一、當前集群環境
CDH 6.3.3
hadoop 3.0.0
hbase 2.1.0
hive 2.1.1
impala 3.2.0
spark 2.4.0
kafka 2.2.1
scala 2.11.12
二、hadoop
1.Hdfs的作業原理(讀和寫)★★★★★
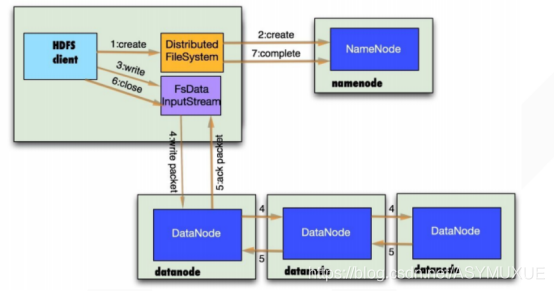
讀:client請求namenode ,獲取目標檔案的元資料資訊,namenode校檢無誤后,回傳給client,client根據元資料與就近的datanode建立連接,獲取block 塊,并將block 塊合并后,回傳給client,
寫:client 向 namenode發出寫 的請求,namenode 檢查是否路徑存在,權限等,通過后,將操作寫入editLog,并回傳一個節點串列,給client,client根據元資料與串列中就近的DataNode進行連接,并將data與回傳的節點串列一并發送給它,此后,client就與所有的DataNode節點建立 piepline管道,一個DataNode寫完后會傳給下一個DataNode,每個DataNode寫完一個 block 后,會回傳確認資訊給namenode,同時進行下一個 block的寫入,直到全部寫入完成,
2.MapReduce的原理 ★★★★★
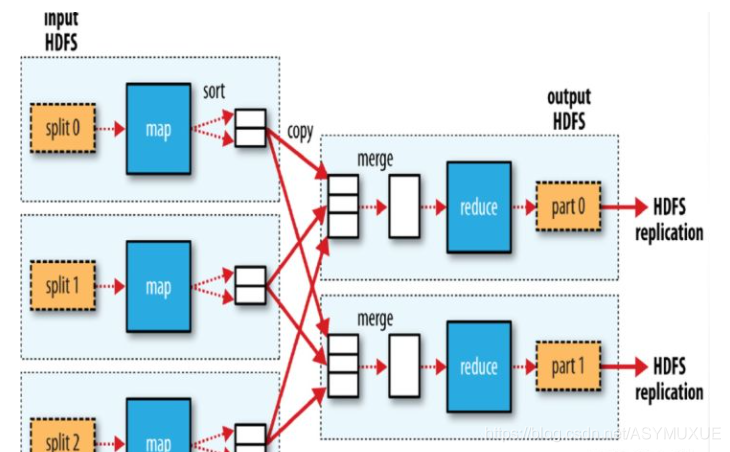
MR把拿到的 split 分配給相應的 task,每個task處理對應的split,split 以line的方式讀取每一行資料,將這些資料加載到一個環形緩沖區中,當環形緩沖區達到 80%的時候,會將這些資料溢寫到磁盤中,同時按照 k-v的方式進行磁區,(默認采用hashpartition),同時在每個磁區內進行排序,如果這時設定了setcombinerclass,則會對每個磁區的資料進行combiner操作,還可以設定 output-compress,對資料進行壓縮,最后merge,根據磁區規則,將資料歸并到同一個檔案中,等待reduce端拉取,等到所有的maptask 任務結束后,會根據磁區數量啟動相應的數量的reduceTask,每個reducetask 從mapTask機器上拷貝相應磁區的資料到本地的緩沖區,緩沖區不夠就溢寫到磁盤,待所有資料拷貝完畢后,進行歸并排序,之后按照相同的key分組,最后呼叫 reduce() 方法進行聚合處理,生成的結果將以檔案形式在hdfs中體現,
3.Yarn的作業流程 ★★★★★

1.client 提交一個任務到Yarn,包括用戶程式、 相關檔案、applicationMasrer程式、啟動AM(applicationMaster)命令,
2.RM(Resource Manager)分配第一個 container,并與所在的 NM(nodeManager)進行 通信,要求NM在container中啟動 AM,
3.AM向RM注冊自己,這樣用戶可以通過 RM查看程式的運行狀態等,然后它準備為程式的各個任務申請資源,并監控他們的 運行狀態直到任務結束,
4.AM以輪詢的方式通過RPC協議與RM通信,申請和領取資源,
5.AM領取到資源后,會向申請到的Container所在的NM進行通信,要求NM在container中啟動任務,
6.任務啟動,NM為要啟動的任務配置好環境變數、jar包、二進制檔案等,并將啟動命令寫在一個腳步中,通過改腳步運行任務,
7.NM與相應的AM保持RPC通信,匯報自身任務的運行進度與狀態,以讓AM在任務失敗時,可以重啟任務,
