目錄
- 1. 堆疊和佇列
- 2. 堆疊的模擬實作
- 3. 佇列的模擬實作
- 4. 認識雙端佇列
- 5. 優先級佇列
- 5.1 優先級佇列實作
- 5.1.1 push
- 5.1.2 pop
- 5.2 仿函式
- 6. 優先級佇列最終代碼
1. 堆疊和佇列
堆疊最優實作是陣列,
- 優點:隨機訪問,cpu快取利用率高
- 缺點:頭部和中間,洗掉,插入效率較低,且需要增容
佇列最優實作是鏈表,
- 優點:任意位置,插入和洗掉,O(1)
- 缺點:不支持隨機訪問,快取利用率低
2. 堆疊的模擬實作
#pragma once
//配接器模式
namespace zjn{
template <class T, class Container = deque<T> >
class stack{
public:
void push_back(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
const T& top()const
{
return _con.back();
}
bool empty()const
{
return _con.empty();
}
size_t size()const
{
return _con.size();
}
private:
Container _con;
};
}
3. 佇列的模擬實作
#pragma once
namespace zjn{
template <class T, class Container = deque<T> >
class queue{
public:
void push_back(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
const T& front()const
{
return _con.front();
}
const T& back()const
{
return _con.back();
}
bool empty()const
{
return _con.empty();
}
size_t size()const
{
return _con.size();
}
private:
Container _con;
};
}
4. 認識雙端佇列
deque(雙端佇列):是一種雙開口的"連續"空間的資料結構,雙開口的含義是:可以在頭尾兩端進行插入和洗掉操作,且時間復雜度為O(1),佇列只能先進先出,他和佇列沒有關系,更像一個vector和list的融合體,
與vector比較,頭插效率高,不需要搬移元素;與list比較,空間利用率比較高,
vector和list現在依舊存在,證明了其實他是一個最終失敗的設計,但是佇列和堆疊依舊用它來適配,佇列和堆疊主要就是對頭尾進行操作,說明對于他們兩個來說,用雙端佇列來實作是個不錯的選擇,
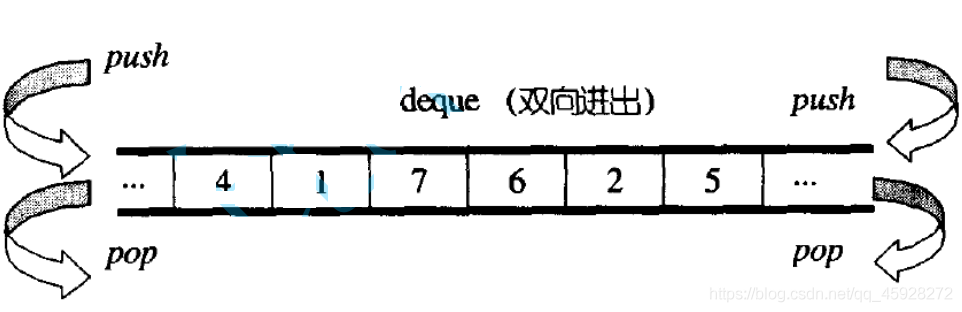
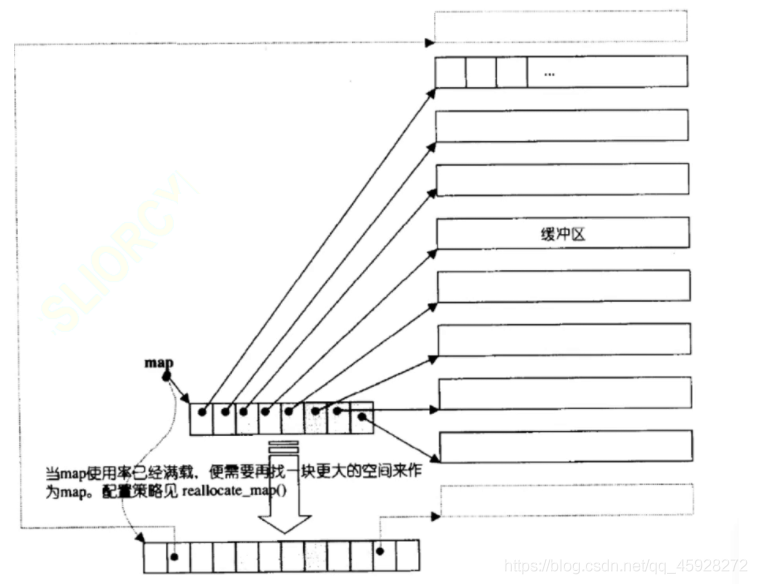
