參考了Mask-RCNN實體分割模型的訓練教程:
- pytorch官方的Mask-RCNN實體分割模型訓練教程:TORCHVISION OBJECT DETECTION FINETUNING TUTORIAL
- 官方Mask-RCNN訓練教程的中文翻譯:手把手教你訓練自己的Mask R-CNN影像實體分割模型(PyTorch官方教程)
在Mask-RCNN實體分割模型訓練的基礎上稍作修改即可實作Faster-RCNN目標檢測模型的訓練
相關網頁:
- torchvision自帶的影像分類、語意分割、目標檢測、實體分割、關鍵點檢測、視頻分類模型:TORCHVISION.MODELS
- torchvision Github專案地址: https://github.com/pytorch/vision
1. 準備作業
除了需要安裝pytorch和torchvision外,還需要安裝COCO的API pycocotools
windows系統安裝pycocotools的方法:Windows下安裝pycocotools
匯入相關包和模塊:
import torch
import os
import numpy as np
import cv2
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
from PIL import Image
from xml.dom.minidom import parse
%matplotlib inline
2. 定義資料集
我使用的是自己使用labelme進行標注后轉為voc格式的目標檢測資料集,除了背景外有兩種標簽(mark_type_1和mark_type_2),即num_classes=3
我的voc資料集的目錄結構如下圖所示:

Annotations檔案夾下的xml標注舉例:
<annotation>
<folder/>
<filename>172.26.80.5_01_20191128084208520_TIMING.jpg</filename>
<database/>
<annotation/>
<image/>
<size>
<height>1536</height>
<width>2048</width>
<depth>3</depth>
</size>
<segmented/>
<object>
<name>mark_type_1</name>
<pose/>
<truncated/>
<difficult/>
<bndbox>
<xmin>341.4634146341463</xmin>
<ymin>868.2926829268292</ymin>
<xmax>813.4146341463414</xmax>
<ymax>986.5853658536585</ymax>
</bndbox>
</object>
<object>
<name>mark_type_1</name>
<pose/>
<truncated/>
<difficult/>
<bndbox>
<xmin>1301.2195121951218</xmin>
<ymin>815.8536585365853</ymin>
<xmax>1769.512195121951</xmax>
<ymax>936.5853658536585</ymax>
</bndbox>
</object>
</annotation>
該標注包含了一個類別(mark_type_1)的兩個bbox
定義資料集:
class MarkDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
# load all image files, sorting them to ensure that they are aligned
self.imgs = list(sorted(os.listdir(os.path.join(root, "JPEGImages"))))
self.bbox_xml = list(sorted(os.listdir(os.path.join(root, "Annotations"))))
def __getitem__(self, idx):
# load images and bbox
img_path = os.path.join(self.root, "JPEGImages", self.imgs[idx])
bbox_xml_path = os.path.join(self.root, "Annotations", self.bbox_xml[idx])
img = Image.open(img_path).convert("RGB")
# 讀取檔案,VOC格式的資料集的標注是xml格式的檔案
dom = parse(bbox_xml_path)
# 獲取檔案元素物件
data = https://www.cnblogs.com/wildgoose/p/dom.documentElement
# 獲取 objects
objects = data.getElementsByTagName('object')
# get bounding box coordinates
boxes = []
labels = []
for object_ in objects:
# 獲取標簽中內容
name = object_.getElementsByTagName('name')[0].childNodes[0].nodeValue # 就是label,mark_type_1或mark_type_2
labels.append(np.int(name[-1])) # 背景的label是0,mark_type_1和mark_type_2的label分別是1和2
bndbox = object_.getElementsByTagName('bndbox')[0]
xmin = np.float(bndbox.getElementsByTagName('xmin')[0].childNodes[0].nodeValue)
ymin = np.float(bndbox.getElementsByTagName('ymin')[0].childNodes[0].nodeValue)
xmax = np.float(bndbox.getElementsByTagName('xmax')[0].childNodes[0].nodeValue)
ymax = np.float(bndbox.getElementsByTagName('ymax')[0].childNodes[0].nodeValue)
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.as_tensor(labels, dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((len(objects),), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
# 由于訓練的是目標檢測網路,因此沒有教程中的target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
# 注意這里target(包括bbox)也轉換\增強了,和from torchvision import的transforms的不同
# https://github.com/pytorch/vision/tree/master/references/detection 的 transforms.py里就有RandomHorizontalFlip時target變換的示例
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
3. 定義模型
有兩種方式來修改torchvision默認的目標檢測模型:第一種,采用預訓練的模型,在修改網路最后一層后finetuning微調;第二種,根據需要替換掉模型中的骨干網路,如將ResNet替換成MobileNet等,
這兩種方法的具體使用可以參考最文章開頭的官方教程以及官方教程翻譯,在這里我選擇了第一種方法,
定義模型可以簡單的使用:
torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False, progress=True, num_classes=3, pretrained_backbone=True)
也可參考教程的寫法:
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
def get_object_detection_model(num_classes):
# load an object detection model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# replace the classifier with a new one, that has num_classes which is user-defined
num_classes = 3 # 3 class (mark_type_1,mark_type_2) + background
# get the number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
4. 資料增強
在影像輸入到網路前,需要對其進行資料增強,這里需要注意的是,由于Faster R-CNN模型本身可以處理歸一化(默認使用ImageNet的均值和標準差來歸一化)及尺度變化的問題,因而無需在這里進行mean/std normalization或影像縮放的操作,
由于from torchvision import的transforms只能對圖片進行資料增強,而無法同時改變圖片對應的label標簽,因此我們選擇使用torchvision Github專案中的一些封裝好的用于模型訓練和測驗的函式:https://github.com/pytorch/vision/tree/master/references/detection
其中的engine.py、utils.py、transforms.py、coco_utils.py、coco_eval.py我們會用到,把這些檔案下載下來,我把這些檔案放在了正在寫的Faster-RCNN目標檢測模型訓練.ipynb腳本的旁邊
查看下載下來的transforms.py,可以看到它里面就有對影像進行水平翻轉(RandomHorizontalFlip)時target(bbox)變換的示例:
class RandomHorizontalFlip(object):
def __init__(self, prob):
self.prob = prob
def __call__(self, image, target):
if random.random() < self.prob:
height, width = image.shape[-2:]
image = image.flip(-1)
bbox = target["boxes"]
bbox[:, [0, 2]] = width - bbox[:, [2, 0]]
target["boxes"] = bbox
if "masks" in target:
target["masks"] = target["masks"].flip(-1)
if "keypoints" in target:
keypoints = target["keypoints"]
keypoints = _flip_coco_person_keypoints(keypoints, width)
target["keypoints"] = keypoints
return image, target
由此撰寫相應的資料增強函式:
import utils
import transforms as T
from engine import train_one_epoch, evaluate
# utils、transforms、engine就是剛才下載下來的utils.py、transforms.py、engine.py
def get_transform(train):
transforms = []
# converts the image, a PIL image, into a PyTorch Tensor
transforms.append(T.ToTensor())
if train:
# during training, randomly flip the training images
# and ground-truth for data augmentation
# 50%的概率水平翻轉
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
5. 訓練模型
至此,資料集、模型、資料增強的部分都已經寫好,在模型初始化、優化器及學習率調整策略選定后,就可以開始訓練了,在每個epoch訓練完成后,我們還要在測驗集上對模型的性能進行評價,
from engine import train_one_epoch, evaluate
import utils
root = r'資料集路徑'
# train on the GPU or on the CPU, if a GPU is not available
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# 3 classes, mark_type_1,mark_type_2,background
num_classes = 3
# use our dataset and defined transformations
dataset = MarkDataset(root, get_transform(train=True))
dataset_test = MarkDataset(root, get_transform(train=False))
# split the dataset in train and test set
# 我的資料集一共有492張圖,差不多訓練驗證4:1
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-100])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-100:])
# define training and validation data loaders
# 在jupyter notebook里訓練模型時num_workers引數只能為0,不然會報錯,這里就把它注釋掉了
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, # num_workers=4,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=2, shuffle=False, # num_workers=4,
collate_fn=utils.collate_fn)
# get the model using our helper function
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False, progress=True, num_classes=num_classes, pretrained_backbone=True) # 或get_object_detection_model(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
# SGD
optimizer = torch.optim.SGD(params, lr=0.0003,
momentum=0.9, weight_decay=0.0005)
# and a learning rate scheduler
# cos學習率
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=1, T_mult=2)
# let's train it for epochs
num_epochs = 31
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
# engine.py的train_one_epoch函式將images和targets都.to(device)了
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=50)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
print('')
print('==================================================')
print('')
print("That's it!")
