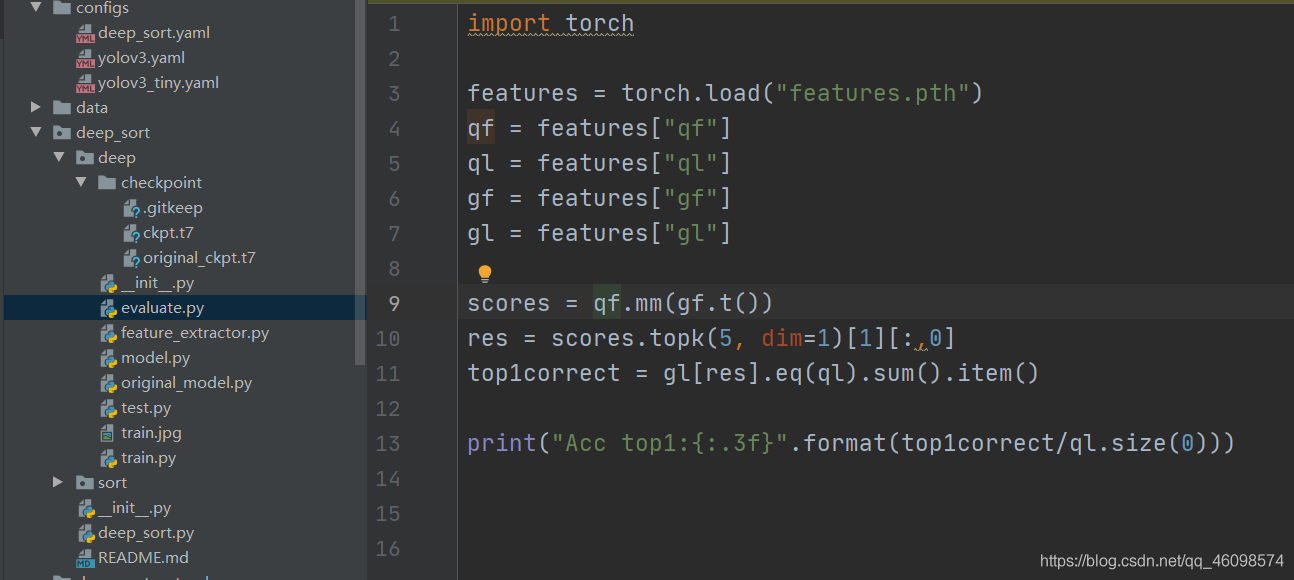
特征提取類
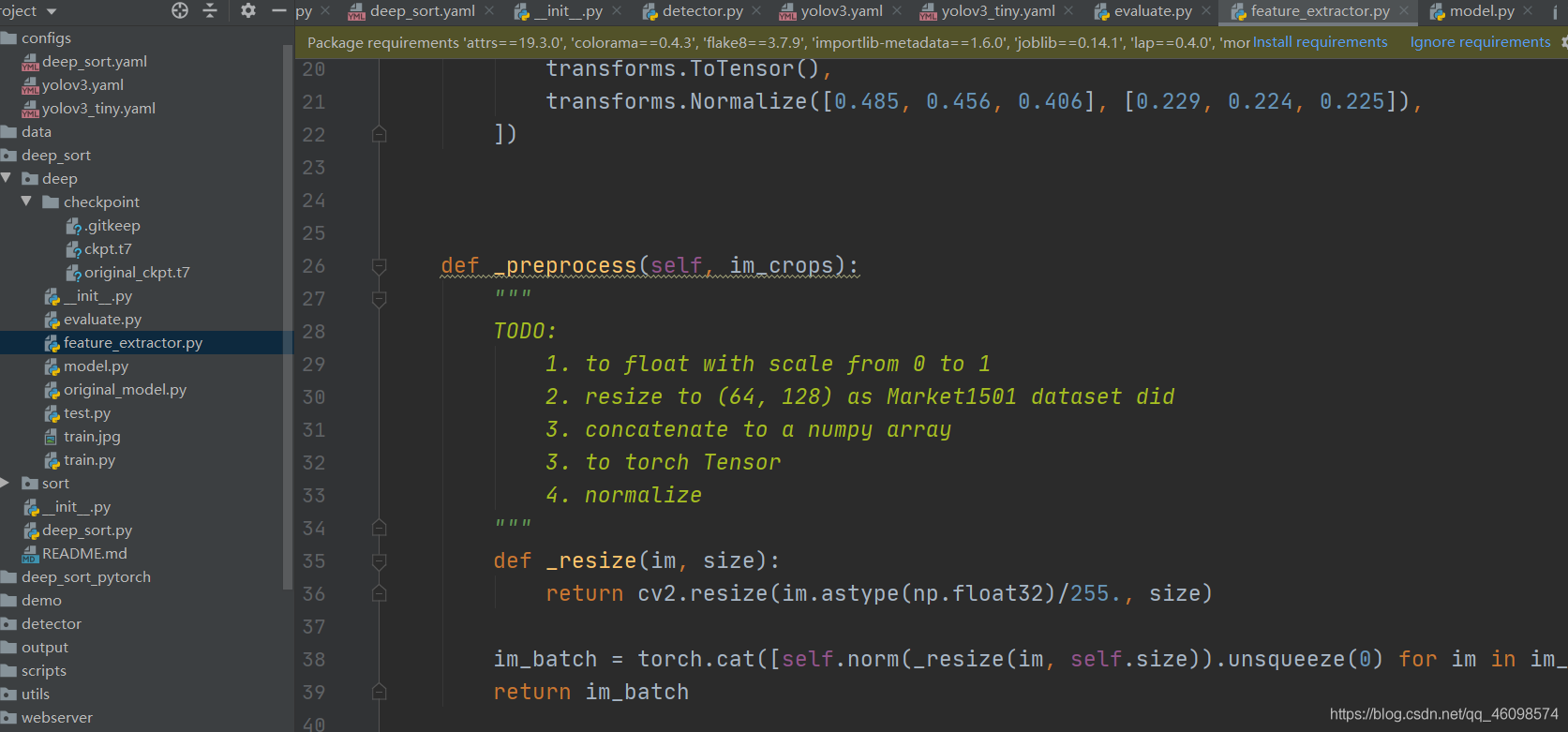
以【batch size,3,128,64】輸入,回傳類別結果的網路處理層,被上圖特征提取類使用,
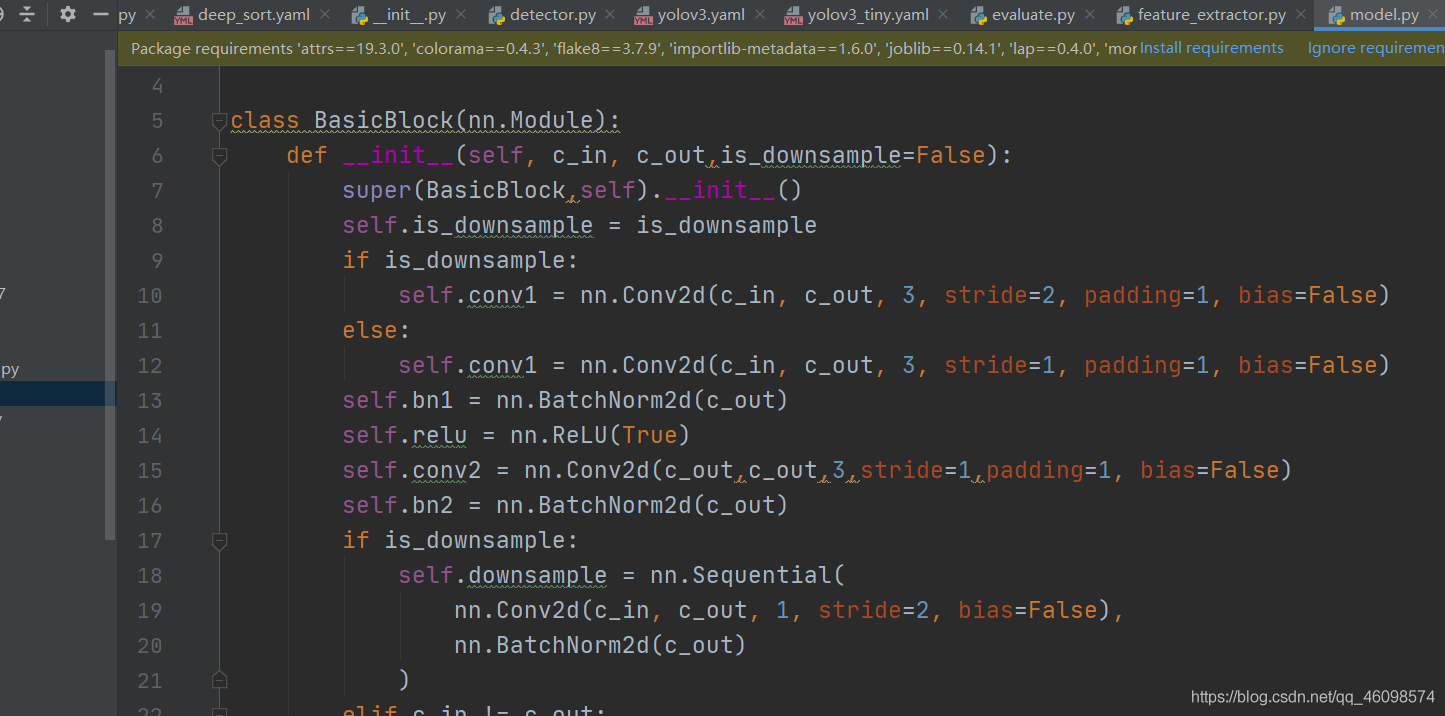
