一、簡介
在語音去噪中最常用的方法是譜減法,譜減法是一種發展較早且應用較為成熟的語音去噪演算法,該演算法利用加性噪聲與語音不相關的特點,在假設噪聲是統計平穩的前提下,用無語音間隙測算到的噪聲頻譜估計值取代有語音期間噪聲的頻譜,與含噪語音頻譜相減,從而獲得語音頻譜的估計值,譜減法具有演算法簡單、運算量小的特點,便于實作快速處理,往往能夠獲得較高的輸出信噪比,所以被廣泛采用,該演算法經典形式的不足之處是處理后會產生具有一定節奏性起伏、聽上去類似音樂的“音樂噪聲”,
轉換到頻域后,這些峰值聽起來就像幀與幀之間頻率隨機變化的多頻音,這種情況在清音段尤其明顯,這種由于半波整流引起的“噪聲”被稱為“音樂噪聲”,從根本上,通常導致音樂噪聲的原因主要有:
(1)對譜減演算法中的負數部分進行了非線性處理
(2)對噪聲譜的估計不準
(3)抑制函式(增益函式)具有較大的可變性
1 原理




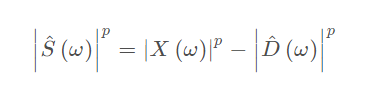
2 流程圖
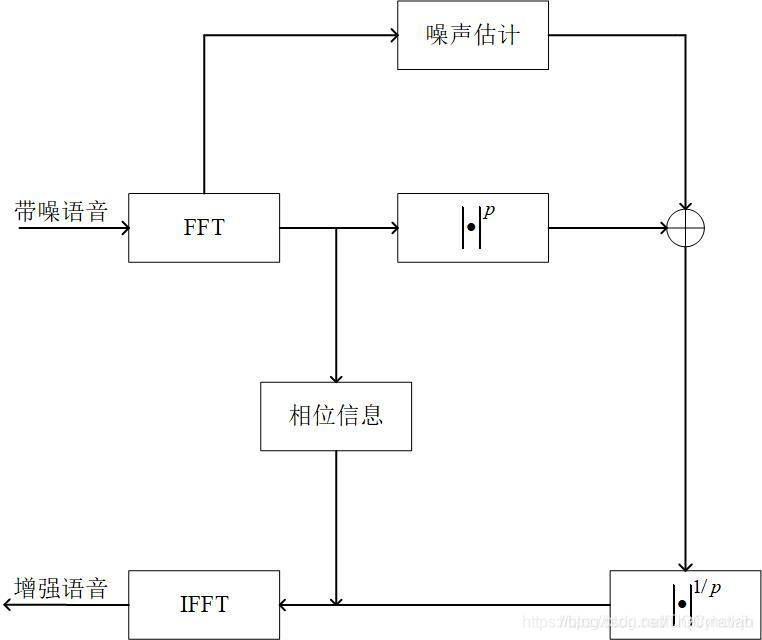
3 譜減法的缺點
1)由于對負值進行半波整流,導致幀頻譜的隨機頻率上出現小的、獨立的峰值,變換到時域上面,這些峰值聽起來就像幀與幀之間頻率隨機變化的多顫音,也就是通常所說的“音樂噪聲”(Musical Noise)
2)另外,譜減法還存在一個小缺點就是使用帶噪語音的相位作為增強后語音的相位,因此產生語音的質量可能比較粗糙,尤其是在低信噪比的條件下,可能會達到被聽覺感知的程度,降低語音的質量,
為了更好的理解譜減法語音增強,這里對該演算法進行簡單仿真,仿真引數設定如下

二、源代碼
%%三種語音增強方法的測驗腳本
%******************************************************
% 在audioread函式中可以設定讀入的語音信號
% 改變SNR的值即可改變加入的噪聲
%
[Input, Fs] = audioread('sp01.wav');
Time = (0:1/Fs:(length(Input)-1)/Fs)';
%取單聲道
Input = Input(:,1);
%SNR為加入噪聲與純凈信號的信噪比(dB)
SNR=15;
[NoisyInput,Noise] = add_noise(Input,SNR);%NoisyInput為加噪信號,Noise是噪聲
%% 三種語音增強方法的實作
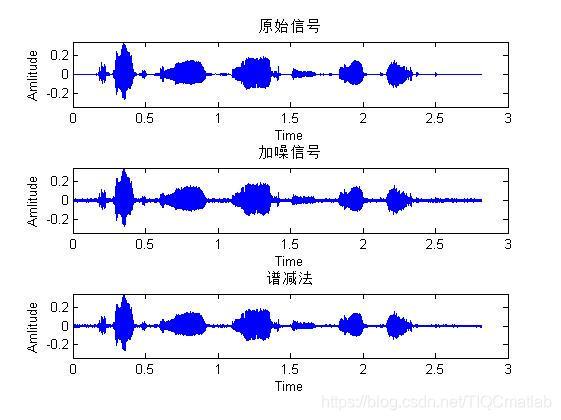
[spectruesub_enspeech] = spectruesub(NoisyInput);
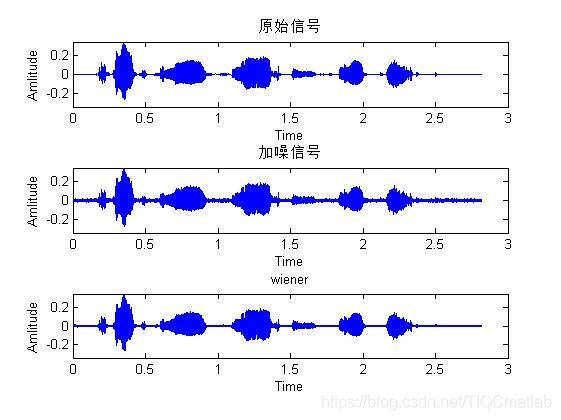
[wiener_enspeech] = wienerfilter(NoisyInput);
[Klaman_Output] = kalman(NoisyInput,Fs,Noise);
sound(Input,8000)
sound(spectruesub_enspeech,8000)
sound(wiener_enspeech,8000)
sound(Klaman_Output,8000)
%% spectruesub繪制
%將信號長度對齊
sig_len=length(spectruesub_enspeech);
NoisyInput=NoisyInput(1:sig_len);
Input=Input(1:sig_len);
wiener_enspeech=wiener_enspeech(1:sig_len);
Klaman_Output=Klaman_Output(1:sig_len);
Time = (0:1/Fs:(sig_len-1)/Fs)';
% Time= ((0:1/Fs:(sig_len)-1)/Fs)';
figure(1)
MAX_Am(1)=max(Input);
MAX_Am(2)=max(NoisyInput);
MAX_Am(3)=max(spectruesub_enspeech);
subplot(3,1,1);
plot(Time, Input)
ylim([-max(MAX_Am),max(MAX_Am)]);
xlabel('Time')
ylabel('Amlitude')
