目錄
一、Title
二、arXiv
三、Background
四、Model
五、Experiments
Experiment 1
Experiment 2
Experiment 3
Experiment 4
論文閱讀時間:2021-4-20 20:07:56
一、Title
Multi-Modal Attention-based Fusion Model for Semantic Segmentation of RGB-Depth Images
二、arXiv
arXiv
三、Background

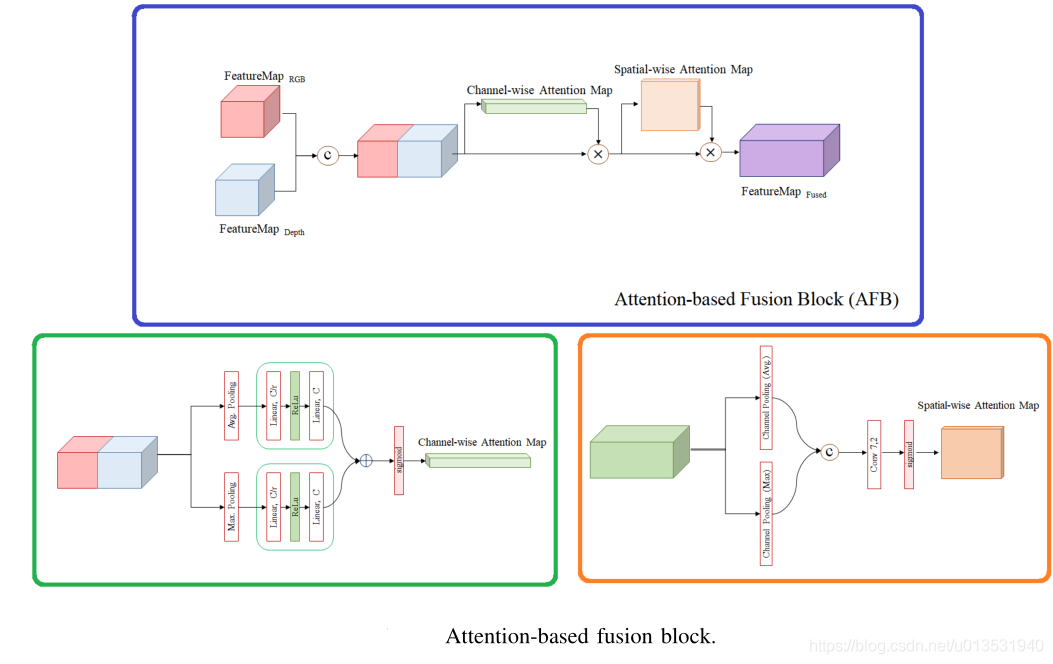
基于注意力機制的融合模塊受注意力機制的啟發,該網路注重于feature maps的channel-wise recalibration,對通道的dependency進行建模,從兩個編碼器的RGB和深度通道提取的中間特征圖作為基于注意力機制的融合塊的輸入,基于注意力機制的融合塊計算attention maps,attention maps再乘以輸入的feature