05_pytorch的Tensor操作
目錄- 一、引言
- 二、tensor的基礎操作
- 2.1 創建tensor
- 2.2 常用tensor操作
- 2.2.1 調整tensor的形狀
- 2.2.2 添加或壓縮tensor維度
- 2.3 索引操作
- 2.4 高級索引
- 2.5 Tensor型別
- 2.5.1 Tensor資料型別
- 2.5.2 資料型別轉換
- 2.5.3 cpu和gpu間資料型別轉換
- 2.6 逐元素操作
- 2.7 歸并操作
- 2.8 比較
- 2.9 線性代數
- 三、Tensor和Numpy
- 3.1 tensor資料和ndarray資料相互轉換
- 3.2 廣播法則
- 四、Tensor內部存盤結構
- 五、其他
- 5.1 持久化
- 5.1.1 保存模型
- 5.1.2 加載模型
- 5.2 向量化
- 5.1 持久化
- 5.3 注意事項
- 六、總結
pytorch完整教程目錄:https://www.cnblogs.com/nickchen121/p/14662511.html
一、引言
上一篇文章我們利用手寫數字分類這個問題講解了深度網路模型的架構以及來源,簡單點說,深度網路模型就是多個分類的模型疊加在一起,而分類模型就是在回歸模型上加了一個激活函式,
本次分享更多的是想讓我們更好的利用torch幫我們解決更多的實際問題,而為了解決我們這第一個手寫數字分類問題,首先讓我們來先了解下torch的一些基礎語法和基礎方法,不得不再次申明,由于torch的資料型別和numpy的資料型別有異曲同工之妙,所以此處默認你有numpy的基礎,如果你不是很了解numpy的用法,可以查看我的這篇博客https://www.cnblogs.com/nickchen121/p/10807564.html
二、tensor的基礎操作
tensor,也可以叫做張量,學過線性代數的你,其實早就接觸了張量,只不過我們一直把它叫做向量和矩陣,而向量就是一維張量、矩陣是二維張量,只不過張量還可以是三維的、四維的,只是維數高了之后,我們難以理解,因此統一把它都叫做張量,
在torch中,張量是一個資料型別,也就是tensor,它和numpy中的ndarray這個資料型別很像,以及和它的操作方法也很類似,其實你可以發現,ndarray不就是一維和二維張量嗎?
如果你看過我的Python博客,可以發現我把python的所有的基礎型別和其對應的操作方法都講到了,那是因為任何框架的基礎都是python,python的所有操作方法都學習全面了,你自己也可以造框架,而對于框架的各種操作方法,底層無非就是一堆python代碼的堆疊,也就是有些操作方法你不學,你也可以自己造出來,所以對于torch的很多不常用的內容我們可能會一筆概之或者直接不講,
而對于tensor的基礎操作,我們可以從兩個方面來講,
如果從介面的角度,對tensor的操作可以分為兩類:
torch.function,如torch.savetensor.function,如tensor.view
注:對于這兩種介面方法,大多數時候都是等價的,如torch.sum(a,b)和a.sum(b)
如果從存盤的角度講,對tensor的操作也可以分為兩類:
a.add(b),不會修改a自身的資料,加法的結果會回傳一個新的tensora.add_(b),會修改a自身的資料,也就是說加法的結果存在a中
注:函式名以_結尾的都是修改呼叫者自身的資料,
2.1 創建tensor
此處我只列出表格,不給出詳細介紹和代碼列印結果,只給出一些細節上需要注意的東西,因為它除了支持多維,其他和numpy簡直一模一樣
| 函式 | 功能 |
|---|---|
Tensor(*size) |
基礎建構式 |
ones(*sizes) |
全1Tensor |
zeros(*sizes) |
全0Tensor |
eye(*sizes) |
對角矩陣(對角線為1,其他為0,不要求行列一致) |
arrange(s,e,step) |
從s到e,步長為step |
linspace(s,e,steps) |
從s到e,均勻分成steps份 |
rand/randn(*sizes) |
均勻/標準分布 |
normal(mean,std)/uniform(from,tor) |
正態分布/均勻分布 |
randperm(m) |
隨機排列 |
import torch as t
如果*size為串列,則按照串列的形狀生成張量,否則傳入的引數看作是張量的形狀
a = t.Tensor(2, 3) # 指定形狀構建2*3維的張量
a
tensor([[ 0.0000e+00, -2.5244e-29, 0.0000e+00],
[-2.5244e-29, 6.7294e+22, 1.8037e+28]])
