Apache Kafka 是一個開源流處理平臺,如今有超過30%的財富500強企業使用該平臺,Kafka 有很多特性使其成為事件流平臺(event streaming platform)的事實上的標準,在這篇博文中,我將介紹每個 Kafka 開發者都應該知道的五件事,這樣在使用 Kafka 就可以避免很多問題,
Tip #1 理解訊息傳遞和持久性保證
對于資料持久性(data durability),我們可以通過 KafkaProducer 類來設定 acks,acks 指的是 Producer 的訊息發送確認機制,這個引數支持以下三種選項:
?acks = 0:意味著如果生產者能夠通過網路把訊息發送出去,那么就認為訊息已成功寫入 Kafka ,是一種 fire and forget 模式,?acks = 1:意味若 Leader 在收到訊息并把它寫入到磁區資料檔案(不一定同步到磁盤上)時會回傳確認或錯誤回應,?acks = all(這個和 request.required.acks = -1 含義一樣):意味著 Leader 在回傳確認或錯誤回應之前,會等待所有同步副本都收到悄息,
正如您所看到的,這里需要進行權衡取舍(trade-off)——因為不同的應用程式有不同的需求,我們可以選擇較高的吞吐量,但有可能導致資料丟失,或者可以選擇以較低吞吐量為代價提供非常高的資料持久性保證,
現在,我們花點時間討論一下 acks=all 場景,如果你在一個由三個 Kafka broker 組成的集群中發送一條記錄,那么這意味著在理想的情況下,Kafka 包含你資料的三個副本:一份存在 lead broker 上,另外兩份存在 followers 上,當每個副本的日志都具有相同的記錄偏移量時,就認為它們是同步的,換句話說,這些同步副本對于給定的主題磁區具有相同的內容,看看下面的插圖,清楚地描繪出發生了什么:
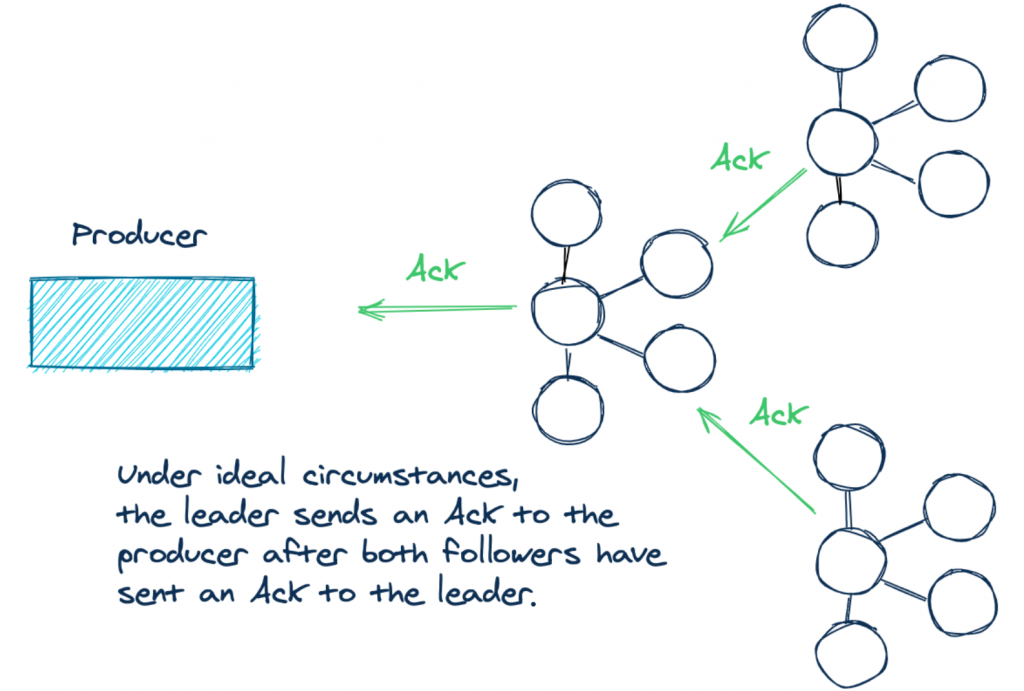
但是使用 acks=all 配置有一些微妙之處,它沒有指定需要同步多少個副本,主 broker 總是與自己保持同步,但是,由于網路磁區、記錄負載等原因,你可能會遇到以下兩個 broker 無法跟上的情況,因此,當生產者成功發送時,實際的確認數量可能只來自一個 broker !如果兩個 follower 不同步,生產者仍然會收到所需數量的 ack,但是在這種情況下只是 leader 同步了資料,
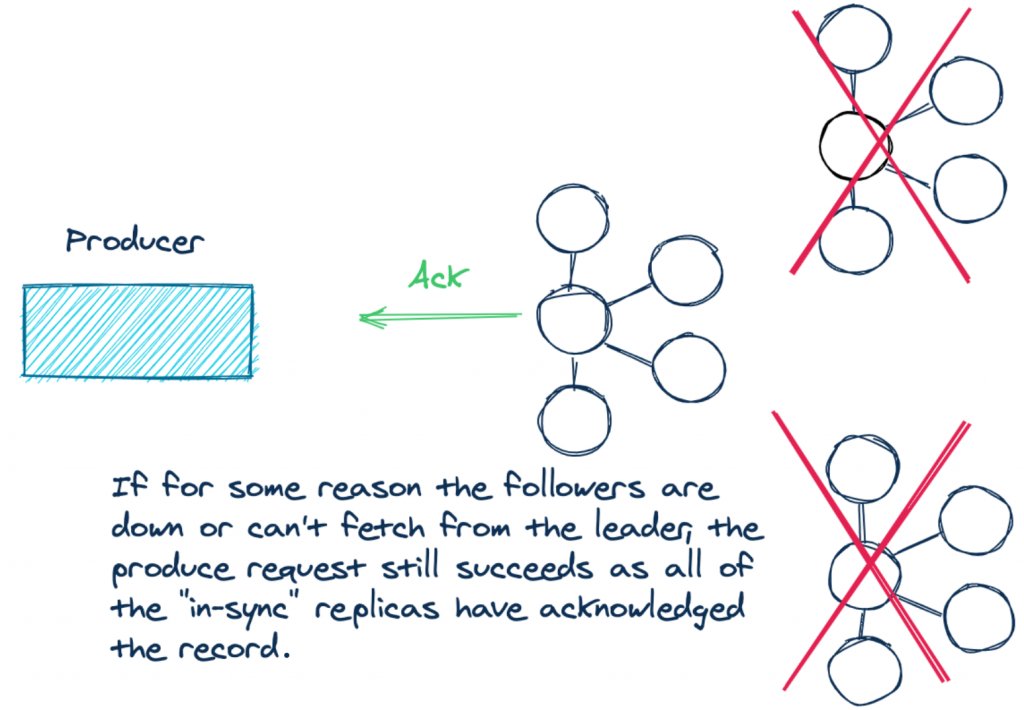
通過設定 acks=all,您正在為資料的持久性付出代價,因此,如果副本沒有跟上進度,則有理由要在副本被追上之前為新記錄引發例外,
簡而言之,我們需要的是使用 acks=all 設定時的保證,成功的發送至少涉及大多數可用的同步 broker(in-sync brokers),
恰好有一種這樣的配置:min.insync.replicas,min.insync.replicas配置強制執行復制操作之前必須同步的副本數,請注意,min.insync.replicas配置是在代理或主題級別設定的,而不是生產者配置,min.insync.replicas的默認值為1,因此,為避免上述情況,在三經紀商集群中,您希望將該值增加到兩個,
