volatile
- JMM
- 重排序
- JMM記憶體屏障
- volatile關鍵字
- 作用
- 原理
- DCL單例再剖析
- 位元組碼層面
- JVM原始碼層面
- cpu的lock指令
- 匯編層面
- 常見問題
- volatile能不能保證原子性?
- volatile是否能保證陣列中元素的可見性?
- 參考書籍
本文的volatile是Java中的,虛擬機默認是hotspot,默認是英特爾x86_64處理器.同時希望你有Java多執行緒的基礎和Java虛擬機的相關知識 如果發現本文有錯誤,煩請告知
JMM
上一篇文章萬字長文深入剖析快取一致性協議(MESI),記憶體屏障我們花了大量的篇幅講述快取一致性協議,明白快取一致性協議確保了一個處理器對某個記憶體地址進行的寫操作的結果能夠被其他處理器讀取,但并不能保證一個處理器對共享變數所做的更新具體在什么時候能夠被其他處理器讀取,比如Store Buffer,Invalidate Queue的存在可能導致一個處理器讀取到共享變數的舊值,為了解決這個問題,又引入了記憶體屏障,但是由于多種處理器架構的存在,它們對有序性的保障也各不相同,例如x86處理器僅支持StoreLoad重排序,而ARM處理器支持四種重排序,
這篇文章我們回到Java的世界,Java作為一個跨平臺(跨作業系統和硬體)的語言,為了屏蔽不同處理器的差異,避免Java程式員根據不同的處理器撰寫不同的代碼,定義了Java記憶體模型(Java Memory Model),簡稱JMM,Java記憶體模型是一套規范,描述了Java程式中各種變數(執行緒共享變數)的訪問規則,以及在JVM中將變數存盤到記憶體和從記憶體中讀取變數這樣的底層細節,
Java記憶體模型規定了所有的變數都存盤在主記憶體中,每條執行緒還有自己的作業記憶體,執行緒的作業記憶體中保存了該執行緒中是用到的變數的主記憶體副本拷貝,執行緒對變數的所有操作都必須在作業記憶體中進行,而不能直接讀寫主記憶體,不同的執行緒之間也無法直接訪問對方作業記憶體中的變數,執行緒間變數的傳遞均需要自己的作業記憶體和主存之間進行資料同步進行,
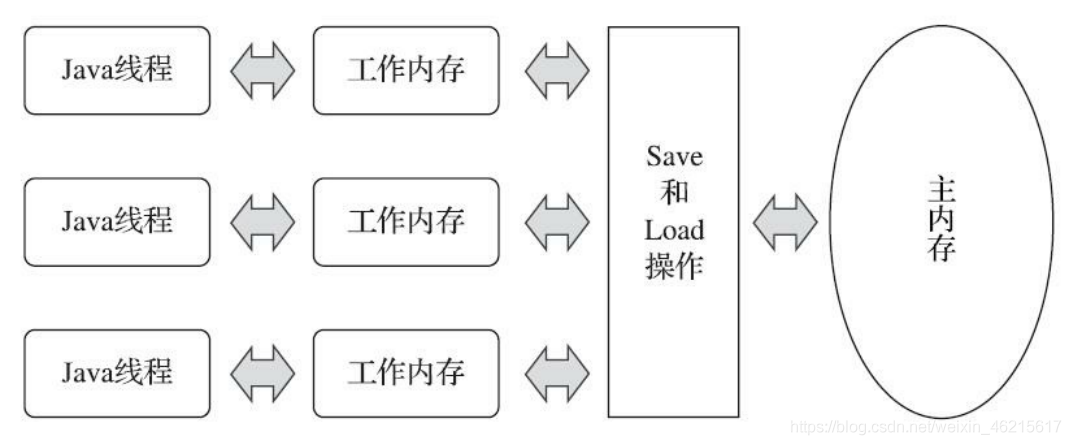
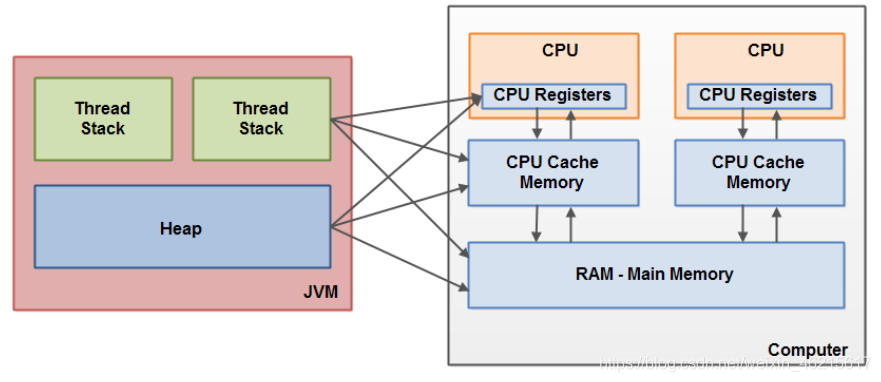
這里面提到的主記憶體和作業記憶體,可以簡單的類比成計算機記憶體模型中的主存和快取的概念,特別需要注意的是,主記憶體和作業記憶體與JVM記憶體結構中的Java堆、堆疊、方法區等并不是同一個層次的記憶體劃分,無法直接類比,如果兩者一定要勉強對應起來,那么從變數、主記憶體、作業記憶體的定義來看,主記憶體主要對應于Java堆中的物件實體資料部分,而作業記憶體則對應于虛擬機堆疊中的部分區域,但這也只是大致劃分,從更基礎的層次上說,主記憶體直接對應于物理硬體的記憶體,而為了獲取更好的運行速度,虛擬機(或者是硬體、作業系統本身的優化措施)可能會讓作業記憶體優先存盤于暫存器和高速快取中,因為程式運行時主要訪問的是作業記憶體,
重排序
在執行程式時,為了提高性能,在不影響程式(單執行緒程式)正確性的情況下,編譯器和處理器常常會對指令做重排序,重排序分3 種型別,
- 編譯器優化的重排序,編譯器在不改變單執行緒程式語意的前提下,可以重新安排陳述句的執行順序,
- 指令級并行的重排序,現代處理器采用了指令級并行技術(Instruction-Level Parallelism,ILP)來將多條指令重疊執行,如果不存在資料依賴性,處理器可以改變陳述句 對應機器指令的執行順序,
- 記憶體系統的重排序,由于處理器使用快取和讀/寫緩沖區,這使得加載和存盤操作看上去可能是在亂序執行, 從Java源代碼到最終實際執行的指令序列,會分別經歷下面3種重排序,

Java平臺目前有兩種編譯器: - 前端編譯器(javac):將Java源代碼(.java檔案)編譯為位元組碼(.class二進制檔案),它基本上不會進行指令重排序,
- 后端編譯器(比如JIT編譯器):在HotSpot中,內部同時含有解釋器和編譯器(將Java代碼編譯成匯編代碼),JDK10以前,JIT編譯器包括Client Compiler(C1編譯器,進行簡單可靠的優化)和Server Compiler(C2編譯器,優化策略比較激進),JDK7及以后,默認情況下使用分層編譯,解釋器、Client Compiler和Server Compiler同時作業,
public class ReorderDemo {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; ; i++) {
