腦瓜子嗡嗡的小劉煉丹之路—CenterNet paper Analysis
? ? 嘿嘿嘿,腦瓜子嗡嗡的小劉又來了哦,小劉似乎很久沒有更新了哇,上次要更新的車內車內空氣檢測分析系統,因為這個是我同學的畢業設計所以暫時也不能開源,哈哈哈哈(鴿了就鴿了噻)! 然后呢,小劉最近在忙論文和考研的事情,當然也也筆試了幾家大廠,如位元組跳動這種大廠呢,一定要把資料結構搞清楚,然后就算去刷題,過來人一把心酸了,因為大學沒有學過資料結構,次了虧!(想要筆試型別的可以call me) 雖然而自學了,但是也不過家,不過最近準備要考研這些都會循序漸進的!加油吧,后浪們,卷起來就對了,同為搬磚人,如何把磚搬得更好,這是一門技術!
??CenterNet:是2019年的論文了,其核心思想就如同其論文題目一樣:Objects as Points,將目標看為一個點,相對于anchor base 的網路:YOLO SSD RCNN來說,CenterNet是一種anchor free的Object Detection Convolutional Neural Network,其在速度和精度上面相對于anchor base較為快一點,但是對比兩階段的可能較弱一點,并且CenterNet的可拓展性非常的強,不僅可用于目標檢測,還可以用姿態檢測或3D目標檢測等,
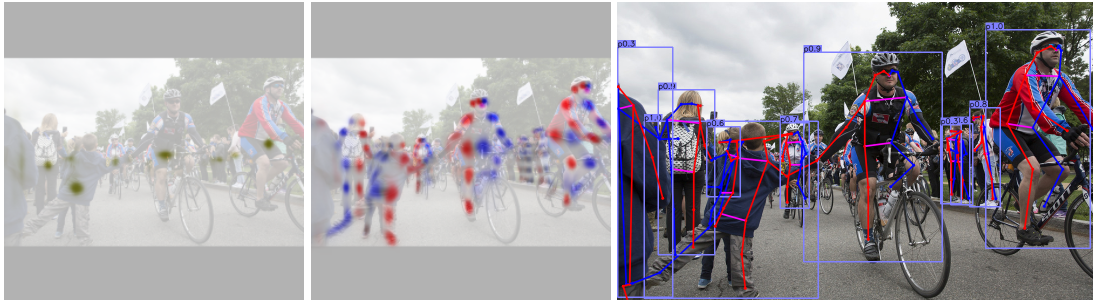
??姿態檢測:估計影像中每個人的k個二維關節點的位置(coco資料為17),將姿態視為中心點的[K?2]維屬性,并對每個關鍵點進行引數化,使其偏離中心點,再使用L1 loss(平滑的作用)直接對關節點偏移量進行回歸,并且通過 masking the loss來忽略看不到的關鍵點,
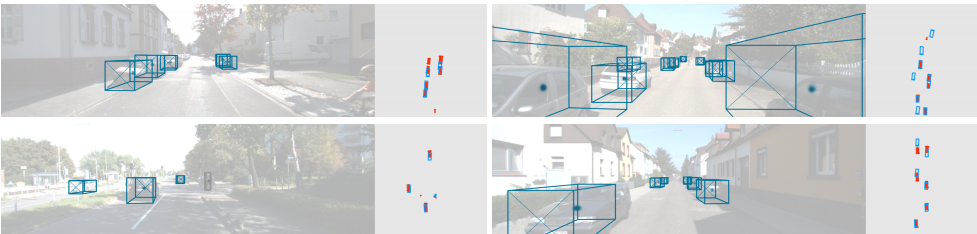
??三維包圍盒估計,需要回歸到目標絕對深度、三維包圍盒尺寸和目標方向等,似乎和YOLO3D非常的不同,YOLO3D中提取了Point的高度、密度、光強(反射率)等特征,分別作為像素值,繼而將得到鳥瞰圖在輸入卷積通道中,而centernet似乎采用的是單目攝像頭,其backbone為DLA-34,同時也是采用L1 loss((平滑的作用)計3Dbox 的長寬高,因為其方向也是單一的數值,很難回歸,CenterNet將方向分成2個bin,每個bin用4個數值表示,每個bin中2個值用于做softmax分類,五個值用于回歸角度,
一、anchor base & anchor free
anchor base