b = t.tensor([[1, 2, 3], [2, 3, 4]]) # 通過傳入串列構建2*3維的張量
b
tensor([[1, 2, 3],
[2, 3, 4]])
b.tolist() # 把b轉化為串列,但是b的實際資料型別仍是tensor
[[1, 2, 3], [2, 3, 4]]
print(f'type(b): {type(b)}')
type(b): <class 'torch.Tensor'>
b.size() # 回傳b的大小,等價于b.shape()
torch.Size([2, 3])
b.numel() # 計算b中的元素個數,等價于b.nelement()
6
c = t.Tensor(b.size()) # 創建一個和b一樣形狀的張量
c
tensor([[0.0000e+00, 3.6013e-43, 1.8754e+28],
[2.0592e+23, 1.3003e+22, 1.0072e-11]])
注:t.Tensor(*size)創建tensor時,系統不會馬上分配空間,只有使用到tensor時才會分配記憶體,而其他操作都是在創建tensor后馬上進行空間分配
2.2 常用tensor操作
2.2.1 調整tensor的形狀
view()方法調整tensor的形狀,但是必須得保證調整前后元素個數一致,但是view方法不會修改原tensor的形狀和資料
a = t.arange(0, 6)
a
tensor([0, 1, 2, 3, 4, 5])
b = a.view(2, 3)
print(f'a: {a}\n\n b:{b}')
a: tensor([0, 1, 2, 3, 4, 5])
b:tensor([[0, 1, 2],
[3, 4, 5]])
c = a.view(-1, 3) # -1會自動計算大小,注:我已經知道你在想什么了,兩個-1你就上天吧,鬼知道你想改成什么形狀的
print(f'a: {a}\n\n b:{c}')
a: tensor([0, 1, 2, 3, 4, 5])
b:tensor([[0, 1, 2],
[3, 4, 5]])
a[1] = 0 # view方法回傳的tensor和原tensor共享記憶體,修改一個,另外一個也會修改
print(f'a: {a}\n\n b:{b}')
a: tensor([0, 0, 2, 3, 4, 5])
b:tensor([[0, 0, 2],
[3, 4, 5]])
resize()是另一種用來調整size的方法,但是它相比較view,可以修改tensor的尺寸,如果尺寸超過了原尺寸,則會自動分配新的記憶體,反之,則會保留老資料
b.resize_(1, 3)
tensor([[0, 0, 2]])
b.resize_(3, 3)
tensor([[0, 0, 2],
[3, 4, 5],
[0, 0, 0]])
b.resize_(2, 3)
tensor([[0, 0, 2],
[3, 4, 5]])
2.2.2 添加或壓縮tensor維度
unsqueeze()可以增加tensor的維度;squeeze()可以壓縮tensor的維度
# 過于抽象,無法理解就跳過,
d = b.unsqueeze(
1) # 在第1維上增加“1”,也就是2*3的形狀變成2*1*3,如果是b.unsqueeze(0)就是在第0維上增加1,形狀變成1*2*3,
d, d.size()
(tensor([[[0, 0, 2]],
[[3, 4, 5]]]), torch.Size([2, 1, 3]))
b.unsqueeze(-1) # 在倒數第1維上增加“1”,也就是2*3的形狀變成2*3*1,
tensor([[[0],
[0],
[2]],
[[3],
[4],
[5]]])
e = b.view(1, 1, 2, 1, 3)
f = e.squeeze(0) # 壓縮第0維的“1”,某一維度為“1”才能壓縮,如果第0維的維度是“2”如(2,1,1,1,3)則無法亞索第0維
f, f.size()
(tensor([[[[0, 0, 2]],
[[3, 4, 5]]]]), torch.Size([1, 2, 1, 3]))
e.squeeze() # 把所有維度為“1”的壓縮,
tensor([[0, 0, 2],
[3, 4, 5]])
2.3 索引操作
tensor的索引操作和ndarray的索引操作類似,并且索引出來的結果與原tensor共享記憶體,因此在這里普通的切片操作我們就不多介紹,我們只講解tensor一些特有的選擇函式,
| 函式 | 功能 |
|---|---|
index_select(input,dim,index) |
在指定維度dim上選取,例如選取某些行、某些列 |
masked_select(inpu,mask) |
a[a>1] 等價于a.masked_select(a>1) |