這里恰好有一個這樣的配置:min.insync.replicas,min.insync.replicas 配置強制執行復制操作之前必須同步的副本數,請注意,min.insync.replicas 配置是在 broker 或主題級別設定的,而不是 producer 配置的,min.insync.replicas 的默認值是1,因此,為了避免上述場景,在三個 broker 的集群中,您需要將值增加到2,
讓我們回顧一下之前的示例,看看其中的區別:
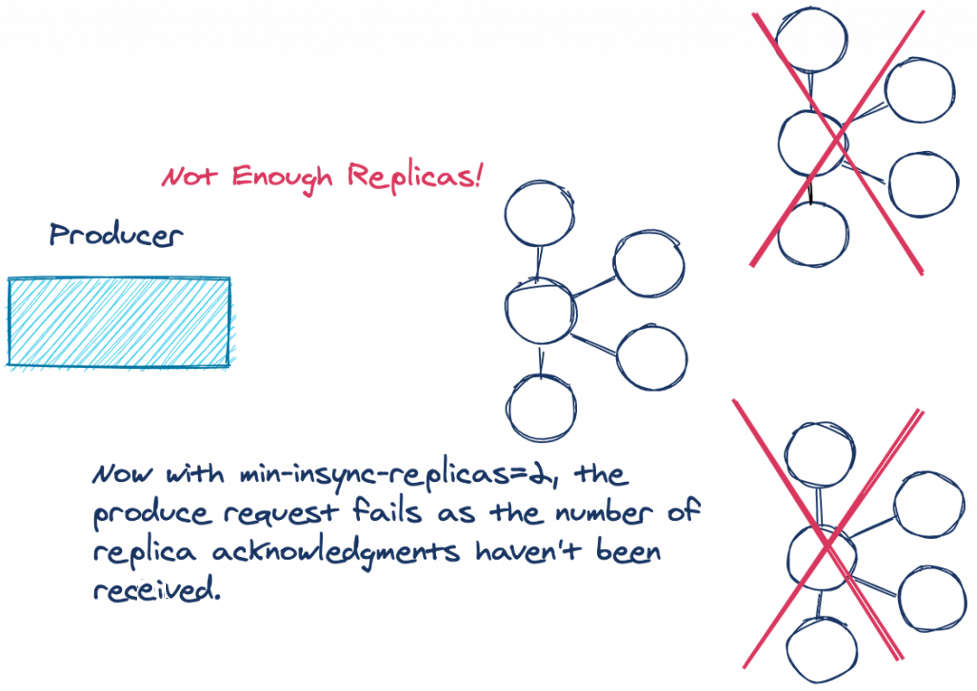
如果同步的副本數量低于配置的數量,則主 broker 不會嘗試將記錄追加到其日志中,leader broker 將拋出 NotEnoughReplicasException 或 NotEnoughReplicasAfterAppendException 例外,迫使 producer 重試寫操作,副本與 leader 不同步被認為是一個可重試的錯誤,因此生產者將繼續重試直到超時,
因此,通過 min.insync.replicas 和生產者 acks 一起使用,可以提高資料的持久性,
Tip #2: 了解 producer API 中新加的 sticky partitioner
Kafka使用磁區來增加吞吐量,并將訊息分散到集群中所有的 brokers ,Kafka records 采用鍵/值格式,鍵可以為空(null),Kafka 生產者不會立即發送記錄,而是將它們放入特定磁區的批次中,以便稍后發送,批處理是提高網路利用率的有效手段,有三種方法確定記錄應該寫入哪個磁區,
可以通過多載的 ProducerRecord 建構式在 ProducerRecord 物件中顯式地提供磁區,在這種情況下,生產者總是使用這個磁區,
如果沒有提供任何磁區,并且 ProducerRecord 有一個鍵,則生產者將該鍵的哈希值除以磁區的數量,計算得到的結果數就是生產者將要使用的磁區,
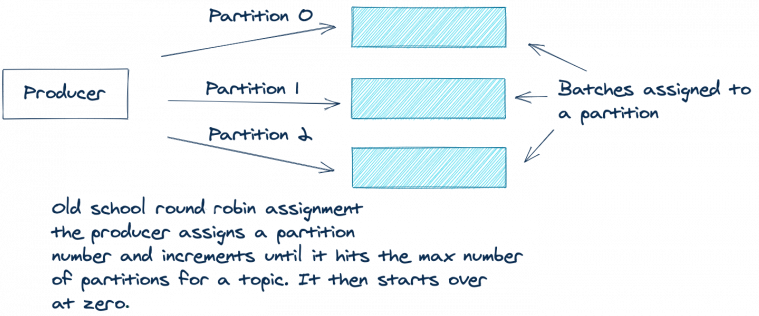
如果 ProducerRecord 中沒有鍵,也沒有磁區,那么以前的 Kafka 使用輪詢方法來跨磁區分配訊息,生產者將批處理中的第一個記錄分配給磁區0,第二個記錄分配給磁區1,依此類推,直到磁區結束,然后,生產者將從磁區0開始,并對所有剩余的記錄重復整個程序,
下圖描述了此程序:
輪詢方法適用于跨磁區均勻分布記錄,但也有一個缺點,由于這種“公平”的輪詢方法,您最終可能會發送多個稀疏填充的批處理,發送更少的批并在每個批中發送更多的記錄會更有效率,較少的批次意味著更少的生產請求排隊,因此 brokers 負載更少,
我們來看一個簡化的示例,在該示例中,我們有一個包含三個磁區的主題,為了簡單起見,假設我們的應用程式生成了9條沒有 key 的記錄,而這些記錄都是同時到達的:
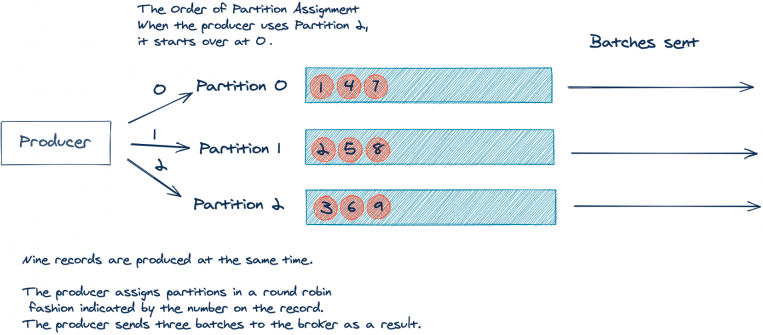
正如我們在上面所看到的,這9條記錄將產生3個批次,每個批次里面有三條訊息,但是,如果我們能將這9條記錄作為一個批次發送就更好了,如前所述,更少的批處理會導致 broker 上更少的網路流量和負載,
Apache Kafka 2.4.0 增加了粘性磁區(sticky partitioner)的方法,使得上面的假設成為可能,與對每個記錄使用輪詢方法不同,粘性磁區將記錄分配給同一個磁區,直到批處理被發送為止,然后,在發送一個批處理之后,粘性磁區將磁區增加以用于下一個批處理,讓我們看下上面的例子使用粘性磁區之后的處理方式:
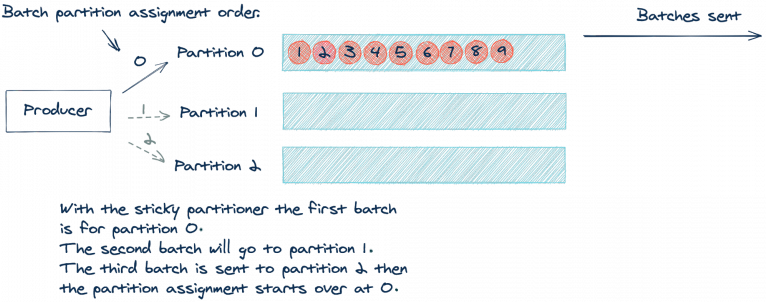
通過使用相同的磁區直到批處理滿或完成,我們將發送更少的請求,這減少了請求佇列上的負載,也減少了系統的延遲,值得注意的是,粘性磁區仍然會導致記錄的均勻分布,隨著時間的推移,均勻分布會發生,因為磁區程式會向每個磁區發送批處理,我們可以將其視為“每批”輪循或“最終均衡”的方法,
Tip #3: 通過 cooperative rebalancing 來避免“stop-the-world”的消費者組再平衡
Kafka 是一個分布式系統,分布式系統需要做的關鍵事情之一是處理故障和中斷,不僅僅是預測故障,而是完全接受它們,Kafka 如何處理這種預期中斷的一個很好的例子是消費者組協議(consumer group protocol),它為一個邏輯應用管理一個消費者的多個實體,如果一個消費者的實體停止了,不管是出于設計還是其他原因,Kafka 將重新平衡并確保另一個消費者實體接管作業,
從 Kafka 2.4版開始,Kafka 引入了新的再平衡協議:合作再平衡(cooperative rebalancing),但是,在我們深入研究新協議之前,讓我們先詳細了解消費者組(consumer group)的基礎知識,
假設我們有一個分布式應用程式,其中有多個消費者訂閱了同一個主題,配置有相同 group.id 的任意一個消費者構成一個邏輯消費者,在 Kafka 中稱為消費者組(consumer group),組中的每個消費者負責從訂閱主題的一個或多個磁區進行消費,這些磁區由消費者組 leader 進行分配,下圖說明了這個場景:
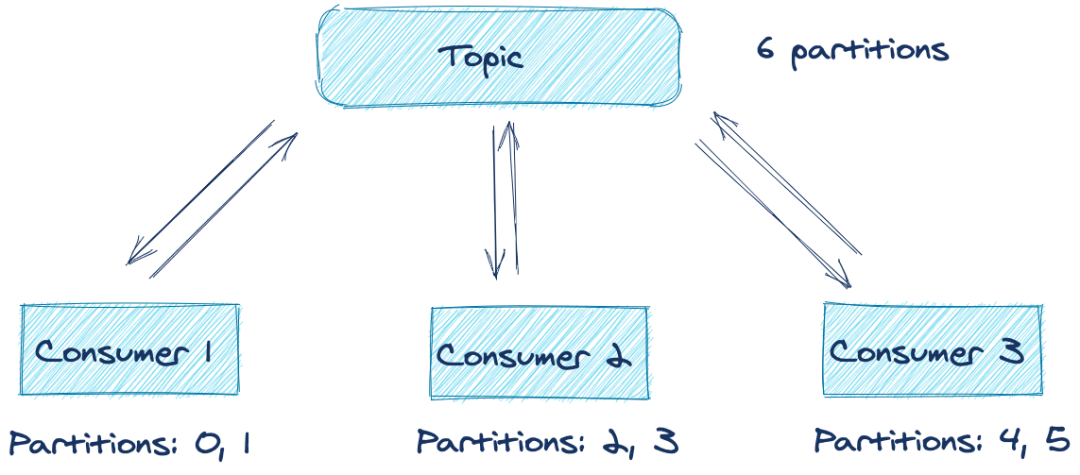
從上圖中可以看到,在最佳條件下,三個消費者分別處理來自兩個磁區的記錄,但是,如果其中一個應用程式出現錯誤或不能再連接到網路,會發生什么情況呢?在應用程式恢復之前對這些主題磁區的處理是否會停止?幸運的是,由于消費者再平衡協議,答案是否定的,下面是當一個消費者出現問題,消費者再平衡之后的結果:

正如我們看到的,消費者2由于某些原因出現問題,組協調器(group coordinator)將其從消費者組中洗掉,并觸發所謂的 rebalance,rebalance 是一種機制,它試圖在一個消費者組的所有可用成員之間均勻地分配(平衡)作業負載,在這種情況下,由于消費者2離開了組,rebalance 將其以前擁有的磁區分配給組的其他活動成員,因此,某個消費者應用程式出現問題不會導致丟失對這些主題磁區的處理,
但是,默認的再平衡方法存在一個缺點,每個消費者都需要放棄之前已經分配的主題磁區,并且直到重新分配主題磁區之后才進行資料處理,這個再平衡有時被稱為“stop-the-world”再平衡,為了使問題更加復雜,根據所使用的 ConsumerPartitionAssignor 實體,只需重新分配消費者在重新分配之前擁有的相同主題磁區,其最終結果是不需要暫停這些磁區上的作業,
重新平衡協議的這種實作方式稱為“eager rebalancing”,因為它優先考慮了確保同一組中的沒有消費者宣告對同一主題磁區的所有權的重要性,同一組中的兩個消費者擁有同一個主題磁區將導致未定義的行為,