??目標檢測演算法通常會在輸入影像中采樣大量的區域,然后判斷這些區域中是否包含感興趣(Region of interest)的目標,并調整區域邊緣從而更準確地預測目標的真實邊界框(ground-truth bounding box),不同的模型使用的區域采樣方法可能不同,anchor base的方法則是以每個像素為中心生成多個大小和寬高比(aspect ratio)不同的邊界框,這些邊界框被稱為錨框(anchor box),anchor 的設定也講究著方法,也關系著精度問題,YOLO使用Kmeans聚類得到anchor box 的大小,YOLO2是5個anchor box ,V3為9個anchor box , V4為(忘記了),只記得使用的是Mosaic資料增強的方式,anchor感覺和滑窗是類似的,
anchor free
??其大概分為3種方法吧:
??1、基于角點的anchor free :如CornerNet :直接預測每個點是左上、右下角點的概率,通過左上右下角點配對提取目標框,
??2、基于中心點的anchor:如CenterNet:對特征圖的每個位置預測它是目標中心點的概率, 并且在沒有錨框先驗的情況下進行邊框的預測,(本文主要探討的)
?? 3、基于全卷積的anchor free:如FCOS:直接將每個位置的目標邊界框進行回歸,也就是將坐標點而不是錨框作為訓練的樣本,
??小弟我就了解過一點點CenterNet,大哥不懂就去搜索一下,anchor free的出現應該可以歸功于RetinaNet的Focal Loss:較好的解決的樣本的類別不均衡導致的問題,ps:說解決有點太絕對了,哈哈哈哈,
??anchor free 的優點:
???1、不需要設定anchor相關的超引數;
???2、避免大量計算GT boxes和anchor boxes 之間的IoU,計算量更小,(似乎可以用于嵌入式設備上)
???3、相對于anchor base的方法,更加靈活,
二、 CenterNet
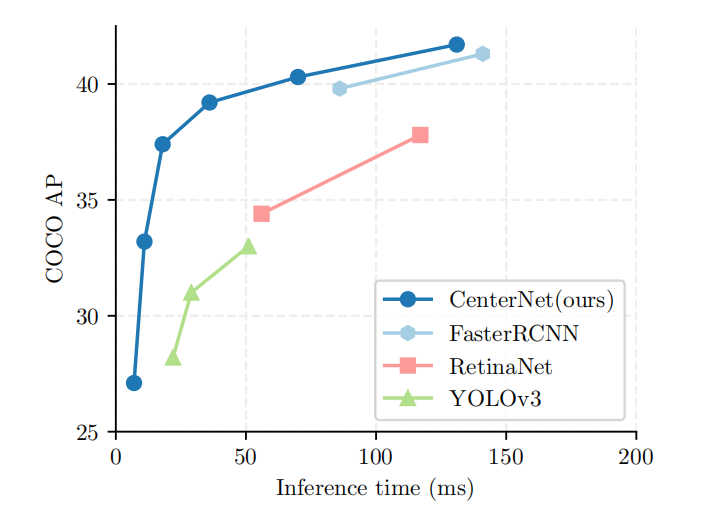
??首先來看一張圖吧,在COCO資料集上CenterNet的AP(Average precision)遠遠的大于了YOLO,FasterRCNN,RetinaNet等網路,因為是2019年的論文了,沒有和YOLOV4,V5 等SOTA網路進行對比,并且現在CenterNet-V2也出來蠻久的了,CenterNet-V2為二階的檢測器(我沒看),要對比的自己可以去做一下實驗,菜雞🐥的我就不做了,ps:這個大哥似乎做了,可以去看看,push here就ojbk了
|
|
object as the center point