non_zero(input) |
獲取非0元素的下標 |
gather(input,dim,index) |
根據index,在dim維度上選取資料,輸出的size與index一樣 |
import torch as t
對于上述選擇函式,我們講解一下比較難的gather函式,對于一個二維tensor,gather的輸出如下所示:
out[i][j] = input[index[i][j]][j] # dim=0out[i][j] = input[i][index[i][j]] # dim=1
a = t.arange(0, 16).view(4, 4)
a
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
# 選取對角線的元素
index = t.LongTensor([[0, 1, 2, 3]])
print(f'index: {index}')
a.gather(0, index) # dim=0
index: tensor([[0, 1, 2, 3]])
tensor([[ 0, 5, 10, 15]])
對于上述實體,可以做出如下解釋:
i=0,j=0 -> index[0,0]=0 -> input[index[0,0]][0]=input[0][0] = 0i=0,j=1 -> index[0,1]=1 -> input[index[0,1]][1]=input[1][1] = 5i=0,j=2 -> index[0,2]=2 -> input[index[0,2]][2]=input[2][2] = 10i=0,j=3 -> index[0,3]=3 -> input[index[0,3]][3]=input[3][3] = 15
下述實體,自行判斷,
# 選取反對角線上的元素
index = t.LongTensor([[3, 2, 1, 0]]).t() # .t()是轉置
print(f'index: {index}')
a.gather(1, index)
index: tensor([[3],
[2],
[1],
[0]])
tensor([[ 3],
[ 6],
[ 9],
[12]])
# 選取反對角線上的元素
index = t.LongTensor([[3, 2, 1, 0]]) # .t()是轉置
a.gather(0, index)
tensor([[12, 9, 6, 3]])
# 選取兩個對角線上的元素
index = t.LongTensor([[0, 1, 2, 3], [3, 2, 1, 0]]).t() # .t()是轉置
print(f'index: {index}')
b = a.gather(1, index)
b
index: tensor([[0, 3],
[1, 2],
[2, 1],
[3, 0]])
tensor([[ 0, 3],
[ 5, 6],
[10, 9],
[15, 12]])
與gather函式相應的逆操作則是scatter_,scatter_可以把gather取出的元素放回去,
out = input.gather(dim, index)
out = Tensor()
out.scatter_(dim, index)
# 把兩個對角線元素放回到指定位置里
c = t.zeros(4, 4, dtype=t.int64)
c.scatter_(1, index, b)
tensor([[ 0, 0, 0, 3],
[ 0, 5, 6, 0],
[ 0, 9, 10, 0],
[12, 0, 0, 15]])
2.4 高級索引
torch的高級索引和numpy的高級索引也很類似,因此照例,只講一些復雜的高級索引方法,
注:高級索引操作的結果和原tensor不共享記憶體
x = t.arange(0, 27).view(3, 3, 3)
x
tensor([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
x[[1, 2], [1, 2], [2, 0]] # x[1,1,2] 和 x[2,2,0]
tensor([14, 24])
x[[2, 1, 0], [0], [1]] # x[2,0,1],x[1,0,1],x[0,0,1]
tensor([19, 10, 1])
x[[0, 2], ...] # x[0] 和 x[2]
tensor([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
可以從上述三個例子看出高級索引的本質就是先回圈第一個串列中的元素,然后與后面串列的元素配對,配對滿足維數要求則停止,否則繼續往后搜索,
對于第一個例子:
- 先從
[1,2]中取出1 - 1和第二個串列
