文章目錄
- 一、前言
- 二、最長不重復子串
- 1、初步分析
- 2、樸素演算法
- 3、優化演算法
- 三、尺取法
- 1、演算法定義
- 2、演算法描述
- 3、條件
- 1)單調性
- 2)時效性
- 四、尺取法的應用
- 1、前綴和問題
- 2、哈希問題
- 3、K 大數問題
- 五、尺取法相關題集整理
一、前言
??收到讀者私信說:為什么你的演算法越講越簡單了?
??我告訴他:因為你越來越聰明了!
??今天要講的演算法,《演算法導論》書上是看不到的,因為無論是思考程序還是代碼實作上都是非常容易理解的,所以各大演算法書上都不屑將它歸為演算法,但是它卻作為職場面試,省賽水題的絕佳選擇,它有一個比較優雅的名字叫 尺取法,英文把它叫 “two pointers”,也就是 “雙指標” 的意思,
??現在幾點來著?四點?哈哈,早睡早起,方能養生!

二、最長不重復子串
- 接下來,以一個非常經典的面試題【最長不重復子串】為例,展開今天演算法的講解,
【例題1】給定一個長度為 n ( 1 ≤ n ≤ 1 0 7 ) n (1 \le n \le 10^7) n(1≤n≤107) 的字串 s s s,求一個最長的滿足所有字符不重復的子串,
1、初步分析
- 首先我們分析一下這個問題的關鍵詞,主要有以下幾個:
- 1) n ≤ 1 0 7 n \le 10^7 n≤107;
- 2)最長;
- 3)所有字符不重復;
- 4)子串;
- 根據以上的幾個關鍵詞,我們可以得出一些結論,首先,根據 n n n 的范圍已經能夠大致確認這是一個需要 O ( n ) O(n) O(n) 或者 O ( n l o g 2 n ) O(nlog_2n) O(nlog2?n) 的演算法才能解決的問題;其次,“最長” 這個詞告訴我們,可能是一個動態規劃問題或者貪心問題,也有可能是搜索,所以這個關鍵詞給我們的資訊用處不大;而判斷字符是否重復可以用 哈希表 在 O ( 1 ) O(1) O(1) 的時間內判斷;最后,列舉所有 “子串” 的時間復雜度是 O ( n 2 ) O(n^2) O(n2) 的,
2、樸素演算法
- 由以上分析,我們可以發現第(1)個 和 第(4)個關鍵詞給我們得出的結論是矛盾的,那么,我們可以先嘗試減小 n n n 的范圍,如果 n ≤ 1000 n \le 1000 n≤1000 時,怎么解決這個問題呢?
- 因為最后求的是滿足條件的最長子串,所以我們如果能夠列舉所有子串,那么選擇長度最長的滿足條件的子串就是答案了(這里的條件是指子串中所有字符都不同),
用 a n s ans ans 記錄我們需要求的最大不重復子串的長度,用一個哈希表 h h h 來代表某個字符是否出現過,演算法描述如下:
??1)列舉子串的左端點 i = 0 → n ? 1 i = 0 \to n-1 i=0→n?1;
??2)清空哈希表 h h h;
??3)列舉子串的右端點 j = i → n ? 1 j = i \to n-1 j=i→n?1,如果當前這個字符 s j s_j sj? 出現過(即 h [ s j ] = t r u e h[s_j] = true h[sj?]=true),則跳出 j j j 的回圈;否則,令 h [ s j ] = t r u e h[s_j] = true h[sj?]=true,并且用當前長度去更新 a n s ans ans(即 a n s = m a x ( a n s , j ? i + 1 ) ans= max(ans, j - i +1) ans=max(ans,j?i+1));
??4)回到 2);
- c++ 代碼實作如下:
int getmaxlen(int n, char *str, int& l, int& r) {
int ans = 0, i, j, len;
memset(h, 0, sizeof(h));
for(i = 0; i < n; ++i) { // 1)