??前面我們說到,CenterNet的核心就算將object view as a point,主要是利用了目標的中心點,其他如:目標的大小,維度,方向和姿態都可以直接從中心位置的影像特征回歸,并且其采用Heatmap,Heatmap峰值對于物件的中心,每個峰值的影像特征用來預測物體的bounding box 的高度和寬度,因為是anchor free的方式,通過heatmap峰值點直接預測出目標中心點,再針對中心點進行其余屬性的預測,因為每個目標只有一個 “positive anchor”,同時也沒有靠IoU來分配anchor,所以是沒有必要使用NMS(Non-maximum suppression)來濾除其他的重復多余的box的,centernet的輸出是4倍下采樣后的結果,一般的目標檢測器輸出的是 16 倍下采樣的結果,所以 centernet 不需要多個anchor
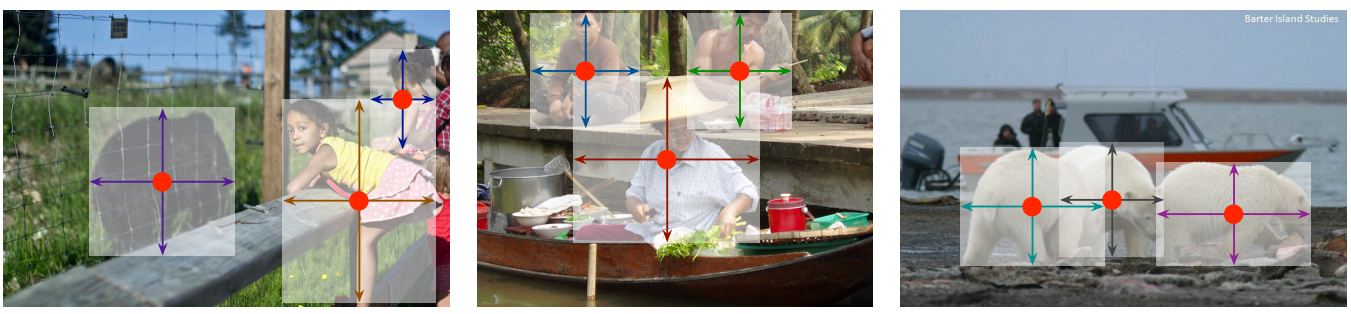
Preliminary
??CenterNet輸入為512 * 512 * 3的影像(具體看直接網路的設定),
I
∈
R
W
×
H
×
3
I \in R^{W\times H\times 3}
I∈RW×H×3,為了產生heatmap
Y
^
∈
[
0
,
1
]
W
R
×
H
R
×
C
\hat{Y} \in [0, 1]^{\frac{W}{R} \times \frac{H}{R} \times C}
Y^∈[0,1]RW?×RH?×C 其中R是輸出步長,C是關鍵點型別的個數,默認的輸出步長R = 4,即為下采樣,結果
Y
^
x
,
y
,
c
=
1
\hat{Y}_{x,y,c}=1
Y^x,y,c?=1對應于一個被檢測的關鍵點,而
Y
^
x
,
y
,
c
=
0
\hat{Y}_{x,y,c} = 0
Y^x,y,c?=0 則對應背景, 對于類別c中每一個關鍵點的真實值
p
∈
R
2
p \in R^2
p∈R2 ,關鍵點真實值
p
=
(
x
1
+
x
2
2
,
y
1
+
y
2
2
)
p=(\frac{x_1+x_2}{2},\frac{y_1+y_2}{2})
p=(2x1?+x2??,2y1?+y2??),計算了一個低解析度等價的
p
~
=
[
p
R
]
\tilde{p}=[\frac{p}{R}]
p~?=[Rp?],之后把所有的真實的關鍵點分布在一個heatMap上
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
Y \in [0, 1]^{\frac{W}{R} \times \frac{H}{R} \times C}
Y∈[0,1]RW?×RH?×C,并使用一個高斯卷積核
Y
x
y
c
=
e
x
p
(
?
