前言
寫了那個圖書館預約腳本發現吸引了很多小白,然后發現他們學了爬蟲,但是可能并不知道爬蟲的本質和原理,可能看完視頻或者教程覺得自己已經懂了,然后換了一個網站發現就懂爬教程里的那一個,因為寫爬蟲難的不是代碼的實作,寫一些小爬蟲代碼能有多難?不會就百度嘛,難的主要是資料包的分析,看完這一篇基本能讓你會爬取所有的小網站了,
爬蟲的實質
我們在瀏覽器中點擊、輸入等操作可以簡化為下圖,
以下是一個簡化的登錄流程圖,
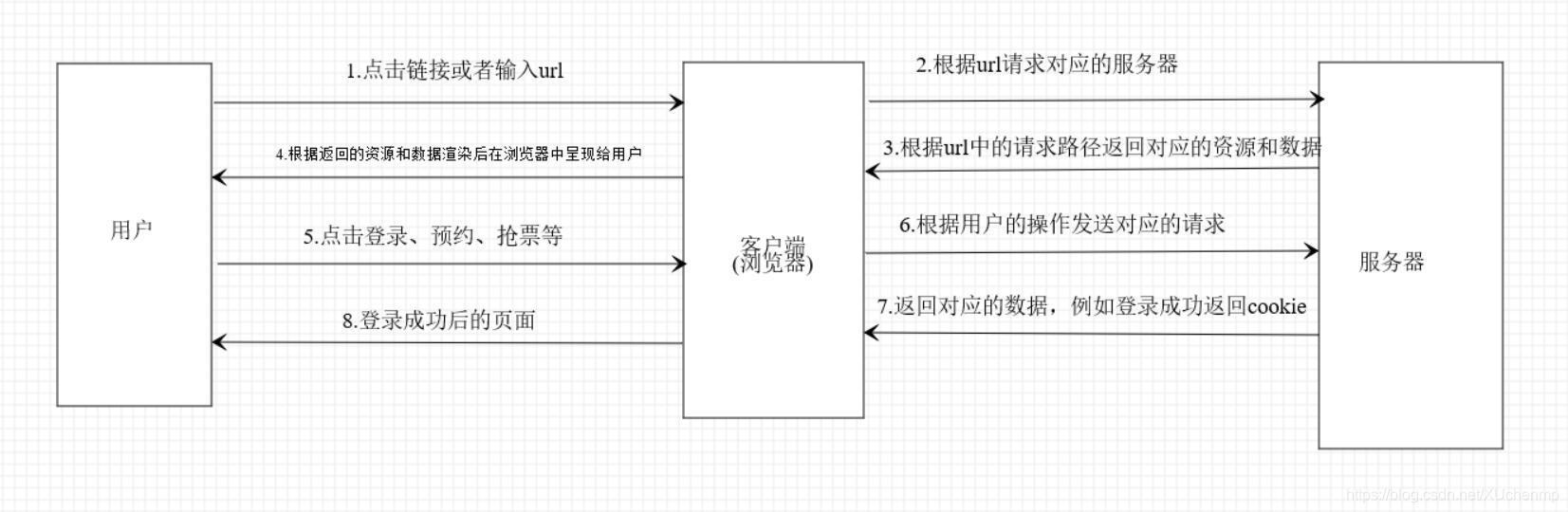 這是一個簡化圖,但是可以知道,用戶在瀏覽器上做什么操作實質上都是瀏覽器向服務器發送資料包、接收資料包,
這是一個簡化圖,但是可以知道,用戶在瀏覽器上做什么操作實質上都是瀏覽器向服務器發送資料包、接收資料包,
無論是爬蟲(例如:爬取小說)還是自動化腳本(例如:圖書館搶座)的實質都是發送資料包、接收資料包,如圖: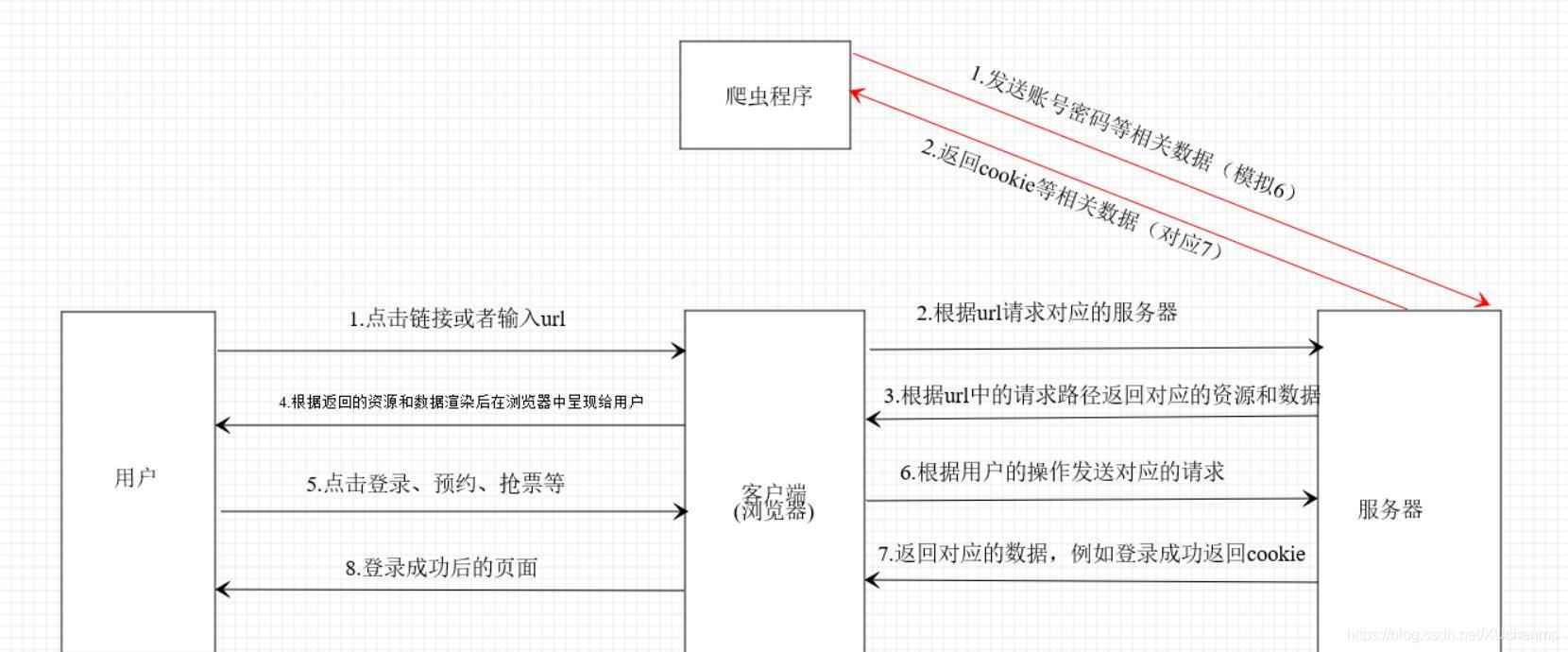 