1 概述
資料結構和內部編碼
Redis 沒有傳統關系型資料庫的Table 模型
schema 所對應的db僅以編號區分,同一個db 內,key 作為頂層模型,它的值是扁平化的,也就是說db 就是key的命名空間
key的定義通常以“:” 分隔,如:Article:Count:1
我們常用的Redis資料型別有:string、list、set、map、sorted-set
redisObject通用結構
Redis中的所有value 都是以object 的形式存在的,其通用結構如下
typedef struct redisObject {
unsigned [type] 4;
unsigned [encoding] 4;
unsigned [lru] REDIS_LRU_BITS;
int refcount;
void *ptr;
} robj;
- type 指的是前面提到的 string、list 等型別
- encoding 指的是這些結構化型別具體的實作方式,同一個型別可以有多種實作
e.g. string 可以用int 來實作,也可以使用char[] 來實作;list 可以用ziplist 或者鏈表來實作 - lru 表示本物件的空轉時長,用于有限記憶體下長時間不訪問的物件清理
- refcount 物件參考計數,用于GC
- ptr 指向以encoding 方式實作這個物件實際實作者的地址
如:string 物件對應的SDS地址(string的資料結構/簡單動態字串)
單執行緒

單執行緒為何這么快?
-
純記憶體
-
非阻塞IO
-
避免執行緒切換和競態消耗
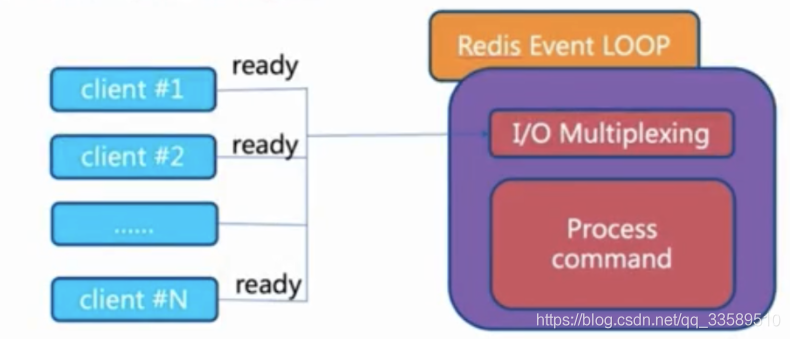
-
一次只運行一條命令
-
拒絕長(慢)命令
keys, flushall, flushdb, slow lua script, mutil/exec, operate big value(collection) -
其實不是單執行緒
fysnc file descriptor
close file descriptor
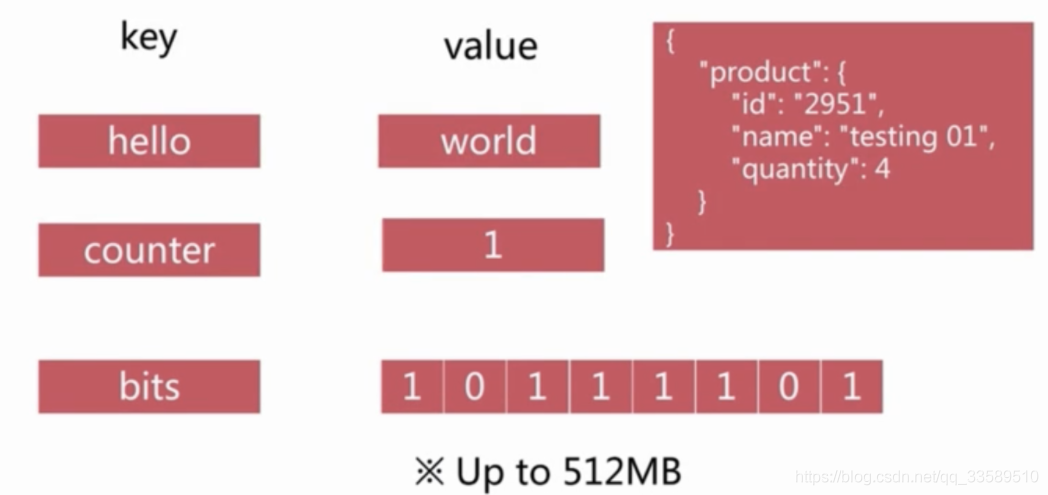
string
Redis中的string 可表示很多語意
- 位元組串(bits)
- 整數
- 浮點數
這三種型別,redis會根據具體的場景完成自動轉換,并且根據需要選取底層的承載方式
例如整數可以由32-bit/64-bit、有符號/無符號承載,以適應不同場景對值域的要求
- 字串鍵值結構,也能是 JSON 串或者 XML 結構
記憶體結構
在Redis內部,string的內部以 int、SDS(簡單動態字串 simple dynamic string)作為存盤結構
- int 用來存放整型
- SDS 用來存放位元組/字符和浮點型SDS結構
SDS
typedef struct sdshdr {
// buf中已經占用的字符長度
unsigned int len;
// buf中剩余可用的字符長度
unsigned int free;
// 資料空間
char buf[];
}
- 結構圖
存盤的內容為“Redis”,Redis采用類似C語言的存盤方法,使用’\0’結尾(僅是定界符),