[1,2]配對,滿足三維要求,即[1,1,2],停止配對,回圈步驟一取出2 - 2和第三個串列
[2,0]配對,滿足三維要求,即[2,2,0],停止配對
對于第二例子:
- 先從
[2,1,0]中取出2 - 2和第二個串列
[0]配對,不滿足三維要求,繼續往后搜索,和第三個串列[1]配對,滿足三維要求,即[2,0,1] - ……
2.5 Tensor型別
2.5.1 Tensor資料型別
| 資料型別 | CPU tensor | GPU tensor |
|---|---|---|
| 32bit浮點 | torch.FloatTensor | torch.cuda.FloatTensor |
| 64bit浮點 | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 16bit半精度浮點 | torch.HalfTensor | torch.cuda.HalfTensor |
| 8bit無符號整型(0~255) | torch.ByteTensor | torch.cuda.ByteTensor |
| 8bit有符號整型(-128~127) | torch.CharTensor | torch.cuda.CharTensor |
| 16bit有符號整型 | torch.ShortTensor | torch.cuda.ShortTensor |
| 32bit有符號整型 | torch.IntTensor | torch.cuda.IntTensor |
| 64bit有符號整型 | torch.LongTensor | torch.cuda.LongTensor |
上表中只有HalfTensor值得一提,它是gpu獨有的資料型別,使用該資料型別,gpu在存盤該型別資料時,記憶體占用會減少一半,可以解決gpu顯存不足的問題,但是由于它所能表示的數值大小和精度有限,所以可能存在溢位問題,
2.5.2 資料型別轉換
# 設定默認tensor,系統默認tensor是FloatTensor,也僅支持浮點數型別為默認資料型別,設定成IntTensor會報錯
t.set_default_tensor_type('torch.DoubleTensor')
a = t.Tensor(2, 3)
a, a.type() # a現在是DoubleTensor
(tensor([[0., 0., 0.],
[0., 0., 0.]]), 'torch.DoubleTensor')
b = a.int() # 可通過`float(), int(), double(), char(), long(), int()`更換資料型別
b.type()
'torch.IntTensor'
c = a.type_as(b) # 對a進行資料型別轉換
c, c.type()
(tensor([[0, 0, 0],
[0, 0, 0]], dtype=torch.int32), 'torch.IntTensor')
d = a.new(2, 3) # 生成與a資料型別一致的tensor
d, d.type()
(tensor([[ 2.0000e+00, 2.0000e+00, 3.9525e-323],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00]]), 'torch.DoubleTensor')
a.new?? # 查看new的原始碼
t.set_default_tensor_type('torch.FloatTensor') # 恢復之前的默認設定
2.5.3 cpu和gpu間資料型別轉換
cpu和gpu的資料型別通常有tensor.cpu()和tensor.gpu()互相轉換,由于我的電腦沒有gpu,從網上摘抄一段供大家參考:
In [115]: a = t.ones(2,3)
In [116]: a.type()
Out[116]: 'torch.FloatTensor'
In [117]: a
Out[117]:
tensor([[1., 1., 1.],
[1., 1., 1.]])
In [118]: a.cuda()
Out[118]:
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
In [119]: b = a.cuda()
In [120]: b
Out[120]:
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
In [121]: b.type()
Out[121]: 'torch.cuda.FloatTensor'
In [122]: b.cpu()
Out[122]:
tensor([[1., 1., 1.],
[1., 1., 1.]])