j = i;
memset(h, false, sizeof(h)); // 2)
while(j < n && !h[str[j]]) {
h[ str[j] ] = true; // 3)
len = j - i + 1;
if(len > ans)
ans = len, l = i, r = j;
++j;
}
}
return ans;
}
- 1)這一步列舉對應子串的左端點 i i i;
- 2)這一步用于清空哈希表 h h h,其中 h [ s j ] = t r u e h[ s_j ] = true h[sj?]=true 代表原字串的第 j j j 個字符 s j s_j sj? 是否出現在以第 i i i 個字符為左端點的子串中;
- 3)而第三步可以這么理解:如果字串 s [ i : j ] s[i:j] s[i:j] 中已經出現重復的字符,那么 s [ i : j + 1 ] , s [ i : j + 2 ] , . . . , s [ i : n ? 1 ] s[i:j+1],s[i:j+2], ... , s[i:n-1] s[i:j+1],s[i:j+2],...,s[i:n?1] 必然會有重復字符,所以這里不需要繼續往下列舉,直接跳出第二層回圈即可,
- 這個演算法執行完畢, a n s ans ans 就是我們要求的最長不重復子串的長度, [ l , r ] [l, r] [l,r] 代表了最長不重復子串在原字串的區間,正確性毋庸置疑,因為已經列舉了所有子串的情況,如果字符集的個數 z z z,演算法的時間復雜度就是 O ( n z ) O(nz) O(nz),
- 最后奉上一張動圖,代表了上述樸素演算法的求解程序,如圖二-2-1所示:
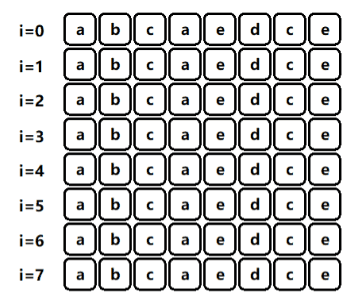
圖二-2-1 - 字串下標從 0 開始,最長無重復子串為: s [ 1 : 5 ] = b c a e d s[1:5] = bcaed s[1:5]=bcaed,長度為 5,
- 由于是字串,字符集的個數 z z z 最多 256,所以時間復雜度基本就是 O ( 256 n ) O(256n) O(256n),當 n ≤ 1 0 7 n \le 10^7 n≤107 時,這個時間復雜度是無法接受的,需要想辦法優化,
3、優化演算法
- 如果仔細思考上面樸素演算法的求解程序,就會發現:列舉子串的時候有很多區間是重疊的,所以必然存在許多沒有必要的重復計算,
- 我們考慮一個子串以
s
i
s_i
si? 為左端點,
s
j
s_j
sj? 為右端點,且
s
[
i
:
j
?
1
]
s[i:j-1]
s[i:j?1] 中不存在重復字符,
s
[
i
:
j
]
s[i:j]
s[i:j] 中存在重復字符(換言之,
s
j
s_j
sj? 和
s
[
i
:
j
?
1
]
s[i:j-1]
s[i:j?1] 中某個字符相同),如圖二-3-1所示:
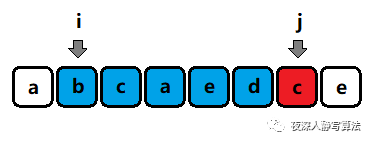
圖二-3-1 - 那么我們沒必要再去檢測 s [ i : j + 1 ] s[i:j+1] s[i:j+1], s [ i : j + 2 ] s[i:j+2] s[i:j+2], s [ i : n ? 1 ] s[i:n-1] s[i:n?1] 這幾個字串的合法性,因為當前情況 s [ i : j ] s[i:j] s[i:j] 是非法的,而這些字串是完全包含 s [ i : j ] s[i:j] s[i:j] 的,所以它們必然也是不合法的,
- 那么我們可以把列舉的左端點自增,即: i = i + 1 i = i +1 i=i+1,這時,按照樸素演算法的實作,右端點需要重置,即 j = i j = i j=i,實際上這里的右端點可以不動,
- 可以這么考慮,由于
s
j
s_j
sj? 這個字符和
s
[
i
:
j
?