SDS的free 空間大小為0,當free > 0時,buf中的free 區域的引入提升了SDS對字串的處理性能,可以減少處理程序中的記憶體申請和釋放次數,
buf 的擴容與縮容
當對SDS 進行操作時,如果超出了容量,SDS會對其進行擴容,觸發條件如下:
- 位元組串初始化時,buf的大小 = len + 1,即加上定界符’\0’剛好用完所有空間
- 當對串的操作后小于1M時,擴容后的buf 大小 = 業務串預期長度 * 2 + 1,也就是擴大2倍,
- 對于大小 > 1M的長串,buf總是留出 1M的 free空間,即2倍擴容,但是free最大為 1M,
位元組串與字串
SDS中存盤的內容可以是ASCII 字串,也可以是位元組串
由于SDS通過len 欄位來確定業務串的長度,因此業務串可以存盤非文本內容
對于字串的場景,buf[len] 作為業務串結尾的’\0’ 又可以復用C的已有字串函式
SDS編碼的優化
value 在記憶體中有2個部分:redisObject和ptr 指向的位元組串部分,在創建時,通常要分別為2個部分申請記憶體,但是對于小位元組串,可以一次性申請,
快取視頻的基本資訊(資料源在MySQL)
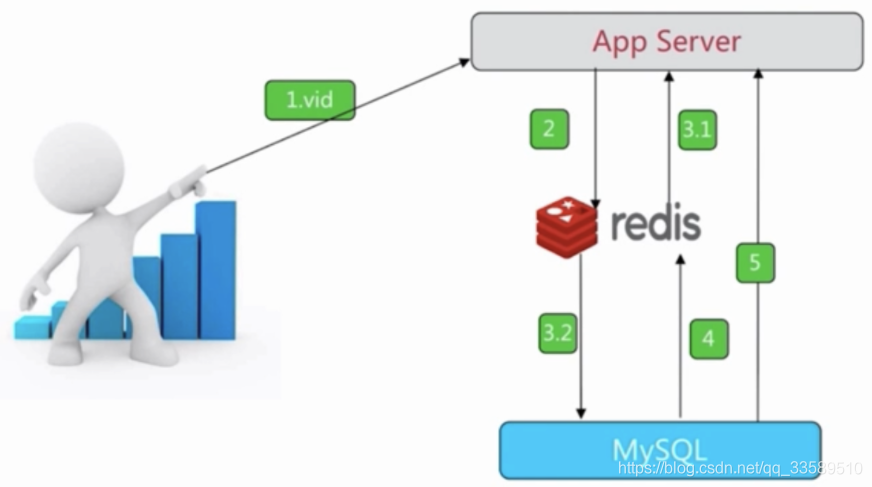
public VideoInfo get(Long id) {
String redisKey = redisPrefix + id;
VideoInfo videoInfo e redis.get(redisKey);
if (videoInfo == null) {
videoInfo = mysql.get(id);
if (videoInfo != null) {
// 序列化
redis.set(redisKey serialize(videoInfo)):
}
}
}
除此之外,string 型別的value還有一些CAS的原子操作,如:get、set、set value nx(如果不存在就設定)、set value xx(如果存在就設定),
String 型別是二進制安全的,也就是說在Redis中String型別可以包含各種資料,比如一張JPEG圖片或者是一個序列化的Ruby物件,一個String型別的值最大長度可以是512M,
在Redis中String有很多有趣的用法
- 把String當做原子計數器,這可以使用INCR家族中的命令來實作:INCR, DECR, INCRBY,
- 使用APPEND命令來給一個String追加內容,
- 把String當做一個隨機訪問的向量(Vector),這可以使用GETRANGE和 SETRANGE命令來實作
- 使用GETBIT 和SETBIT方法,在一個很小的空間中編碼大量的資料,或者創建一個基于Redis的Bloom Filter 演算法,
List
可從頭部(左側)加入元素,也可以從尾部(右側)加入元素,
有序串列,
微博粉絲即可以list結構存放在redis做快取,
key = 某大v
value = [zhangsan, lisi, wangwu]
還可存盤一些list型的資料結構,類似粉絲串列、文章的評論串列之類,
