為什么要用壓縮
壓縮和解壓本質上:CPU的計算(執行演算法)
它們就是一種特殊的加密演算法,這個加密的要求是,加密后的體積要比原本更小
本質的原因是:CPU的速度遠大于硬碟同時也遠大于網路傳輸速度
核心點:將硬碟負載或者網路負載轉移到CPU負載,是一種收益行為
行存盤和列存盤的區別

-
列存盤,每個檔案存盤一個列,多個檔案存盤多個列,多個檔案合成一張二維表
-
優點:列過濾,列查找,針對列相關操作更快,擴展列,增刪列很容易,列單獨存盤
- 列相關查詢、過濾性能更快
- 擴展列、洗掉列更簡單
- 列單獨存盤,每個列均可以進行單獨排序,性能更好
- 列單獨存盤,可以針對每個列的資料型別設定針對性的壓縮演算法,使得壓縮率更好
- 資料加載可以選擇指定的列加載到記憶體中,更加節省記憶體,
數倉的特性很大一部分是針對列的過濾,列的搜索,列的匹配,所以很多數倉結構比較適合使用列存盤
列存盤也比較適合做OLAP
-
缺點:整行相關操作性能低,同時對事務的支持性不行(因為把列都拆開存盤,每個列單獨做事務,整體還要同步很麻煩)
-
-
行存盤,資料行存盤,一個檔案可表達一個二維表,
-
優點:
-
概念簡單容易理解,和很多現實中的資料模型概念相通,比如CSV檔案,文本資料檔案等概念簡單容易理解是一個很大的優勢,畢竟性能低點可以忍,難以理解就不可以忍了,
人天生懶,
-
針對行操作更快捷
-
事務支持比較好
-
-
缺點:
- 針對列的操作性能比列存盤低,因為無論操作哪個列都要取出來整行資料
- 只能針對整行資料選定壓縮演算法,無法針對列選定,壓縮率不高(對比列存盤)
- 排序只可基于某一個列排序,然后整體行和行之間排序(索引等額外的解決方案除外,這里只是指原始狀態下)
- 擴展列、洗掉列不方便
-
Hive磁區資料的寫入
-
靜態磁區
insert into … partition(year=‘2020’, month=‘09’)
-
動態磁區
insert into … partition(year, month)
開啟動態磁區,同時要求非嚴格模式
set hive.exec.dynamic.partition=true; 是開啟動態磁區
set hive.exec.dynamic.partition.mode=nonstrict; 這個屬性默認值是strict,就是要求磁區欄位必須有一個是靜態的磁區值,當前設定為nonstrict,那么可以全部動態磁區
-
混合磁區
insert into …partition(year=‘2020’, month)
這種方式要求靜態在前,
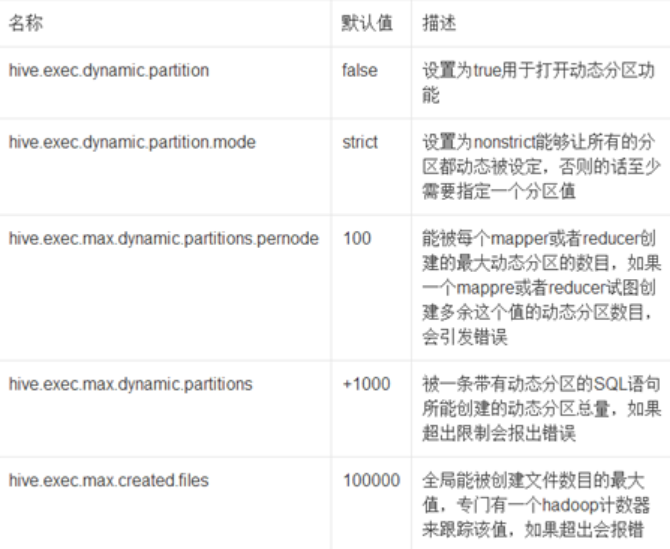
Hive分桶優化
分桶的概念
分桶和磁區不同,磁區是粗粒度的劃分資料,并且是大范圍的
分桶是細粒度的資料劃分
磁區劃分的是檔案夾
分桶劃分的是檔案
磁區的規則是:按照指定key的值來確定檔案夾
分桶的規則是:按照hash散列來計算資料應該落入哪個分桶的檔案中,
總結:磁區就是通過檔案夾的方式大范圍切分表資料
分桶就是通過區分檔案的方式在細粒度上切分表資料
什么時候用分桶
-
查詢性能優化(在有JOIN的場景下)
- 如果磁區數量過多,會對檔案系統造成負載壓力,
- 分桶是hash散列,如果分桶key相同,一定在一個檔案內,當進行JOIN的時候,分桶就可以幫助完成檔案對檔案的對應,提升JOIN的性能
-
資料采樣
我們用的都是大資料系統,特點是資料量夠大,
大量的資料如果做驗證,比較消耗性能,
如果能夠抽取一部分資料做驗證
分桶就比較適合做資料采樣用,
分桶表的資料寫入
分桶表,不能夠用load data的形式加載,也就是說只能夠INSERT 來執行資料插入,
也就是,分桶表不能夠直接用sqoop匯入資料
sqoop匯入的方案
創建一個不帶分桶的臨時表,用sqoop將資料匯入臨時表
執行:INSERT INTO 正式表 SELECT * FROM 臨時表;
MapJoin優化
分桶本身也能提供優化,除了標準分桶外,還有一個MapJoin的優化,
MapJoin優化:將Join發生在Map端,而不在Reduce端,
如果在map端進行Join,每一個map都要有對應的資料存在記憶體中,也就是:
- 主表可能資料是分散在各個map的
- 被關聯的表,肯定要全量的存在各個map的記憶體中
場景限制
一般用于,大表 Join 小表的場景
引數
# 開啟自動執行MapJoin(達到條件,會自動走Map的Join而不是Reduce的Join)
set hive.auto.convert.join=true;