盡管防止任何兩個消費者聲稱對同一主題磁區的所有權是至關重要的,但事實證明,有一種更好的方法可以在不減少處理時間的情況下提供安全性:增量協作再平衡(incremental cooperative rebalancing),它首先在 Apache Kafka 2.3 中的 Kafka Connect 中引入,現在已經在消費者組協議中實作了,使用協作方法,消費者不會在重新平衡開始時自動放棄所有主題磁區的所有權,相反,所有成員對他們當前的任務進行編碼,并將資訊轉發給組長,然后組長決定哪些磁區需要更改所有權,而不是從頭生成一個全新的分配,
現在第二種再平衡技術已經實作了,但是這次只涉及需要更改所有權的主題磁區,它可以回收不再分配的主題磁區或添加新的主題磁區,那些不需要移動的主題磁區可以繼續處理資料,
要啟用這個新的再平衡協議,我們需要將 partition.assignment.strategy 設定為 CooperativeStickyAssignor,另外,這個修改是在客戶端進行的,要利用新的再平衡協議,只需更新客戶端版本,如果你是 Kafka Streams 的用戶,還有更好的訊息,默認情況下,Kafka Streams 啟用的就是這個再平衡協議,因此無需執行其他操作,
Tip #4: 掌握命令列工具
Apache Kafka二進制安裝包括位于bin目錄中的幾個工具,盡管您會在該目錄中找到一些工具,但我想向您展示我認為會對您的日常作業產生最大影響的四個工具,我指的是控制臺用戶,控制臺生產者,轉儲日志和洗掉記錄,
Apache Kafka 二進制安裝包括幾個位于 bin 目錄下的工具,雖然我們可以在該目錄中找到幾個工具,但我想向您展示我認為對您的日常作業影響最大的四種工具,我這里指的是 console-consumer、console-producer、dump-log 以及 delete-records 四個工具,
Kafka console producer
console-producer 允許我們直接從命令列生成主題的記錄,當我們還沒有為主題生成資料時,從命令列生成資料是快速測驗新的消費者應用程式的一種好方法,要啟動 console producer,可以直接運行以下命令:
kafka-console-producer --topic --broker-list <broker-host:port>
執行這個命令后,將出現一個空提示,等待我們的輸入,只需鍵入一些字符,然后按 Enter 即可生成一條訊息,
以這種方式發送訊息不會發送任何 Key,僅會發送訊息的值,幸運的是,kafka-console-producer 為我們提供了一種發送 Key 的方法,我們只需要使用以下命令就可以:
kafka-console-producer --topic \
--broker-list <broker-host:port> \
--property parse.key=true \
--property key.separator=":"
key.separator 屬性可以設定任意的字符,現在,我們可以從命令列發送完整的鍵/值對!如果我們使用 Confluent Schema Registry,那么還可以使用這個工具生成 Avro、Protobuf 和 JSON 模式的訊息,
Kafka console consumer