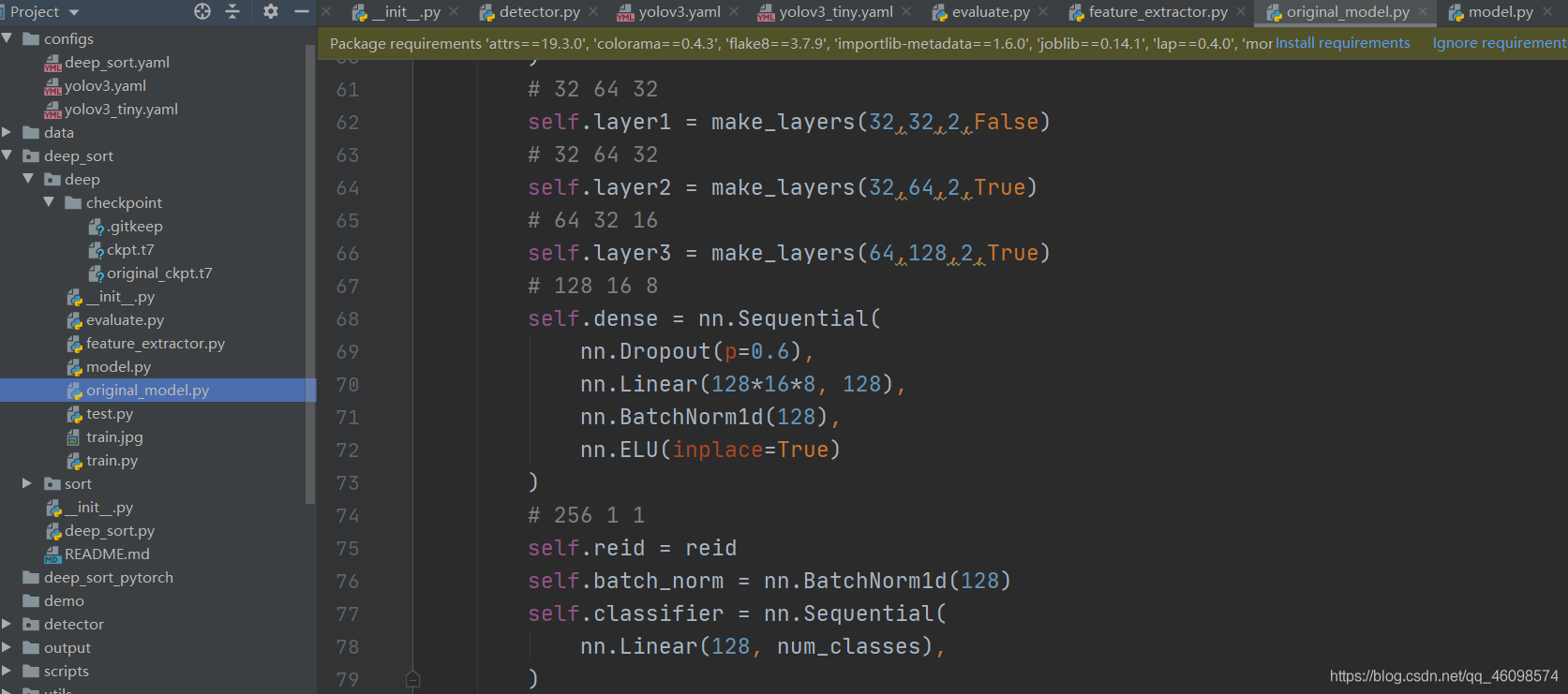
上圖目前網路較原網路稍稍優化了,下圖為原始網路,
網路性能驗證與測驗
網路訓練,
追蹤部分:
追蹤部分的資料轉換

匹配 Iou,用來區別框是否為待追蹤目標的途徑之一,
卡爾曼濾波
追蹤類,回傳識別結果
同追蹤類,回傳匹配追蹤目標,和不匹配目標