(
x
?
p
~
x
)
2
+
(
y
?
p
~
y
)
2
2
σ
p
2
)
Y_{xyc}=exp(- \frac{(x-\tilde{p}_{x})^2+(y-\tilde{p}_{y})^2}{2\sigma^{2}_{p}})
Yxyc?=exp(?2σp2?(x?p~?x?)2+(y?p~?y?)2?),生成一個二維的正態分布,如果兩個同類別的高斯結果重合,我們就取每個元素的最大值,(感覺也是有點類似于anchor的方法,只不過是從資料中去學習得到中心點,資料在標注的程序中應該是,會得到左上角坐標和右下角坐標,以及label標簽)
??上面說到下采樣為4(對512的size來說),即輸出應該為128 * 128 * 2的heatmap圖,其會將每個目標的尺寸回歸到heatmap上,而只會預測兩個通道,即一個width 和一個height,而并非每個label對于的兩個channel,
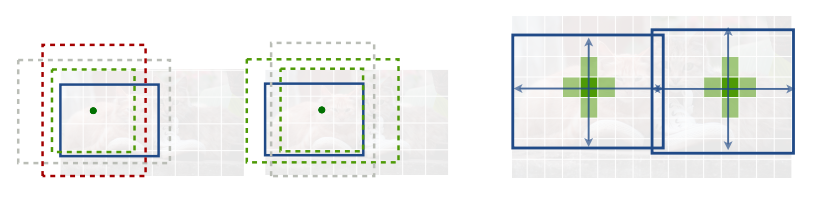
?Heatmap
??我覺得應該好多人不知道這個,哈哈哈哈哈,heatmap是在二維空間中以顏色的形式顯示一個現象的絕對量一種資料可視化技術,顏色的變化可能是通過色調或強度,給讀者提供明顯的視覺提示,說明現象是如何在空間上聚集或變化的
??因為用heatmap做關鍵點的檢測(即輸出關鍵點的位置坐標),在生成heatmap的時候,會在最大值附近出現多個峰值,即目標附近的點會和目標會有著相似性(不可能用某一個像素來定義),而如果將其作為負樣本,會對關鍵點的位置坐標和訓練產生影響,所以使用才采用高斯核來對其預先處理,起到一定的平滑操作,如果周圍存在著多個其峰值,對網路的回歸會有一定的影響,而加上高斯核,會給網路的訓練帶來一個方向指引,距離目標點越近,激活值越大,這樣網路能有方向的去快速到達目標點,中間區域的概率最大,基本上接近于1,邊緣逐漸減小,
計算Heatmap部分code:
def draw_gaussian(heatmap, center, radius, k=1):
diameter = 2 * radius + 1
gaussian = gaussian2D((diameter, diameter), sigma=diameter / 6)
x, y = int(center[0]), int(center[1])
height, width = heatmap.shape[0:2]
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius + bottom, radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
return heatmap
def GaussianHeatMap(shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape] #image shape
y, x = np.meshgrid[-m:m + 1, -n:n + 1]
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
return h
def gaussian_radius(det_size, min_overlap=0.7):
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
??emmm,到這里應該還只是個半成品(其實還不到1/3,因為還有姿態和3D的),但先發出來吧,到時候再補充!嘻嘻嘻,小劉應該快從小鵬離職了,要回學校答辯了,然后復習考研,要是今年12月考研上了,那就繼續造車吧,沖沖沖!giao
?? 沒寫完就沒寫完,嘿!我就是玩!

腦瓜子嗡嗡的小劉,一名自動駕駛影像演算法實習生,同時小劉也是一枚熱衷于人工智能技術與嵌入式技術的萌新小白,小劉在校期間也參加過許許多多的國內比賽(主要是嵌入式與物聯網相關的),要是大哥們有什么問題,可以隨時Call me,希望能和大哥們共同進步!!!同時也希望大哥們看文章的時候也能抽空點個贊!謝謝大哥們了!!!(づ ̄ 3 ̄)づ
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278081.html
標籤:其他