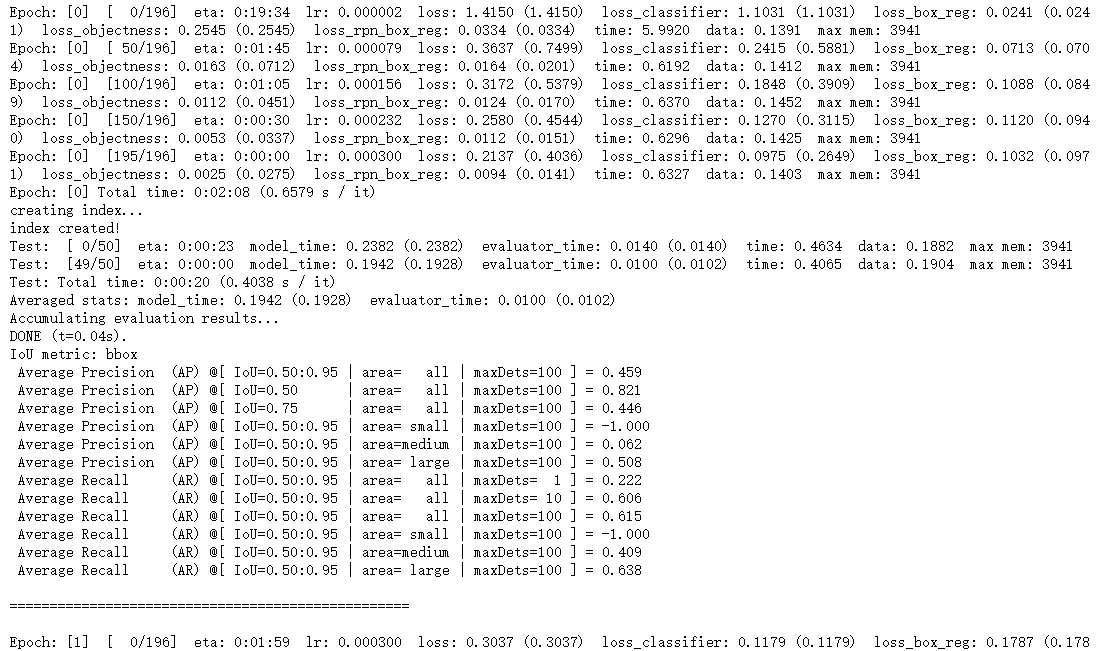
可以看到第一個epoch的學習率并不是設定的0.0003,而是從0開始逐漸增長的,其原因是在engine.py的train_one_epoch函式中,第一個epoch采用了warmup的學習率:
if epoch == 0:
warmup_factor = 1. / 1000
warmup_iters = min(1000, len(data_loader) - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
此外,由于我的資料集中的bbox的面積都比較大,因此area= small時的AP和AR都為-1.000
最后,保存模型:
torch.save(model, r'保存路徑\modelname.pkl')
6. 查看效果
用opencv繪制bbox:
def showbbox(model, img):
# 輸入的img是0-1范圍的tensor
model.eval()
with torch.no_grad():
'''
prediction形如:
[{'boxes': tensor([[1492.6672, 238.4670, 1765.5385, 315.0320],
[ 887.1390, 256.8106, 1154.6687, 330.2953]], device='cuda:0'),
'labels': tensor([1, 1], device='cuda:0'),
'scores': tensor([1.0000, 1.0000], device='cuda:0')}]
'''
prediction = model([img.to(device)])
print(prediction)
img = img.permute(1,2,0) # C,H,W → H,W,C,用來畫圖
img = (img * 255).byte().data.cpu() # * 255,float轉0-255
img = np.array(img) # tensor → ndarray
for i in range(prediction[0]['boxes'].cpu().shape[0]):
xmin = round(prediction[0]['boxes'][i][0].item())
ymin = round(prediction[0]['boxes'][i][1].item())
xmax = round(prediction[0]['boxes'][i][2].item())
ymax = round(prediction[0]['boxes'][i][3].item())
label = prediction[0]['labels'][i].item()
if label == 1:
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (255, 0, 0), thickness=2)
cv2.putText(img, 'mark_type_1', (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0),
thickness=2)
elif label == 2:
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=2)
cv2.putText(img, 'mark_type_2', (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0),
thickness=2)
plt.figure(figsize=(20,15))
plt.imshow(img)
查看效果:
model = torch.load(r'保存路徑\modelname.pkl')
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
img, _ = dataset_test[0]
showbbox(model, img)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/27937.html
標籤:其他