1
]
s[i:j-1]
s[i:j?1] 中的字符產生了重復,假設這個重復的字符的下標為
k
k
k,那么
i
i
i 必須滿足
i
>
k
i \gt k
i>k,換言之,
i
i
i 可以一直自增,直到
i
=
k
+
1
i = k+1
i=k+1,如圖二-3-2所示:

圖二-3-2 - 利用上述思路,我們重新實作 最長不重復子串 的演算法, c++ 代碼實作如下:
int getmaxlen(int n, char *str, int& l, int& r) {
int ans = 0, i = 0, j = -1, len; // 1)
memset(h, 0, sizeof(h)); // 2)
while (j++ < n - 1) { // 3)
++h[ str[j] ]; // 4)
while (h[ str[j] ] > 1) { // 5)
--h[ str[i] ];
++i;
}
len = j - i + 1;
if(len > ans) // 6)
ans = len, l = i, r = j;
}
return ans;
}
- 1)初始化
i = 0, j = -1,代表 s [ i : j ] s[i:j] s[i:j] 為一個空串,從空串開始列舉; - 2)同樣需要維護一個哈希表,哈希表記錄的是當前列舉的區間 s [ i : j ] s[i:j] s[i:j] 中每個字符的個數;
- 3)只推進子串的右端點;
- 4)在哈希表中記錄字符的個數;
- 5)當
h[ str[j] ] > 1滿足時,代表出現了重復字符,這時候左端點 i i i 推進,直到沒有重復字符為止; - 6)記錄當前最優解
j-i+1; - 這個演算法執行完畢,我們就可以得到最長不重復子串的長度為 a n s ans ans,并且 i i i 和 j j j 這兩個指標分別只自增 n n n 次,兩者自增相互獨立,是一個相加而非相乘的關系,所以這個演算法的時間復雜度為 O ( n ) O(n) O(n) ,
- 利用該優化演算法優化后的最長不重復子串的求解程序如圖二-3-3所示:

圖二-3-3 - 參考這個圖,一個比較通俗易懂的解釋:當區間 [ i , j ] [i, j] [i,j] 中存在重復(紅色)字符時,左指標 i i i 自增;否則,右指標 j j j 自增,
三、尺取法
1、演算法定義
- 如上文所述,這種利用問題特性,通過兩個指標,不斷調整區間,從而求出問題最優解的演算法就叫 “尺取法”,由于利用的是兩個指標,所以又叫 “雙指標” 演算法,
- 這里 “尺” 的含義,主要還是因為這類問題,最終要求解的都是連續的序列(子串),就好比一把尺子一樣,故而得名,
2、演算法描述
演算法描述如下:
??1)初始化 i = 0 i=0 i=0, j = i ? 1 j=i-1 j=i?1,代表一開始 “尺子” 的長度為 0;
??2)增加 “尺子” 的長度,即 j = j + 1 j = j +1 j=j+1;
??3)判斷當前這把 “尺子” [ i , j ] [i, j] [i,j] 是否滿足題目給出的條件:
????3.a)如果不滿足,則減小 “尺子” 長度,即 i = i + 1 i = i + 1 i=i+1,回到 3);
????3.b)如果滿足,記錄最優解,回到 2);
- 上面這段文字描述的比較官方,其實這個演算法的核心,只有一句話:
滿足條件時, j j j++;不滿足條件時, i i i++; - 如圖三-2-1 所示,當區間
[
i
,
j
]
[i, j]
[i,j] 滿足條件時,用藍色表示,此時
j
j
j 自增;反之閃紅,此時
i
i
i 自增,
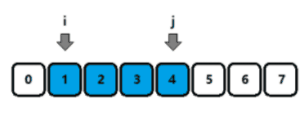
圖三-2-1
3、條件
- 這里所說的條件比較模糊,對于【例題1】來說,條件就是 “字符不重復”,當然也可以是 “每個字符重復次數不超過 k k k 次”,“至少包含 k k k 種字符”,"求和不大于 k k k" 等等,因題而異,
- 然而,無論問題怎么變,這里的條件都需要滿足以下兩點:
1)單調性
- 所謂單調性,就是說:任意一個指標的增加,條件滿足與否只會出現兩種情況,即 : 【滿足 -> 不滿足】或者 【不滿足 -> 滿足】,不會出現 【滿足 -> 不滿足 -> 滿足】這樣的情況,