x = 0; y = 0;
a = 0; b = 0;
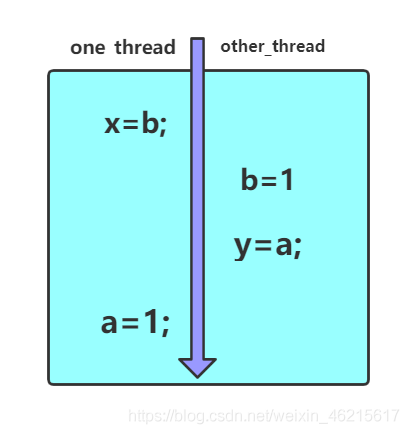
Thread one = new Thread(() -> {
a = 1;
x = b;
});
Thread other = new Thread(() -> {
b = 1;
y = a;
});
one.start();
other.start();
//主執行緒在這堵塞,等待one執行緒執行完畢
one.join();
//主執行緒在這堵塞,等待other執行緒執行完畢,可能此時other執行緒已經執行完畢
other.join();
if (x == 0 && y == 0) {
String result = "第" + i + "次(" + x + ", " + y + ")";
System.out.println(result);
}
}
}
}
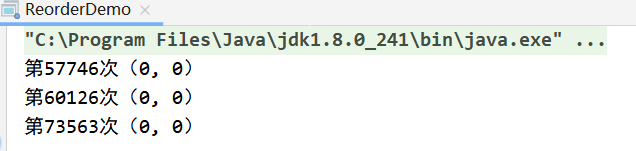
按照正常的結果是不會出現(0,0)這個結果的,這種現象只有在x=b跑到a=1前面,并且b=1和y=a在a=1前面執行才有可能產生,以上實驗結果證明了指令確實進行重排,
對于編譯器,JMM的編譯器重排序規則會禁止特定型別的編譯器重排序(不是所有的編譯器重排序都要禁止),對于2和3,JMM的處理器重排序規則會要求Java編譯器在生成指令序列時,插入特定型別的記憶體屏障指令,通過記憶體屏障指令來禁止特定型別的處理器重排序,
JMM記憶體屏障
JVM 一共提供了四種 Barrier,比如 LoadLoad Barrier 就是放在兩次 Load 操作中間的 Barrier,LoadStore 就是放在 Load 和 Store 中間的 Barrier,具體如下:
| 屏障型別 | 指令示例 | 說明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 用于保證訪問 Load2 的讀取操作一定不能重排到 Load1 之前,類似于前面說的 Read Barrier,需要先處理 Invalidate Queue 后再讀 Load2; |
| StoreStore Barriers | Store1;StoreStore;Store2 | 用于保證 Store1 及其之后寫出的資料一定先于 Store2 寫出,即別的 CPU 一定先看到 Store1 的資料,再看到 Store2 的資料,可能會有一次 Store Buffer 的刷寫,也可能通過所有寫操作都放入 Store Buffer 排序來保證; |
| LoadStore Barriers | Load1;LoadStore;Store2 | 用于保證 Store2 及其之后寫出的資料被其它 CPU 看到之前,Load1 讀取的資料一定先讀入快取,甚至可能 Store2 的操作依賴于 Load1 的當前值, |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 用于保證 Store1 寫出的資料被其它 CPU 看到后才能讀取 Load2 的資料到快取,如果 Store1 和 Load2 操作的是同一個地址,StoreLoad Barrier 需要保證 Load2 不能讀 Store Buffer 內的資料,得是從記憶體上拉取到的某個別的 CPU 修改過的值,StoreLoad 一般會認為是最重的 Barrier ,它會清空Invalidate Queue并將Store Buffer中的內容寫入高速快取,即StoreLoad屏障能夠實作其他三個基本記憶體屏障的效果 |
這四個 Barrier 只是 Java 為了跨平臺而設計出來的,實際上根據 CPU 的不同,對應 CPU 平臺上的 JVM 可能會優化掉一些 Barrier,比如在 x86 平臺的JVM上只剩下一個 StoreLoad Barrier被使用,
volatile關鍵字
volatile有不穩定的意思,在Java中,volatile關鍵字用于修飾沒有final關鍵字修飾的實體變數或靜態變數,這些變數一般是共享可變的,即一個變數可能被多個執行緒訪問(讀/寫),值容易發生變化,因而不穩定,
作用
volatile關鍵字的作用包括:保證可見性,保證有序性和保證long/double型變數讀寫操作的原子性
- 可見性:每次讀 volatile 變數總能讀到它的最新值,即最后一個執行緒對它的寫入操作,不管這個寫入是不是當前執行緒完成的,