一個個分散的空間無法隨機訪問,連續的空間需要增容,所以雙端佇列采取折中的方式,將資料存在一段空間里,假如空間滿了,不是增容而是轉入下一個緩沖區,
這些緩沖區可以看做一個個陣列,使用一個指標陣列來管理他(即一個個指標指向緩沖區)
T* arr[]
或者
T** arr=(T**)malloc(sizeof(int*));
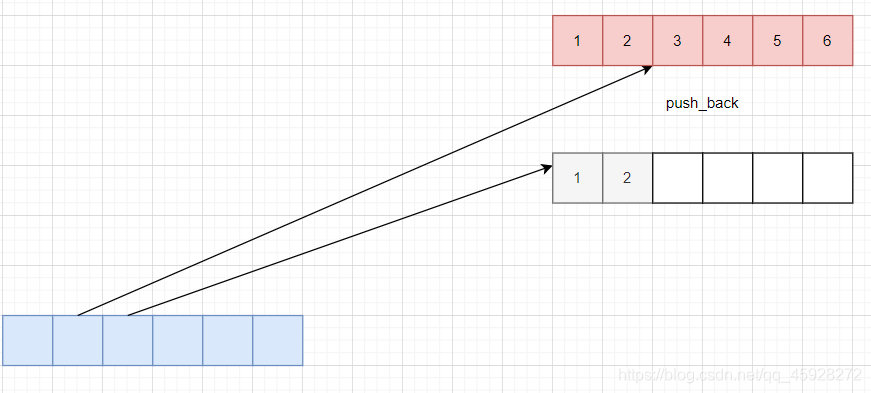
push_back,當前空間滿了不擴容,轉向下一個陣列,
那中間插入呢,挪動資料嗎,插入洗掉效率低,但單個擴容呢,【】可以使用是因為他根據每個陣列的大小是一致的,相除算出你在那一個陣列,單個擴容就會讓陣列大小不一致,那還要記錄他增了多少,來計算,
迭代器是比較復雜的
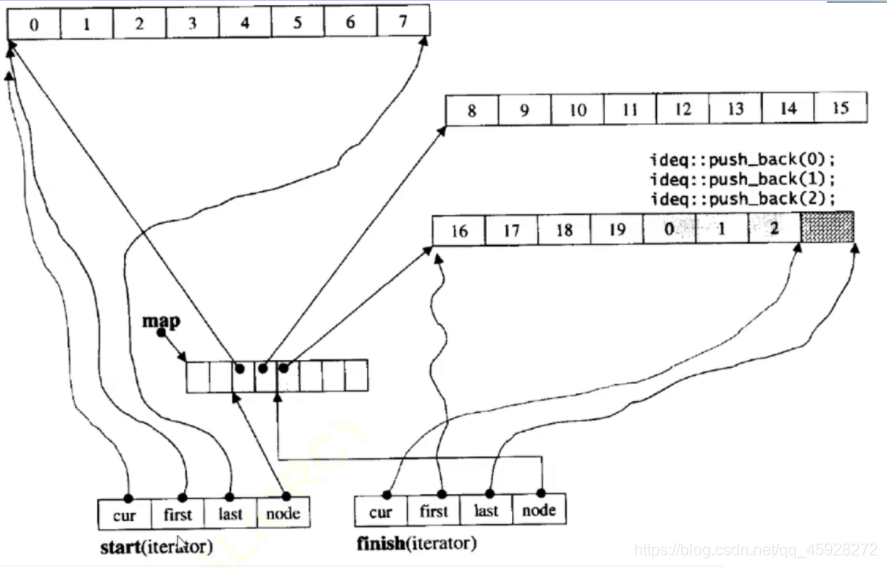
有兩個迭代器,一個start,一個finish,
first指向起始位置,last指向末尾的下一個位置,
cur指向當前位置,
node是下一個buf的首地址,
一般用迭代器的場景,
iterator it=begin();
while(it!=end())
{
*it;
it++;
}
*it實際就是對start中的cur進行解參考
it++就是讓cur++,但是end()是finish中last的位置
cur++到自己buf的end()的時候,通過node找到下一個陣列,
然后將找到的陣列的開始和結束,給到start的開始結束,node++在指向下一個buf,
然后cur再次++,所以這個指標陣列就像一個中控器,
所以總結一下,對于雙端佇列頭刪頭插效率還可以,但是無法替代的原因就是,【】使用太頻繁了,所以比較雞肋
5. 優先級佇列
對于入資料沒有要求,但是出資料是按默認優先級高的來出,優先級是否高視場景而定,
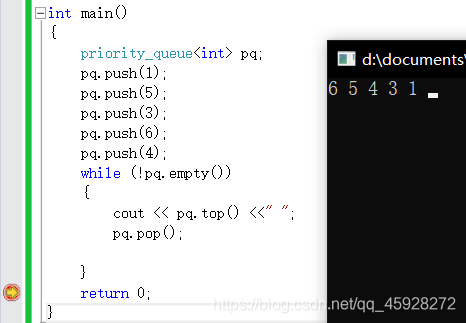
由于他底層是堆,可以看到默認大堆,每次用的時候,取堆頂資料輸出,然后洗掉堆頂,就完成了堆排序,所以他的pop介面里面必定有調堆的程序,

template很好理解,因為他底層是完全二叉樹,使用vector來適配堆,Compare是一個仿函式,當less的時候是大堆,當傳入greater的時候是小堆,
5.1 優先級佇列實作
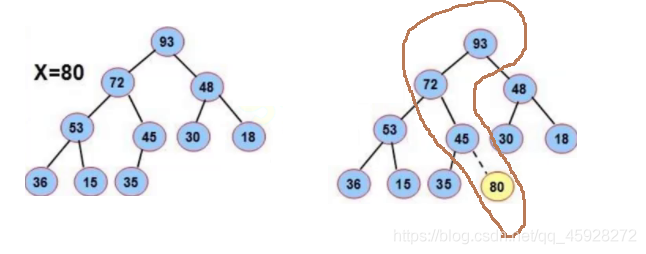
5.1.1 push
尾插資料,向上調整
大堆為例:
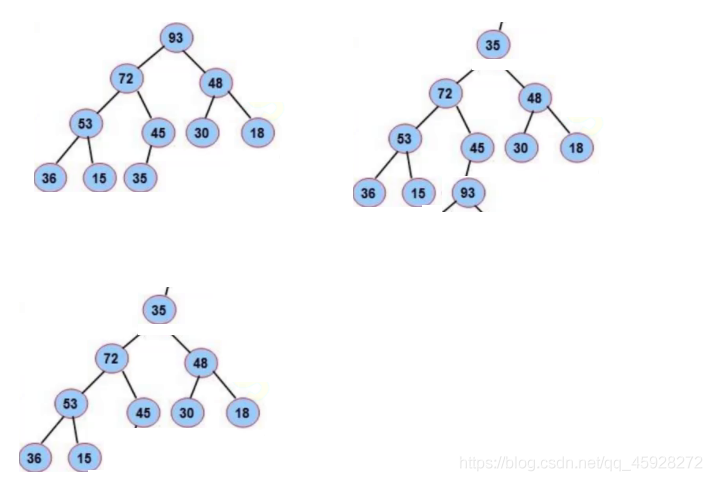
5.1.2 pop
洗掉堆頂,堆頂和堆尾交換,洗掉堆尾,向下調整
#pragma once
#include<iostream>
#include<vector>
#include<assert.h>
#include<queue>
using namespace std;
namespace zjn{