In [123]: b.cpu().type()
Out[123]: 'torch.FloatTensor'
2.6 逐元素操作
通俗點講,就是對tensor進行數學操作,只不過是對tensor的每個元素都進行相對應的操作,因此叫做逐元素操作,也因此該類操作的輸出形狀與原tensor形狀一致,常見的逐元素操作如下表:
| 函式 | 功能 |
|---|---|
| mul/abs/sqrt/exp/fmod/log/pow…… | 乘法(*)/絕對值/平方根/除法(/)/指數/求余(%)/求冪(**) |
| cos/sin/asin/atan2/cosh | 三角函式 |
| ceil/round/floor/trunc | 上取整/四舍五入/下去整/只保留整數部分 |
clamp(input,min,max) |
超過min和max部分截斷 |
| sigmod/tanh/... | 激活函式 |
針對上述一些運算子,torch實作了運算子多載,例如a**2等價于torch.pow(a,2),
針對clamp函式,它的輸出滿足下述公式:
\[y_i = \begin{cases} & min,\quad\text{if x_i < min} \\ & x_i,\quad\quad\text{if min}\leq\text{x_i}\leq\text{max}\\ & max,\quad\text{if x_i > max} \end{cases} \]a = t.arange(0, 6).view(2, 3)
a
tensor([[0, 1, 2],
[3, 4, 5]])
a.clamp(min=3)
tensor([[3, 3, 3],
[3, 4, 5]])
2.7 歸并操作
該類操作可以沿著某一維度進行指定操作,因此它們的輸出形狀一般小于元tensor形狀,如加法sum,可以計算正整個tensor的和,也可以計算某一行或某一列的和,常用的歸并操作如下表所示:
| 函式 | 功能 |
|---|---|
| mean/sum/median/mode | 均值/和/中位數/眾數 |
| norm/dist | 范數/距離 |
| std/var | 標準差/方差 |
| cunsum/cumprod | 累加/累乘 |
以上函式大多都有一個dim引數(對應numpy中的axis引數),它的使用如下所示(假設輸入的形狀是(a,b,c)):
- 如果指定dim=0,輸出形狀是(1,b,c)或(b,c)
- 如果指定dim=1,輸出形狀是(a,1,c)或(a,c)
- 如果指定dim=2,輸出形狀是(a,b,1)或(a,b)
對于上述操作是否保留輸出形狀中的“1”,取決于引數keepdim,如果keepdim=True則保留,反之不保留,但是從torch0.2.0版本開始,統一不保留,雖然以上總結適用于大多數函式,但是對于cumsum函式,則不適用該規則,
b = t.ones(2, 3)
b.sum(dim=0), b.sum(dim=0, keepdim=True) # 前者輸出形狀是(3),后者輸出形狀是(1,3)
(tensor([2., 2., 2.]), tensor([[2., 2., 2.]]))
a = t.arange(0, 6).view(2, 3)
a
tensor([[0, 1, 2],
[3, 4, 5]])
a.cumsum(dim=1) # 對第二個維度行的元素按照索引順序進行累加
tensor([[ 0, 1, 3],
[ 3, 7, 12]])
2.8 比較
對于比較函式中,有些函式逐元素操作,有些函式則類似于歸并不逐元素操作,常用的比較函式有:
| 函式 | 功能 |
|---|---|
| gt/lt/le/eq/ne | 大于(>)/小于(<)/大于等于(>=)/小于等于(<=)/等于)(=)/不等(!=) |
| topk | 最大的k個數 |
| sort | 排序 |
| max/min | 比較兩個tensor的最大值和最小值 |
其中max和min兩個函式有點特殊,它們有以下三種情況:
t.max(tensor):回傳tensor中最大的一個數t.max(tensor,dim):指定維上最帶的數,回傳tensor和下標t.max(tensor1,tensor2):比較兩個tensor相比較大的元素
a = t.linspace(0, 15, 6).view(2, 3)
a
tensor([[ 0., 3., 6.],
[ 9., 12., 15.]])
b = t.linspace(15, 0, 6).view(2, 3)
b
tensor([[15., 12., 9.],
[ 6., 3., 0.]])
t.max(a)
tensor(15.)
t.max(a, 1) # 回傳第0行和第1行的最大的元素
torch.return_types.max(
values=tensor([ 6., 15.]),
indices=tensor([2, 2]))
t.max(a, b)
tensor([[15., 12., 9.],
[ 9., 12., 15.]])
