接上篇文章《自然語言處理入門小白從0開始學自然語言處理+學習筆記(一)》
1、自然語言處理學習路徑規劃
- 自然語言處理(NLP)開發環境搭建√
- 分詞demo(搭建helloworld工程)√
- 案例:nlp實作預測天氣冷暖感知度 √
- ---案例需求和資料準備√
- ---可視化資料分析√
- ---KNN模型原理及歐式距離計算√
- ---KNN分類器模型實作
- ---利用KNN分類器采訪隨機游客預測天氣感知度
- ---機器學習庫sklearn實作預測天氣冷暖感知度
- 自然語言處理學習總結歸納
2、案例:nlp實作預測天氣冷暖感知度
KNN分類器模型實作
上代碼
#coding=utf8
from audioop import reverse
import numpy as np
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
'''創建資料源、回傳資料集和類標簽'''
def creat_dataset():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5]])#資料集
labels = ['非常熱','非常熱','一般熱','一般熱']#類標簽
return datasets,labels
'''可視化資料分析'''
def analyse_data_plot(x,y):
plt.scatter(x,y)
plt.show()
'''構造KNN分類器'''
def knn_Classifier(newV,datasets,labels,k):
import operator
#1.計算樣本資料與樣本庫資料之間的距離
SqrtDist = EuclideanDistance3(newV,datasets)
#2.根據距離進行排序,按照列向量進行排序
sortDistIndexs = SqrtDist.argsort(axis=0)
#print(sortDistIndexs)
#3.針對K個點,統計各個類別的數量
classCount = {}#統計各個類別分別的數量
for i in range(k):
#根據距離排序索引值,找到類標簽
votelabel = labels[sortDistIndexs[i]]
#print(sortDistIndexs[i],votelabel)
#統計類標簽的鍵值對
classCount[votelabel] = classCount.get(votelabel,0)+1
#print(classCount)
#4.投票機制,少數服從多數原則
#對各個分類字典進行排序,降序,itemgetter按照value排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1),reverse=1)
#print(newV,'KNN投票預測結果:',sortedClassCount[0][0])
return sortedClassCount
'''歐氏距離計算1:d2=(x1-x2)2+(y1-y2)2'''
def ComputerEuclideanDistance(x1,y1,x2,y2):
d = math.sqrt(math.pow((x1-x2),2)+math.pow((y1-y2),2))
return d
'''歐氏距離計算2:多維度支持'''
def EuclideanDistance(instance1,instance2,length):
d = 0
for i in range(length):
d += pow((instance1[i]-instance2[i]),2)
return math.sqrt(d)
'''歐氏距離計算3'''
def EuclideanDistance3(newV,datasets):
#1.獲取資料向量的行向量維度和縱向量維度值
rowsize,colsize = datasets.shape
#2.各特征向量之間做差值
diffMat = tile(newV,(rowsize,1)) - datasets
#3.對差值平方
sqDiffMat = diffMat ** 2
#4.差值平方和進行開方
SqrtDist = sqDiffMat.sum(axis=1) ** 0.5
return SqrtDist
if __name__ == '__main__':
#1.創建資料集和類標簽
datasets,labels = creat_dataset()
print('資料集:\n',datasets,'\n','類標簽:\n',labels)
#2.資料可視化分析
#analyse_data_plot(datasets[:,0],datasets[:,1])
#3.1.歐式距離計算
d = ComputerEuclideanDistance(2,4,8,2)
print('歐氏距離計算1:',d)
#3.2.歐式距離計算
d2 = EuclideanDistance([2,4],[8,2],2)
print('歐式距離計算2:',d2)
#3.3.歐式距離計算,可支持多維
d3 = EuclideanDistance3([2,4,4],datasets)
print('歐式距離計算3:',d3)
#KNN分類器
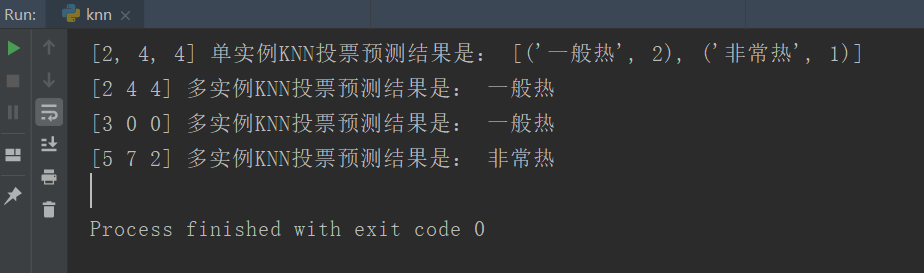
newV = [2,4,4]
#4.1.單實體構造KNN分類器
res = knn_Classifier(newV,datasets,labels,3)
print(newV,'單實體KNN投票預測結果是:',res)
#4.2.多實體構造KNN分類器
vecs = array([[2,4,4],[3,0,0],[5,7,2]])
for vec in vecs:
res = knn_Classifier(vec,datasets,labels,3)
print(vec,'多實體KNN投票預測結果是:',res[0][0])
運行結果:
利用KNN分類器采訪隨機游客預測天氣感知度