# 使用MapJoin的閾值設定,默認是20MB
set hive.auto.convert.join.noconditionaltask.size=512000000
/* 這個設定表示,如果N張表執行Join,N - 1張表的大小小于這個閾值,即可走MapJoin */
顯示的告知Hive走MapJoin
在查詢中加入:/*+mapjoin(表)*/
示例:
# 顯示的告知Hive,這個查詢要走MapJoin
select /*+mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802) ;
Bucket-MapJoin
桶MapJoin
大表對大表的場景下,無法使用MapJoin(因為大表指的就是超過了MapJoin允許的大小閾值)
我們可以使用Bucket-MapJoin來進行優化,
表整體無法在Map中hold住,可以將表的分桶在Map中hold
相當于,兩個表的分桶和分桶之間,做區域的MapJoin
限制條件
-
必須有分桶
-
bucket數是另一個表bucket數的
整數倍也就是可以做1個檔案對一個檔案,或者1個檔案對2個檔案等,
但是不能出現1個檔案對1.3個檔案
所以要求整數倍
-
分桶列也是JOIN列
引數
# 開啟bucket mapjoin的優化
set hive.optimize.bucketmapjoin = true;
SMB Join 優化
Sorted Merge Bucket Join
MapJoin優化了整表的Join流程(整表在Map記憶體中Join)
BucketMapJoin優化了表的區域Join(桶檔案和桶檔案之間在Map端的記憶體中Join)
SMB Join 優化的是,在shuffle程序中的性能提升,
MapReduce執行流程,Map和Reduce之間有Shuffle,Shuffle是需要耗費一定的時間的,
如果提供的資料就是已排好序的,Shuffle就可以被加速吧
SMB的核心就是:
- 在BucketMapJoin的基礎上,對桶檔案進行排序
通俗說就是:分桶 + 桶排序
CLUSTERED BY(xxx) SORTED BY (xxx) INTO 10 BUCKET;
引數
# 開啟排序
set hive.enforce.sorting = true;
# 開啟SMB優化的自動嘗試
set hive.optimize.bucketmapjoin.sortedmerge = true;
分桶優化小總結
| bucket mapjoin | SMB join |
|---|---|
| set hive.optimize.bucketmapjoin = true; | set hive.optimize.bucketmapjoin = true; set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; |
| 一個表的bucket數是另一個表bucket數的整數倍 | 小表的bucket數**=**大表bucket數 |
| bucket列 == join列 | Bucket 列 == Join 列 == sort 列 |
| 必須是應用在map join的場景中 | 必須是應用在bucket mapjoin 的場景中 |
引數總結
# 開啟自動執行MapJoin(達到條件,會自動走Map的Join而不是Reduce的Join)
set hive.auto.convert.join=true;
# 使用MapJoin的閾值設定,默認是20MB
set hive.auto.convert.join.noconditionaltask.size=512000000
# 開啟bucket mapjoin的優化
set hive.optimize.bucketmapjoin = true;
# 開啟排序
set hive.enforce.sorting = true;
# 開啟SMB優化的自動嘗試
set hive.optimize.bucketmapjoin.sortedmerge = true;
Hive索引
索引的概念
索引:本質上就是將資料查詢的檢索次數和需要加載的資料量進行優化的一種手段
大白話:加速查詢的程序
優點:
- 就是查的超快
缺點:
- 增、刪、改都是性能拖累
對資料庫表而言,只對頻繁使用過濾條件或者關聯條件的列,加索引最好,不要全都加,
索引是以時間+空間換時間的操作
- 前面的時間指的是,插入、更新、洗掉等操作變慢