console consumer 可讓我們直接從命令列消費 Kafka 主題中的記錄,對于原型設計或除錯來說是非常寶貴的工具,假設我們構建了一個新的微服務,要快速確認生產者應用程式正在發送訊息,我們可以簡單地運行以下命令:
kafka-console-consumer --topic --bootstrap-server <broker-host:port>
運行此命令后,我們將開始看到訊息在螢屏上滾動(只要當前正在為該主題生成資料),如果要從頭開始查看所有訊息,可以在命令中添加 --from-beginning 標志,然后我們將可以查看到這個主題的所有訊息,
如果我們使用了 Schema Registry,則有一些特殊的 console-consumer(kafka-protobuf-console-consumer、kafka-json-schema-console-consumer) 可用于消費 Avro,Protobuf 和 JSON Schema 編碼的記錄,Schema Registry console-consumer 用于處理 Avro,Protobuf 或 JSON 格式的記錄,而普通的 console-consumer 則用于處理原始 Java 型別的記錄:字串,長整數,雙精度,整數等,普通 console-consumer 的值是 String型別,
如果鍵或值不是字串,則需要通過命令列標記(--key-deserializer 和 --value-deserializer)提供反序列化器,這些反序列化器必須是帶包名的類,
你可能已經注意到,默認情況下,console-consumer 僅將訊息的值部分列印到螢屏上,如果還想查看對應訊息的 Key,則可以通過包含必要的標志來實作:
kafka-console-consumer --topic \
--bootstrap-server <broker-host:port> \
--property print.key=true
--property key.separator=":"
和 console-producer 一樣,key.separator 引數的值也是任意的字符,
Dump log
有時,當我們使用 Kafka 時,可能會發現自己需要手動檢查主題的底層日志,無論你只是好奇 Kafka 內部還是你需要除錯一個問題并驗證內容,kafka-dump-log 命令都是你的朋友,下面介紹如何使用這個命令,該示例的主題名為 example:
kafka-dump-log \
--print-data-log \
--files ./iteblog/kafka/data/example-0/00000000000000000000.log
?--print-data-log 標記指定列印 log 里面的資料;?--files 標記是必選項,可以是逗號分隔的檔案串列,
如果想查看 kafka-dump-log 命令的所有支持的選項,可以使用 --help,運行上面的命令可以得到以下的輸出:
Dumping ./var/lib/kafka/data/example-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1599775774460 size: 81 magic: 2 compresscodec: NONE crc: 3162584294 isvalid: true