- 有序性: 對一個volatile變數的寫操作,先發生于后面任何地方對這個變數的讀操作,編譯器會放棄對volatile變數做任何冒進的優化,從而禁止了編譯器層面的指令重排序,同時在生成匯編指令時在相應的位置插入記憶體屏障,也禁止了cpu層面和記憶體層面的指令重排序,禁止指令重排不是禁止所有的重排,只是 volatile 寫入不能向前排,讀取不能向后排,別的重排還是會允許,
- 原子性:在Java語言中,long/double型的變數為8個位元組,即64位,對long/double型以外的任何型別變數的寫操作都是原子操作,在JMM中,允許虛擬機將沒有被volatile修飾的64位資料的讀寫劃分為兩次32位的操作,如果有多個執行緒共享一個并未宣告為volatile的long/double型別的變數,并同時對它們進行修改與讀取,那么某些執行緒可能讀到例外的值,但這非常罕見,主流的64位商用虛擬機并不會出現這種情況,32位的虛擬機出現這種情況的概率也不大,
原理
JMM針對編譯器制定的volatile重排序規則表如下:
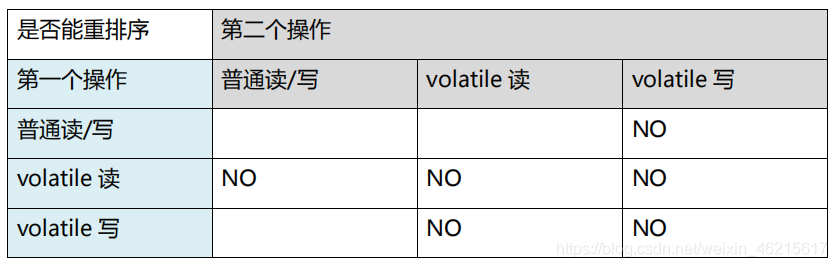
舉例來說,第三行最后一個單元格的意思是:在程式中,當第一個操作為普通變數的讀或寫時,如果第二個操作為volatile寫,則編譯器不能重排序這兩個操作,
- 當第二個操作是volatile寫時,不管第一個操作是什么,都不能重排序,這個規則確保volatile寫之前的操作不會被編譯器重排序到volatile寫之后,
- 當第一個操作是volatile讀時,不管第二個操作是什么,都不能重排序,這個規則確保volatile讀之后的操作不會被編譯器重排序到volatile讀之前,
- 當第一個操作是volatile寫,第二個操作是volatile讀時,不能重排序,
在 JSR-133 Cookbook中提出幾乎無法找到一個“最理想”位置,將記憶體屏障個數降到最小,因此JMM采取了保守策略,以保證在任意處理器平臺,任意的程式都能得到正確的volatile語意,
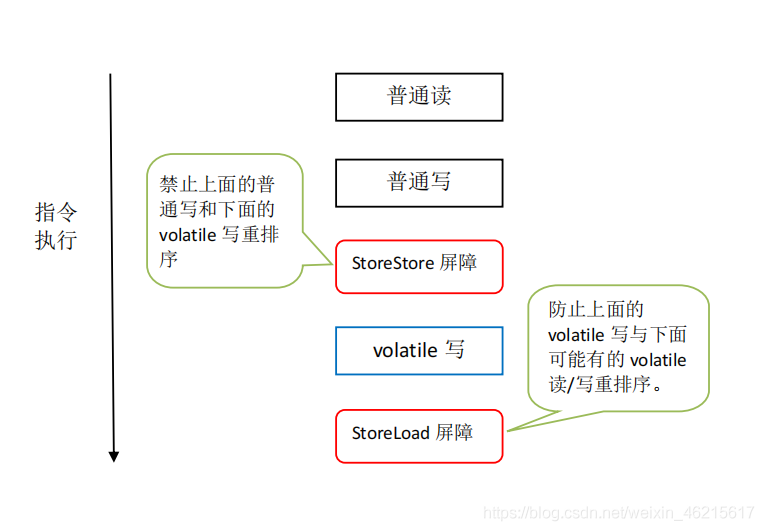
- 在每個volatile寫操作的前面插入一個StoreStore屏障,
- 在每個volatile寫操作的后面插入一個StoreLoad屏障,雖然也可以在每條volatile load指令之前插入一個StoreLoad屏障,但對于使用volatile的典型程式來說則會更慢,因為讀操作會大大超過寫操作,
- 當volatile store后面是一個return時, 此時編譯器可能無法準確斷定后面是否會有volatile讀或寫,為了安全起見,編譯器通常會在這里插入一個StoreLoad屏障
- 在每個volatile讀操作的后面插入一個LoadLoad屏障和一個LoadStore屏障,
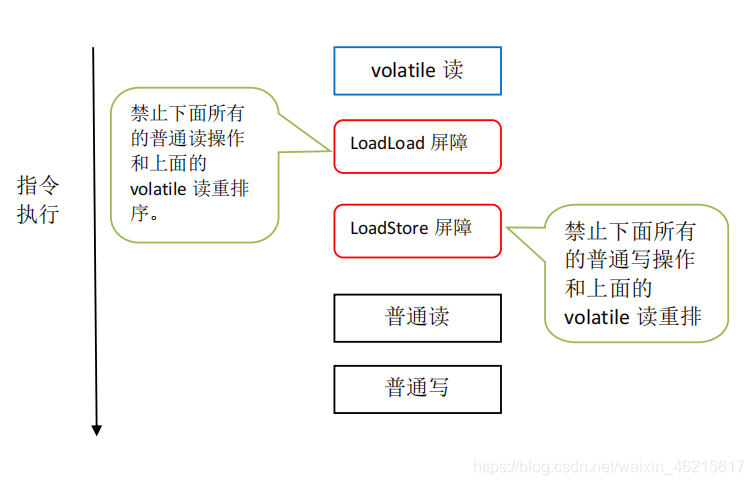
上述volatile寫和volatile讀的記憶體屏障插入策略非常保守,在實際執行時,只要不改變 volatile寫-讀的記憶體語意,編譯器可以根據具體情況省略不必要的屏障
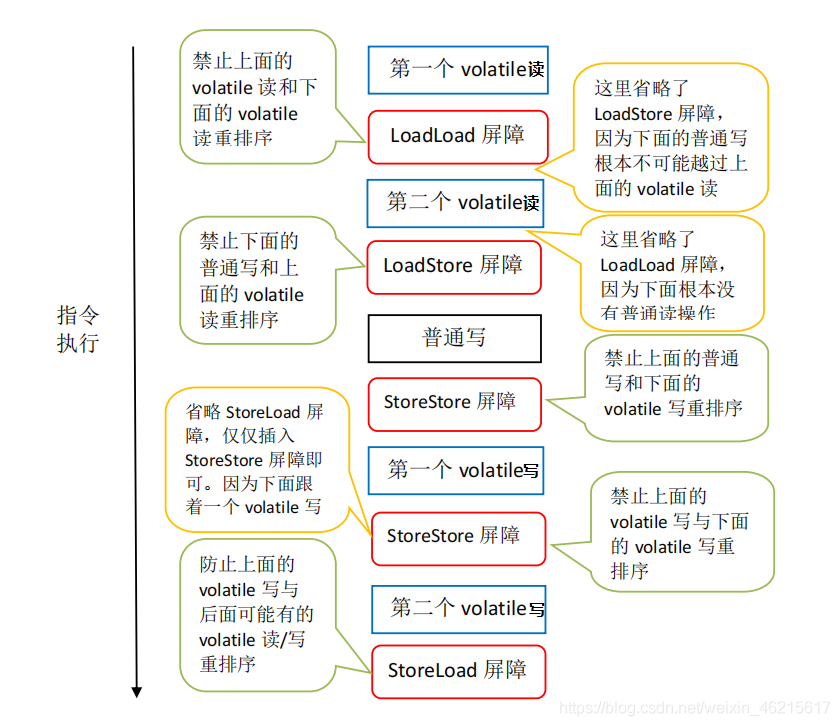
大部分時候可以簡化為下面的表:


由于x86處理器僅支持StoreLoad重排序,因此在x86處理器上Java虛擬機會將LoadLoad記憶體屏障,LoadStore記憶體屏障以及StoreStore記憶體屏障映射為空指令,也就是說只需要在volatile寫操作后插入一個StoreLoad記憶體屏障,其它的都不用管,
DCL單例再剖析
在設計模式——單例模式(Singleton Pattern)這篇文章中,深入講解了各種單例模式,其中Double Check Lock單例模式有一個問題
public class Singleton {
private volatile static Singleton singleton = null;
private Singleton(){
}
public static Singleton getInstance(){
if (singleton == null){
synchronized (Singleton.class){
if (singleton == null){
singleton = new Singleton();
}
}
}
return singleton;
}
}
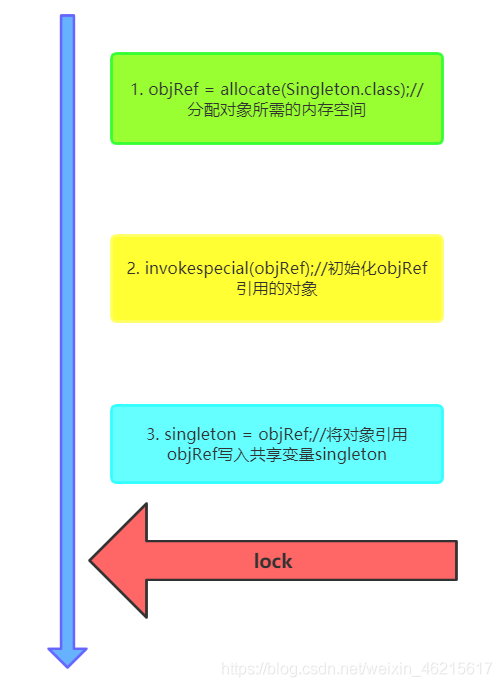
在Java中,singleton = new Singleton();這個操作會分解為以下偽代碼所示的幾個獨立子操作:
- objRef = allocate(Singleton.class);//分配物件所需的記憶體空間
- invokespecial(objRef);//初始化objRef參考的物件
- singleton = objRef;//將物件參考objRef寫入共享變數singleton
其中volatile關鍵字 僅保障子操作3是一個原子操作,但是由于子操作1和子操作2僅涉及區域變數而未涉及共享變數,因此對變數singleton的賦值操作仍可以看作是一個原子操作,
由于volatile能夠禁止volatile變數寫操作與該操作之前的任何讀,寫操作進行重排序,因此,用volatile修飾singleton相當于禁止JIT編譯器以及處理器將子操作2,3進行重排序,這就保障了一個執行緒讀取到singleton變數所參考的實體時該實體已經初始化完成,
位元組碼層面
通過javac Singleton.java將類編譯為class檔案,再通過javap -v -p Singleton.class命令反編譯查看位元組碼檔案,-p的作用是顯示所有類與成員
D:\JavaSE\JavaProject\design-pattern\src\main\java>javap -p -v Singleton.class
Classfile /D:/JavaSE/JavaProject/design-pattern/src/main/java/Singleton.class
Last modified 2021-4-19; size 509 bytes
MD5 checksum fc6fcd094d2d9cdf0edd20d59c6b0d22
Compiled from "Singleton.java"
public class Singleton
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #5.#20 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#21 // Singleton.singleton:LSingleton;
#3 = Class #22 // Singleton
#4 = Methodref #3.#20 // Singleton."<init>":()V
#5 = Class #23 // java/lang/Object
#6 = Utf8 singleton
#7 = Utf8 LSingleton;
#8 = Utf8 <init>
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 getInstance
#13 = Utf8 ()LSingleton;
#14 = Utf8 StackMapTable
#15 = Class #23 // java/lang/Object
#16 = Class #24 // java/lang/Throwable
#17 = Utf8 <clinit>
#18 = Utf8 SourceFile
#19 = Utf8 Singleton.java
#20 = NameAndType #8:#9 // "<init>":()V
#21 = NameAndType #6:#7 // singleton:LSingleton;
#22 = Utf8 Singleton
#23 = Utf8 java/lang/Object
#24 = Utf8 java/lang/Throwable
{
private static volatile Singleton singleton;
descriptor: LSingleton;
flags: ACC_PRIVATE, ACC_STATIC, ACC_VOLATILE
private Singleton();
descriptor: ()V
flags: ACC_PRIVATE
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
line 5: 4
public static Singleton getInstance();
descriptor: ()LSingleton;
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=0
0: getstatic #2 // Field singleton:LSingleton;
3: ifnonnull 37
6: ldc #3 // class Singleton
