1、自然語言處理學習路徑規劃
- 自然語言處理(NLP)開發環境搭建
- 分詞demo(搭建helloworld工程)
- 案例:nlp實作預測天氣冷暖感知度
- ---案例需求和資料準備
- ---可視化資料分析
- ---KNN模型原理及歐式距離計算
- ---KNN分類器模型實作
- ---利用KNN分類器采訪隨機游客預測天氣感知度
- ---機器學習庫sklearn實作預測天氣冷暖感知度
- 自然語言處理學習總結歸納
2、自然語言處理(NLP)開發環境搭建
- 自然語言處理一般用python語言,java其實也可以,反正每個語言生態都有自己的相關NLP庫
- 開發環境千萬個,蘿卜青菜給有所愛,這里給搭建推薦用idea了
- 下載idea https://www.jetbrains.com/idea/download/
- 下載python語言插件(File->settings->plugins->marketplace->搜索:python選擇python language那個)
- 有了插件,就可以新建python專案了,先默認新建一個專案,比如:nlp
- 下載idea https://www.jetbrains.com/idea/download/
3、分詞demo(搭建helloworld工程)
- 按照國際上的慣例,咱們應該先寫個hello world,體驗一下python(希望大家有python基礎,沒有也沒關系)
- NLP當中有個常用的技術,分詞,咱也不會,用個第三方的試試
- jieba庫是一款優秀的 Python 第三方中文分詞庫jieba 支持三種分詞模式:精確模式、全模式和搜索引擎模式,下面是三種模式的特點,
- 精確模式:試圖將陳述句最精確的切分,不存在冗余資料,適合做文本分析
- 全模式:將陳述句中所有可能是詞的詞語都切分出來,速度很快,但是存在冗余資料
- 搜索引擎模式:在精確模式的基礎上,對長詞再次進行切分
上代碼之前得安裝這個分詞包,秒級安裝鏡像pip install jieba -i https://pypi.douban.com/simple/