template<class T, class Container = vector<T>>
class priority_queue
{
public:
//寫了有區間的,不會默認生成了,所以要再寫一個無參的
priority_queue()
{};
//對于已有的一段區間進行構造優先級佇列,兩種方法
template<class iterator>
priority_queue(iterator first, iterator last)
:_Con(first,last)
{
//向下調整法
for (int i = ((_Con.size() - 1-1)/2); i >=0; i--)
{
AdjustDown(i);
}
//向上調整法建堆
//for (int i = 1; i < _Con.size(); i++)
//{
// AdjustUp(i);
//}
}
//從下往上,和父親開始比較
void AdjustUp(int child)
{
//找出父親
int parnet = (child - 1) / 2;
//本來應該是當孩子小于等于0時,父親小于0停止,但是由于父親是除法算出來的不會小于0,那就讓孩子小于等于0時停止(孩子大于0繼續)
while (child>0)
{
//如果孩子比父親大,那么就交換
if (_Con[child]>_Con[parnet])
{
swap(_Con[child], _Con[parnet]);
//向上繼續迭代
child = parnet;
parnet = (child - 1) / 2;
}
//孩子小于父親說明插入的資料剛好滿足,退出
else
{
break;
}
}
}
void push(const T& x)
{
//堆尾插入x
_Con.push_back(x);
//傳下標,把孩子調整上去
AdjustUp(_Con.size() - 1);
}
//從上往下,父親和大的那一個孩子比較
void AdjustDown(int parent)
{
//默認是左孩子
size_t child = parent * 2 + 1;
while (child<_Con.size())
{
//左右孩子大的那一個和父親比較,注意當堆尾只有一個左孩子時,雖然child<size進入回圈,但是他沒有右孩子會導致越界
if (child + 1<_Con.size() && _Con[child] < _Con[child + 1])
{
child++;
}
if (_Con[child]>_Con[parent])
{
swap(_Con[child], _Con[parent]);
//向下繼續迭代
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//洗掉堆頂
void pop()
{
assert(size() > 0);
//堆頂和堆尾交換
swap(_Con[0], _Con[_Con.size() - 1]);
//尾刪