8: dup
9: astore_0
10: monitorenter
11: getstatic #2 // Field singleton:LSingleton;
14: ifnonnull 27
17: new #3 // class Singleton
20: dup
21: invokespecial #4 // Method "<init>":()V
24: putstatic #2 // Field singleton:LSingleton;
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field singleton:LSingleton;
40: areturn
Exception table:
from to target type
11 29 32 any
32 35 32 any
LineNumberTable:
line 7: 0
line 8: 6
line 9: 11
line 10: 17
line 12: 27
line 14: 37
StackMapTable: number_of_entries = 3
frame_type = 252 /* append */
offset_delta = 27
locals = [ class java/lang/Object ]
frame_type = 68 /* same_locals_1_stack_item */
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
static {};
descriptor: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: aconst_null
1: putstatic #2 // Field singleton:LSingleton;
4: return
LineNumberTable:
line 2: 0
}
SourceFile: "Singleton.java"

volatile在位元組碼層面,就是使用訪問標志:ACC_VOLATILE來表示,供后續操作此變數時判斷訪問標志是否為ACC_VOLATILE,來決定是否遵循volatile的語意處理,
下面看一下getInstance()方法的位元組碼:
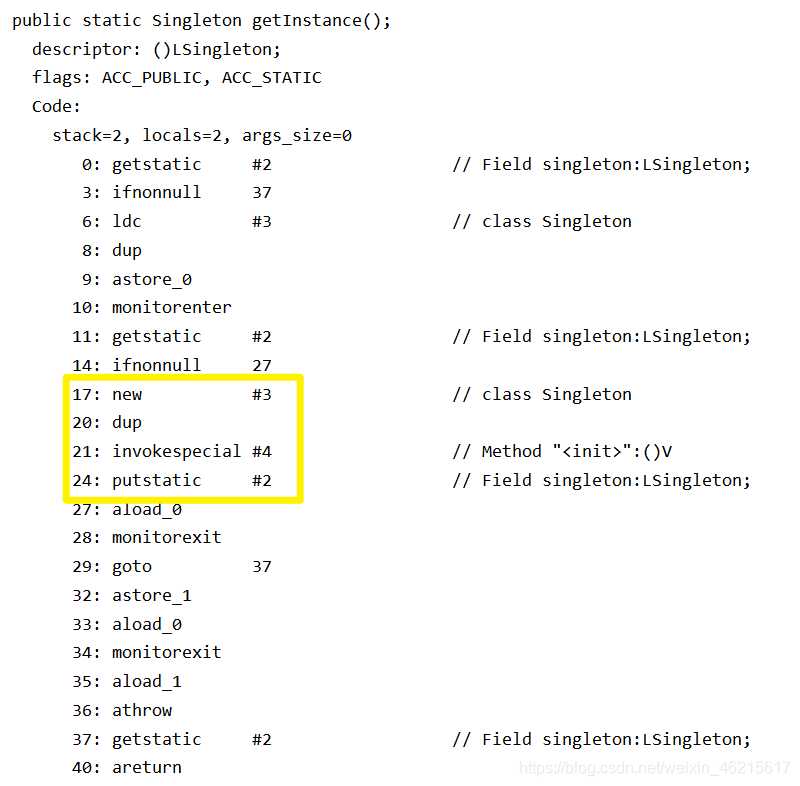
下面簡單介紹黃框里面的四個位元組碼指令:
- new:首先進行類加載檢查,通過后,虛擬機會給新生物件分配記憶體(把一塊確定大小的記憶體塊從Java堆中劃分出來)并將它所有的實體變數都會初始化為相應型別的初始值,隨后一個代表該實體的reference型別資料objRef將壓入運算元堆疊,即完成
objRef = allocate(Singleton.class), - invokespecial:用于呼叫一些需要特殊處理的實體方法,包括實體初始化方法、私有方法和父類方法,在這里呼叫Class檔案的
<init>方法,對物件進行初始化,這時一個真正可用的物件才算真正被構造出來,即完成invokespecial(objRef), - pustatic:設定類的靜態欄位值,在上面的例子中,指令執行時,reference型別資料objRef從運算元堆疊出堆疊,將靜態變數
singleton賦值為objRef,即完成singleton = objRef, - dup:將堆疊頂元素復制一份,
這里的細節比較多,如果讀者對這塊不了解,讀一下深入理解Java虛擬機的相關內容,
其實從位元組碼層面,看到的東西很有限,無法看到volatile變數具體怎么起作用的,那我們從hotspot原始碼看一下發生了什么?
JVM原始碼層面
看一下bytecodeInterpreter.cpp中的代碼片段(其實這個解釋器很少用到,大部分平臺用模板解釋器,通過JIT編譯器執行的差異更大,但是看一下運行程序還是沒問題的),這兒簡單看看領會那個意思就行,cpp代碼也看不太懂
在openjdk8根路徑/hotspot/src/share/vm/interpreter路徑下的bytecodeInterpreter.cpp檔案中,處理putstatic和putfield指令的代碼:
CASE(_putfield):
CASE(_putstatic):
......
//
// Now store the result
//
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
}
......