好,上代碼:
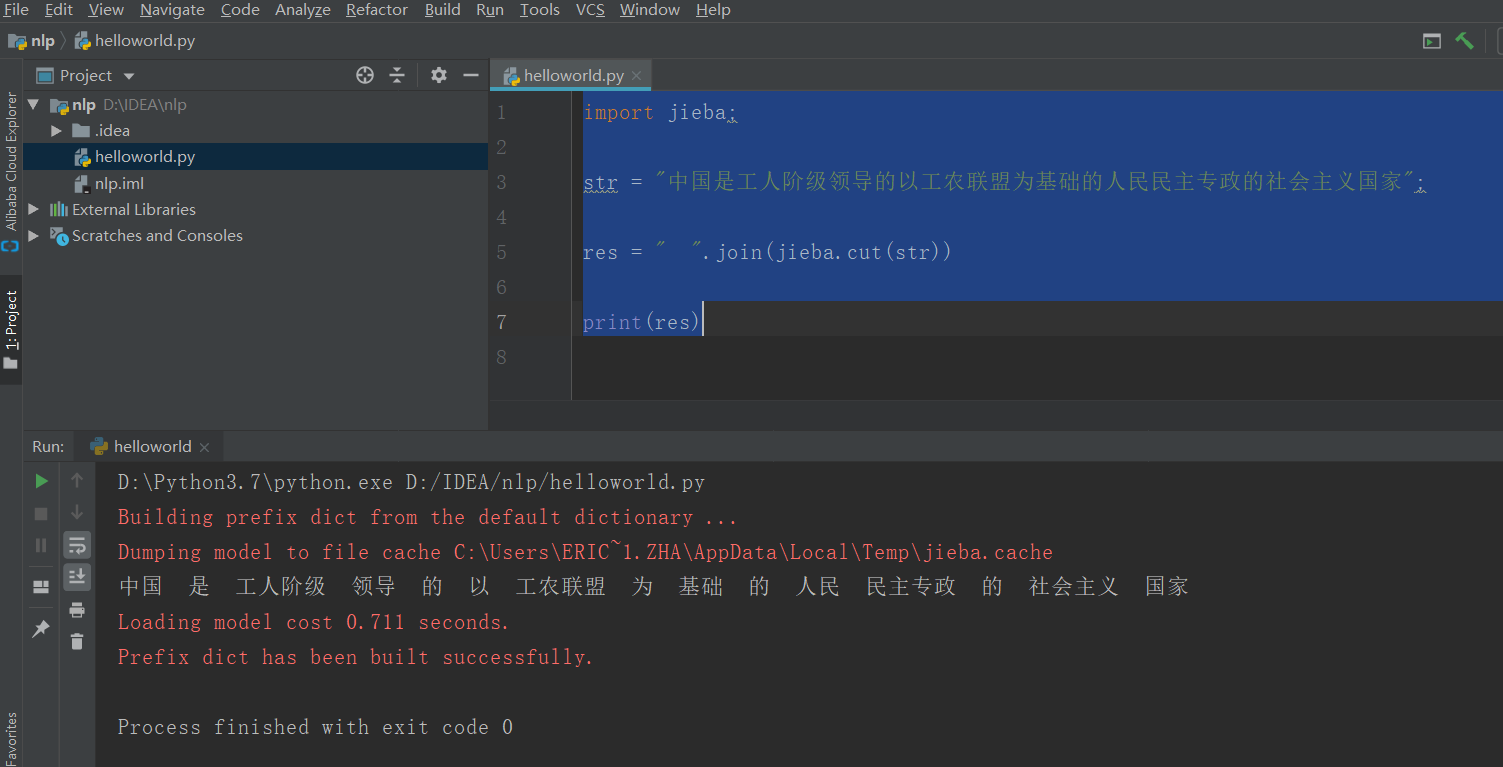
import jieba;
str = "中國是工人階級領導的以工農聯盟為基礎的人民民主專政的社會主義國家";
res = " ".join(jieba.cut(str))
print(res)
運行效果如下:
4、案例:nlp實作預測天氣冷暖感知度
4.1、案例需求及資料準備

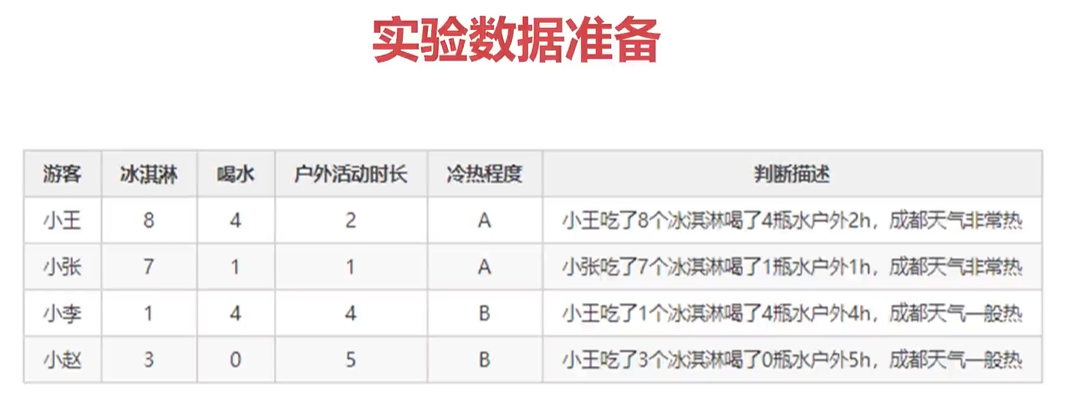
上代碼:
#coding=utf8
'''創建資料源、回傳資料集和類標簽'''
def creat_dataset():
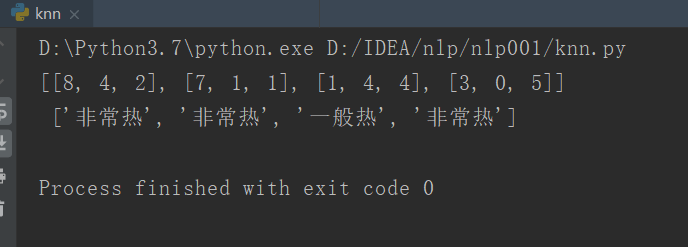
datasets = [[8,4,2],[7,1,1],[1,4,4],[3,0,5]]#資料集
labels = ['非常熱','非常熱','一般熱','非常熱']#類標簽
return datasets,labels
if __name__ == '__main__':
datasets,labels = creat_dataset()
print(datasets,'\n',labels)
運行結果:
4.2、資料分析與可視化
上代碼:
#coding=utf8
import numpy as np
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
'''創建資料源、回傳資料集和類標簽'''
def creat_dataset():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5]])#資料集
labels = ['非常熱','非常熱','一般熱','非常熱']#類標簽
return datasets,labels
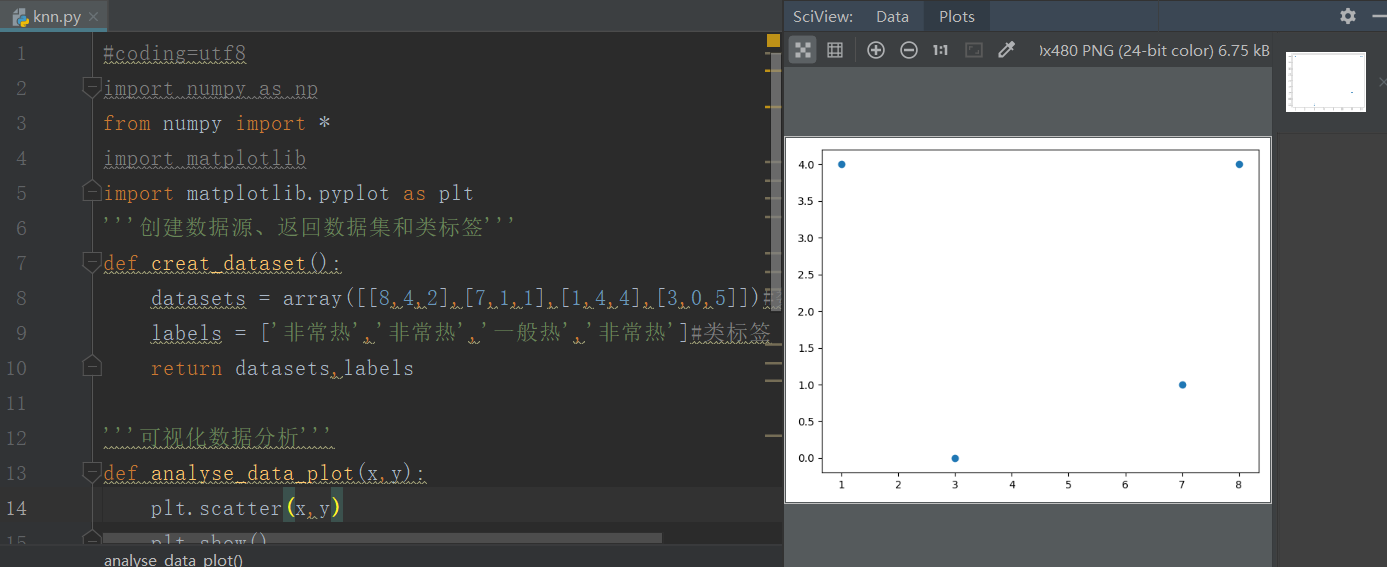
'''可視化資料分析'''