- 后面的時間指的是,查詢的速度變快
- 空間指的是:額外的存盤來記錄索引資訊
Hive索引型別
- Hive原始索引(3.0廢棄)
- 不會自動跟隨資料更新而更新,每次更細資料都需要自行的執行重建索引的操作
- Row Group Index(行組索引)
- Bloom Filter Index(布隆過濾器索引)
行組索引和布隆過濾器索引,都需要使用ORC
行組索引
針對某個列,行組索引是在ORC檔案的每一個分塊上,構建分塊中針對這個列的最大值和最小值的記錄
通過這個記錄,來確保索引資料,查詢資料的時候可以pass掉大部分資料,
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-ezvFNQFv-1619097949231)(https://image-set.oss-cn-zhangjiakou.aliyuncs.com/img-out/image-20210105153702771.png)]
條件:
- Hive的表存盤是
ORC - 創建表的時候指定
TABLEPROPERTIES中有:orc.create.index = true 資料插入的時候是有序插入- 主要應用
數值型別的列,用于:> >= < <= !=的判斷
使用
創建表
CREATE TABLE xxx stored AS ORC
TABLEPROPERTIES(
-- 開啟壓縮
'orc.compress' = 'SNAPPY',
-- 開啟行組索引
'orc.create.index = true'
);
插入資料
INSERT INTO TABLE xxx SELECT ......
DISTRIBUTE BY id SORT BY id;
查詢資料
set hive.optimize.index.filter=true; -- 自動使用索引優化
SELECT * FROM xxx WHERE id < 100;
布隆過濾器
原理
對ORC中每個分塊的資料,做分塊索引
確保=的查詢是很快的,
如果確定了分塊,那么
=判斷很快,如果不確定分塊,需要挨個判斷,
最好和行組索引一起使用,行組可以加速對分塊的判斷,
布隆索引可以加速對分塊內資料的
=判斷
條件
- 必須是ORC存盤
- 創建表的時候指定
TABLEPROPERTIES中有:orc.bloom.filter.columns = '欄位串列逗號分隔' - 只用于
=判斷
如何使用
布隆過濾器索引可以和行組過濾器索引一起使用,效果更好,
建表
CREATE TABLE xxx stored AS ORC
TABLEPROPERTIES(
-- 開啟壓縮
'orc.compress' = 'SNAPPY',
-- 開啟行組索引
'orc.create.index = true',
-- 開啟布隆過濾器
"orc.bloom.filter.columns" = "id,price"
);
插入資料
無要求(針對布隆過濾器)
如果使用了行組,請有序寫入
查詢資料
set hive.optimize.index.filter=true; -- 自動使用索引優化
SELECT * FROM xxx WHERE id = 1000;
索引使用的限制
不要亂加索引,有消耗
作為關聯條件的可以用索引
經常被WHERE的可以選擇行組過濾索引
經常被=的,可以選擇布隆過濾器
Hive的常見函式
IF 函式
語法:
IF (運算式, true結果, false結果)
意義:對運算式進行判斷,如果運算式為真,將回傳true的結果
如果為假將回傳false的結果
舉例:
SELECT IF (1=1, '是', '否');
-- IF也可以嵌套比如
IF (a=b, IF(c=e, 1, 2), 0);
nvl函式
語法:
NVL(被判斷的值, 默認回傳值)
意義:對被判斷的值進行判斷,如果它為NULL,將回傳默認值,否則就回傳這個值本身
舉例:
SELECT NVL(NULL, '是空');
COALESCE函式
幫助查找第一個不為空的資料
語法:
COALESCE(引數串列*);
作用:從引數串列中,回傳第一個不為NULL的資料
-- 示例
SELECT COALESCE(NULL,NULL,'你好', '哈哈');
-- 將會回傳你好
CASE WHEN THEN
作用就是對資料進行判斷,回傳想要的值
語法1:
-- 以CASE開始
CASE
WHEN 運算式 THEN 回傳值
WHEN 運算式 THEN 回傳值
......