_Con.pop_back();
//堆頂是原先堆尾的資料,除了他其他結構并未變化,可以使用向下調整
AdjustDown(0);
}
const T& top()const
{
/*return _Con.top();*/
return _Con[0];
}
size_t size()const
{
return _Con.size();
}
bool empty()const
{
return _Con.empty();
}
private:
Container _Con;
};
}
5.2 仿函式
在上述實作中,固定的是個大堆,再次實作一個小堆,就需要我們改變里面的邏輯關系,仿函式可以幫我們解決這個問題,
先來看一下仿函式
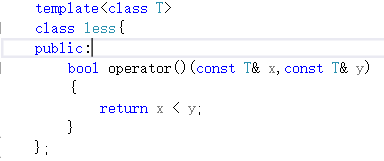

可以看出仿函式其實是一個類,里面多載了運算子(),看起來有點像函式呼叫的(),
那么怎么運用到剛才的代碼中呢,不得不佩服實作者是真的很厲害,
template<class T>
class less{
public:
bool operator()(const T& x,const T& y)
{
return x > y;
}
};
template<class T>
class greater{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
上面實作兩個類,里面都多載了(),用于比較,
template<class T, class Container = vector<T>,
class Compare=less<T> >
class priority_queue
{
.........
};
上面用一個模板,表示這是一個比較的類,這個類里面得成員方法是x>y,還是x<y,不知道,我就傳進來一個模板,根據你實體化物件時所用的引數,再來決定,怎么用起來呢?
Compare com;
//if(_Con[child]>_Con[parent])
if (com(_Con[child],_Con[parent]))
這個不確定的模板,定義一個不確定的物件,里面是不確定的關系,取決于你傳入的是less類還是greater類,生成對應的物件呼叫他們自己的成員函式,實作比較關系,不過默認給了less類,關系是x>y,體現為_Con[child]>_Con[parent]默認實作為大堆,
假如佇列里面存的是自定義型別,里面沒有多載大于小于,那么可以把仿函式宣告成友元,從而訪問他的私有資料,從而對自定義型別的基本成員進行比較,來達到比較自定義型別,至于比較哪個成員變數,視場景而定,
來看一個應用場景,比如比較一個貨物,按銷量排序,按價格排序,
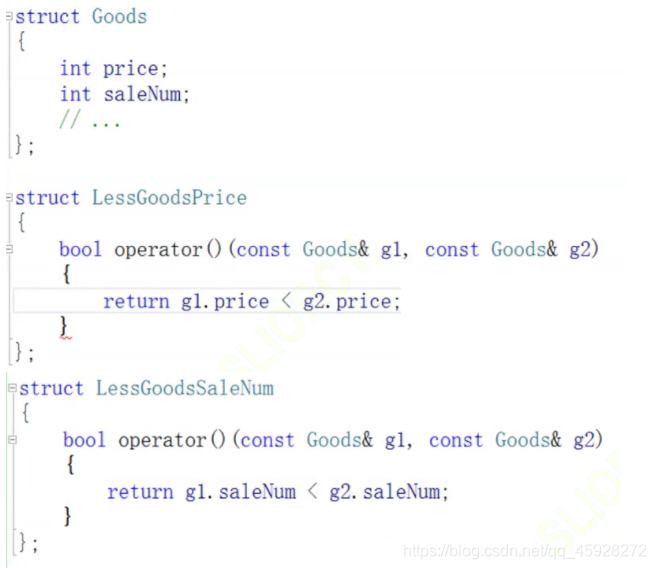
通過呼叫sort函式,里面傳入仿函式物件,進行自定義比較

也直接匿名物件,很類似于c語言中的函式指標

假如面試官問起什么是仿函式,仿函式的作用,該怎么表述呢?
