前言
配置的虛擬機為Centos6.7系統,hadoop版本為2.6.0版本,先前已經完成搭建CentOS部署Hbase、CentOS6.7搭建Zookeeper和撰寫MapReduce前置插件Hadoop-Eclipse-Plugin 安裝,在此基礎上完成了Hive詳解以及CentOS下部署Hive和Mysql和Spark框架在CentOS下部署搭建,Spark的組件Spark SQL的部署:Spark SQL CLI部署CentOS分布式集群Hadoop上方法,
配置JDK1.8、Scala11.12
本文將介紹DataFrame基礎操作以及實體運用,重點介紹直接在DataFrame物件上查詢的方法,
DataFrame查詢操作
第一種方法是將DataFrame注冊成為臨時表,通過SQL陳述句進行查詢,
第二種方法是直接在DataFrame物件上進行查詢,DataFrame的查詢操作也是一個懶操作,只有觸發Action操作才會進行計算并回傳結果,
DataFrame常用查詢結果:
| 方法 | 描述 |
| where | 條件查詢 |
| select/selectExpr/col/apply | 查詢指定欄位的資料資訊 |
| limit | 查詢前n行記錄 |
| order by | 排序查詢 |
| group by | 分組查詢 |
| join | 連接查詢 |
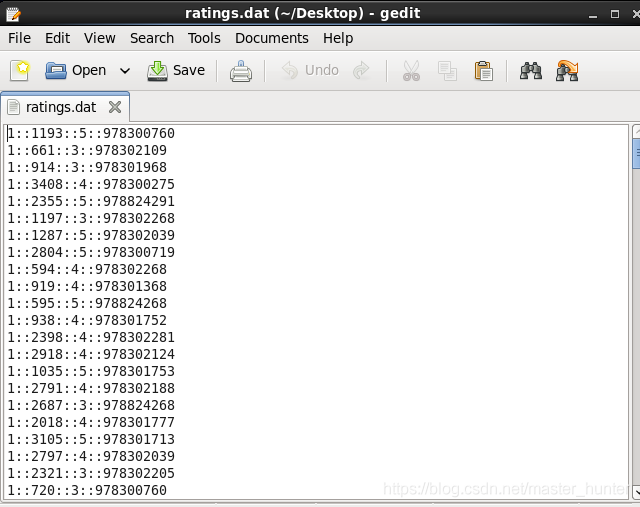
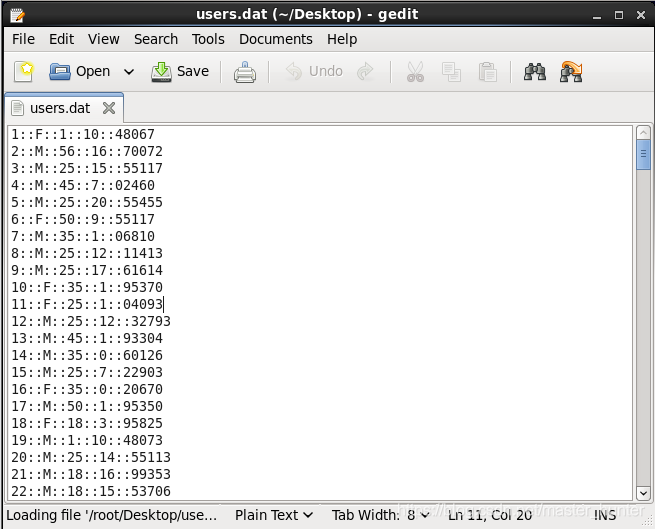
對于連接查詢有兩份資料用戶對電影評分資料ratings.dat和用戶的基本資訊資料users.dat,