maps以進行自適應特征融合,基于注意力機制的融合模塊由通道方向和空間方向的注意力機制組成,來構建attention maps,因此,基于兩種模態在不同通道之間的相互依賴性來融合它們的feature maps,圖2說明了基于注意力機制的融合塊的架構,此外,每個AFB之后是lightweight chained redisual pooling layers,用于考慮解碼器側的全域背景關系資訊,
四、Model
MMAF-Net以RGB和深度模態的兩個編碼器分支同時作為輸入,同時包含一個解碼器分支,在解碼器分支中,基于新提出的注意融合模塊,融合同一解析度下兩個編碼器分支的特征圖,將外觀和3D特征圖結合起來,這些融合的feature map被用來恢復編碼器的資訊丟失,并產生高解析度的預測輸出,
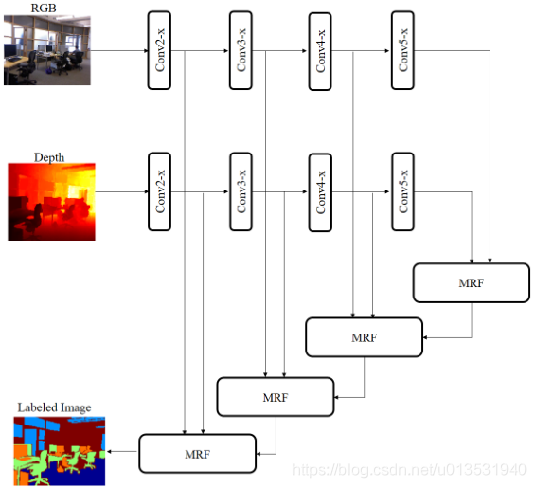
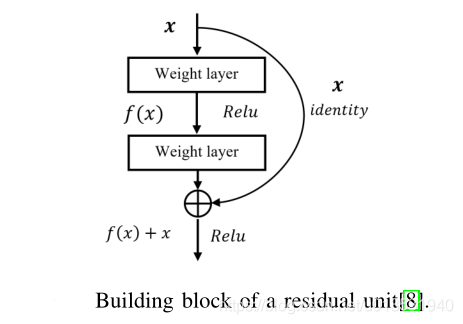
提出的模型利用ResNet模型(Convi-x)的residual blocks作為兩個獨立的編碼器分支,在deep residual network中使用identity map函式,