| offset: 0 CreateTime: 1599775774460 keysize: 3 valuesize: 10 sequence: -1 headerKeys: [] key: 887 payload: -2.1510235
baseOffset: 1 lastOffset: 9 count: 9 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 81 CreateTime: 1599775774468 size: 252 magic: 2 compresscodec: NONE crc: 2796351311 isvalid: true
| offset: 1 CreateTime: 1599775774463 keysize: 1 valuesize: 9 sequence: -1 headerKeys: [] key: 5 payload: 33.440664
| offset: 2 CreateTime: 1599775774463 keysize: 8 valuesize: 9 sequence: -1 headerKeys: [] key: 60024247 payload: 9.1408728
| offset: 3 CreateTime: 1599775774463 keysize: 1 valuesize: 9 sequence: -1 headerKeys: [] key: 1 payload: 45.348946
| offset: 4 CreateTime: 1599775774464 keysize: 6 valuesize: 10 sequence: -1 headerKeys: [] key: 241795 payload: -63.786373
| offset: 5 CreateTime: 1599775774465 keysize: 8 valuesize: 9 sequence: -1 headerKeys: [] key: 53596698 payload: 69.431393
| offset: 6 CreateTime: 1599775774465 keysize: 8 valuesize: 9 sequence: -1 headerKeys: [] key: 33219463 payload: 88.307875
| offset: 7 CreateTime: 1599775774466 keysize: 1 valuesize: 9 sequence: -1 headerKeys: [] key: 0 payload: 39.940350
| offset: 8 CreateTime: 1599775774467 keysize: 5 valuesize: 9 sequence: -1 headerKeys: [] key: 78496 payload: 74.180098
| offset: 9 CreateTime: 1599775774468 keysize: 8 valuesize: 9 sequence: -1 headerKeys: [] key: 89866187 payload: 79.459314