title('原始信號')
subplot(3,1,2);
plot(Time, NoisyInput)
ylim([-max(MAX_Am),max(MAX_Am)]);
xlabel('Time')
ylabel('Amlitude')
title('加噪信號')
%% wiener繪制
% Time_wiener = (0:1/Fs:(length(wiener_enspeech)-1)/Fs)';
figure(2)
MAX_Am(1)=max(Input);
MAX_Am(2)=max(NoisyInput);
MAX_Am(3)=max(wiener_enspeech);
subplot(3,1,1);
plot(Time, Input)
ylim([-max(MAX_Am),max(MAX_Am)]);
xlabel('Time')
ylabel('Amlitude')
title('原始信號')
subplot(3,1,2);
plot(Time, NoisyInput)
ylim([-max(MAX_Am),max(MAX_Am)]);
xlabel('Time')
ylabel('Amlitude')
title('加噪信號')
function [wiener_enspeech] = wienerfilter(testsignal)
%維納濾波器函式
testsignal=testsignal';
frame_len=256; %幀長
step_len=0.5*frame_len; %分幀時的步長,相當于重疊50%
wav_length=length(testsignal);
R = step_len;
L = frame_len;
f = (wav_length-mod(wav_length,frame_len))/frame_len;
k = 2*f-1; % 幀數
h = sqrt(1/101.3434)*hamming(256)'; % 漢寧窗乘以系數的原因是使其復合條件要求;
% testsignal = testsignal(1:f*L); % 帶噪語音與純凈語音長度對齊
% signal= signal(1:f*L);
win = zeros(1,f*L); % 設定初始值;
wiener_enspeech = zeros(1,f*L);
%-------------------------------分幀-------------------------------------
for r = 1:k
y = testsignal(1+(r-1)*R:L+(r-1)*R); % 對帶噪語音幀間重疊一半取值;
y = y.*h; % 對取得的每一幀都加窗處理;
w = fft(y); % 對每一幀都作傅里葉變換;
Y(1+(r-1)*L:r*L) = w(1:L); % 把傅里葉變換值放在Y中;
end
%-------------------------------估計噪聲-----------------------------------
NOISE= stationary_noise_evaluate(Y,L,k); %噪聲最小值跟蹤演算法
% 每幀中的傅里葉變換和噪聲估計均如上所示
%-------------------------------winner-------------------------------------
for t = 1:k
X = abs(Y).^2;
S=max((X(1+(t-1)*L:t*L)-NOISE(1+(t-1)*L:t*L)),0);
G_k=(X(1+(t-1)*L:t*L)-NOISE(1+(t-1)*L:t*L))./X(1+(t-1)*L:t*L);
S = sqrt(S);
A1=G_k.*S;
A = Y(1+(t-1)*L:t*L)./abs(Y(1+(t-1)*L:t*L)); % 帶噪于語音的相位;
S = A1.*A; % 因為人耳對相位的感覺不明顯,所以恢復時用的是帶噪語音的相位資訊;
s = ifft(S);
s = real(s); % 取實部;
wiener_enspeech(1+(t-1)*L/2:L+(t-1)*L/2) = wiener_enspeech(1+(t-1)*L/2:L+(t-1)*L/2)+s; % 在實域疊接相加;