ELSE
END -- 以END結束
示例sql
CASE
WHEN name='張三' THEN '帥哥'
WHEN name='李四' THEN '丑男'
ELSE '呵呵'
END
語法2:
-- 以CASE開始
CASE
列
WHEN 值 THEN 回傳值
WHEN 值 THEN 回傳值
......
ELSE
END -- 以END結束
CASE
name
WHEN ’張三' THEN '帥哥'
ELSE '丑男'
END;
isnull
語法:isnull( a )
回傳值:boolean
說明:如果a為null就回傳true,否則回傳false,
isnotnull
語法:isnotnull(a)
回傳值:boolean
說明:如果a為非null就回傳true,否則回傳false,
Hive優化2
并行優化
并行編譯
Hive默認情況下,只能同時編譯一個SQL到MapReduce代碼的轉換,并對這個程序上鎖,
為了提高效率,同時減少死鎖發生的可能性,我們需要將這個一次只能編譯一個的操作,優化為并行執行,
引數:
set hive.driver.parallel.compilation=true;
默認這個引數是False;
搭配引數:
hive.driver.parallel.compilation.global.limit
表示,最大的并行度是多少,默認是3
這個優化不能提交性能,但是能夠提高體驗
并行Stage執行
Hive的SQL在翻譯成MR任務的時候,可能會有很多的stage(階段)
階段之間都會有依賴關系:
- 前后依賴(前面的MR執行完成,后面的MR才可以去運行)
- 無依賴
如果多個State之間沒有依賴,他們如果能夠并行執行就能夠提高集群的整體資源利用率,
引數:
set hive.exec.parallel=true,可以開啟并發執行,默認為false,
set hive.exec.parallel.thread.number=16; //同一個sql允許的最大并行度,默認為8,
小檔案優化
建議在企業中去使用,個人虛擬機電腦的性能不足,會導致性能下降,
前置條件:MapReduce的執行結果,不是一個單獨的檔案,而是多個檔案,
如果MR任務的結果產生了很多的小檔案存盤在HDFS中,那么就會造成性能的下降(對NameNode的壓力會很大)
小檔案的HDFS影響
-
對磁盤尋道不友好(排除SSD,這里指的是機械硬碟)
- 95%的HDFS集群底層都是機械硬碟(少量土豪用SSD)
- 機械硬碟在隨機讀寫上的性能是非常弱勢的(對比SSD)
- 因為小檔案代表了更多的block,更多的block代表了更多的資料并非連續的存盤在磁盤的某一區域而是分散存盤,
- 因為block多帶來的分散存盤,導致磁盤會頻繁的進行隨機尋址,
-
對NameNode的壓力很大
在HDFS中檔案是以
block存盤的,每一個塊在HDFS中都有記錄,如果檔案較小,并且比較多的話,就導致block的數量會變的更多,更多的block會消耗更多的NameNode的資源,
舉例:
磁盤占用率100%,但是每秒傳輸資料量,不到5MB/s
底層原因就是:小檔案太多,磁盤在做頻繁的隨機尋址
Hive執行MapReduce也會產生很多的結果檔案,
這些結果檔案,都不一定每一個都達到了一個block的大小,
隨著時間的推移,結果檔案會越攢越多,最侄訓是導致了檔案過多對HDFS的影響,以及檔案都不一定達到block的大小,也是一種小檔案過多的問題,
對于這個問題,我們可以要求Hive在執行完畢后,合并結果檔案,
合并后不是一個檔案,而是可能多個檔案,
每一個檔案默認是按照HDFS的block大小來設定的
引數
# 是否開啟合并Map端小檔案,在Map-only的任務結束時合并小檔案,true是打開,
hive.merge.mapfiles
# 是否開啟合并Reduce端小檔案,在map-reduce作業結束時合并小檔案,true是打開,
hive.merge.mapredfiles
# 合并后MR輸出檔案的大小,默認為256M,建議設定為255M
hive.merge.size.per.task
# 對小檔案判斷的平均大小閾值(結果檔案的平均大小如果小于閾值,才會進行合并的操作)
hive.merge.smallfiles.avgsize
