【干貨滿滿】
最近由于面試需要,回顧了SQL當中的視窗函式,并整理了面試以及實際作業中常用的幾種視窗函式,話不多說,直接上干貨!!!
文章目錄
- 前言
- 一、聚合函式作為視窗函式sum()、avg()、max()、min()、count()
- 1、應用場景
- 2、語法結構
- 3、案例說明
- 二、磁區排序視窗函式row_number()、rank()、dense_rank()
- 1、應用場景
- 2、語法結構
- 3、案例說明
- 三、分組排序視窗函式ntile()
- 1、應用場景
- 2、語法結構
- 3、案例說明
- 四、偏移分析視窗函式lag()、lead()
- 1、應用場景
- 2、語法結構
- 3、案例說明
- 五、結語
前言
回想當初我在學習SQL視窗函式時,基本概念心中已大致有了了解,但是具體視窗函式型別以及相同型別不同視窗函式的用法區別一直混淆,我相信大家在學習視窗函式相關知識時也會有同樣的困惑,
因此我決定在本篇文章中視窗函式的基本概念就不做過多介紹了,直接講解幾種常用視窗函式的具體用法,以案例練習題加圖表說明的方式大家理解起來會更加容易,但是,如果大家有需要可以評論或者私信我再出一版SQL視窗函式的基本概念以及與普通group by的區別,同時也會附帶大量SQL練習題講解哦,
一、聚合函式作為視窗函式sum()、avg()、max()、min()、count()
1、應用場景
1、截止到某月累計數值問題
2、計算移動平均等問題
3、連續多個月中,單月最大支付金額問題
2、語法結構
以sum聚合函式為例:
sum(欄位名A) over(partition by 欄位名B order by 欄位名C rows between D1 and D2)
其中:
① partition by:按照某一欄位將資料進行分組;
② order by:按照某一欄位將資料進行排序,默認升序ASC,可設定為降序DESC;
③ 欄位名A:被聚合操作的欄位;
④ 欄位名B:通過該欄位進行分組;
⑤ 欄位名C:通過該欄位進行排序;
⑥ D1:行數的起始范圍;
⑦ D2:行數的結束范圍;
rows between D1 and D2用法如下:
rows between unbounded preceding and current row——包括本行和之前所有的行
rows between current row and unbounded following——包括本行和之前所有的行
rows between 2 preceding and current row——包括本行和前2行
rows between 2 preceding and 1 following——包括前2行、本行和下一行
3、案例說明
現有一張2020年某店鋪各個月份商品的銷售數量情況統計表,表名為sale:
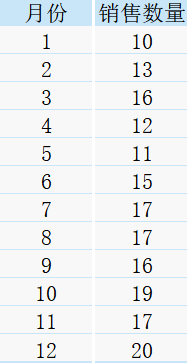
下面我們來試一試,當同時執行不同的視窗函式時,會出現什么樣的效果,
select *,
sum(銷售數量) over(order by 月份) as sum_value,
avg(銷售數量) over(order by 月份) as avg_value,
max(銷售數量) over(order by 月份) as max_value,
min(銷售數量) over(order by 月份) as min_value,
count(銷售數量) over(order by 月份) as count_value
from sale;
得到如下結果:
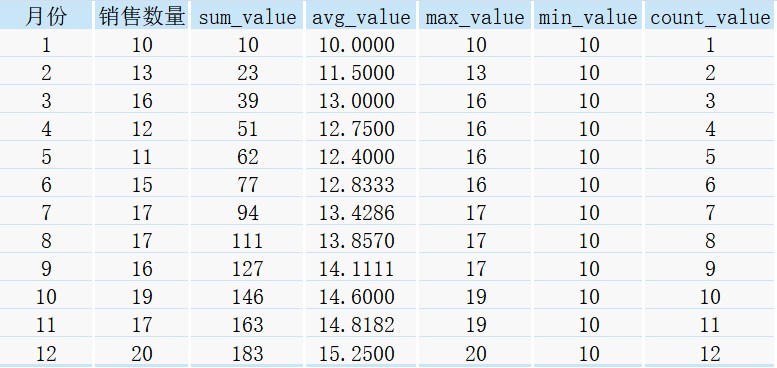
下面分別介紹每種結果的計算程序:
①sum作為視窗函式:
sum作為視窗函式,其計算的值 = 自身對應的資料 + 自身之上所有的資料
直接上圖,大家理解起來可能更加容易!!!