OrderAccess::storeload();
}
//在windows_x86上的具體實作
inline void OrderAccess::loadload() { acquire(); }
inline void OrderAccess::storestore() { release(); }
inline void OrderAccess::loadstore() { acquire(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() {
#ifndef AMD64
__asm {
mov eax, dword ptr [esp];
}
#endif // !AMD64
}
inline void OrderAccess::release() {
//避免不同的執行緒擊中相同的快取行
volatile jint local_dummy = 0;
}
inline void OrderAccess::fence() {
#ifdef AMD64
StubRoutines_fence();
#else
if (os::is_MP()) {
__asm {
// 使用lock指令是因為mfence的代價比較昂貴
// always use locke since mfence is sometimes expensive
lock add dword ptr [esp], 0;
}
}
#endif // AMD64
}
通過上面的代碼可以大體看出,如果發現某個變數是is_volatile(),進行putstatic操作后,會加上storeLoad屏障,且只有fence()里面的內嵌匯編指令加上了lock指令,即在x86處理器上只有StoreLoad屏障有真正記憶體屏障的功能,使用lock而不用mfence是因為mfence的開銷比較大,在原始碼的注釋中也有體現,
cpu的lock指令
在Intel? 64 and IA-32 Architectures Software Developer’s Manual 中給出LOCK指令的詳細解釋
- 在早期的cpu,總是采用鎖總線的方式,即一旦遇到lock指令,就由仲裁器選擇一個核心獨占總線,其余的cpu核心不能通過總線與記憶體通訊,從而達到原子性的目的,但這種方式比較低效,鎖總線的時候其它cpu都不能正常作業了,
- 從Intel P6 CPU(這個處理器比較老了,大約1995出的)開始做了優化,改用RingBus+Mesi協議,如果訪問的記憶體區域已經快取在處理器的快取行中,它會對CPU的高速快取中的快取行進行鎖定,在鎖定期間,其它 CPU 不能同時快取此資料,在修改之后,通過MESI來保證修改的原子性這種技術被稱為快取鎖(Cache Locking),
- 當操作的資料不能被快取在處理器內部或操作的資料跨多個快取行時,也會使用總線鎖
匯編層面
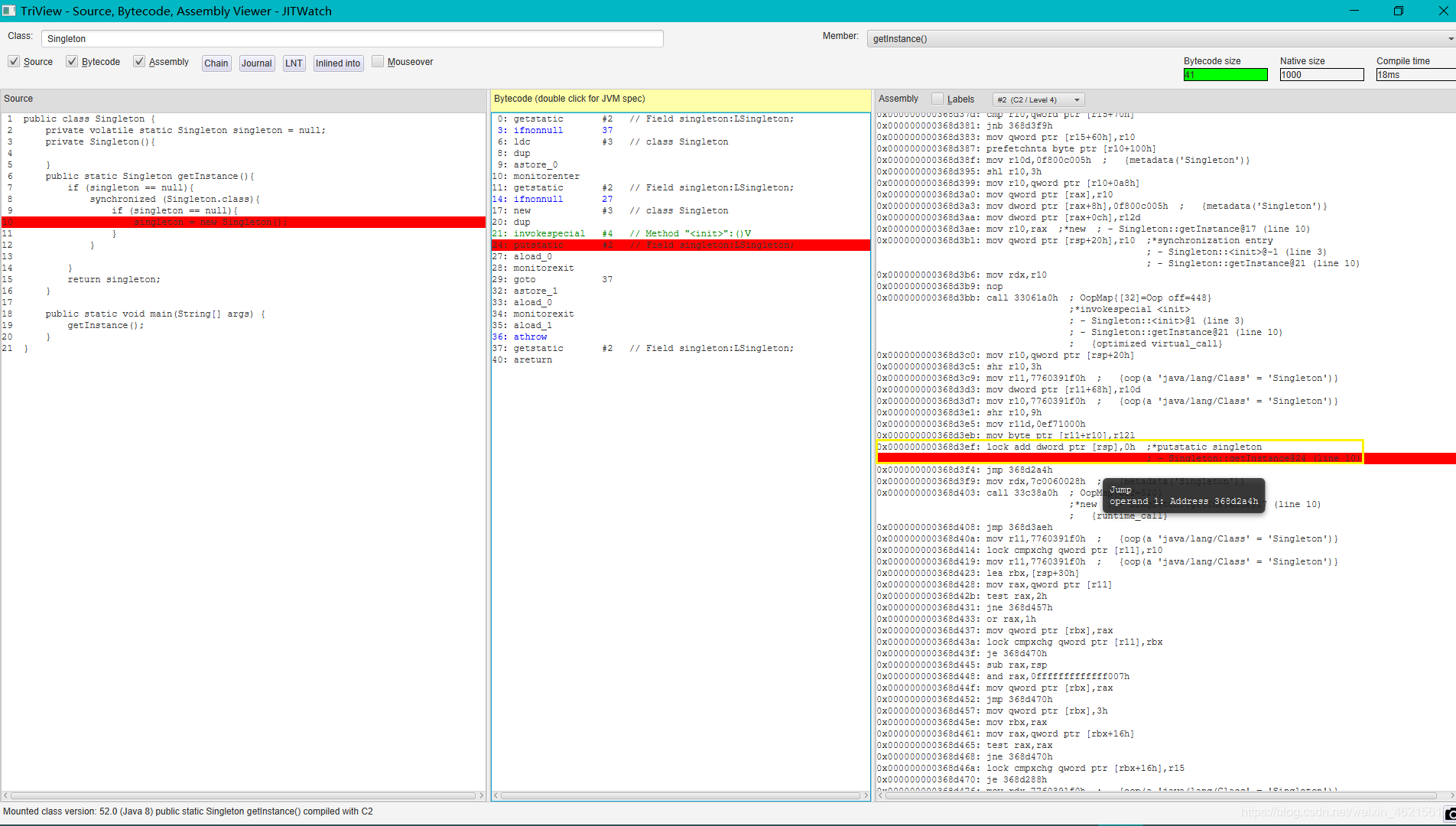
可以看到在賦值操作(putstatic)后執行了一個lock add dword ptr [rsp], 0;,這一句會清空Store Buffer,將資料寫入高速快取(或者記憶體),同時通過快取一致性協議讓其它CPU相關快取行失效,起到了StoreLoad的作用,從而使該指令前面對資料的更新能被其他處理器看到,進而保證了可見性,
常見問題
volatile能不能保證原子性?