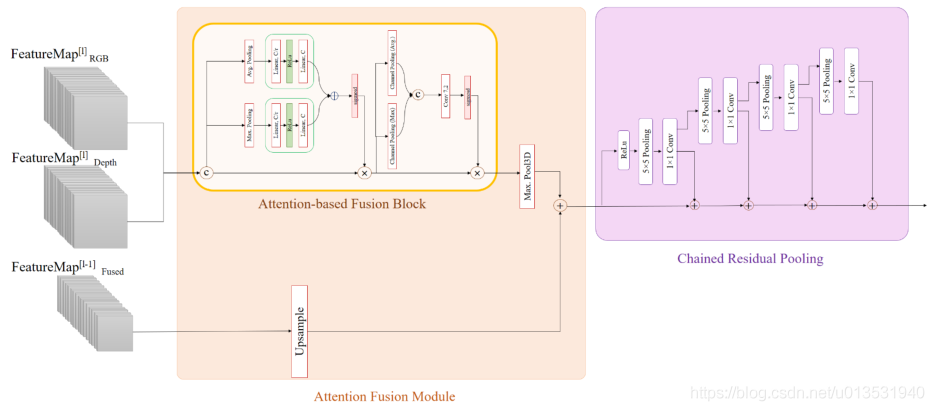
encoder branch的residual block的輸出作為long跳躍連接,被饋送到解碼器的4個級聯子模塊,稱為多模態多解析度融合(MRF)模塊,MRF模塊的結構見下圖,
五、Experiments
Experiment 1
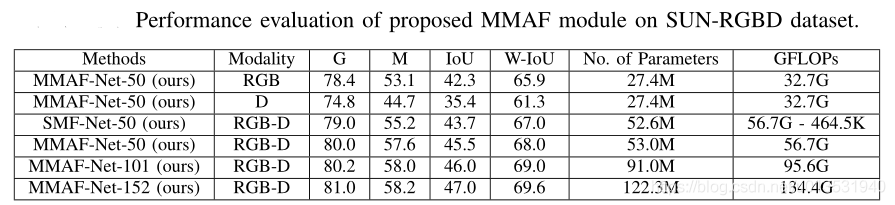
Experiment 2
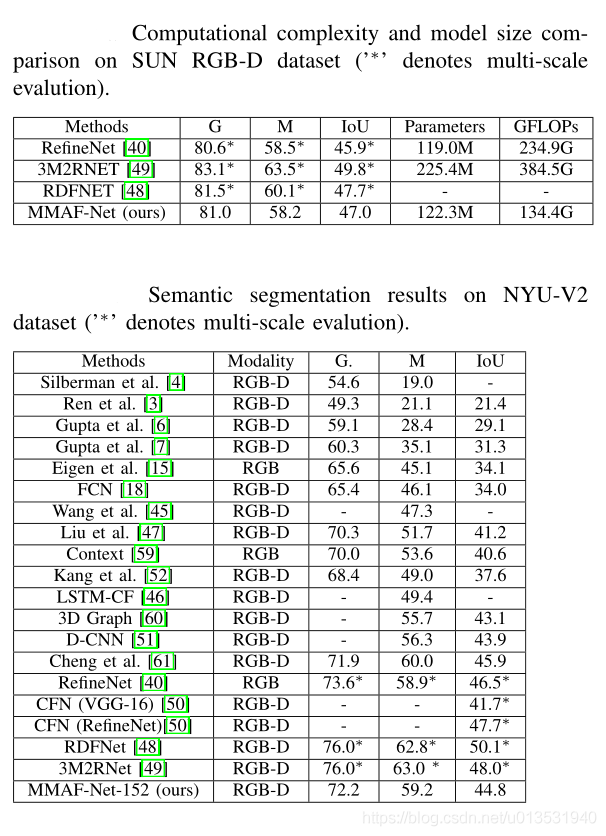
Experiment 3
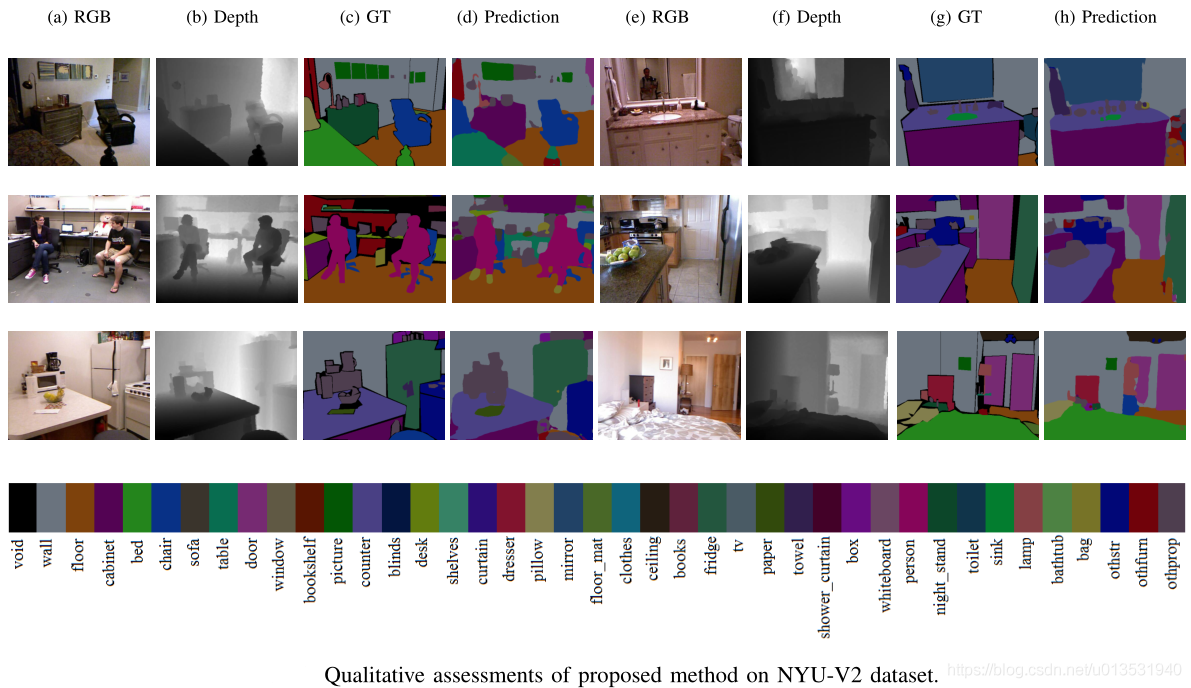
Experiment 4
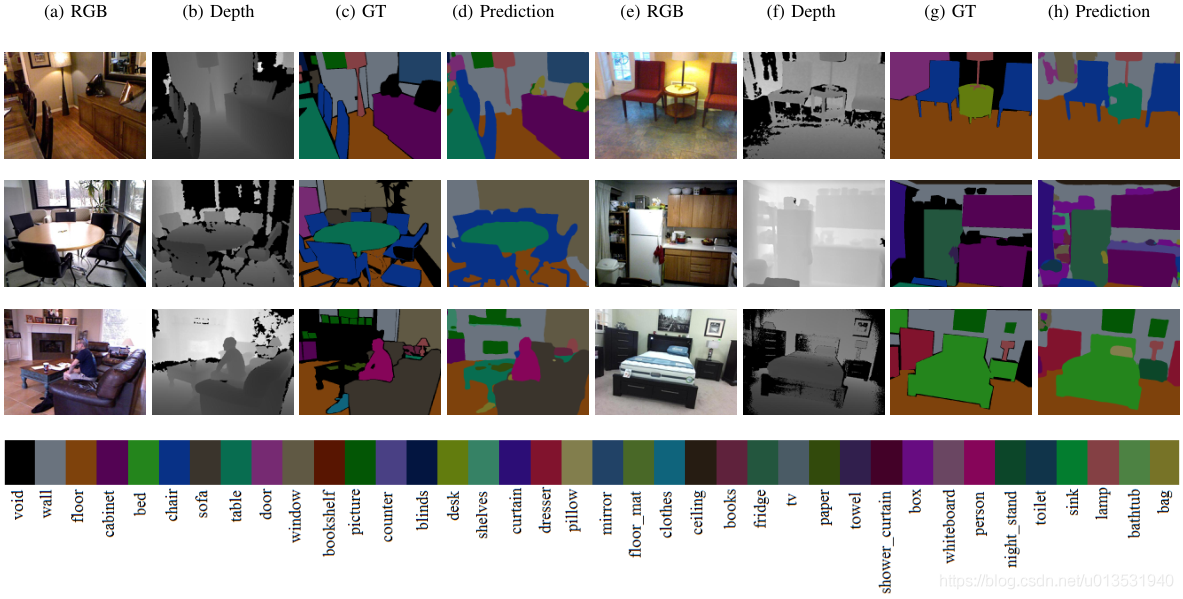
論文閱讀時間:2021-4-20 20:07:56
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/278960.html
標籤:其他