可通過lrange命令,即從某元素開始讀取多少元素,可基于list實作分頁查詢,這就是基于redis實作簡單的高性能分頁,可以做類似微博那種下拉不斷分頁的東西,性能高,就一頁一頁走,
搞個簡單的訊息佇列,從list頭推進去,從list尾拉出來,
List型別中存盤一系列String值,這些String按照插入的順序排序,
5.1 記憶體資料結構
List 型別的 value物件,由 linkedlist 或者 ziplist 實作,
當 List 元素個數少并且元素內容長度不大采用ziplist 實作,否則使用linkedlist
5.1.1 linkedlist實作
鏈表的代碼結構
typedef struct list {
// 頭結點
listNode *head;
// 尾節點
listNode *tail;
// 節點值復制函式
void *(*dup)(void * ptr);
// 節點值釋放函式
void *(*free)(void *ptr);
// 節點值對比函式
int (*match)(void *ptr, void *key);
// 鏈表長度
unsigned long len;
} list;
// Node節點結構
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
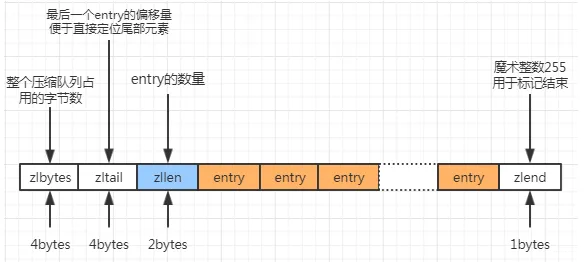
5.1.2 ziplist實作
ziplist 存盤在連續記憶體
- zlbytes:表示ziplist 的總長度
- zltail:指向最末元素,
- zllen:表示元素的個數,
- entry:為元素內容,
- zlend:恒為0xFF,作為ziplist的定界符
從上面的結構可以看出,對于linkedlist和 ziplist,它們的rpush、rpop、llen的時間復雜度都是O(1)
但是對于ziplist,lpush、lpop都會牽扯到所有資料的移動,時間復雜度為O(N)
但是由于List的元素少,體積小,這種情況還是可控的
對于ziplist 的每個Entry 其結構如下
記錄前一個相鄰的Entry的長度,作用是方便進行雙向遍歷,類似于linkedlist 的prev 指標
ziplist是連續存盤,指標由偏移量來承載
Redis中實作了2種方式的實作
- 當前鄰 Entry的長度小于254 時,使用1位元組來實作
- 否則使用5個位元組
這里面會有個問題,就是當前一個Entry的長度變化時,這時候有可能會造成后續的所有空間移動,當然這種情況發生的可能性比較小,
Entry內容本身是自描述的,意味著第二部分(Entry內容)包含了幾個資訊:Entry內容型別、長度和內容本身,而內容本身包含:型別長度部分和內容本身部分,型別和長度同樣采用變長編碼:
- 00xxxxxx :string型別;長度小于64,0~63可由6位bit 表示,即xxxxxx表示長度
- 01xxxxxx|yyyyyyyy : string型別;長度范圍是[64, 16383],可由14位 bit 表示,即xxxxxxyyyyyyyy這14位表示長度,
- 10xxxxxx|yy…y(32個y) : string型別,長度大于16383.