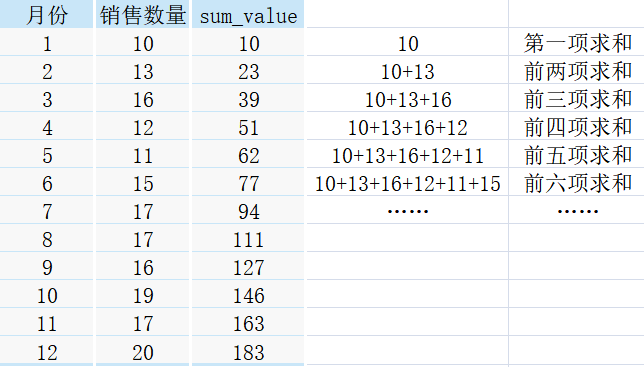
根據上圖的計算程序,想必大家已經直觀的體會到sum作為視窗函式是怎么使用的了吧,
②avg作為視窗函式:
avg作為視窗函式,其計算的值 = (自身對應的資料 + 自身之上所有的資料)/ 資料個數
簡單粗暴,直接上圖!!!

唉,我去?avg不就是根據sum計算的結果得來的嗎,沒錯,不過當你回過頭去看看count計算的結果之后,你會發現,avg計算的值其實就是sum計算的值 / count計算的值,
③max作為視窗函式:
max作為視窗函式,其實就和拍賣商品一個道理,比比誰大就完事了
圖來!!!
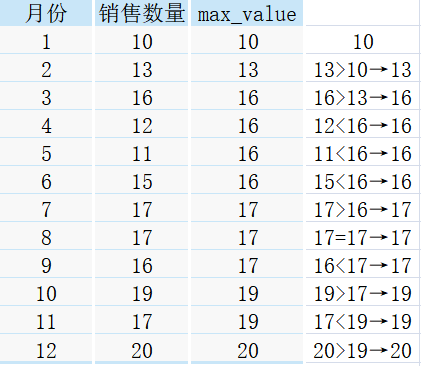
看到這里,相信有著聰明小腦瓜的你已經明白聚合函式作為視窗函式是怎么使用的了,其它兩個聚合函式的使用方法就不做過多介紹了, 在這里參考一位梗王的口頭禪:
Don’t say so much(無需多言) ———這街3.霹靂小雞
二、磁區排序視窗函式row_number()、rank()、dense_rank()
1、應用場景
1、top N問題,即解決每一個分組中最大或最小的N條記錄
2、分組排名問題
2、語法結構
1、row_number() over(partition by 欄位名A order by 欄位名B )
2、rank() over(partition by 欄位名A order by 欄位名B )
3、dense_rank() over(partition by 欄位名A order by 欄位名B )
3、案例說明
現有一張班級各科成績表score,如下所示:
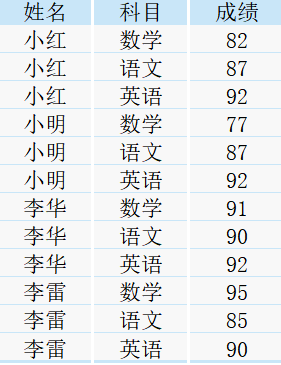
下面我們來試一試,當同時執行不同的視窗函式時,會出現什么樣的效果,
select *,
row_number() over(partition by 科目 order by 成績 desc) as row_number_val,
rank() over(partition by 科目 order by 成績 desc) as rank_val,
dense_rank() over(partition by 科目 order by 成績 desc) as dense_rank_val
from score;
執行上述SQL后,得到如下結果:
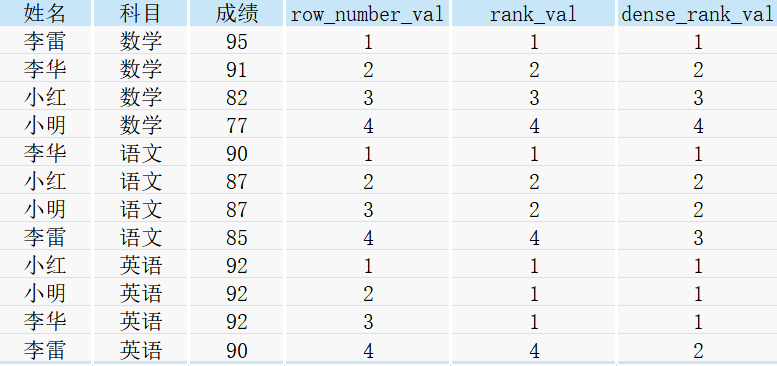
由于我們設定了partition by 科目 order by 成績 desc,所以上述結果首先按照科目進行分組,再按照成績由高到低進行排序,