2.9 線性代數
常用的線性代數函式如下表所示:
| 函式 | 功能 |
|---|---|
| trace | 對角線元素之和(矩陣的跡) |
| diag | 對角線元素 |
| triu/tril | 矩陣的上三角/下三角,可指定偏移量 |
| mm/bmm | 矩陣的乘法/batch的矩陣乘法 |
| addmm/addbmm/addmv | 矩陣運算 |
| t | 轉置 |
| dot/cross | 內積/外積 |
| inverse | 求逆矩陣 |
| svd | 奇異值分解 |
其中矩陣的轉置會導致存盤空間不連續,需呼叫它的.contiguous方法讓它連續
b = a.t()
b, b.is_contiguous()
(tensor([[ 0., 9.],
[ 3., 12.],
[ 6., 15.]]), False)
b = b.contiguous()
b, b.is_contiguous()
(tensor([[ 0., 9.],
[ 3., 12.],
[ 6., 15.]]), True)
三、Tensor和Numpy
由于tensor和ndarray具有很高的相似性,并且兩者相互轉化需要的開銷很小,但是由于ndarray出現時間較早,相比較tensor有更多更簡便的方法,因此在某些時候tensor無法實作某些功能,可以把tensor轉換為ndarray格式進行處理后再轉換為tensor格式,
3.1 tensor資料和ndarray資料相互轉換
import numpy as np
a = np.ones([2, 3], dtype=np.float32)
a
array([[1., 1., 1.],
[1., 1., 1.]], dtype=float32)
b = t.from_numpy(a) # 把ndarray資料轉換為tensor資料
b
tensor([[1., 1., 1.],
[1., 1., 1.]])
b = t.Tensor(a) # 把ndarray資料轉換為tensor資料
b
tensor([[1., 1., 1.],
[1., 1., 1.]])
a[0, 1] = 100
b
tensor([[ 1., 100., 1.],
[ 1., 1., 1.]])
c = b.numpy() # 把tensor資料轉換為ndarray資料
c
array([[ 1., 100., 1.],
[ 1., 1., 1.]], dtype=float32)
3.2 廣播法則
廣播法則來源于numpy,它的定義如下:
- 讓所有輸入陣列都向其中shape最長的陣列看齊,shape中不足部分通過在前面加1補齊
- 兩個陣列要么在某一個維度的長度一致,要么其中一個為1,否則不能計算
- 當輸入陣列的某個維度的長度為1時,計算時沿此維度復制擴充×一樣的形狀
torch當前支持自動廣播法則,但更推薦使用以下兩個方法進行手動廣播,這樣更直觀,更不容出錯:
- unsqueeze或view:為資料某一維的形狀補1