- 1111xxxx :integer型別,integer本身內容存盤在xxxx 中,只能是1~13之間取值,也就是說內容型別已經包含了內容本身,
- 11xxxxxx :其余的情況,Redis用1個位元組的型別長度表示了integer的其他幾種情況,如:int_32、int_24等,
由此可見,ziplist 的元素結構采用的是可變長的壓縮方法,針對于較小的整數/字串的壓縮效果較好
LPUSH 命令是在頭部加入一個新元素,RPUSH 命令是在尾部加入一個新元素,當在一個空的鍵值(key)上執行這些操作時會創建一個新的串列,類似的,當一個操作清空了一個list時,這個list對應的key會被洗掉,這非常好理解,因為從命令的名字就可以看出這個命令是做什么操作的,如果使用一個不存在的key呼叫的話就會使用一個空的list,
一些例子:
LPUSH mylist a # 現在list是 "a"
LPUSH mylist b # 現在list是"b","a"
RPUSH mylist c # 現在list是 "b","a","c" (注意這次使用的是 RPUSH)
list的最大長度是2^32 – 1個元素(4294967295,一個list中可以有多達40多億個元素)
從時間復雜度的角度來看,Redis list型別的最大特性是:即使是在list的頭端或者尾端做百萬次的插入和洗掉操作,也能保持穩定的很少的時間消耗,在list的兩端訪問元素是非常快的,但是如果要訪問一個很大的list中的中間部分的元素就會比較慢了,時間復雜度是O(N)
適用場景
- 社交網路中使用List進行時間表建模,使用 LPUSH 在用戶時間線中加入新的元素,然后使用 LRANGE 獲得最近加入的元素
- 可以把[LPUSH] 和[LTRIM] 命令結合使用來實作定長的串列,串列中只保存最近的N個元素
- 做訊息佇列,依賴像[BLPOP]這樣的阻塞命令
Set
類似List,但無序且其元素不重復,
向集合中添加多次相同的元素,集合中只存在一個該元素,在實際應用中,這意味著在添加一個元素前不需要先檢查元素是否存在,
支持多個服務器端命令來從現有集合開始計算集合,所以執行集合的交集,并集,差集都可以很快
set的最大長度是2^32 – 1個元素(一個set中可多達40多億個元素)
記憶體資料結構
Set在Redis中以intset 或 hashtable存盤,
- 對于Set,HashTable的value永遠為NULL
- 當Set中只包含整型資料時,采用intset作為實作
intset
核心元素是一個位元組陣列,從小到大有序的存放元素

因為元素有序排列,所以SET的獲取操作采用二分查找的方式,復雜度為O(log(N))
進行插入操作時,首先通過二分查找到要插入的位置,再對元素進行擴容
然后將插入位置之后的所有元素向后移動一個位置,最后插入元素,時間復雜度為O(N),
為了使二分查找的速度足夠快,存盤在content 中的元素是定長的,
當插入2018 時,所有的元素向后移動,并且不會發生覆寫的情況
并且當Set 中存放的整型元素集中在小整數范圍[-128, 127]內時,可以大大的節省記憶體空間,這里面需要注意的是:IntSet支持升級,但是不支持降級,
- Set 基本操作
適用場景
無序集合,自動去重,其實資料太多時不太推薦使用,
直接基于set將系統里需要去重的資料扔進去,自動就給去重了,如果你需要對一些資料進行快速的全域去重,你當然也可以基于jvm記憶體里的HashSet進行去重,但是如果你的某個系統部署在多臺機器上呢?