上代碼:
#coding=utf8
from audioop import reverse
import numpy as np
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
'''創建資料源、回傳資料集和類標簽'''
def creat_dataset():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5]])#資料集
labels = ['非常熱','非常熱','一般熱','一般熱']#類標簽
return datasets,labels
'''可視化資料分析'''
def analyse_data_plot(x,y):
plt.scatter(x,y)
plt.show()
'''構造KNN分類器'''
def knn_Classifier(newV,datasets,labels,k):
import operator
#1.計算樣本資料與樣本庫資料之間的距離
SqrtDist = EuclideanDistance3(newV,datasets)
#2.根據距離進行排序,按照列向量進行排序
sortDistIndexs = SqrtDist.argsort(axis=0)
#print(sortDistIndexs)
#3.針對K個點,統計各個類別的數量
classCount = {}#統計各個類別分別的數量
for i in range(k):
#根據距離排序索引值,找到類標簽
votelabel = labels[sortDistIndexs[i]]
#print(sortDistIndexs[i],votelabel)
#統計類標簽的鍵值對
classCount[votelabel] = classCount.get(votelabel,0)+1
#print(classCount)
#4.投票機制,少數服從多數原則
#對各個分類字典進行排序,降序,itemgetter按照value排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1),reverse=1)
#print(newV,'KNN投票預測結果:',sortedClassCount[0][0])
return sortedClassCount
'''歐氏距離計算1:d2=(x1-x2)2+(y1-y2)2'''
def ComputerEuclideanDistance(x1,y1,x2,y2):
d = math.sqrt(math.pow((x1-x2),2)+math.pow((y1-y2),2))
return d
'''歐氏距離計算2:多維度支持'''
def EuclideanDistance(instance1,instance2,length):
d = 0
for i in range(length):
d += pow((instance1[i]-instance2[i]),2)
return math.sqrt(d)
'''歐氏距離計算3'''
def EuclideanDistance3(newV,datasets):
#1.獲取資料向量的行向量維度和縱向量維度值
rowsize,colsize = datasets.shape
#2.各特征向量之間做差值
diffMat = tile(newV,(rowsize,1)) - datasets
#3.對差值平方
sqDiffMat = diffMat ** 2
#4.差值平方和進行開方
SqrtDist = sqDiffMat.sum(axis=1) ** 0.5
return SqrtDist
#利用KNN分類器預測隨機訪客天氣感知度
def Predict_temperature():
#1.創建資料集和類標簽
datasets,labels = creat_dataset()
#2.采訪新游客
iceCream = float(input('Q:請問你今天吃了幾個冰激凌?\n'))
drinkWater = float(input('Q:請問你今天喝了幾杯水?\n'))
playAct = float(input('Q:請問你今天戶外活動了幾個小時?\n'))
newV = array([iceCream,drinkWater,playAct])
res = knn_Classifier(newV,datasets,labels,3)
print('該訪客認為北京的天氣是:',res[0][0])
if __name__ == '__main__':
#1.創建資料集和類標簽
datasets,labels = creat_dataset()
#KNN分類器預測隨機訪客天氣感知度
Predict_temperature()
運行結果:


機器學習庫sklearn實作預測天氣冷暖感知度
上代碼:
# coding = utf8
from sklearn import neighbors
from numpy import *
import nlp001.knn as KNN
def knn_sklearn_predict(newV,datasets,labels):
#呼叫機器學習庫knn分類器演算法
knn = neighbors.KNeighborsClassifier()
#傳入引數、特征資料、分類標簽
knn.fit(datasets,labels)
#knn預測
predictRes = knn.predict([newV])
print('該訪客認為北京天氣是:\t',predictRes,'非常熱' if predictRes[0] == 0 else '一般熱')
#利用KNN分類器預測隨機訪客天氣感知度
def Predict_temperature():
#1.創建資料集和類標簽
datasets,labels = KNN.creat_datasets()
#2.采訪新游客
iceCream = float(input('Q:請問你今天吃了幾個冰激凌?\n'))
drinkWater = float(input('Q:請問你今天喝了幾杯水?\n'))
playAct = float(input('Q:請問你今天戶外活動了幾個小時?\n'))
newV = array([iceCream,drinkWater,playAct])
knn_sklearn_predict(newV,datasets,labels)
if __name__ == '__main__':
Predict_temperature()
knn.py中新增函式(該示例中包含呼叫knn.py中的模塊)
'''創建資料源、回傳資料集和類標簽'''
def creat_datasets():
datasets = array([[8,4,2],[7,1,1],[1,4,4],[3,0,5],[9,4,2],[7,0,1],[1,5,4],[4,0,5]])#資料集
labels = [0,0,1,1,0,0,1,1]#類標簽:0代表非常熱,1代表一般熱
return datasets,labels
3、自然語言處理學習總結歸納

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/27953.html
標籤:其他
上一篇:一起學scala--陣列相關操作