def analyse_data_plot(x,y):
plt.scatter(x,y)
plt.show()
if __name__ == '__main__':
datasets,labels = creat_dataset()
print('資料集:\n',datasets,'\n','類標簽:\n',labels)
'''資料可視化分析'''
analyse_data_plot(datasets[:,0],datasets[:,1])
運行結果:
4.3、演算法模型及原理
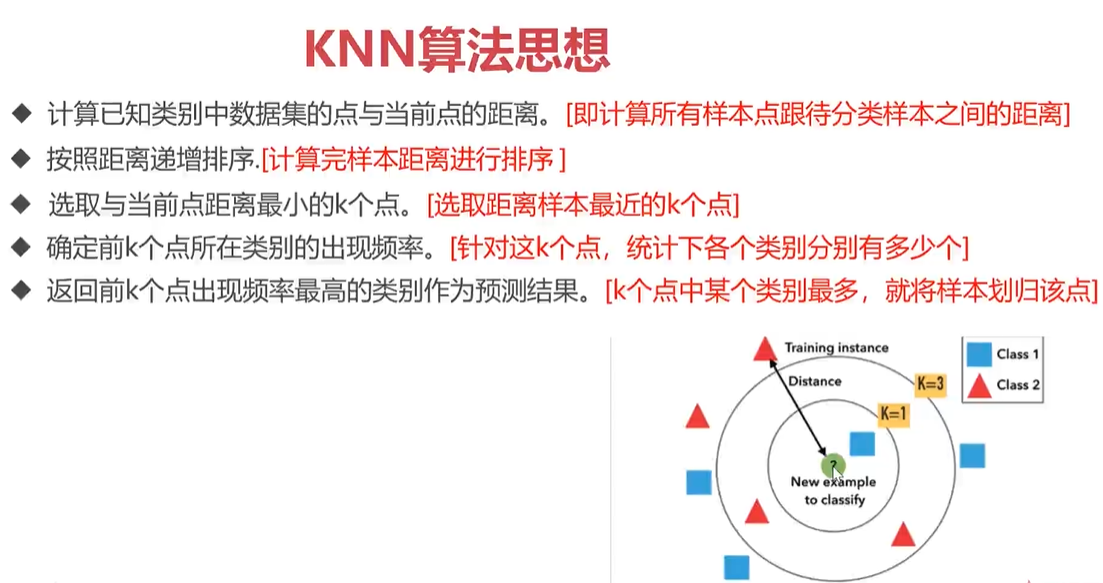
KNN模型原理及歐式距離計算



上代碼:
#coding=utf8
import numpy as np
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
'''創建資料源、回傳資料集和類標簽'''
def creat_dataset():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5]])#資料集
labels = ['非常熱','非常熱','一般熱','非常熱']#類標簽
return datasets,labels
'''可視化資料分析'''
def analyse_data_plot(x,y):
plt.scatter(x,y)
plt.show()
'''構造KNN分類器'''
#def knn_Classifier(newV,datasets,labels,2):
#1.獲取新的樣本資料
#2.獲取樣本庫的資料
#3.選擇K值
#4.計算樣本資料與樣本庫資料之間的距離
#5.根據距離進行排序
#6.針對K個點,統計各個類別的數量
#7.投票機制,少數服從多數原則
'''歐氏距離計算:d2=(x1-x2)2+(y1-y2)2'''
def ComputerEuclideanDistance(x1,y1,x2,y2):