public class VolatileAtomicSample {
private volatile static int counter = 0;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
counter++;
}
});
thread.start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("結果為" + counter);
}
}

可以看到,理想的結果應該是10000,但是結果為9368,在Java語言規范中,volatile關鍵字對原子性的保障僅限于共享變數寫和讀操作本身,對共享變數進行的賦值操作往往是一個復合操作,volatile并不能保障這些賦值操作的原子性,例如上面代碼中的i++,它等價于i=i+1;而i是多個執行緒間的共享變數,那一條陳述句就可以分解為如下的幾個子操作:
r1 = i;//將共享變數i的值加載到暫存器r1r2=r2+1;//將暫存器r1的值加1i=r2;//將暫存器r1的值寫入共享變數i(記憶體/快取)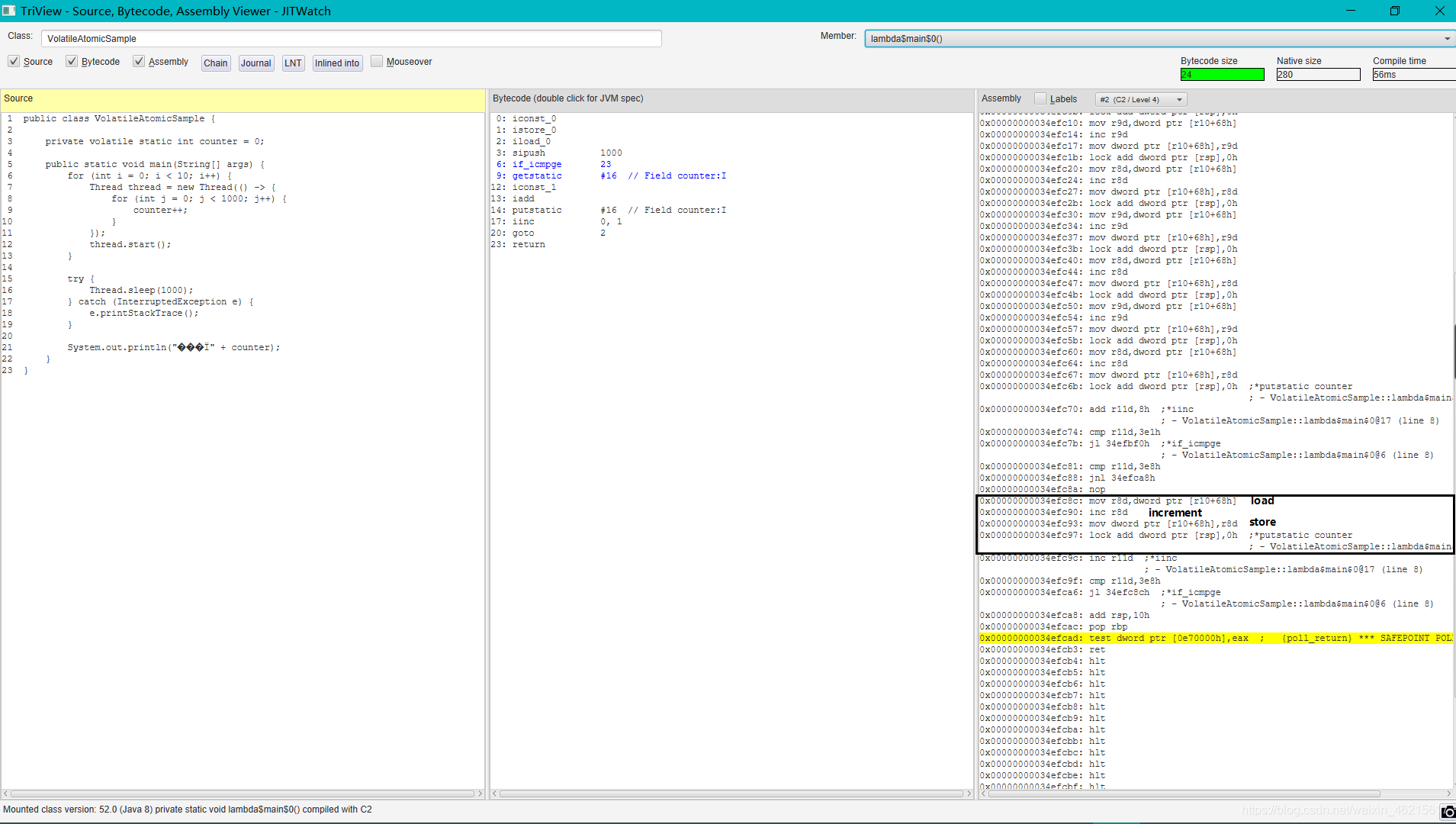
正如上面三行匯編代碼
mov r8d,dword ptr [r10+68h]//把記憶體地址[r10+68h]中的雙字型(dword 32位)資料賦給r8d暫存器inc r8d//inc加1操作mov dword ptr [r10+68h] , r8d//把r8d暫存器中的資料賦給記憶體地址[r10+68h]中的雙字型( 32位)資料
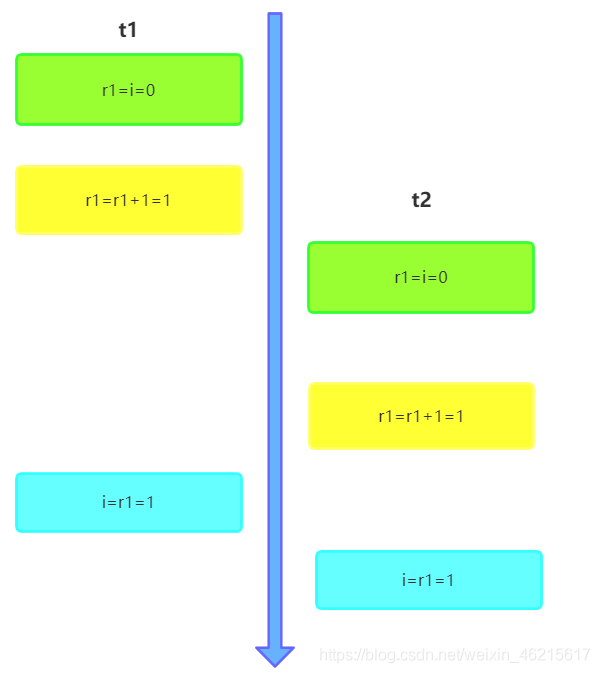
volatile關鍵字并不像鎖那樣具有排他性,在寫操作方面,其對原子性的保障也僅僅作用于上述的子操作3.因此,當一個執行緒在執行到子操作3的時候,其他執行緒可能已經更新了共享變數i的值,這樣就使得子操作3的執行執行緒實際上是向共享變數i寫入了一個舊值,比如下圖,進行兩次加1操作,但最終寫入記憶體的結果最侄訓是1,
volatile是否能保證陣列中元素的可見性?
