文章目錄
- 一、希爾排序法
- 二、實體:使用希爾排序法進行遞增排序
- 三、練習:熱門游戲下載量排名
本系列文章通過 1000(一篇文章表示 1 個實體) 個實體 ,為讀者提供較為詳細的練習題目,以便讀者舉一反三,深度學習,本系列的文章涉及到 Python 知識點包括:Python 語言基礎、運算子和運算式、陳述句和程式結構、串列和元組、字典和集合、字串、正則運算式、函式、面向物件編程、模塊和包、例外處理和程式除錯、檔案和目錄操作、資料庫編程、界面編程、網路編程、WEB 編程、行程和執行緒、網路爬蟲、游戲編程等知識點,由易到難,由淺入深,一步步打下堅實的編程基礎,
本系列文章涉及的演算法包括搜索、回溯、遞回、排序、迭代、貪心、分治和動態規劃等,涉及的資料結構包括字串、串列、指標、區間、佇列、矩陣、堆疊、鏈表、哈希表、線段樹、二叉樹、二叉搜索樹和圖結構等,
本系列文章是筆者為適應當前教育改革的創新要求,更好地踐行語言類課程,滿足實踐教學與創新能力培養的需要,閱讀大量書籍、各大互聯網公司的面試演算法、LintCode、LeetCode、九章演算法和結合筆者近幾年專案經驗撰寫的系列文章,精選了 1000 個趣味性、實用性強的應用實體,從不同難度、不同演算法、不同型別和不同資料結構等方面,將實際演算法進行總結,希望為 Python 編程人員拋磚引玉,由于筆者經驗與水平有限,博文中疏漏及不妥之處在所難免,衷心地希望各位讀者在評論區多提寶貴意見及具體的修改建議,以便筆者進一步修改和完善,
一、希爾排序法
希爾排序法是插入排序法的一種,是直接插入排序演算法的更高級的改進版本,希爾排序法可以減少插入排序法中資料移動的次數,加快排序的進行,因此它被稱為縮小增量排序,希爾排序法排序的原則是將原始資料分成特定間隔的幾組資料,然后使用插入排序法對每組資料進行排序,排序之后,再減小間隔距離,然后重復插入排序法對每組資料排序,直到所有資料完成排序為止,希爾排序法最后的結果有兩種形式,即遞增數列和遞減數列,接下來通過一組資料來演示希爾排序法的排序原理,
例如,一組原始資料:60,82,17,35,52,73,54,9,如下圖所示:

按照遞增進行排序,步驟如下:
步驟1:從上圖中可以看出,原始值中有8個資料,將間隔位數設定為8/2=4,即將原始值分為四組數列,分別為:數列1(60,52)、數列2(82,73)、數列3(17,54)、數列4(35,9),如下圖所示,將每個數列內的資料進行排序,按照左小右大的原則,將位置錯誤的資料進行交換,即數列1(52,60)、數列2(73,82)、數列3(17,54)和數列4(9,35),
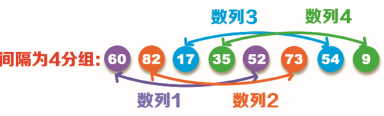
說明:間隔位數不一定必須除以2,可以根據自己的需求而定,
步驟2:將步驟1排序后的數列進行插入放置,得出第一次排序結果,如下圖所示:

步驟3:接著縮小間隔[(8/2)/2=2],即將原數列分為兩組數列,分別為:數列1(52,17,60,54)、數列2(82,35,73,9),如下圖所示,然后再對上圖中的每個數列內的資料進行排序,按照從小到大的順序,將位置錯誤的資料進行交換,即數列1(17,52,54,60)和數列2(9,35,73,82),
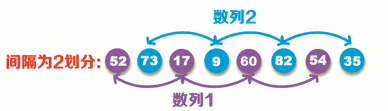
步驟4:將步驟3排序后的數列進行插入放置,得出第二次排序結果,如下圖所示:

步驟5:再以[((8/2)/2)]2=1取間隔數,對第二次排序后的數列(如上圖所示)中的每一個元素進行排序,得到最后的結果如下圖所示:

至此,排序完成,
二、實體:使用希爾排序法進行遞增排序
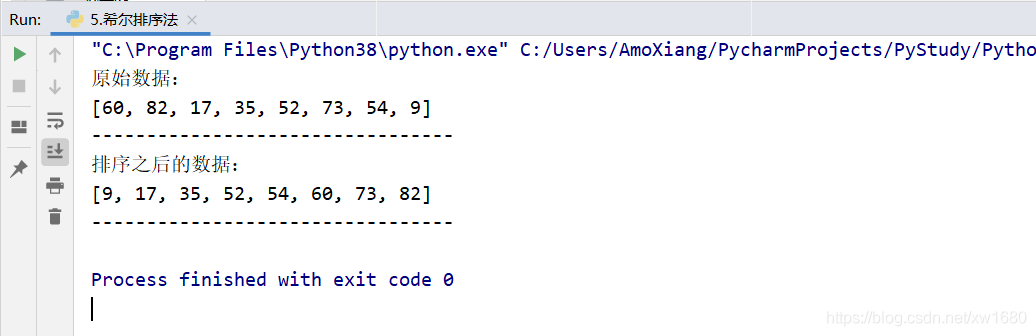
使用希爾排序法為串列:60,82,17,35,52,73,54,9進行遞增排序,具體代碼如下:
def hill(data): # 自定義希爾排序函式
n = len(data) # 獲取資料長度
step = n // 2 # 讓步長從大變小,最后一步必須是1,獲取gap的偏移值
while step >= 1: # 只要gap在我們的合理范圍內,就一直分組下去
# 按照步長把資料分兩半,從步長的位置遍歷后面所有的資料,指定j下標的取值范圍
for j in range(step, n):
while j - step >= 0: # 拿當前位置的資料,跟當前位置-gap位置的資料進行比較
if data[j] < data[j - step]: # 組內大小元素進行替換操作
data[j], data[j - step] = data[j - step], data[j]
j -= step # 更新遷移元素的下標值為最新值
else: # 否則的話,不進行替換
break
step //= 2 # 每執行完畢一次分組內的插入排序,對gap進行/2細分
data = [60, 82, 17, 35, 52, 73, 54, 9] # 定義串列并初始化
print("原始資料:")
print(data) # 輸出原資料
print("---------------------------------")
hill(data) # 呼叫自定義希爾排序函式
print("排序之后的資料:")
print(data) # 輸出排序之后資料
print("---------------------------------")
程式運行結果如下圖所示:
三、練習:熱門游戲下載量排名
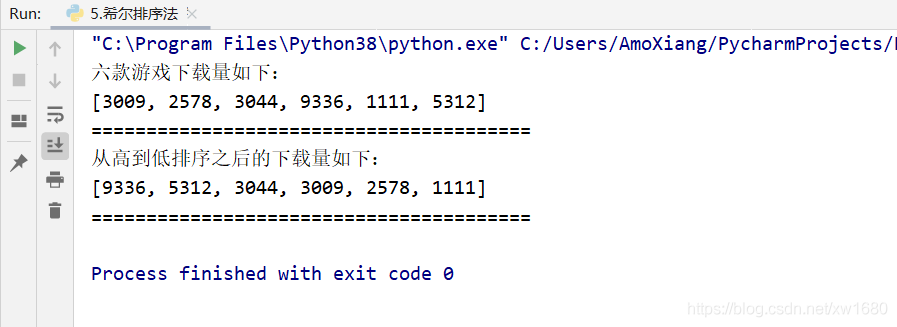
游戲是很多人消遣時間的一種方式,在手機的軟體安裝商店里,也有各類游戲,假設有6款游戲,它們的下載量(單位是萬次)分別是:3009,2578,3044,9336,1111,5312,利用希爾排序法為下載量按照從高到低順序進行排序,具體代碼如下:
def hill(data): # 自定義希爾排序函式
n = len(data) # 獲取資料長度
step = n // 2 # 讓步長從大變小,最后一步必須是1,獲取gap的偏移值
while step >= 1: # 只要gap在我們的合理范圍內,就一直分組下去
# 按照步長把資料分兩半,從步長的位置遍歷后面所有的資料,指定j下標的取值范圍
for j in range(step, n):
while j - step >= 0: # 拿當前位置的資料,跟當前位置-gap位置的資料進行比較
if data[j] > data[j - step]: # 組內大小元素進行替換操作
data[j], data[j - step] = data[j - step], data[j]
j -= step # 更新遷移元素的下標值為最新值
else: # 否則的話,不進行替換
break
step //= 2 # 每執行完畢一次分組內的插入排序,對gap進行/2細分
data = [3009, 2578, 3044, 9336, 1111, 5312] # 定義串列并初始化
print("六款游戲下載量如下:")
print(data) # 輸出原資料
print("========================================")
hill(data) # 呼叫自定義希爾排序函式
print("從高到低排序之后的下載量如下:")
print(data) # 輸出排序之后資料
print("========================================")
程式運行結果如下圖所示:
感謝您閱讀本篇博文,希望本文能成為您編程路上的領航者,祝您閱讀愉快!

好書不厭讀百回,熟讀課思子自知,而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用博客見證成長,用行動證明我在努力,
如果我的博客對你有幫助、如果你喜歡我的博客內容,請點贊、評論、收藏一鍵三連哦!聽說點贊的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我博客看看,
?編碼不易,大家的支持就是我堅持下去的動力,點贊后不要忘了關注我哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279338.html
標籤:其他