dump-log 命令提供了大量資訊,您可以清楚地看到每個記錄的鍵、payload (值)、偏移量和時間戳,需要注意的是,上面輸出的資料來自僅包含10條訊息的演示主題,因此對于真實主題,將有更多的資料,另外,在本例中,主題的鍵和值都是字串,如果要使用非字串的鍵或值型別,可以在運行 kafka-dump-log 命令的時候加上 --key-decoder-class 或 --value-decoder-class 標記即可,
Delete records
Kafka 將主題記錄存盤在磁盤上,即使消費者已經讀取了這些資料,它也會保留這些資料,然而,記錄不是存盤在一個大檔案中,而是按磁區分為多個分段( segments),其中偏移量的順序在同一主題磁區的各個分段之間是連續的,由于服務器的存盤不可能無限大,因此 Kafka 提供了一些設定,用于根據時間和大小來控制保留多少資料:
控制資料保留的時間配置為 log.retention.hours ,默認為168小時(一周);log.retention.bytes 引數控制 segments 在洗掉之前可以增加到多少,但是,log.retention.bytes 的默認設定是-1,這使日志段的大小不受限制,如果您不小心并且沒有配置保留大小以及保留時間,則可能會出現磁盤空間用完的情況,請記住,您永遠不要進入檔案系統并手動洗掉檔案,相反,我們希望有一種受控且受支持的方式從主題中洗掉記錄,以釋放空間,幸運的是,Kafka 附帶了一個工具,可以根據需要洗掉資料,
kafka-delete-records 有兩個主要的引數:
?--bootstrap-server:需要連接的 brokers 地址;?--offset-json-file:包含洗掉配置的 Json 檔案,下面是 JSON 檔案的示例:
{
"partitions": [
{
"topic": "example",
"partition": 0,
"offset": -1
}
],
"version": 1
}
正如你所看到的,JSON 檔案的格式非常簡單,它其實是一個 JSON 物件陣列,每個 JSON 物件有以下三個屬性:
?Topic:需要洗掉資料的主題;?Partition:需要洗掉的磁區;?Offset:需要從什么偏移量洗掉資料,將會把小于這個偏移量的資料洗掉,
上面示例中,我洗掉 example 主題的磁區 0 的資料,example 主題只包含10條記錄,所以您可以很容易地計算啟動洗掉程序的起始偏移量,但在實踐中,你很可能不知道應該使用哪種偏移量,還要記住 offset != message number,因此不能直接從“message 42”中洗掉,如果您將這個值設定為 -1,這意味著您將洗掉主題中所有資料,可以使用下面命令來洗掉主題的資料:
kafka-delete-records --bootstrap-server <broker-host:port> \
--offset-json-file offsets.json
運行完這個命令之后,你可以在控制臺看到以下的輸出:
Executing records delete operation
Records delete operation completed:
partition: example-0 low_watermark: 10