8.任務結束,AM向RM通信,要求注銷和關閉自己,
4.各個組件的作用 ★★★
NameNode: 集群的主節點,保存元資料、副本數、檔案目錄樹等資訊
DataNode:真正存放資料的節點,匯報block塊的狀態
SceondNameNode: 檢查點節點,NameNode日志高可用的關鍵,定期的對 edits 檔案和 FsImage 檔案進行合并,防止元資料丟失
Edits:記錄資料的寫操作,體現了HDFS的最新狀態
fsImage: 集群中元資料的一個永久性檢查點,用于故障恢復
5.為什么引入SecondNameNode ★
因為只有集群重啟時,edits 才會和 FsImage 檔案進行合并,因此為了防止 edit檔案越來越大,導致重啟時,檔案的合并耗時過長,因此引入 檢查點機制,
6.NameNode 元資料的持久化機制 ★★
“Fsimage" 和”Edits",SecondaryNameNode 定期 對 FsImage 和 Edits檔案的合并來保證NameNode中資料的高可用
7.如果client從DataNode上讀取block時網路中斷了如何解決? ★
此時我們會找到block另外的副本(一個block塊有3個副本),并且通過FSData InputStream進行記錄,以后就不再從中斷的副本上讀了,
8.如果一個DataNode掛掉了怎么辦? ★
由于心跳機制的存在,dataNode 會定時向 nameNode 發送blockReport ,一旦dataNode 掛掉后,nameNode,會在其余副本所在節點向 nameNode 報告時,向其他的副本所在的任一節點發送指令,使其拷貝本身的副本給另外的正常節點,保證副本數量為設定的值,
9.client如何保證讀取資料的完整性 ★
因為從DataNode上讀資料是通過網路來讀取的,這說明會存在讀取過來的資料是不完整的或者是錯誤的情況,
DataNode上存盤的不僅僅是資料,資料還附帶著一個叫做checkSum檢驗和(CRC32演算法)的概念,針對于任何大小的資料塊計算CRC32的值都是32位4個位元組大小,此時我們的FSData InputStream向DataNode讀資料時,會將與這份資料對應的checkSum也一并讀取過來,此時FSData InputStream再對它讀過來的資料做一個checkSum,把它與讀過來的checkSum做一個對比,如果不一致,就重新從另外的DataNode上再次讀取,
之后FSData InputStream會告訴NameNode,這個DataNode上的這個block有問題了,NameNode收到訊息后就會再通過心跳機制通知這個DataNode洗掉它的block塊,然后再用類似上面3中的做法,讓正常的DataNode去copy一份正常的block資料給其它節點,保證副本數為設定值,
三、Hbase
1.Hbase的架構 ★★★★
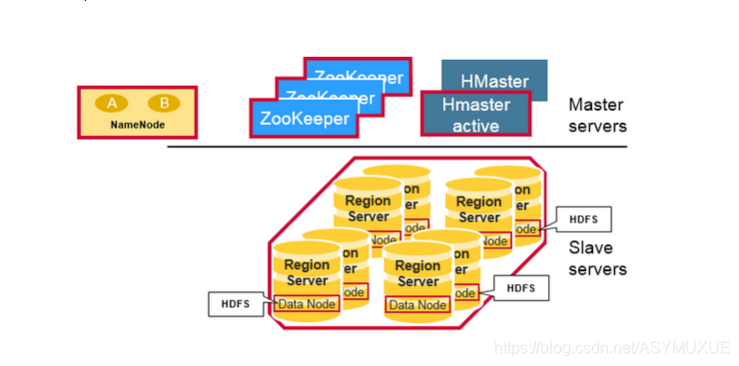
粗略來說:Hbase 主要由 ZooKeeper,HMaster , HRegion Server 三部分組成,
Hbase Master 負責Region的分配,DDL(創建,洗掉table)等操作
Region Server 負責處理資料的讀寫請求,客戶端請求資料時直接和 Region Server 互動
zookeeper 負責維護和記錄Hbase集群狀態
2.RowKey的設計原則 ★★★★★
1.長度限制 (最好16位元組內)
2.散列原則(rowKey要打散,避免熱點寫)
3.唯一性