可以看到,登錄的話我們只需要發送一個關鍵的資料包就可以,不需要那么多沒用的資料包,當然這是簡化版,有一些網站登錄可不止發送一個資料包,這就需要自己抓包、發包測驗分析了,
可以看到,登錄的話我們只需要發送一個關鍵的資料包就可以,不需要那么多沒用的資料包,當然這是簡化版,有一些網站登錄可不止發送一個資料包,這就需要自己抓包、發包測驗分析了,
看到這可能有些人已經按耐不住內心的激動去找個網站試試了,先別急,不然一會又回來了多少有點尷尬,
分析資料包的小技巧
如果你以為打開一個網頁或者做某一個操作都是發送一個資料包那就太天真了,不信點f12然后打開百度看看,那資料包看的你頭皮發麻,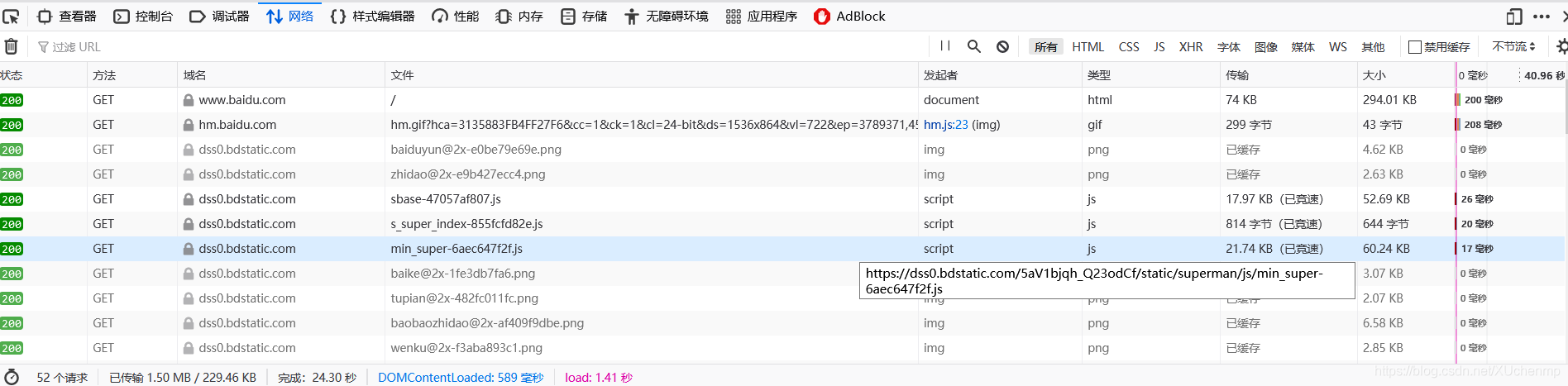 52個請求,就,挺懵逼的,
52個請求,就,挺懵逼的,
不過這是大網站嘛,這么多挺正常,一般的小網站不會有這么多,那么如何在多個資料包中找出你最想要的那些呢,
1.根據請求的路徑、名稱等
比如說你要找登錄的關鍵資料包,你就找登錄的對應關鍵字嘛,比如說login、logincheck啥的,可能有些低級網站指不定還有denglu這樣的,這就要靠個人經驗了,爬多了啥都能見到,