得基于redis進行全域的set去重
可以基于set玩兒交集、并集、差集的操作,比如交集吧,可以把兩個人的粉絲串列整一個交集,看看倆人的共同好友是誰?對吧
把兩個大v的粉絲都放在兩個set中,對兩個set做交集,但是全域這種計算開銷也大,
-
記錄唯一的事物
比如,你想知道訪問某個博客的IP地址,不要重復的IP,這種情況只需要在每次處理一個請求時簡單的使用SADD命令就可以了,可以確信不會插入重復的IP -
表示關系
你可以使用Redis創建一個標簽系統,每個標簽使用一個Set來表示,然后你可以使用SADD命令把具有特定標簽的所有物件的所有ID放在表示這個標簽的Set中
如果你想要知道同時擁有三個不同標簽的物件,那么使用SINTER命令就好了 -
可以使用SPOP 或者 SRANDMEMBER 命令從集合中隨機的提取元素,
Hashes/ Maps
一般可將結構化的資料,比如一個物件(前提是這個物件未嵌套其他的物件)給快取在redis里,然后每次讀寫快取的時候,即可直接操作hash里的某個欄位,
key=150
value={
“id”: 150,
“name”: “zhangsan”,
“age”: 20
}
hash類的資料結構,主要存放一些物件,把一些簡單的物件給快取起來,后續操作的時候,可直接僅修改該物件中的某欄位的值,
value={
“id”: 150,
“name”: “zhangsan”,
“age”: 21
}
因為Redis本身是一個K.V存盤結構,Hash型別的結構可以理解為subkey - subvalue
這里面的subkey - subvalue只能是
- 整型
- 浮點型
- 字串
因為Map的 value 可表示整型和浮點型,因此Map也可以使用hincrby 對某個field的value值做自增操作,
7.1 記憶體資料結構
hash有HashTable 和 ziplist 兩種實作,對于資料量較小的hash,使用ziplist 實作
7.1.1 HashTable 實作
HashTable在Redis 中分為3 層,自底向上分別是:
- dictEntry:管理一個field - value 對,保留同一桶中相鄰元素的指標,以此維護Hash 桶中的內部鏈
- dictht:維護Hash表的所有桶鏈
- dict:當dictht需要擴容/縮容時,用戶管理dictht的遷移
dict是Hash表存盤的頂層結構
// 哈希表(字典)資料結構,Redis 的所有鍵值對都會存盤在這里,其中包含兩個哈希表,
typedef struct dict {
// 哈希表的型別,包括哈希函式,比較函式,鍵值的記憶體釋放函式
dictType *type;
// 存盤一些額外的資料
void *privdata;
// 兩個哈希表
dictht ht[2];
// 哈希表重置下標,指定的是哈希陣列的陣列下標
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 系結到哈希表的迭代器個數
int iterators; /* number of iterators currently running */