命令的結果表明,Kafka 從主題磁區 example-0 洗掉了所有記錄,low_watermark=10表示可供消費者使用的最低偏移量,因為示例主題中只有10條記錄,所以我們知道偏移量的范圍是0到9,并且沒有消費者可以再次讀取這些記錄,
Tip #5: 使用訊息頭的強大功能
Apache Kafka 0.11引入了記錄頭的概念,記錄標題使您能夠添加一些有關Kafka記錄的元資料,而無需在記錄本身的鍵/值對中添加任何額外的資訊,考慮是否要在訊息中嵌入一些資訊,例如資料所源自的系統的識別符號,也許您希望這樣做是為了沿襲和審核目的,以便于向下游路由資料,Apache Kafka 0.11 引入了訊息頭的概念,訊息頭讓你能夠添加一些關于 Kafka 記錄的元資料,而不需要向記錄本身的鍵/值對添加任何額外的資訊,考慮是否要在訊息中嵌入一些資訊,例如資料所源自系統的識別符號,這樣我們可以做一些審計相關的統計,
Adding headers to Kafka records
下面是使用 Java 代碼給 ProducerRecord 添加訊息頭:
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("bizops", "value");
producerRecord.headers().add("client-id", "2334".getBytes(StandardCharsets.UTF_8));
producerRecord.headers().add("data-file", "incoming-data.txt".getBytes(StandardCharsets.UTF_8));
// Details left out for clarity
producer.send(producerRecord);
Retrieving headers
可以使用下面命令在消費端來消費頭資訊
//Details left out for clarity
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
for (Header header : consumerRecord.headers()) {
System.out.println("header key " + header.key() + "header value " + new String(header.value()));
}
}
當然,我們也可以使用 kafkacat 來從命令列上查看訊息的頭資訊:
kafkacat -b kafka-broker:9092 -t my_topic_name -C \
-f '\nKey (%K bytes): %k
Value (%S bytes): %s
Timestamp: %T
Partition: %p
Offset: %o
Headers: %h\n'
本文翻譯自:Top 5 Things Every Apache Kafka Developer Should Know - https://www.confluent.io/blog/5-things-every-kafka-developer-should-know/#kafka-console-consumer
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278013.html
標籤:AI
上一篇:我眼中的線性代數