矢量化查詢
對于分布式系統的優化,有兩個方向:
-
增加分布式能力(增加并行計算能力)(橫向拓展)
說白了就是加機器,加CPU數量
-
增加單機的處理能力(縱向拓展)
矢量化查詢,就是型別2的優化,
MapReduce默認情況下,對資料的處理是一條條的處理的,
一條條處理是很正常的處理方式,寫到這里,沒有任何歧義,只是為了烘托矢量化查詢而已,
矢量化查詢是指,對資料一批批的處理,
要執行矢量化是有要求的:
- 必須是
ORC存盤
引數
# 開啟矢量化查詢
set hive.vectorized.execution.enabled=true;
# 開啟矢量化在reduce端
set hive.vectorized.execution.reduce.enabled = true;
這種帶有enable型別的,只是指開啟某個功能,功能能不能用得上,是hive的判斷,
比如前面將的map join
讀取零拷貝優化
概念:盡量減少在讀取的時候讀取的資料量的大小,
條件:
- ORC存盤(列存盤)
- 查詢只用到的部分的列
一般情況下,我們寫SQL是有一部分的SQL是只會用到表中的部分的列,并不是要全部的列,
這種場景下,就可以只加載用到的列即可,不用到的不去加載(必須是列式存盤),
引數
set hive.exec.orc.zerocopy=true;
依舊是開啟功能,能否用上,看hive的判斷
資料傾斜優化
資料傾斜:在分布式程式分配任務的時候,任務分配的不平均,
資料傾斜,在企業開發中是經常遇到的,以及是非常影響性能的一種場景,
資料傾斜一旦發生,橫向拓展只能緩解這個情況,而不能解決這個情況,
如果遇到資料傾斜,一定要從根本上去解決這個問題,而不是想著加機器來解決,
JOIN的時候的傾斜
方案一
用前面講過的map join SMB join 這些優化去解決,
效果不太好,本身這些提高執行性能的方案,順帶著將傾斜的性能也提升一點,本質上不是解決傾斜的方案,
方案二
Sekw Join
方案的方式是:
對傾斜列的資料,進行單獨處理,也就是遇到傾斜列的資料的時候,直接找一個中間目錄臨時存盤,當前MR不去處理
等當前MR完成后,在單獨處理這個傾斜的資料集,
這種解決方式有一個前置條件,Hive必須要知道,哪個列的資料傾斜了,
如何讓Hive知曉哪個列是傾斜列,就有2種方式
方式1:運行時判斷
在執行MR的程序中,Hive會對資料記錄計數器,當計數器的值大于某個閾值的時候,認為這個資料是傾斜的列,對其進行單獨處理,
方式2:編譯時判斷
指的就是,執行SQL的人提前知曉某個列就是傾斜列,
在建表的時候,就指定某個列是傾斜列即可,
引數
# 開啟傾斜優化,針對傾斜優化的總開關
set hive.optimize.skewjoin=true;
# 設定運行時判斷的時候,對傾斜資料量的閾值
set hive.skewjoin.key=100000;
# 開啟編譯時的傾斜優化,針對編譯時的開關
set hive.optimize.skewjoin.compiletime=true;
# 示例陳述句,這個陳述句用于編譯時判斷,提前告知Hive哪個列是傾斜的
CREATE TABLE list_bucket_single (key STRING, value STRING)
-- 傾斜的欄位和需要拆分的key值
SKEWED BY (id) ON (1,5,6)
-- 為傾斜值創建子目錄單獨存放
[STORED AS DIRECTORIES];
-- 上面的引數可以組合一塊使用
-- 當表有SKEWED BY的設定,走編譯時優化
-- 如果表沒有這個設定,就運行時優化
在企業場景中,滿足編譯時的判斷的場景不多,多數時候還是靠運行時來優化,
編譯時的一種場景舉例:
比如,傳智播客的北京和上海校區很火爆,90%的學生都來這倆校區,
學生報名的事實表,鐵定在北京和上海兩個校區的ID上產生傾斜,
這樣的場景才是適合編譯時的,也就是在干活之前就分析出來哪個地方是傾斜了,
資料傾斜,無法避免,這是事實產生事件的現實映射,
只要你沒有能力解決現實事件,那么事件的產生就會傾斜,
我們要做的是,在資料傾斜的前提下,完成性能優化,
Union優化
在前面的優化中,不管是運行時優化,還是編譯時優化,都會產生兩份結果,