- expand或expand_as:重復陣列,實作當輸入的陣列的某個維度的長度為1時,計算時沿此維度復制擴充成一樣的形狀
注:repeat與expand功能相似,但是repeat會把相同資料復制多份,而expand不會占用額外空間,只會在需要的時候才擴充,可以極大地節省記憶體,
a = t.ones(3, 2)
b = t.zeros(2, 3, 1)
自動廣播法則:
- a是二維,b是三維,所在現在較小的a前面補1(等價于
a.unsqueeze(0),a的形狀變成(0,2,3)) - 由于a和b在第一維和第三維的形狀不一樣,利用廣播法則,兩個形狀都變成了(2,3,2)
a + b
tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
對上述自動廣播可以通過以下方法實作手動廣播
a.unsqueeze(0).expand(2, 3, 2) + b.expand(
2, 3, 2) # 等價于a.view(1,3,2).expand(2,3,2) + b.expand(2,3,2)
tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
四、Tensor內部存盤結構
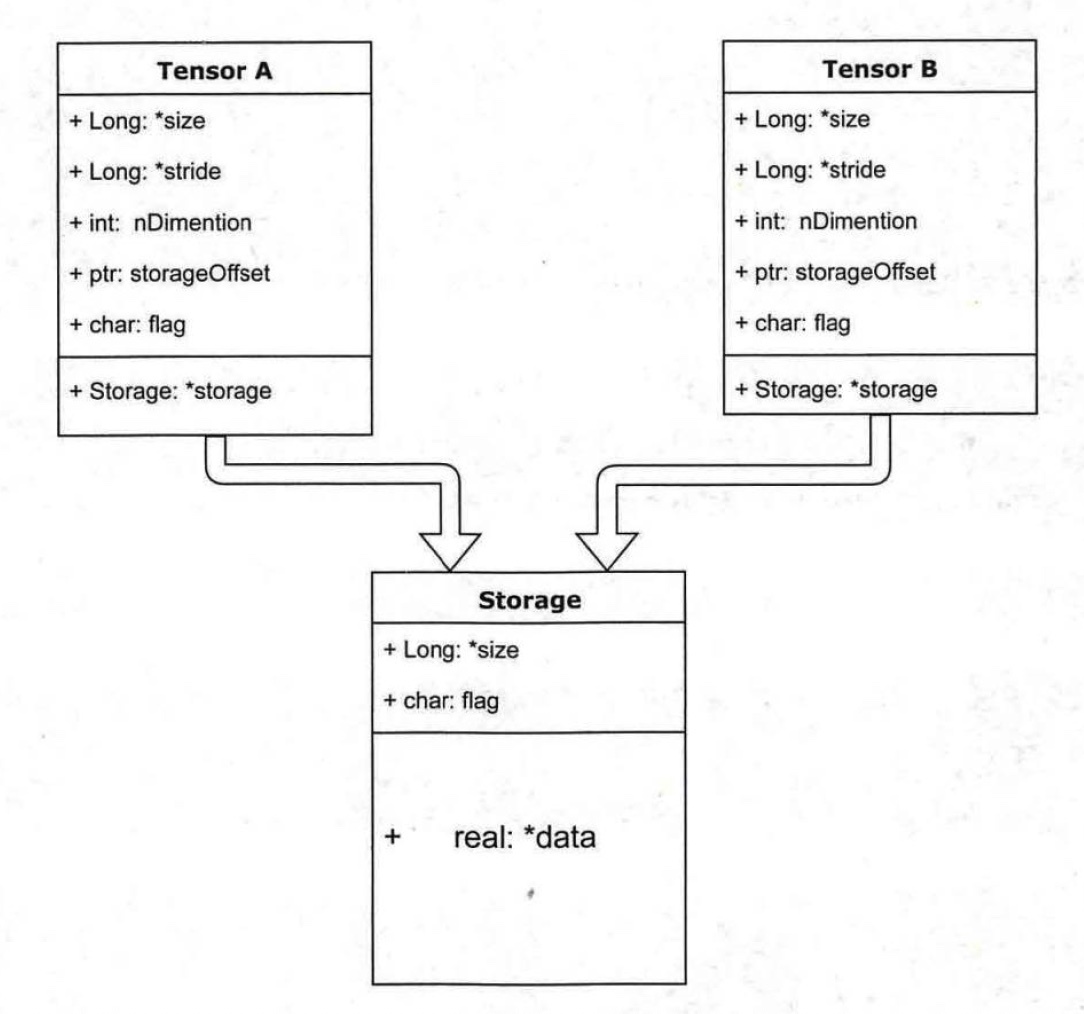
tensor的資料存盤結構如上圖所示,它分為資訊區(Tensor)和存盤區(Storage),資訊區主要保存tensor的形狀、資料型別等資訊;而真正的資料則保存成連續陣列存放在存盤區,
一個tensor有著一個與之對應的storage,storage是在data之上封裝的介面,便于使用,不同的tensor的頭資訊一般不同,但卻有可能使用相同的storage,
a = t.Tensor([0, 1, 2, 3, 4, 5])
b = a.view(2, 3)
id(a.storage()), id(b.storage()), id(a.storage()) == id(b.storage())
(140397108640200, 140397108640200, True)
a[1] = 100 # a改變,b進而隨之改變,因為它們共享記憶體
b
tensor([[ 0., 100., 2.],
[ 3., 4., 5.]])
c = a[2:]
# data_ptr回傳tensor首元素的地址
c.data_ptr() - a.data_ptr() # 相差16,這是因為2*8=16相差兩個元素,每個元素占8個位元組
8
c[0] = -100 # c和a共享記憶體
a
tensor([ 0., 100., -100., 3., 4., 5.])
c.storage()
0.0
100.0
-100.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
d = t.Tensor(c.storage()) # 使用a的存盤資料建立d
d[0] = 666
a
tensor([ 666., 100., -100., 3., 4., 5.])
