python對BP神經網路實作
一、概念理解
開始之前首先了解一下BP神經網路,BP的英文是back propagationd的意思,它是一種按誤差反向傳播(簡稱誤差反傳)訓練的多層前饋網路,其演算法稱為BP演算法,
它的基本思想是梯度下降法,利用梯度搜索技術,期望使網路的實際輸出值和期望輸出值的誤差和均方差為最小,
基本BP演算法包括信號的前向傳播和誤差的反向傳播兩個程序,
正向傳播程序:輸入信號——通過隱含層——>作用于輸出節點(經過非線性變換,產生輸出信號)——>驗證實際輸出結果是否與期望輸出符合【若不符合,轉入到誤差的反向傳播】
反向傳播程序:輸出誤差——通過隱含層——>輸入層(逐層反傳,并將誤差分攤給各層單元)——>獲得誤差信號(作為調整各單元權值的依據)——>調整輸入節點與隱層節點的聯接強度和隱層節點與輸出
節點的聯接強度以及閾值——>誤差沿梯度方向下降——>經過反復學習訓練——>確定與最小誤差相對應的網路引數(權值和閾值)——>結束
二、python實作程序
1、前言
實作任務例子:
路運量主要包括公路客運量和公路貨運量兩方面,某個地區的公路運量主要與該地區的人數、機動車數量和公路面積有關,已知該地區20年(1990-2009)的公路運量相關資料如下:
(1) 人數/萬人
20.55 22.44 25.37 27.13 29.45 30.10 30.96 34.06 36.42 38.09 39.13 39.99 41.93 44.59 47.30 52.89 55.73 56.76 59.17 60.63
(2) 機動車數量/萬輛
0.6 0.75 0.85 0.9 1.05 1.35 1.45 1.6 1.7 1.85 2.15 2.2 2.25 2.35 2.5 2.6 2.7 2.85 2.95 3.1
(3) 公路面積/單位:萬平方公里
0.09 0.11 0.11 0.14 0.20 0.23 0.23 0.32 0.32 0.34 0.36 0.36 0.38 0.49 0.56 0.59 0.59 0.67 0.69 0.79
(4) 公路客運量/萬人
5126 6217 7730 9145 10460 11387 12353 15750 18304 19836 21024 19490 20433 22598 25107 33442 36836 40548 42927 43462
(5) 公路貨運量(單位:萬噸)
1237 1379 1385 1399 1663 1714 1834 4322 8132 8936 11099 11203 10524 11115 13320 16762 18673 20724 20803 21804
結果檢測:預測2010和2011年的公路客運量和公路客運量?、
準備:
(1)、激活函式
此函式為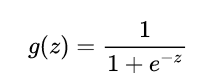 ,注意的是在機器學習中,np.exp()的引數可以是向量,當傳入是向量的時候,其回傳值是該向量內所有的元素值分別進行公式求值后構成的一個串列,
,注意的是在機器學習中,np.exp()的引數可以是向量,當傳入是向量的時候,其回傳值是該向量內所有的元素值分別進行公式求值后構成的一個串列,
1 def sigmod(x):
2 return 1 / (1 + np.exp(-x))
(2)、資料的讀取
需要了解xlrd函式的的使用
2、實作程序
(1)、資料讀取
訓練資料的讀取
1 def read_xls_file(filename): #讀取訓練資料 2 data =https://www.cnblogs.com/yangxunkai/p/ xlrd.open_workbook(filename) 3 sheet1 = data.sheet_by_index(0) 4 m = sheet1.nrows 5 n = sheet1.ncols 6 # 人口數量 機動車數量 公路面積 公路客運量 公路貨運量 7 pop,veh,roa,pas,fre=[],[],[],[],[] 8 for i in range(m): 9 row_data =https://www.cnblogs.com/yangxunkai/p/ sheet1.row_values(i) 10 if i > 0: 11 pop.append(row_data[1]) 12 veh.append(row_data[2]) 13 roa.append(row_data[3]) 14 pas.append(row_data[4]) 15 fre.append(row_data[5]) 16 dataMat = np.mat([pop,veh,roa]) 17 labels = np.mat([pas,fre]) 18 dataMat_old = dataMat 19 labels_old = labels 20 # 資料集合,標簽集合,保留資料集合,保留標簽集合 21 return dataMat,labels,dataMat_old,labels_old
測驗資料的讀取
def read_xls_testfile(filename): #讀取測驗資料 data =https://www.cnblogs.com/yangxunkai/p/ xlrd.open_workbook(filename) sheet1 = data.sheet_by_index(0) m = sheet1.nrows n = sheet1.ncols pop = [] veh = [] roa = [] for i in range(m): row_data = sheet1.row_values(i) if i > 0: pop.append(row_data[1]) veh.append(row_data[2]) roa.append(row_data[3]) dataMat = np.mat([pop,veh,roa]) return dataMat
(2)、最大最小法歸一
將原始資料線性化的方法轉換到[0 1]的范圍,歸一化公式如下:
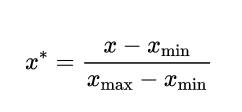
1 def Norm(dataMat,labels): 2 dataMat_minmax = np.array([dataMat.min(axis=1).T.tolist()[0],dataMat.max(axis=1).T.tolist()[0]]).transpose() 3 dataMat_Norm = ((np.array(dataMat.T)-dataMat_minmax.transpose()[0])/(dataMat_minmax.transpose()[1]-dataMat_minmax.transpose()[0])).transpose() 4 labels_minmax = np.array([labels.min(axis=1).T.tolist()[0],labels.max(axis=1).T.tolist()[0]]).transpose() 5 labels_Norm = ((np.array(labels.T).astype(float)-labels_minmax.transpose()[0])/(labels_minmax.transpose()[1]-labels_minmax.transpose()[0])).transpose() 6 return dataMat_Norm,labels_Norm,dataMat_minmax,labels_minmax