這兩份結果最終都需要進行Union操作合并為一份結果
引數:
set hive.optimize.union.remove=true;
開啟這個引數的時候,對中間資料進行重復性利用,提升union的性能,
重復利用:不會單獨開啟任務對多份資料執行合并,而是每一個任務在執行之后直接將結果輸出到目的地,
不開啟Union合并優化:
MR1 對普通資料進行處理,輸入路徑:/tmp/1
MR2 對傾斜資料進行處理,輸入路徑:/tmp/2
合并后,資料寫入最終目的地:/user/hive/warehouse/xxx.db/xxxtable/
如果開啟了優化:
MR1 對普通資料進行處理,輸入路徑:/user/hive/warehouse/xxx.db/xxxtable/
MR2 對傾斜資料進行處理,輸入路徑:/user/hive/warehouse/xxx.db/xxxtable/
GROUP BY分組統計的傾斜處理
對于資料傾斜,典型的兩個性能點:
- Join操作
- Group BY操作
分組
必聚合,
前提條件:對資料走平均打散,不按照hash散列
優化1:
利用MapReduce的Combina 機制,在Map端完成預聚合操作,
因為,分組是必聚合的,所以,我們可以做預聚合
引數:
hive.map.aggr=true;
優化2:
大combina機制,對預聚合產生在第一個MR的reduce端,
最終聚合產生在第二個MR中
將Map端的Combina擴散到真個MR,最終的聚合交由第二個MR來做,
在絕對的性能上:優化1是性能最好的,因為節省了很多的中間資料傳輸,同時一個MR搞定,不需要搞第二個MR來做,
但是,如果資料量巨大,這個MapReduce的任務的壓力就會很大,同時執行時間可能很長,
執行時間過長,中間的變數就不好控,一旦出現問題,重頭再來,
所以,對于海量資料一般使用優化2的方式,因為如果出現問題,起碼可以從第一階段的結果再來,
引數:
hive.groupby.skewindata=true;
MapReduce迭代計算的概念(補充)
迭代計算,就是一步步的計算出結果的方式,
方式比一次性計算出結果效率要低,但是穩定性和資料的可復用性更好,
在很多的企業業務計算中,有的資料計算是很復雜的,
可能:
- 如果要在一個MapReduce中完成這個業務,代碼寫起來很復雜
- 根本就不可能在一個MapReduce中完成整個業務的計算,
MapReduce的計算模型
上面提到:有可能會:根本就不可能在一個MapReduce中完成整個業務的計算,
這個是因為MapReduce的計算模型,就2個:
- Map模型
- Reduce模型
嚴格意義來說,MR叫做可供使用的算子就2個,一個是map算子一個是reduce算子
很多的業務計算都受限map和reduce方法的限制,因為,比如map方法
map(傳入引數固定){
? 我們只能在這個部分,做自由處理,
? return 回傳形式固定
}
reduce(傳入引數固定){
? 我們只能在這個部分,做自由處理,
? return 回傳形式固定
}
MR的迭代
基于前面的概念,所以很多的業務計算本質上是迭代的計算,
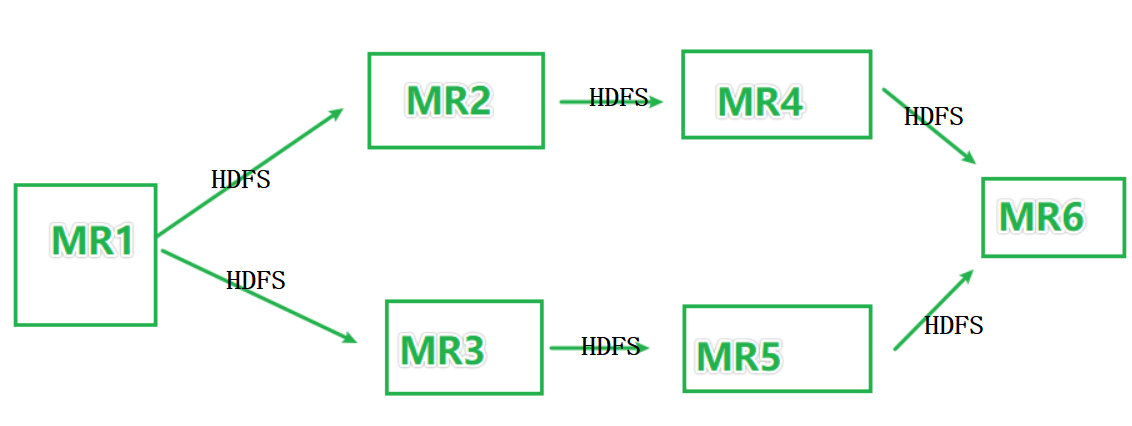
如圖,某些復雜的業務場景可能會如圖所示執行MR的迭代計算,
上圖中,MR之間基于HDFS完成資料的共享,
迭代計算中,中間產生的資料,都是中間結果,
這些中間結果就類似數倉中,ODS->DWD->DWM->DWS->APP的迭代程序,
上圖本質上是一個有向無環圖(DAG)
有向是指:MR1走向MR6的方向
無環:沒有形成倍訓
前面分組傾斜處理優化中的優化2方案,就是一種迭代計算的思想延伸,
Hive優化小總結
Hive在各方面優化的東西亂七八糟一堆,
我們這個數倉專案,70%時間都在Hive上,30%的時間在業務分析,建模分析上,
很痛苦,我們只想專心做業務分析,不想搞亂七八糟的這優化那優化的,
后面學習Spark和Flink的時候就能體會到專心做業務的快感了,
HIVE提到的所有優化項大全
--磁區
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive壓縮