3.RowKey怎么設計以規避熱點寫 ★★★★
1.加鹽 (rowKey 前添加亂數)
2.hash
3.反轉、時間戳反轉追加到 key的末尾
實體: 主鍵+“|”+加密后的時間戳
參考: https://www.talkwithtrend.com/Question/432297
4.Hbase 的讀寫流程 ★★★★
https://segmentfault.com/a/1190000019959411
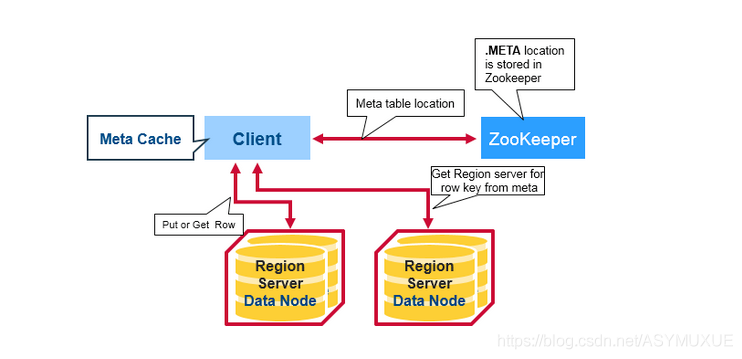
讀:
? 1.Client 請求ZK 獲取 Meta Table 所在的Region Server的地址
? 2.Client 查詢這臺管理 meta table 的Region Server,獲取本次查詢的 rowKey 由哪臺Region Server管理,Client會快取這個資訊,以及Meta Table 的位置資訊,
? 3.Client 直接向目標 Region Server 進行訪問,先從MemStroe 上讀,沒有再從StroeFile 上讀 獲取資料,

寫:
? 1.Client 請求 ZK 獲取Meta Table 所在的 Region Server 所在的位置
? 2.根據 nameSpace 、表名、rowKey、以及meta 表,找到寫入資料對應的 Region 資訊,
? 3.找到對應的 Region Server ,把資料先寫到 WAL(Wrtie Ahead Log),然后寫到 MemStroe,
? 4.當 MemStroe 達到閾值后,會把資料刷成磁盤上的StroeFile 檔案,
? 5.當多個 StroeFile 檔案達到一定大小后,會觸發 compact 合并操作,合并為一個 Store File ;而當 這個檔案大小超過一定的閾值后,會把當前的 Region 分割為兩個,并由 Hmaster 分配給相應的 HRegion Server ,實作負載均衡,
四、Hive
1.Hive 的原理 ★★★★★
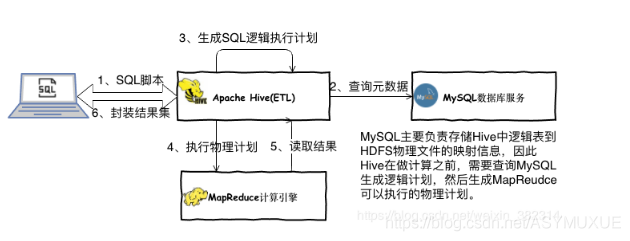
1.提交SQL到hive
2.查詢元資料
3.生成邏輯計劃,優化邏輯計劃
4.生成物理計劃,優化物理計劃
5.執行物理計劃
6.封裝結果集,回傳資料
2.Hive有幾種表 ★★★★★
1.內部表:創建時,資料會被移動到數倉指定的目錄下;洗掉時,元資料和資料一并洗掉
2.外部表:創建時,僅記錄資料所在的位置,不進行移動;洗掉時,只洗掉元資料,不洗掉資料
3.磁區表:根據表中的某個欄位進行磁區,類似于檔案夾,例如:日志檔案,根據時間,每天一個磁區
4.分桶表:相比磁區表,更加細粒度的劃分,根據表中某個欄位的hash值進行分割,類似于一個檔案拆分為多個檔案,
5.臨時表:儲存在用戶的暫存目錄中,并在會話結束后進行洗掉
3.order by 、 sort by 、distribute by 、 cluster by ★★★★
order by :全域排序,只有一個 reduce 耗時長
sort by : 區域有序,不保證多個reduce之間有序,只是單個reduce有序
distribute by: 控制map的分發結果,具有相同欄位的map分發到同一個reduce
cluster by: 相當于是 distribute by + sort by 【只能是降序】
4.什么是資料傾斜,怎么解決 ★★★★★
資料傾斜:資料分布不均勻,有的過分多,有的太少,導致處理資料的時候,有的很快,有的特別慢,從而導致任務一直無法完成,
根本原因:key 的分布不均勻,