ratings.dat4個欄位分別為:UserID,MovieID,Rating,Timestamp
users.dat5個欄位分別為:UserID,Gender,Age,Occupation,Zip-code
首先將檔案匯入,創建兩個case class:

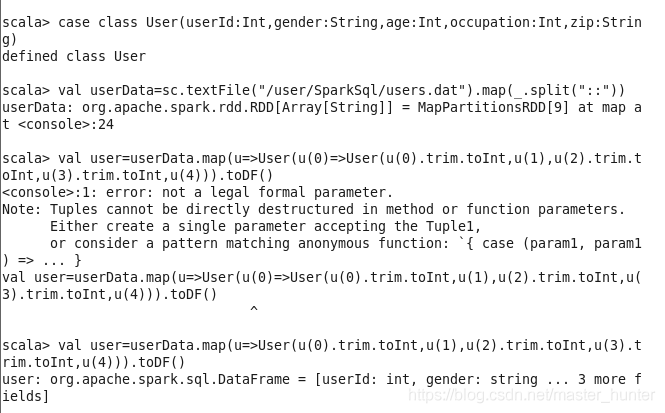
(一不小心敲錯了幾下~)
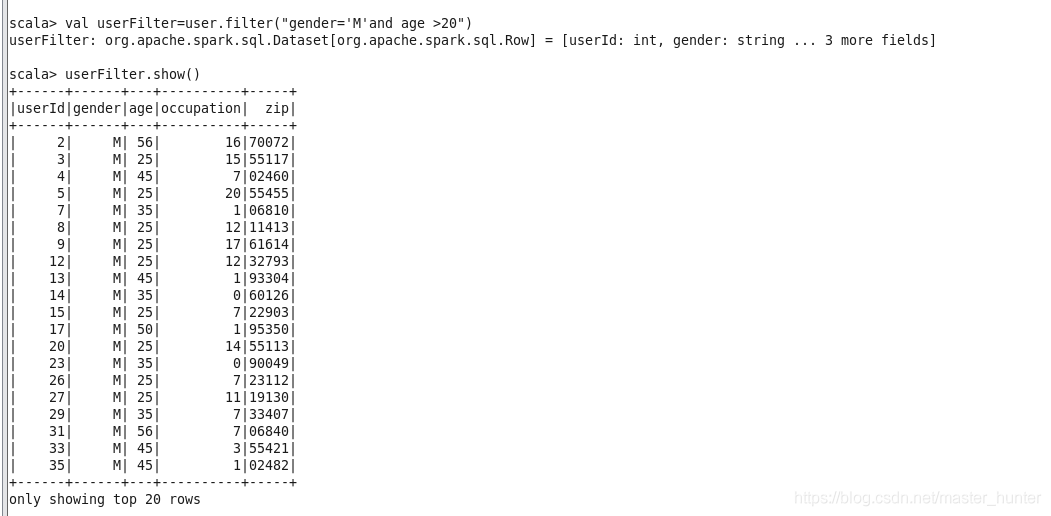
1.條件查詢
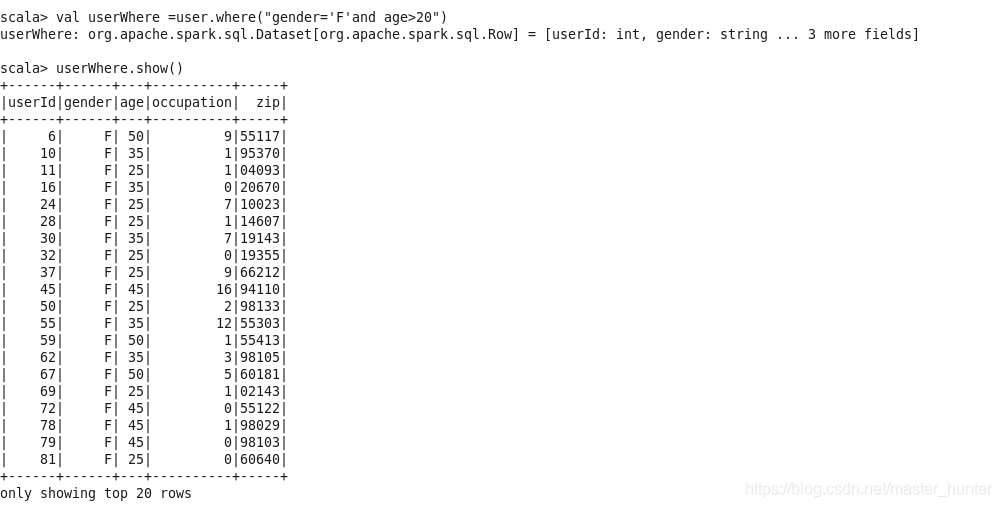
(1)where
DataFrame可以使用where(conditionExpr:String)根據指定條件進行查詢,引數中可以使用and或or,該方法的回傳結果仍為DataFrame型別,
(2)filter
filter和where使用方法一樣,
2.查詢指定欄位的資料資訊
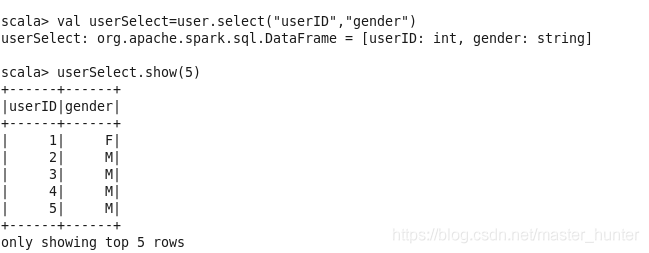
(1)select:獲取指定欄位值
select方法根據傳入的string型別欄位名獲取指定欄位的值,以DataFrame型別回傳,
(2)selectExpr:對指定欄位進行特殊處理
selectExpr可對欄位的名稱進行替換也可對欄位對于的數值進行替換,原表不變:
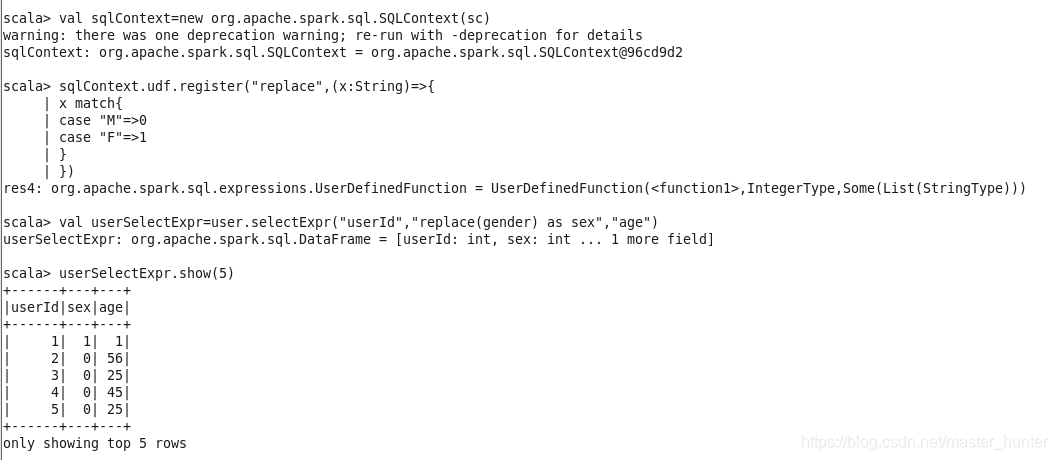
基本看一眼程式就知道是干什么的,很簡單,
(3)col/apply
col或者apply也可以獲取DataFrame指定欄位,但是只能獲取一個欄位,并且回傳物件為Column型別,