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--寫入時壓縮生效
set hive.exec.orc.compression.strategy=COMPRESSION;
--分桶
set hive.enforce.bucketing=true;
set hive.enforce.sorting=true;
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
--并行執行
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8;
--小檔案合并
-- set mapred.max.split.size=2147483648;
-- set mapred.min.split.size.per.node=1000000000;
-- set mapred.min.split.size.per.rack=1000000000;
--矢量化查詢
set hive.vectorized.execution.enabled=true;
--關聯優化器
set hive.optimize.correlation=true;
--讀取零拷貝
set hive.exec.orc.zerocopy=true;
--join資料傾斜
set hive.optimize.skewjoin=true;
-- set hive.skewjoin.key=100000;
set hive.optimize.skewjoin.compiletime=true;
set hive.optimize.union.remove=true;
-- group傾斜
set hive.groupby.skewindata=false;
示例千億級別的資料傾斜優化實操
https://www.bilibili.com/video/BV1Tv411B7Cf
HIVE提到的所有優化項大全
--磁區
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=150000;
--hive壓縮
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--寫入時壓縮生效
set hive.exec.orc.compression.strategy=COMPRESSION;
--分桶
set hive.enforce.bucketing=true;
set hive.enforce.sorting=true;
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
--并行執行
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8;
--小檔案合并
-- set mapred.max.split.size=2147483648;
-- set mapred.min.split.size.per.node=1000000000;
-- set mapred.min.split.size.per.rack=1000000000;
--矢量化查詢
set hive.vectorized.execution.enabled=true;
--關聯優化器
set hive.optimize.correlation=true;
--讀取零拷貝
set hive.exec.orc.zerocopy=true;
--join資料傾斜
set hive.optimize.skewjoin=true;
-- set hive.skewjoin.key=100000;
set hive.optimize.skewjoin.compiletime=true;
set hive.optimize.union.remove=true;
-- group傾斜
set hive.groupby.skewindata=false;
示例千億級別的資料傾斜優化實操
https://www.bilibili.com/video/BV1Tv411B7Cf
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279562.html
標籤:其他