解決辦法:1: 合理設定map數
? ①.小檔案合并:CombineHiveInputFormat
? ②.復雜檔案增加map數:調整切片最大值,maxsize,使其小于 block size
? 2.: 合理設定 reduce 數
? ①:set mapreduce.job.reduces= N
? 3.打亂集中的key,使其進入不同的reduce
5.Hive 調優 ★★★★★
https://blog.csdn.net/qq_43259670/article/details/105927827?spm=1001.2014.3001.5506
hive調優,一般通過 hive-site.xml 或者 客戶端配置完成,一般的調優策略有:
①:jvm重用
②:合并block 減少 task 數量
③:開啟小檔案合并
④:開啟資料壓縮
⑤:有資料傾斜時進行負載均衡
五、Kafka
1.Kafka采用了那些設計保證高性能 ★★★★★
1.producer : ①磁盤順序寫 ② MMF 記憶體映射檔案
2.consumer: ①zero-copy
2.Kafka的冪等性 ★★★★★
冪等性:一般而言是指,對于同一個資源,一次請求和多次請求的結果對資源本身應該是完全一致的,
(比如電子支付,由于網路延遲或者手機卡頓等原因,超市的收銀員掃了你2次收款碼,這時候,你的電子錢包應該要做到只被扣除一次,不能多次扣除,而要做到這一點,①要保證訂單有唯一的id ②處理端要記錄下已經處理過的請求,如果下一條來的id已經存在,則丟棄掉不能處理)kafka的冪等性是對生產者而言的,具體做法是 kafka對每一條訊息添加一個 sequence number,(每條訊息對應一個磁區,不同磁區的訊息不會存在重復)而broker會儲存這個sequence number,當下一條訊息來的時候,只有 sequence number 比上一條的>1,則保留,否則丟棄,
3.訊息丟失與訊息重復 ★★★★★
訊息丟失:
? produce:
①ack設定了0,導致生產者發送訊息后,不確認磁區副本是否收到,如果失敗,就會丟失,? ②ack設定了1,只有leader保存了訊息,就回傳成功,follower未同步,leader就掛掉,
? 解決辦法: 設定 ack = all
? consumer:
①自動提交了offset,但是后續業務邏輯未處理完就失敗? 解決辦法:手動提交偏移量,待業務邏輯處理完后提交
訊息重復:
? producer:
①發送一條訊息,副本已保存,但是因為網路等多種原因未回傳成功,多次重試? 解決辦法:開啟kafka的冪等性
? consumer:
①消費端在消費程序中掛掉沒有及時提交offset,另一個消費端拿取了之前的記錄進行消費? 解決辦法:在下游程式做冪等性
4.幾個概念 ★★★★
https://blog.csdn.net/weixin_43230682/article/details/107317839
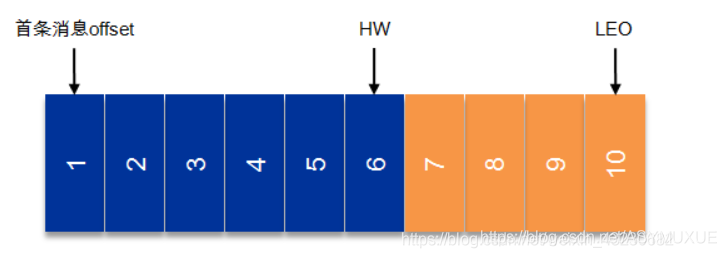
ISR: 與leader保持同步的follower集合 (In-Sync Replicas)
AR:每個磁區下的所有副本統稱 (Assigned Replicas)
LEO:每個磁區最后一條訊息的位置 (log Eed Offset)
HW: 一個磁區對應的ISR中最小的LEO作為 HW (High Watermark)
5.Kafka的儲存與順序一致性、如何保證順序消費 ★★★★★
1.kafka的每一個磁區內部是有序的,因此只要保證需要有順序的資料都向同一個磁區寫就可以,