3.limit
limit方法獲取指定DataFrame的前n行記錄,得到一個新的DataFrame物件,不同于take與head,limit方法不是Action操作,

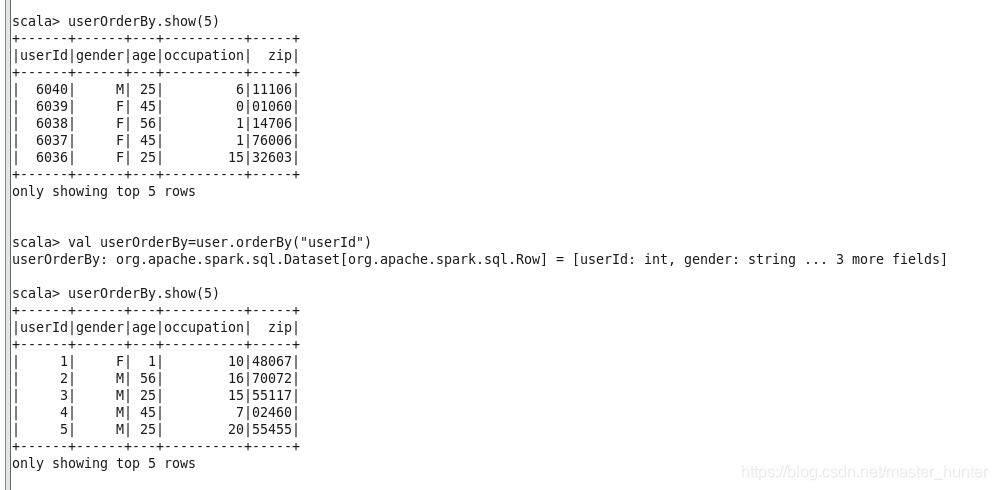
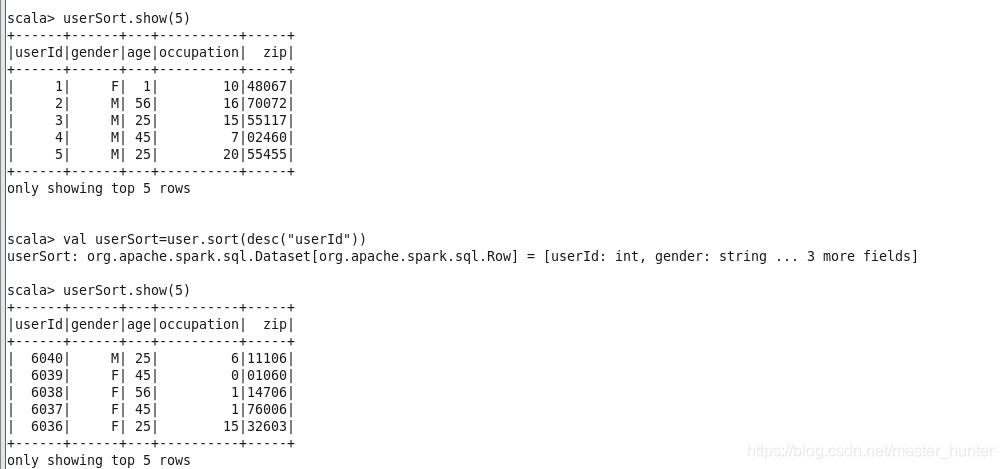
4.orderBy/sort
orderBy方法是根據指定欄位排序,默認為升序排序,若是降序可以用三種方法來表示
orderBy(desc.("userId"))
orderBy($"userId".desc)
orderBy(-user("userId"))
sort方法和orderBy方法一樣
5.groupBy
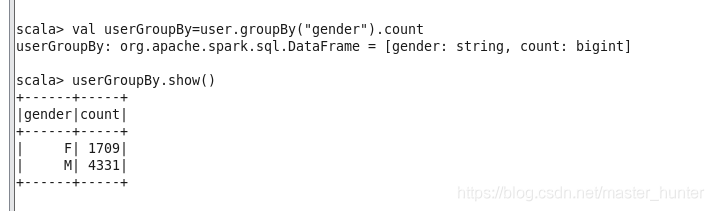
groupBy方法是根據欄位進行分組操作,groupBy方法有兩種呼叫方式,可以傳入String型別的欄位名,也可傳入Column型別的物件,groupBy回傳的是 RelationalGroupedDataset 物件,
GroupedData常用方法
| 方法 | 描述 |
| max(colNames:String) | 獲取分組中指定欄位或者所有的數值型別欄位的最大值 |
| min(colNames:String) | 獲取分組中指定欄位或者所有的數值型別欄位的最小值 |
| mean(colNames:String) | 獲取分組中指定欄位或者所有的數值型別欄位的平均值 |
| sum(colNames:String) | 獲取分組中指定欄位或者所有的數值型別欄位的值的和 |