win(1+(t-1)*L/2:L+(t-1)*L/2) = win(1+(t-1)*L/2:L+(t-1)*L/2)+h; % 窗的疊接相加;
end
wiener_enspeech = wiener_enspeech./win; % 去除加窗引起的增益得到增強的語音;
wiener_enspeech=wiener_enspeech';
end
function [Output] = kalman(NoisyInput,Fs,Noise)
% 卡爾曼濾波函式
% 基礎變數設定
Len_windowT = 0.0025; % 窗長2.5ms
Hop_Percent = 1; % 窗移占比
AR_Order = 20; % 自回歸濾波器階段
Num_Iter = 7; %迭代次數
% [Input, Fs] = audioread('six.wav');
% Input = Input(:,1);
% Noise = normrnd(0,sqrt(0.001),size(Input));
% NoisyInput = Input + Noise;
% Time = (0:1/Fs:(length(Input)-1)/Fs)';
%分幀加窗處理
Len_WinFrame = fix(Len_windowT * Fs);
Window = ones(Len_WinFrame,1);
[Frame_Signal, Num_Frame] = KFrame(NoisyInput, Len_WinFrame, Window, Hop_Percent);
%初始化
H = [zeros(1,AR_Order-1),1]; % 觀測矩陣
R = var(Noise); % 噪聲方差
[FiltCoeff, Q] = lpc(Frame_Signal, AR_Order); % LPC預測,得到濾波器的系數
P = R * eye(AR_Order,AR_Order); % 誤差協方差矩陣
Output = zeros(1,size(NoisyInput,1)); % 輸出信號
Output(1:AR_Order) = NoisyInput(1:AR_Order,1)'; %初始化輸出信號
OutputP = NoisyInput(1:AR_Order,1);
% 迭代器的次數.
i = AR_Order+1;
j = AR_Order+1;
%進行卡爾曼濾波
for k = 1:Num_Frame %一次處理一幀信號
jStart = j; %跟蹤每次迭代AR_Order+1的值.
OutputOld = OutputP; %為每次迭代保留第一批AROrder預估量
for l = 1:Num_Iter
A = [zeros(AR_Order-1,1) eye(AR_Order-1); fliplr(-FiltCoeff(k,2:end))];
for ii = i:Len_WinFrame
%Kalman濾波基本方程式
OutputC = A * OutputP;
Pc = (A * P * A') + (H' * Q(k) * H);
K = (Pc * H')/((H * Pc * H') + R);
OutputP = OutputC + (K * (Frame_Signal(ii,k) - (H*OutputC)));
Output(j-AR_Order+1:j) = OutputP';
P = (eye(AR_Order) - K * H) * Pc;
j = j+1;
end
i = 1;
if l < Num_Iter
j = jStart;
OutputP = OutputOld;
end
% 更新濾波后信號的lpc
[FiltCoeff(k,:), Q(k)] = lpc(Output((k-1)*Len_WinFrame+1:k*Len_WinFrame),AR_Order);
end
end
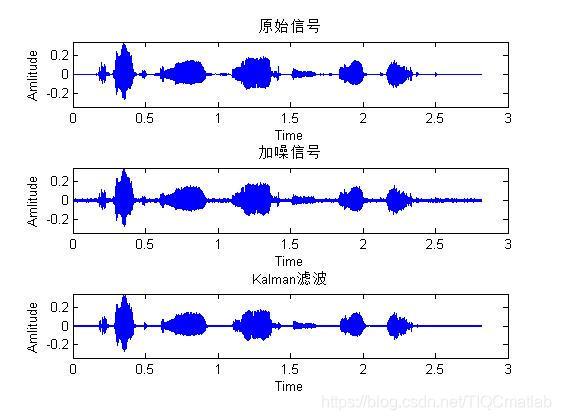
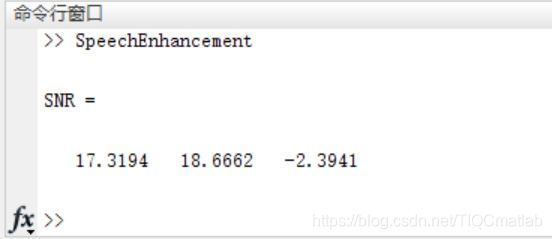
三、運行結果
四、備注
完整代碼或者代寫添加QQ 1564658423
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278563.html
標籤:其他