我們單拿出英語科目的結果來比較row_number()、rank()、dense_rank()三者的不同

① row_number():會為每一行記錄都生成一個序號,依次進行排序且不會重復,形如1、2、3、4
② rank():會將記錄相同的行排成相同的序號,且進行跳躍式的排序,如有三行序號為1時,接下來的行序號就為4,即第二行和第三行中的序號1各占了一個位置,形如1、1、1、4
③ dense_rank():會將記錄相同的行排成相同的序號,且進行連續排序,如有三行序號為1時,接下來的行序號就為2,形如1、1、1、2
三、分組排序視窗函式ntile()
1、應用場景
1、將資料按照某一欄位進行分組
2、分組排名,取前N%,注意區分和取top N不同
2、語法結構
ntile(n) over(partition by 欄位名A order by 欄位名B )
其中,n為分的組數,
3、案例說明
現有一張表student,里面包含了學號、科目以及對應的考試成績
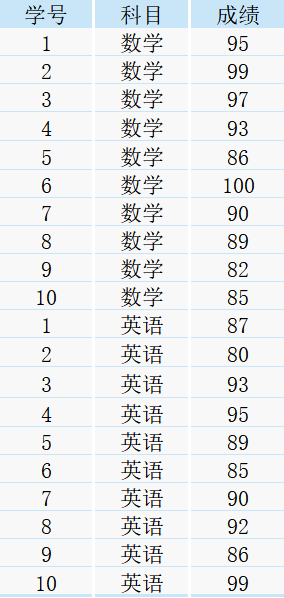
需求1:將各科目按照成績高低分成五組
select *,
ntile(5) over(partition by 科目 order by 成績 desc) as level
from student;
得到如下結果:
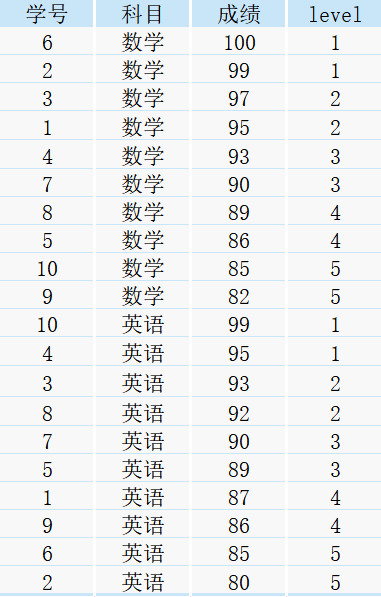
分析:由于我們的需求是將各科目按照成績高低進行分組,所以設定了partition by 科目 order by 成績 desc,分的組數為5組,所以,ntile(n)里的引數n直接設定為5,
需求2:將各科目按照成績高低排序,取出前20%的資料
select a.*
from
(select *,
ntile(5) over(partition by 科目 order by 成績 desc) as level
from student) a
where a.level = 1;
得到如下結果:
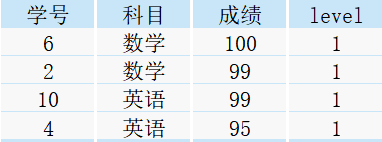
分析:由于每個科目都各有10條記錄,我們取前20%的資料,這里參考小學(不知道是幾年級)的計算公式可得:20% × 10 = 2,所以我們按照成績高低進行排序后,取每個科目的前兩條記錄即可,因此該需求依舊是需要對資料進行分組,然后取序號為1的記錄,
總結:
1、ntile(n) 用于將資料按照某一順序進行分組,并回傳組號;
2、若分組后每組中的資料個數不均勻,會把最后面組中多出來的資料分到第一組中;
3、n為一個正整數,
四、偏移分析視窗函式lag()、lead()
1、應用場景
1、取時間間隔為N天的記錄