| count() | 獲取分組中元素的個數 |
agg(expers:column*) 回傳dataframe型別 ,


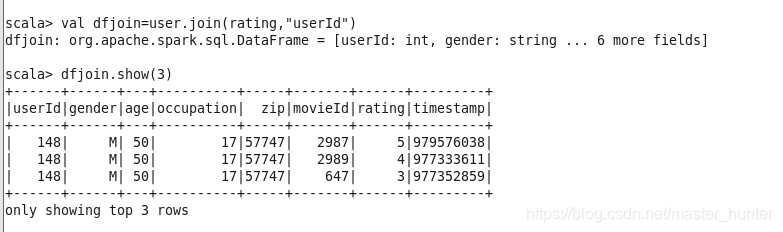
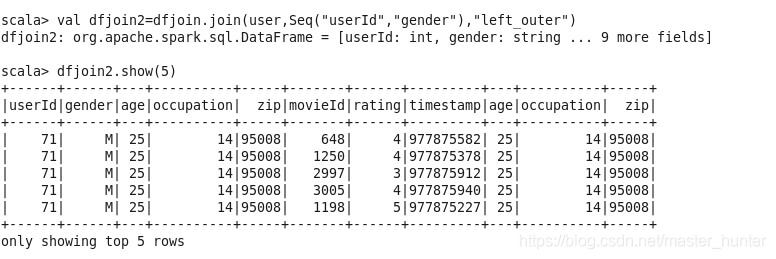
6.join
join可連接兩個表進行操作,資料庫常用函式,
join常用方法:
| 方法 | 描述 |
| join(right:DataFrame) | 兩個表做笛卡爾積 |
| join(right:DataFrame,joinExprs:Column) | 根據兩表中相同的某個欄位進行連接 |
| join(right:DataFrame,joinExprs:Column,joinType:String) | 根據兩表中相同的某個欄位進行連接并指定連接型別 |
spark2.x版本中默認不支持笛卡爾積操作,通過引數spark.sql.crossJoin.enabled開啟,方式如下:
spark.conf.set("spark.sql.crossJoin.enabled", "true")

DataFrame輸出操作
DataFrame API在提供了很多輸出操作方法,save方法可以將DataFrame保存成檔案,save操作有一個可選引數SaveMode,用這個引數可以指定如何處理資料已經存在的情況,另外,在使用HiveContext的時候,DataFrame可以用saveAsTable方法將資料保存成持久化的表,與registerTempTable不同,saveAsTable會將DataFrame的實際內容保存下來,并且在HiveMetastore中創建一個游標指標,持久化的表會一直保存,即使spark程式重啟也沒有影響,只要連接到同一個metastore就可以讀取其資料,讀取持久化表示,只需要用表明作為引數,呼叫SQLContext.table方法即可得到對應的DataFrame,
將DataFrame保存到同一個檔案里面有兩種方法,
(1)首先創建一個Map物件,用于存盤一些save函式需要用到的一些資料,這里將指定保存檔案路徑及JSON檔案的頭資訊

(2)從DataFrame物件中選擇出userId、gender和age

(3)呼叫save函式保存(2)中的DataFrame資料到copyOfUser.json檔案夾中
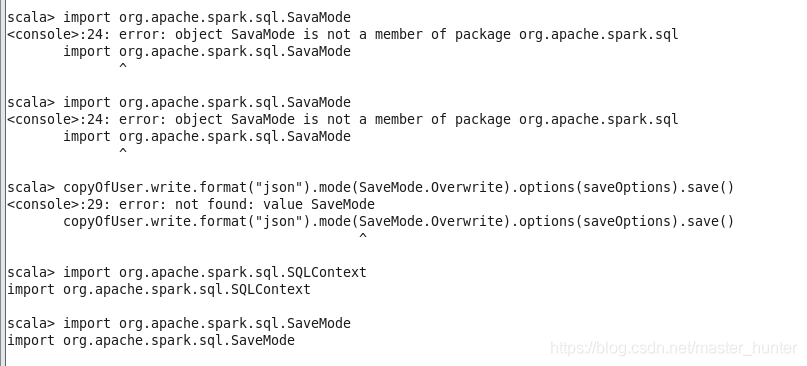
要加載SaveMode需要先加載SQLContext
![]()
mode函式可以接收的引數有Overwrite、Append、Ignore和ErrorIfExists,
Overwirte代表覆寫目錄之前就存在的資料,Append代表給指導目錄下追加資料,Ignore代表如果目錄下已經有的檔案,那就什么都不執行,ErrorIfExits代表如果保存目錄下存在的檔案,那么跑出相應的例外,
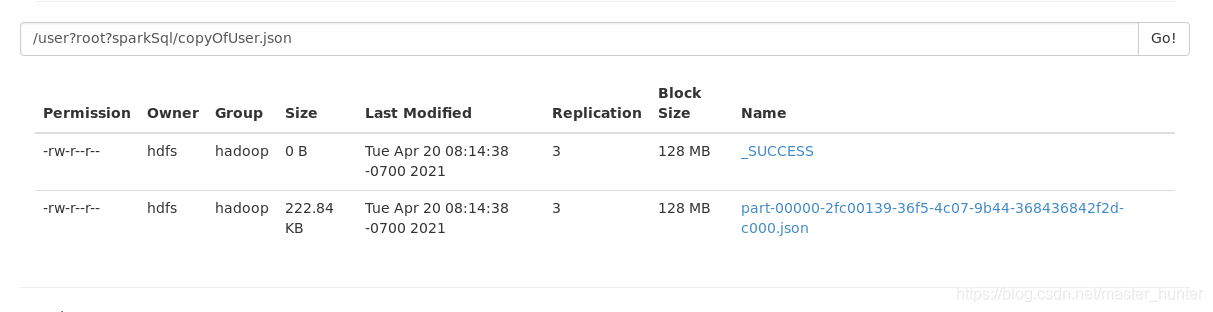
方法二為直接呼叫save方法

參閱
Spark DataSet常用action,及操作匯總
spark學習進度21(聚合操作、連接操作)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278441.html
標籤:其他