d = math.sqrt(math.pow((x1-x2),2)+math.pow((y1-y2),2))
return d
'''歐氏距離計算多維度支持'''
def EuclideanDistance(instance1,instance2,length):
d=0
for i in range(length):
d += pow((instance1[i]-instance2[i]),2)
return math.sqrt(d)
if __name__ == '__main__':
#1.創建資料集和類標簽
datasets,labels = creat_dataset()
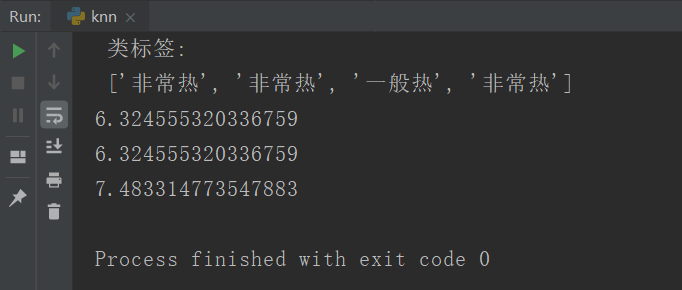
print('資料集:\n',datasets,'\n','類標簽:\n',labels)
#2.資料可視化分析
#analyse_data_plot(datasets[:,0],datasets[:,1])
#3.1.歐式距離計算
d = ComputerEuclideanDistance(2,4,8,2)
print(d)
#3.2.歐式距離計算
d2 = EuclideanDistance([2,4],[8,2],2)
print(d2)
#3.3.歐式距離計算,可支持多維
d3 = EuclideanDistance([2,4,9],[8,2,5],3)
print(d3)
#KNN分類器
newV = [2,4,0]
#knn_Classifier(newV,datasets,labels,2)
運行結果:
下一篇筆記分享學習如下內容
- ---KNN分類器模型實作
- ---利用KNN分類器采訪隨機游客預測天氣感知度
- ---機器學習庫sklearn實作預測天氣冷暖感知度
- 自然語言處理學習總結歸納
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/27950.html
標籤:其他
上一篇:Flutter仿掘金點贊效果
下一篇:一起學scala--陣列相關操作