2)時效性
- 所謂時效性,就是說:必須在 O ( 1 ) O(1) O(1) 或者 O ( l o g 2 n ) O(log_2n) O(log2?n) 的時間內,求出當前區間 [ i , j ] [i, j] [i,j] 是否滿足既定條件,否則無法用尺取法求解,
四、尺取法的應用
1、前綴和問題
【例題2】給定 n ( n < 1 0 5 ) n (n \lt 10^5) n(n<105) 個正數 a i ( a i ≤ 1 0 4 ) a_i ( a_i \le 10^4) ai?(ai?≤104) 和一個正數 p ( p < 1 0 8 ) p(p < 10^8) p(p<108),找到一個最短的連續子序列,滿足它的和 s ≥ p s \ge p s≥p,
- 對于一個連續子序列 a [ i : j ] a[i:j] a[i:j],它的所有數之和為 s [ i : j ] = ∑ k = i j a k s[i:j] = \sum_{k=i}^{j} a_k s[i:j]=∑k=ij?ak?,如果我們已經知道 s [ i : j ] ≥ p s[i:j] \ge p s[i:j]≥p,那么就沒必要再去求 s [ i : j + 1 ] s[i:j+1] s[i:j+1],因為題目要求一個最短的連續子序列,所以基于這點,它滿足單調性,
- 并且,我們可以定義前綴和 s u m i = ∑ k = 1 i a k sum_i = \sum_{k=1}^{i} a_k sumi?=∑k=1i?ak?,這樣就可以通過 O ( 1 ) O(1) O(1) 的時間計算出連續子序列的和:
- s [ i : j ] = ∑ k = i j a k = s u m j ? s u m i ? 1 s[i:j] = \sum_{k=i}^{j} a_k = sum_j - sum_{i-1} s[i:j]=k=i∑j?ak?=sumj??sumi?1?
- c++ 代碼實作如下:
int getminlen(int n, int *sum) {
int len = n + 1, i = 1, j = 0;
while (j++ < n) {
while (sum[j] - sum[i - 1] >= p) {
len = min(len, j - i + 1);
++i;
}
}
if (len == n + 1) len = 0;
return len;
}
2、哈希問題
【例題3】對于一個字串,如果它的每個字符數都 ≤ k \le k ≤k,則稱其為 g o o d good good 串,給定一個長度為 n ( 1 ≤ n ≤ 1 0 5 ) n(1 \le n \le 10^5) n(1≤n≤105) 且只包含小寫字母的字串,求它的 g o o d good good 串的數量,
- 如果某個子串 s [ i : j ] s[i: j] s[i:j] 是 g o o d good good 串,而 s [ i ? 1 : j ] s[i-1: j] s[i?1:j] 不是,那么可以得出:以 j j j 為右端點的情況下,左端點只要大于等于 i i i,那么這個串一定是 g o o d good good 串,所以以 j j j 為右端點,滿足條件的個數為 j ? i + 1 j-i+1 j?i+1;
- 所以整個調整程序就是: j j j 自增的程序,如果滿足每個字符數都 ≤ k \le k ≤k 的情況下,累加 j ? i + 1 j - i + 1 j?i+1;否則,自增 i i i,繼續判斷可行性,每個字符的個數統計就用到了哈希,
- c++ 代碼實作如下:
int has[256];
ll getcount(int n, char* str, int k) {
ll ans = 0;
int s = 0, i = 0, j = -1;
memset(has, 0, sizeof(has));
while (j++ < n - 1) {
if (++has[str[j]] > k)
s = 1;
while (s) {
if (--has[str[i]] == k)
s = 0;
++i;
}
ans += (j - i + 1);
}
return ans;
}
3、K 大數問題