先說結論,如果被修飾的變數是個陣列,那么volatile關鍵字只能夠對陣列參考本身的操作(讀取陣列參考和更新陣列參考)起作用,而無法對陣列元素的操作(讀取,更新陣列元素)起作用,
比如int i = anArray[0];,可以分解為兩個子步驟
- 先讀取陣列參考(此處就相當于C語言中的指標),這是一個volatile變數讀取操作,它能保障執行緒能夠讀取到陣列地址本身的相對新值,
- 第二步則是在指定的記憶體地址基礎上計算偏移量來讀取陣列元素,它和volatile沒有關系,不能保障讀到的值是相對新值,
而anArray=new int[10];是改變anArray的地址,會觸發volatile關鍵字的作用,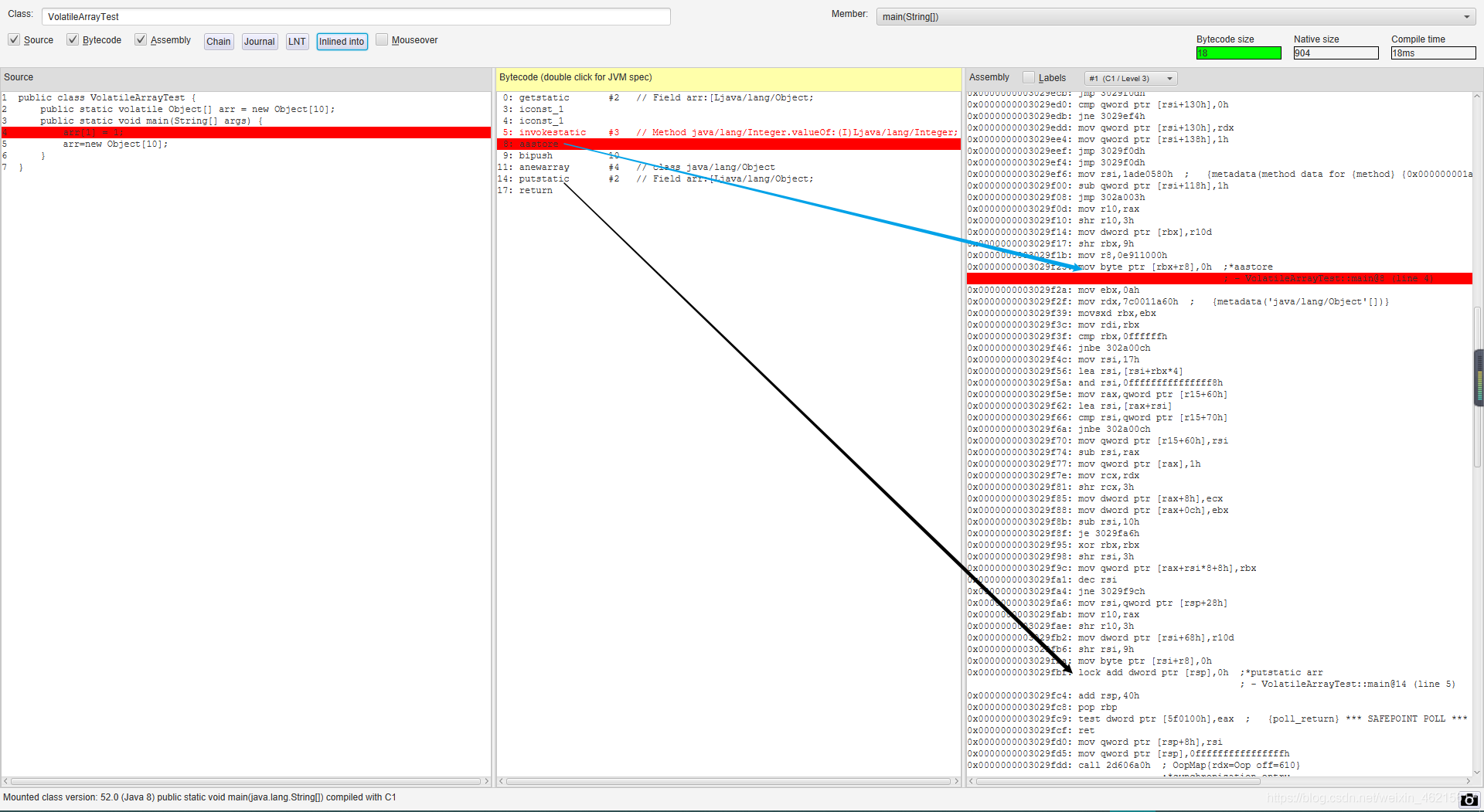
在上圖中,只有修改arr的地址才會生成lock前綴指令,從另一個方面驗證了上面的結論,如果要使對陣列元素的讀,寫也能觸發volatile關鍵字的作用,那么可以用AtomicIntegerArray,AtomicIongArray,AtomicReferenceArray,
參考書籍
[1]周志明.深入理解Java虛擬機(第3版).機械工業出版社,2019.
[2] 黃文海. Java多執行緒編程實戰指南(核心篇).電子工業出版社,2017.
[2] 程曉明. 深入理解Java記憶體模型.InfoQ軟體開發叢書,2018.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278029.html
標籤:其他
下一篇:JavaWeb