YOLOv3 部分,darknet 版本,的 pytorch 版,
原始類別的檢測腳本
更改后用于追蹤的檢測腳本
YOLOv3 網路層
處理資料,bdbox,nms 等操作的配置類 utils
決議 config 類
Rtsp 推流等方式 web 端部署,
V5 區域

訓練部分代碼和引數
圖片,視頻,web,相機等多方式檢測
配置多比例模型和配置 utils,
V5 匯出模型 onnx
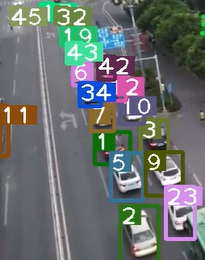
演示

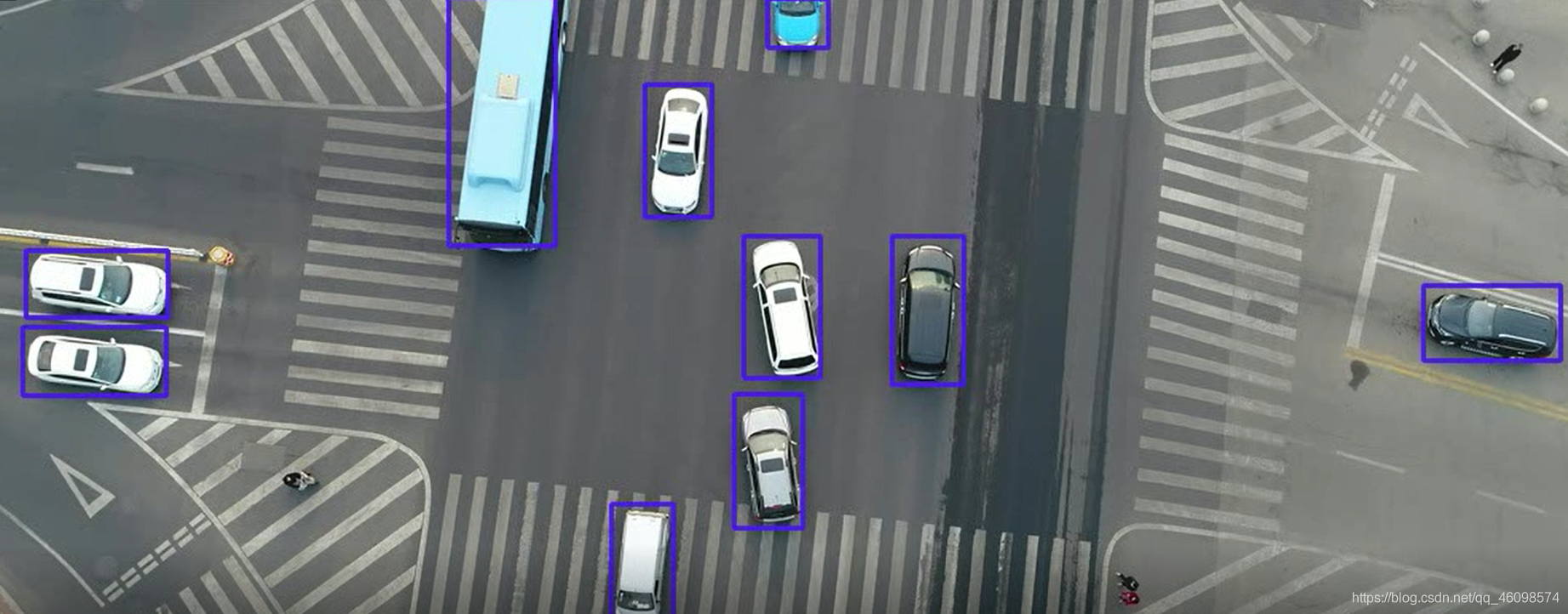
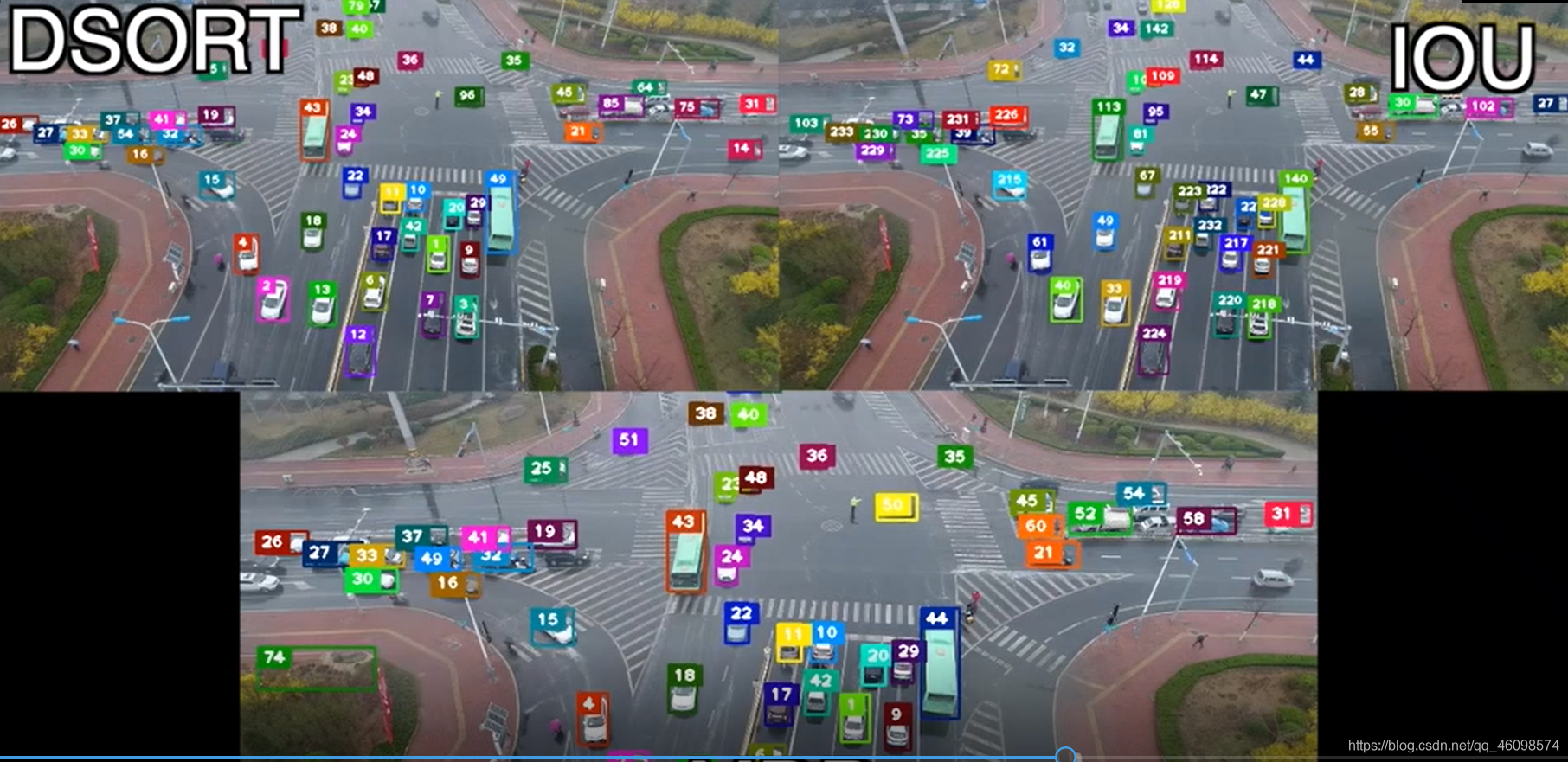
總結
原創好文,從原理到技術到原始碼到實際應用,工程,統統放送,在視頻流處理中,更是大放異彩~
在視頻流的實時追蹤中,我們雖然解決了一些問題,但是發現,還是有許多道阻且長的問題,
大家一起加油干吧~
歡迎關注 cv 君公眾號,原始碼歡迎公眾號回復 跟蹤 獲取哦

致謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278011.html
標籤:AI
上一篇:2021-04-19
下一篇:我眼中的線性代數