【例題4】給定 n ( n ≤ 200000 ) n ( n \le 200000) n(n≤200000) 個數 a i a_i ai?,以及一個數 m m m,求第 k k k 大的數 ≥ m \ge m ≥m 的區間的個數,
- 可以這么考慮:如果一個區間里面 ≥ m \ge m ≥m 的數不小于 k k k 個,那么第 k k k 大的也一定滿足 ≥ m \ge m ≥m,
- 于是我們將原陣列作如下處理:將所有 ≥ m \ge m ≥m 的數變成 1,其它為 0,然后求出前綴和 s u m i sum_i sumi?,
- 那么對于某個區間 [ i , j ] [i, j] [i,j],如果 s u m j ? s u m i ? 1 ≥ k sum_{j} - sum_{i-1} \ge k sumj??sumi?1?≥k,則所有區間 [ i , k ] ( j ≥ k ≥ n ) [i, k] (j \ge k \ge n) [i,k](j≥k≥n) 都滿足 "第 k k k 大的數 ≥ m \ge m ≥m",所有以 i i i 為左端點的滿足條件區間數就是 n ? j + 1 n-j+1 n?j+1 個;累加到答案,
- 并且滿足 s u m j ? s u m i ? 1 ≥ k sum_{j} - sum_{i-1} \ge k sumj??sumi?1?≥k 時,左指標 i i i 自增,
- c++ 代碼實作如下:
#define ll long long
ll getcount(int n, int k) {
ll ans = 0;
int i = 1, j = 0;
while (j++ < n) {
while (sum[j] - sum[i - 1] >= k) {
ans += n - j + 1;
++i;
}
}
return ans;
}
- 關于 尺取法 的內容到這里就全部結束了,如果還有不懂的問題可以留言告訴作者或者添加作者的微信公眾號,
- 本文所有示例代碼均可在以下 github 上找到:github.com/WhereIsHeroFrom/Code_Templates

五、尺取法相關題集整理
| 題目鏈接 | 難度 | 解法 |
|---|---|---|
| HDU 2668 Daydream | ★★☆☆☆ | 【例題1】哈希 + 最長不重復子串 |
| NC41 最長無重復子串 | ★★☆☆☆ | 哈希 + 最長不重復子串 |
| PKU 2100 Graveyard Design | ★☆☆☆☆ | 平方和單調性 |
| PKU 3061 Subsequence | ★☆☆☆☆ | 【例題2】求和單調性 |
| PKU 2739 Sum of Consecutive Prime Numbers | ★☆☆☆☆ | 素數篩選 + 求和單調性 |
| PKU 3320 Jessica’s Reading Problem | ★★☆☆☆ | 離散化 / 哈希 + 全集合連續子序列 |
| HDU 2158 最短區間版大家來找碴 | ★★☆☆☆ | 哈希 + 全集合連續子序列 |
| HDU 2369 Broken Keyboard | ★★☆☆☆ | 哈希 + 最長 m 子串 |
| HDU 5672 String | ★★☆☆☆ | 哈希 + m 子串方案數 |
| HDU 5056 Boring count | ★★☆☆☆ | 哈希 + m 子串方案數 |
| HDU 6205 card card card | ★★☆☆☆ | 前綴和 + 求和單調性 |
| HDU 5178 pairs | ★★☆☆☆ | 前綴和 + 求和單調性 |
| HDU 6103 Kirinriki | ★★★☆☆ | 列舉 + 求和單調性 |
| HDU 6119 小小粉絲度度熊 | ★★★☆☆ | 區間合并 + 前綴和 |
| HDU 1937 Finding Seats | ★★★☆☆ | 矩陣前綴和 + 求和單調性 |
| PKU 2566 Bound Found | ★★★☆☆ | 思維轉換 + 求和單調性 |
| HDU 5806 NanoApe Loves Sequence Ⅱ | ★★★☆☆ | 【例題4】思維轉換 + 求和單調性 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278434.html
標籤:其他