2.根據型別
還是拿百度舉例子,假如你要找登錄包(我打開的是首頁,只是用來舉個例子),像這些js、gif、css、png、還有我也不知道的plain基本沒用,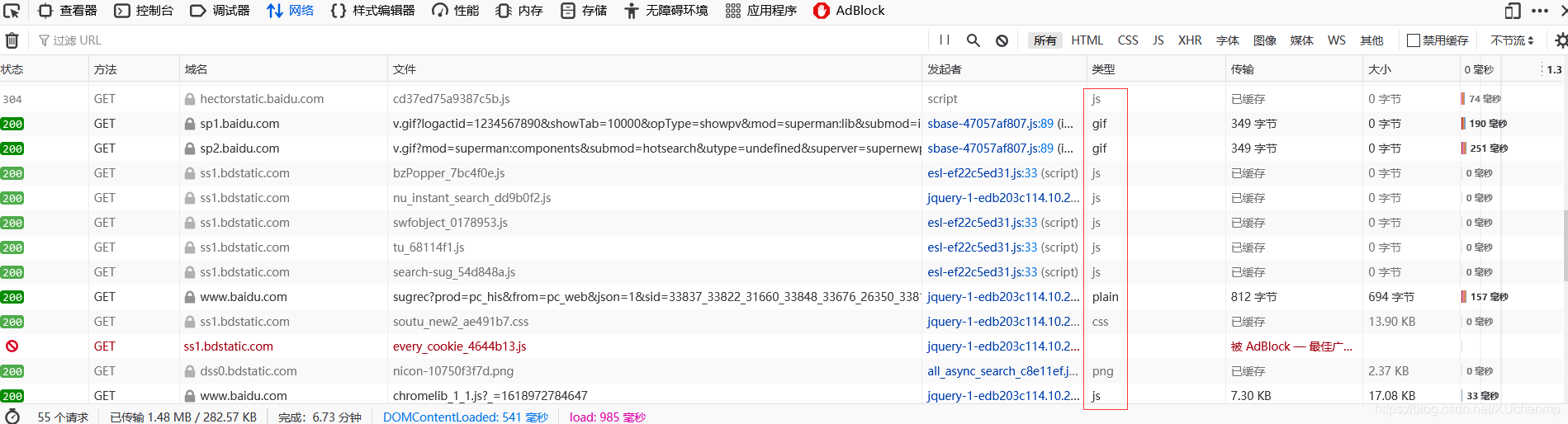 畢竟登錄你管那些圖片、gif圖干啥,如果有圖片驗證碼直接選擇元素找到就行了,
畢竟登錄你管那些圖片、gif圖干啥,如果有圖片驗證碼直接選擇元素找到就行了,
結語
看到這基本上能幫小白對爬蟲的理解更進了一步,分析一些簡單的包不在話下了,你別跟我說把包分析出來了不會用寫程式模擬發包,看我揍不揍你就完事了,
如果是爬資料的話還要xpath等決議、包復雜分析不出來的話可以用selenium,這些就自行百度吧,網上有的我也懶得寫了,
覺得有用的話點個贊吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278802.html
標籤:其他