} dict;
Hash表的核心結構是dictht,它的table 欄位維護著 Hash 桶,桶(bucket)是一個陣列,陣列的元素指向桶中的第一個元素(dictEntry),
typedef struct dictht {
//槽位陣列
dictEntry **table;
//槽位陣列長度
unsigned long size;
//用于計算索引的掩碼
unsigned long sizemask;
//真正存盤的鍵值對數量
unsigned long used;
} dictht;
從上圖可以看出,Hash表使用的是 鏈地址法 解決Hash沖突
當一個bucket 中的Entry 很多時,Hash表的插入性能會下降,此時就需要增加bucket的個數來減少Hash 沖突
7.1.1.1 Hash表擴容
和大多數Hash表實作一樣,Redis引入負載因子判定是否需要增加bucket個數
負載因子 = Hash表中已有元素 / bucket數量
擴容之后bucket的數量是原先的2倍
目前有2 個閥值:
-
小于1 時一定不擴容
-
大于5 時一定擴容
-
在1 ~ 5 之間時,Redis 如果沒有進行
bgsave/bdrewrite操作時則會擴容 -
當key - value 對減少時,低于0.1時會進行縮容,縮容之后,bucket的個數是原先的0.5倍
7.1.2 ziplist 實作
這里面的ziplist 和List的ziplist實作類似,都是通過Entry 存放element
和List不同的是,Map對應的ziplist 的Entry 個數總是2的整數倍,第奇數個Entry 存放key,下一個相鄰的Entry存放value
ziplist承載時,Map的大多數操作不再是O(1)了,而是由Hash表遍歷,變成了鏈表的遍歷,復雜度變為O(N)
由于Map相對較小時采用ziplist,采用Hash表時計算hash值的開銷較大,因此綜合起來ziplist的性能相對好一些
Redis Hashes 保存String域和String值之間的映射,所以它們是用來表示物件的絕佳資料型別(比如一個有著用戶名,密碼等屬性的User物件)
| `1` | `@cli` |
| `2` | `HMSET user:1000 username antirez password P1pp0 age 34` |
| `3` | `HGETALL user:1000` |
| `4` | `HSET user:1000 password 12345` |
| `5` | `HGETALL user:1000` |
一個有著少量資料域(這里的少量大概100上下)的hash,其存盤方式占用很小的空間,所以在一個小的Redis實體中就可以存盤上百萬的這種物件
Hash的最大長度是2^32 – 1個域值對(4294967295,一個Hash中可以有多達40多億個域值對)
Sorted sets(zset)
sorted set(有序集合)
去重但可排序,寫進去的時候給一個分數,有了這個分數可以自定義排序規則,
想根據時間對資料排序,則寫時可用時間戳作為分數,自動按時間排序,
