前言
配置的虛擬機為Centos6.7系統,hadoop版本為2.6.0版本,先前已經完成搭建CentOS部署Hbase、CentOS6.7搭建Zookeeper和撰寫MapReduce前置插件Hadoop-Eclipse-Plugin 安裝,在此基礎上完成了Hive詳解以及CentOS下部署Hive和Mysql和Spark框架在CentOS下部署搭建,Spark的組件Spark SQL的部署:Spark SQL CLI部署CentOS分布式集群Hadoop上方法,
配置JDK1.8、Scala11.12
本文將介紹DataFrame基礎操作以及實體運用
DataFrame查看資料
Spark DataFrame常用操作函式或方法
| 函式或方法 | 描述 |
| printSchema | 列印資料模式 |
| show | 查看資料 |
| first/head/take/takeAsList | 獲取若干行資料 |
| collect/collectAsList | 獲取所有資料 |
下面將: 檔案轉化為DataFrame進行操作:
檔案轉化為DataFrame進行操作:

1.printSchema:列印資料模式
查看資料模式可以通過printSchema函式來查看,它會答應后出列的名稱和型別,

2.show:查看資料
show相關方法
| 方法 | 介紹 |
| show() | 顯示前20條記錄 |
| show(numRows:Int) | 顯示numRows條記錄 |
| show(truncate:Boolean) | 是否最多只顯示20個字符,默認為true |
| show(numRows:Int,truncate:Boolean) | 顯示numRows條記錄并設定過長字串的顯示格式 |
show():

show(5):

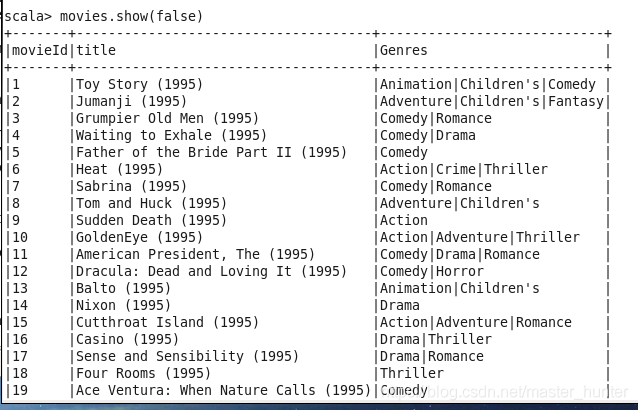
show(false):
3.first/head/take/takeAsList:獲取若干行記錄
DataFrame獲取若干行記錄的方法:
| 方法 | 解釋 |
| first | 獲取第一行記錄 |
| head(n:Int) | 獲取前n行記錄 |
| take(n:Int) | 獲取前n行記錄 |
| takeAsList(n:Int) | 獲取前n行資料,并以List的形式展現 |
first和head功能相同,以Row或者Array[Row]的形式回傳一行或多行資料,


take和takeAsList方法會將獲得的資料回傳到Driver端:

4.collect/collectAsList獲取所有函式
collect方法可以將DataFrame中的所有資料都獲取到,并回傳一個Array物件,collectAsList方法可以獲取所有資料到List:


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278057.html
標籤:其他
下一篇:深入理解計算機系統 第七章:鏈接