? kafka自身的磁區策略:
①用戶給定磁區號,發送資料到指定磁區
? ②沒有給定磁區號,但是有Key,根據key取hash進行磁區
? ③ 沒Key沒磁區號,輪詢磁區
? ④ 自定義磁區
2.一個磁區只能對一個消費者使用,因此要保證順序消費,就要:
①:消費者單執行緒處理訊息
?②:寫N個佇列,將具有相同Key的消費儲存在同一個佇列里,對于N個執行緒,一 個執行緒消費一個佇列即可
六、Spark
1.Spark的作業流程 ★★★★★

1.用戶通過 Spark-Submit 提交代碼至服務器,創建SparkContext,在SparkContext初始化的時候會創建DAGScheduler 和 TaskScheduler
2.初始化的同時,向ClusterManager注冊Application并申請資源
3.ClusterManager 會使用自己的資源調度演算法,在集群的worker 節點上,啟動多個 Executor
4.Executor 會反向注冊給Driver ,結束sparkcontext 的初始化,
5.呼叫 DAGScheduler 完成任務階段的劃分
6.每一個stage 創建一個 taskset
7.taskScheduler 將 taskset 分發給 executor 行程,完成計算,
2.RDD ★★★★★
彈性分布式資料集,是spark中最基本的資料抽象,它代表一個不可變,可磁區,內部元素可并行計算的集合
創建方式:①makeRdd,通過集合創建
? ②使用外部資料源創建,如HDFS
? ③通過其他RDD的結果創建
3.算子 ★★★★★
轉換算子: map、flatmap、filter、join、repartition、coalsece、distinct 、groupByKey 、reduceByKey
動作算子:collect 、 foreach 、take 、first 、count、 saveAsTextFile
4.RDD的依賴關系 ★★★★★
寬依賴:多個子RDD的磁區依賴同一個父RDD的磁區
窄依賴:每一個父RDD的磁區最多被子RDD的一個磁區使用
5.Stage 怎么劃分 ★★★★★
根據RDD之間的依賴關系,遇到一個寬依賴就劃分一個stage,寬依賴表示資料有shuffle程序,即可以認為遇到資料shuffle就產生一個stage,劃分stage有利于形成DAG圖,方便在一個stage內達到資料執行效率的最大化,實作流水線計算,
6.stage 、 Job 、 task ★★★★★
job : 遇到一個action 操作,就劃分一個job,一個job中包含一個或多個stage
stage:遇到一次shuffle就劃分一個stage
task:RDD的有多少的partition就有多少task,是stage中的一個執行單元,一個stage就是一個taskset
7.spark的調優 ★★★★★
1.修改序列化機制,采用 Kryo優化序列化性能
2.提高并行度
? ①:設定 task的數量
? ②:repartition ,給rdd重新磁區
3.RDD的重用和持久化
4,使用廣播變數,廣播小資料
5,減少使用會產生shuffle的算子
6.使用高性能的算子
①:如用 reduceByKey 替代 groupByKey
②:用mapPartitiond 替代 map
③:用 foreachPartitions 替代 foreach
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279379.html
標籤:其他