id(a.storage()) == id(b.storage()) == id(c.storage()) == id(d.storage())
True
# storage_offset是資料在storage中的索引,a和d從sotrage的第一個元素開始找,c是從第三個元素開始查找
a.storage_offset(), c.storage_offset(), d.storage_offset()
(0, 2, 0)
e = b[::2, ::2] # 從0開始,每隔2行/列取一個元素
e
tensor([[ 666., -100.]])
b
tensor([[ 666., 100., -100.],
[ 3., 4., 5.]])
e.storage()
666.0
100.0
-100.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
# stride是storage中對應于tensor的相鄰維度間第一個索引的跨度
# 對于b,第一行第一個元素到第二行第一個元素的索引差距為3,第一列第一個元素到到第二列第一個元素的索引差距為1
# 對于e,第一行第一個元素到第二行第一個元素(空)的索引差距為6,第一列第一個元素到到第二列第一個元素的索引差距為2
b.stride(), e.stride()
((3, 1), (6, 2))
e.is_contiguous()
False
id(d.storage()), id(e.storage())
(140397108641736, 140397108641736)
e.contiguous()
id(e.storage())
140397108699912
從上可見大多數操作并不會修改tensor的資料,只是修改tensor的頭資訊,這種做法減少了記憶體的占用,并且更加節省了時間,但是有時候這種操作會導致tensor不連續,此時可以通過contiguous方法讓其連續,但是這種方法會復制資料到新的記憶體空間,不再和原來的資料共享記憶體,
五、其他
5.1 持久化
和sklearn中的持久化一樣,保存一個模型或者特有的資料為pkl資料,但是tensor在加載資料的時候還可以把gpu tensor映射到cpu上或者其他gpu上,
5.1.1 保存模型
if t.cuda.is_available():
a = a.cuda(1) # 把a轉為gpu1上的tensor
t.save(a, 'a.pkl')
5.1.2 加載模型
# 加載為b,存盤于gpu1上(因為保存時tensor就在gpu1上)
b = t.load('a.pkl')
# 加載為c,存盤于cpu
c = t.load('a.pkl', map_location=lambda storage, loc: storage)
# 加載為d,存盤于gpu0上
d = t.load('a.pkl', map_location={'cuda:1': 'cuda:0'})
5.2 向量化
向量化計算是一種特殊的并行計算方法,通常是對不同的資料執行同樣的一個或一批指令,由于Python原生的for回圈效率低下,因此可以盡可能的使用向量化的數值計算,
def for_loop_add(x, y):
result = []
for i, j in zip(x, y):
result.append(i + j)
return t.Tensor(result)
x = t.zeros(100)
y = t.ones(100)
%timeit -n 100 for_loop_add(x,y)
%timeit -n 100 x+y
566 μs ± 100 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
3.25 μs ± 1.63 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
從上面可以看見,如果自己寫一個方法實作內建函式,運行時間相差200倍,因為內建函式底層大多由c/c++實作,能通過執行底層優化實作高效計算,所以平時在寫代碼時,應該養成向量化的思維習慣,
5.3 注意事項
除了上述講的大多數內容,最后還有以下三點需要注意:
- 大多數
t.function都有一個引數out,可以將其產生的結果保存在out指定的tensor之中 t.set_num_threads可以設定torch進行cpu多執行緒并行計算時所占用的執行緒數,用來限制torch所占用的cpu數目t.set_printoptions可以用來設定列印tensor時的數值精度和格式
b = t.FloatTensor()
t.randn(2, 3, out=b)
b
tensor([[ 1.4754, -0.7392, -0.1900],
[-0.8091, 0.2227, 0.8951]])
t.set_printoptions(precision=10)
b
tensor([[ 1.4753551483, -0.7392477989, -0.1899909824],
[-0.8091416359, 0.2227495164, 0.8951155543]])
六、總結
這一篇章幅度較大,對于熟悉numpy的同學可能得心應手很多,如果對numpy不是特別熟悉的同學,建議先按照上述所給的教程學一遍numpy,再過來學習tensor這個資料型別,從一二維過渡到高維,也將更容易上手,
這篇文章內容雖多,但從實用的角度來說,相對而言也比較全面,其中內容不需要全部熟稔于心,但至少得對每個方法都大概有個印象,知道有這個東西,這個東西能干啥!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278391.html
標籤:其他