仿函式就是一個類,里面的成員函式里多載了(),這個()函式表示針對物件的比較關系,假如是自定義物件(日期,貨物?),還可以根據場景,自己實作對物件的成員變數的比較,當然原本物件對于不同場景,大于,小于等具有相同意義,所以直接多載了比較運算子,直接用即可,
6. 優先級佇列最終代碼
#pragma once
#include<iostream>
#include<vector>
#include<assert.h>
#include<queue>
using namespace std;
namespace zjn{
template<class T>
class less{
public:
bool operator()(const T& x,const T& y)
{
return x > y;
}
};
template<class T>
class greater{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template<class T, class Container = vector<T>,class Compare=less<T>>
class priority_queue
{
public:
//寫了有區間的,不會默認生成了,所以要再寫一個無參的
priority_queue()
{};
//對于已有的一段區間進行構造優先級佇列,兩種方法
template<class iterator>
priority_queue(iterator first, iterator last)
:_Con(first,last)
{
for (int i = ((_Con.size() - 1-1)/2); i >=0; i--)
{
AdjustDown(i);
}
//for (int i = 1; i < _Con.size(); i++)
//{
// AdjustUp(i);
//}
}
//從下往上,和父親開始比較
void AdjustUp(int child)
{
//傳的是模板,從而實作,實體化物件時傳入不同的比較類,實作大堆小堆,
//greater com,less com
Compare com;
//找出父親
int parent = (child - 1) / 2;
//本來應該是當孩子小于等于0時,父親小于0停止,但是由于父親是除法算出來的不會小于0,那就讓孩子小于等于0時停止(孩子大于0繼續)
while (child>0)
{
//如果孩子比父親大,那么就交換
//if(_Con[child]>_Con[parent])
if (com(_Con[child],_Con[parent]))
{
swap(_Con[child], _Con[parent]);
//向上繼續迭代
child = parent;
parent = (child - 1) / 2;
}
//孩子小于父親說明插入的資料剛好滿足,退出
else
{
break;
}
}
}
void push(const T& x)
{
//堆尾插入x
_Con.push_back(x);
//傳下標,把孩子調整上去
AdjustUp(_Con.size() - 1);
}
//從上往下,父親和大的那一個孩子比較
void AdjustDown(int parent)
{
Compare com;
//默認是左孩子
size_t child = parent * 2 + 1;
while (child<_Con.size())
{
//左右孩子大的那一個和父親比較,注意當堆尾只有一個左孩子時,雖然child<size進入回圈,但是他沒有右孩子會導致越界
if (child + 1<_Con.size() && com(_Con[child + 1], _Con[child]))
{
child++;
}
if (com(_Con[child], _Con[parent]))
{
swap(_Con[child], _Con[parent]);
//向下繼續迭代
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//洗掉堆頂
void pop()
{
assert(size() > 0);
//堆頂和堆尾交換
swap(_Con[0], _Con[_Con.size() - 1]);
//尾刪
_Con.pop_back();
//堆頂是原先堆尾的資料,除了他其他結構并未變化,可以使用向下調整
AdjustDown(0);
}
const T& top()const
{
/*return _Con.top();*/
return _Con[0];
}
size_t size()const
{
return _Con.size();
}
bool empty()const
{
return _Con.empty();
}
private:
Container _Con;
};
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279670.html
標籤:其他
上一篇:軟體測驗--基礎概念
下一篇:DAY 7