2、求本次記錄與上一次記錄的差值
3、取某一欄位的前N行資料或后N行資料
2、語法結構
lag(欄位A,偏移量,默認值) over(partition by 欄位B order by 欄位C)
lead(欄位A,偏移量,默認值) over(partition by 欄位B order by 欄位C)
其中:
① 欄位A:操作欄位名稱;
② 偏移量:假設當前記錄所在的行是第6行,當使用lag()視窗函式時,若將偏移量設定為2,則表示要找的記錄所在的行是(6-2)= 4,可不寫此引數,默認偏移量為1;
③ 默認值:當向上或者向下取值超過表的范圍時,兩個函式會將默認值引數對應的值作為函式的回傳值,可不寫此引數,當超過表范圍時,默認回傳NULL;
3、案例說明
現有一張客戶A的消費記錄明細表customer,里面包含了客戶A每次消費的時間,
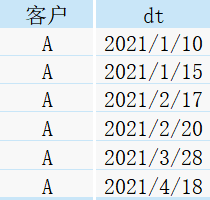
當分別執行偏移分析視窗函式時:
select *,
lag(dt,1,dt) over(order by dt),
lag(dt) over(order by dt),
lead(dt,1,dt) over(order by dt),
lead(dt) over(order by dt)
from customer;
得到如下結果:
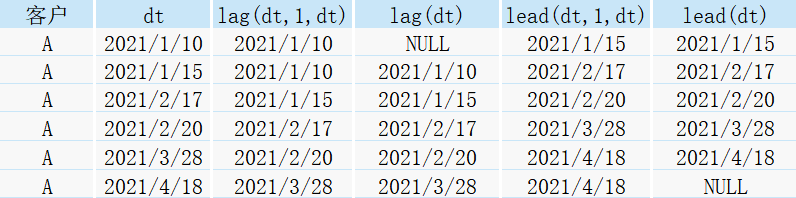
用法分析: lag()為向上偏移、lead為向下偏移,
其對應關系如下表所示:
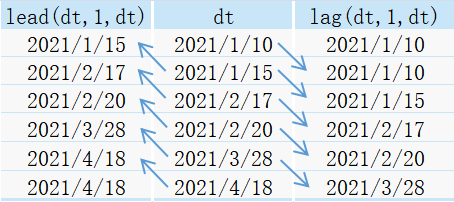
若求當前記錄與上1次記錄或者下1次記錄的差值時,利用lag()或lead()視窗函式即可實作
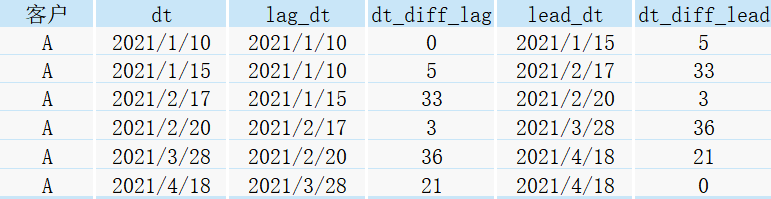
select *,
lag(dt,1,dt) over(order by dt) as lag_dt,
datediff(dt,lag_dt) as dt_diff_lag
lead(dt,1,dt) over(order by dt) as lead_dt,
datediff(lead_dt,dt) as dt_diff_lead
from customer;
得到如下結果:
五、結語
最后祝大家SQL學習之路越來越順利,博主也會定期更新資料分析、資料挖掘、機器學習演算法、深度學習演算法的學習筆記哦,我也經歷了這個程序,懂得大家的需求點,保證都是總結出來的干貨,歡迎關注,一起進步!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278830.html
標籤:其他