排行榜:將每個用戶以及其對應的什么分數寫入進去
zadd board score username
接著
zrevrange board 0 99
就可以獲取排名前100的用戶
zrank board username
可以看到用戶在排行榜里的排名
zadd board 85 zhangsan
zadd board 72 wangwu
zadd board 96 lisi
zadd board 62 zhaoliu
96 lisi
85 zhangsan
72 wangwu
62 zhaoliu
zrevrange board 0 3
獲取排名前3的用戶
96 lisi
85 zhangsan
72 wangwu
zrank board zhaoliu
4
類似于Map的key-value對,但有序
- key :key-value對中的鍵,在一個Sorted-Set中不重復
- value : 浮點數,稱為 score
- 有序 :內部按照score 從小到大的順序排列
基本操作
由于Sorted-Set 本身包含排序資訊,在普通Set 的基礎上,Sorted-Set 新增了一系列和排序相關的操作:
- Sorted-Set的基本操作
內部資料結構
Sorted-Set型別的valueObject 內部結構有兩種:
- ziplist
實作方式和Map類似,由于Sorted-Set包含了Score的排序資訊,ziplist內部的key-value元素對的排序方式也是按照Score遞增排序的,意味著每次插入資料都要移動之后的資料,因此ziplist適用于元素個數不多,元素內容不大的場景, - skiplist+hashtable
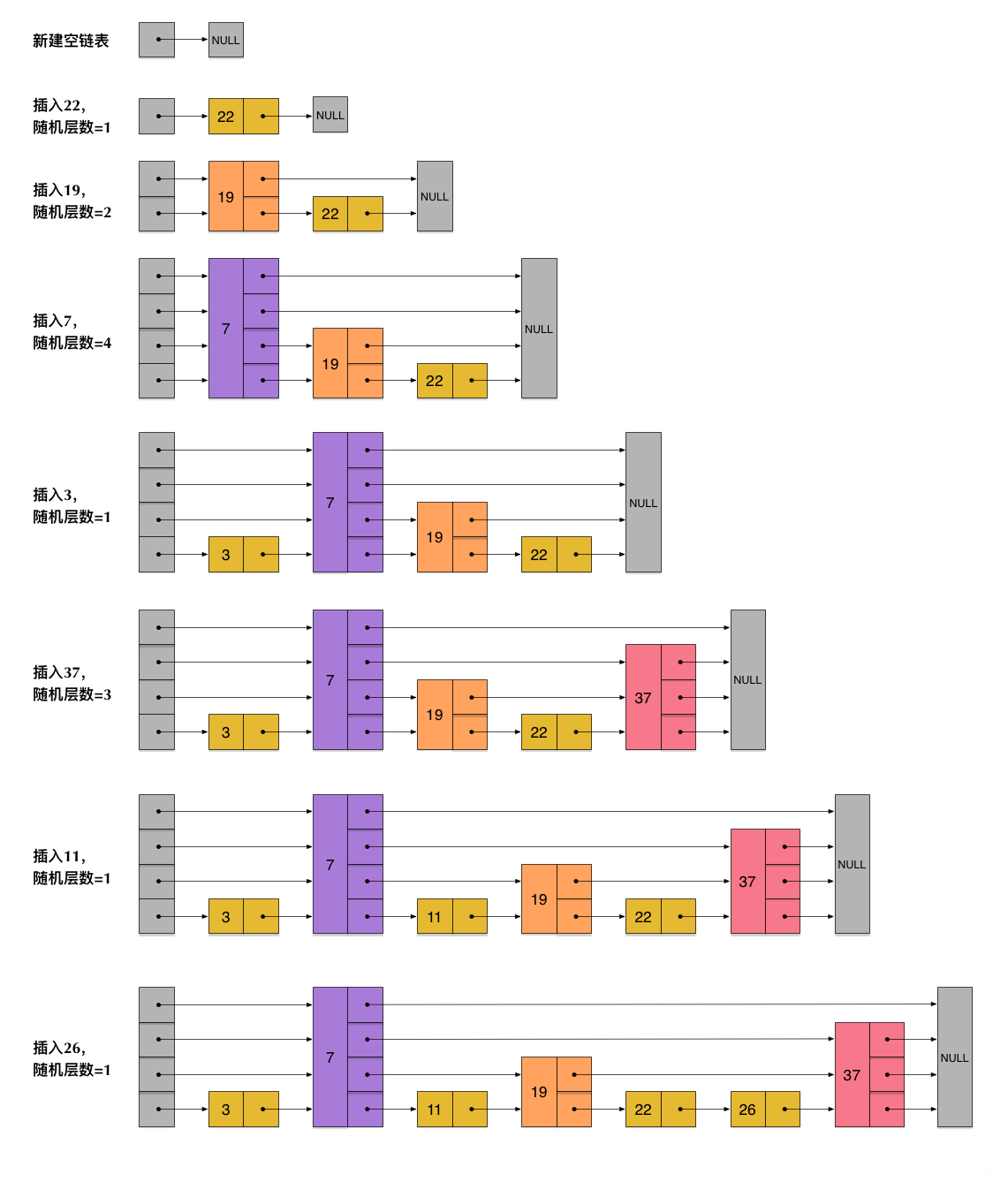
對于更通用的場景,Sorted-Set使用sliplist來實作,
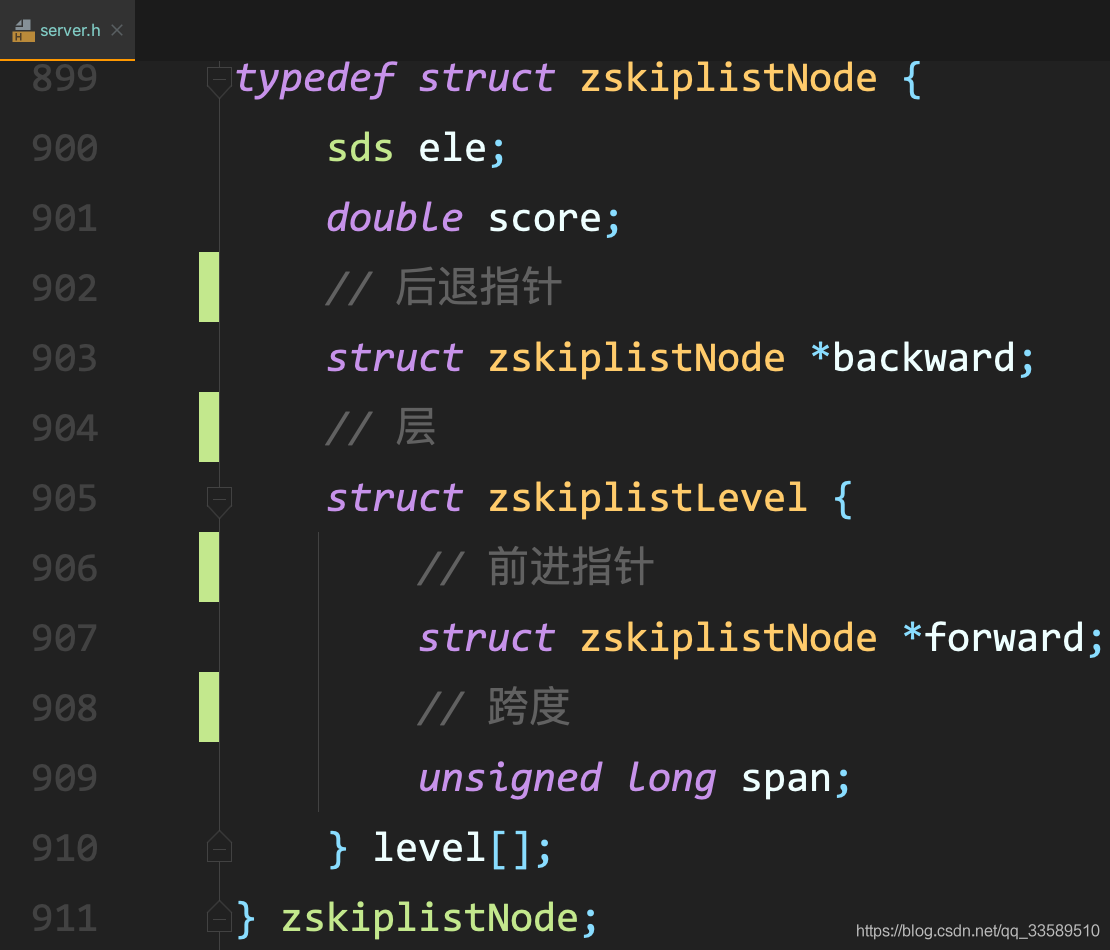
8.2.1 zskiplist
和通用的跳表不同的是,Redis為每個level 物件增加了span 欄位,表示該level 指向的forward節點和當前節點的距離,使得getByRank類的操作效率提升
- 資料結構

- 結構示意圖
從上圖可以看出,每次向skiplist 中新增或者洗掉一個節點時,需要同時修改圖示中紅色的箭頭,修改其forward和span的值,
需要修改的箭頭和對skip進行查找操作遍歷并廢棄過的路徑是吻合的,span修改僅是+1或-1,
zskiplist 的查找平均時間復雜度 O(Log(N)),因此add / remove的復雜度也是O(Log(N)),因此Redis中新增的span 提升了獲取rank(排序)操作的性能,僅需對遍歷路徑相加即可(矢量相加),
還有一點需要注意的是,每個skiplist的節點level 大小都是隨機生成的(1-32之間),
- zskiplistNode原始碼
8.2.2 hashtable
zskiplist 是zset 實作順序相關操作比較高效的資料結構,但是對于簡單的zscore操作效率并不高,Redis在實作時,同時使用了Hashtable和skiplist,代碼結構如下:

Hash表的存在使得Sorted-Set中的Map相關操作復雜度由O(N)變為O(1),
Redis有序集合型別與Redis的集合型別類似,是非重復的String元素的集合,不同之處在于,有序集合中的每個成員都關聯一個Score,Score是在排序時候使用的,按照Score的值從小到大進行排序,集合中每個元素是唯一的,但Score有可能重復,
使用有序集合可以很高效的進行,添加,移除,更新元素的操作(時間消耗與元素個數的對數成比例),由于元素在集合中的位置是有序的,使用get ranges by score或者by rank(位置)來順序獲取或者隨機讀取效率都很高,(本句不確定,未完全理解原文意思,是根據自己對Redis的淺顯理解進行的翻譯)訪問有序集合中間部分的元素也非常快,所以可以把有序集合當做一個不允許重復元素的智能串列,你可以快速訪問需要的一切:獲取有序元素,快速存在測驗,快速訪問中間的元素等等,
簡短來說,使用有序集合可以實作很多高性能的作業,這一點在其他資料庫是很難實作的,
使用有序集合你可以:
-
在大型在線游戲中創建一個排行榜,每次有新的成績提交,使用ZADD命令加入到有序集合中,可以使用ZRANGE命令輕松獲得成績名列前茅的玩家,你也可以使用ZRANK根據一個用戶名獲得該用戶的分數排名,把ZRANK 和 ZRANGE結合使用你可以獲得與某個指定用戶分數接近的其他用戶,這些操作都很高效,
-
有序集合經常被用來索引存盤在Redis中的資料,比如,如果你有很多用戶,用Hash來表示,可以使用有序集合來為這些用戶創建索引,使用年齡作為Score,使用用戶的ID作為Value,這樣的話使用ZRANGEBYSCORE 命令可以輕松和快速的獲得某一年齡段的用戶,
有序集合可能是Redis中最高級的資料型別了,所以請花一些時間查看一下 有序集合命令串列 來獲得更多資訊,同時你可能也想閱讀Redis資料型別介紹
Bitmaps
位圖型別,String型別上的一組面向bit操作的集合,由于 strings是二進制安全的blob,并且它們的最大長度是512m,所以bitmaps能最大設定 2^32個不同的bit,
HyperLogLogs
pfadd/pfcount/pfmerge,
在redis的實作中,使用標準錯誤小于1%的估計度量結束,這個演算法的神奇在于不再需要與需要統計的項相對應的記憶體,取而代之,使用的記憶體一直恒定不變,最壞的情況 下只需要12k,就可以計算接近2^64個不同元素的基數,
GEO
geoadd/geohash/geopos/geodist/georadius/georadiusbymember
Redis的GEO特性在 Redis3.2版本中推出,這個功能可以將用戶給定的地理位置(經、緯度)資訊儲存起來,并對這些資訊進行操作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279571.html
標籤:其他
上一篇:【Redis破障之路】二:Redis安裝和基本資料結構
下一篇:堆疊的應用——運算式求值