(3)、訓練模型
回傳值為4個權值以及最大可迭代次數
1 def BP(sampleinnorm, sampleoutnorm,hiddenunitnum=3): 2 # 超引數 3 maxepochs = 60000 # 最大迭代次數 4 learnrate = 0.030 # 學習率 5 errorfinal = 0.65*10**(-3) # 最終迭代誤差 6 indim = 3 # 輸入特征維度3 7 outdim = 2 # 輸出特征唯獨2 8 # 隱藏層默認為3個節點,1層 9 n,m = shape(sampleinnorm) 10 w1 = 0.5*np.random.rand(hiddenunitnum,indim)-0.1 #8*3維 11 b1 = 0.5*np.random.rand(hiddenunitnum,1)-0.1 #8*1維 12 w2 = 0.5*np.random.rand(outdim,hiddenunitnum)-0.1 #2*8維 13 b2 = 0.5*np.random.rand(outdim,1)-0.1 #2*1維 14 15 errhistory = [] 16 17 for i in range(maxepochs): 18 # 激活隱藏輸出層 19 hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose() 20 # 計算輸出層輸出 21 networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose() 22 # 計算誤差 23 err = sampleoutnorm - networkout 24 # 計算代價函式(cost function)sum對陣列里面的所有資料求和,變為一個實數 25 sse = sum(sum(err**2))/m 26 errhistory.append(sse) 27 if sse < errorfinal: #迭代誤差 28 break 29 # 計算delta 30 delta2 = err 31 delta1 = np.dot(w2.transpose(),delta2)*hiddenout*(1-hiddenout) 32 # 計算偏置 33 dw2 = np.dot(delta2,hiddenout.transpose()) 34 db2 = 1 / 20 * np.sum(delta2, axis=1, keepdims=True) 35 36 dw1 = np.dot(delta1,sampleinnorm.transpose()) 37 db1 = 1/20*np.sum(delta1,axis=1,keepdims=True) 38 39 # 更新權值 40 w2 += learnrate*dw2 41 b2 += learnrate*db2 42 w1 += learnrate*dw1 43 b1 += learnrate*db1 44 45 return errhistory,b1,b2,w1,w2,maxepochs
(7)、曲線顯示
顯示內容為兩個內容:1、神經網路曲線圖(包括客運量預測輸出、客運量真實輸出、貨運量預測輸出、貨運量真實輸出)2、誤差曲線圖
1 def show(sampleinnorm,sampleoutminmax,sampleout,errhistory,maxepochs): # 圖形顯示 2 matplotlib.rcParams['font.sans-serif']=['SimHei'] # 防止中文亂碼 3 hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose() 4 networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose() 5 diff = sampleoutminmax[:,1]-sampleoutminmax[:,0] 6 networkout2 = networkout 7 networkout2[0] = networkout2[0]*diff[0]+sampleoutminmax[0][0] 8 networkout2[1] = networkout2[1]*diff[1]+sampleoutminmax[1][0] 9 sampleout = np.array(sampleout) 10 11 fig,axes = plt.subplots(nrows=2,ncols=1,figsize=(12,10)) 12 line1, = axes[0].plot(networkout2[0],'k',markeredgecolor='b',marker = 'o',markersize=7) 13 line2, = axes[0].plot(sampleout[0],'r',markeredgecolor='g',marker = u'$\star$',markersize=7) 14 line3, = axes[0].plot(networkout2[1],'g',markeredgecolor='g',marker = 'o',markersize=7) 15 line4, = axes[0].plot(sampleout[1],'y',markeredgecolor='b',marker = u'$\star$',markersize=7) 16 axes[0].legend((line1,line2,line3,line4),(u'客運量預測輸出',u'客運量真實輸出',u'貨運量預測輸出',u'貨運量真實輸出'),loc = 'upper left') 17 axes[0].set_ylabel(u'公路客運量及貨運量') 18 xticks = range(0,22,1) 19 xtickslabel = range(1990,2012,1) 20 axes[0].set_xticks(xticks) 21 axes[0].set_xticklabels(xtickslabel) 22 axes[0].set_xlabel(u'年份') 23 axes[0].set_title(u'BP神經網路') 24 25 errhistory10 = np.log10(errhistory) 26 minerr = min(errhistory10) 27 plt.plot(errhistory10) 28 axes[1]=plt.gca() 29 axes[1].set_yticks([-2,-1,0,1,2,minerr]) 30 axes[1].set_yticklabels([u'$10^{-2}$',u'$10^{-1}$',u'$1$',u'$10^{1}$',u'$10^{2}$',str(('%.4f'%np.power(10,minerr)))]) 31 axes[1].set_xlabel(u'訓練次數') 32 axes[1].set_ylabel(u'誤差') 33 axes[1].set_title(u'誤差曲線')34 plt.show() 35 plt.close() 36 return diff, sampleoutminmax
(8)、主函式
1 if __name__ == "__main__": 2 dataMat,labels,dataMat_old,labels_old = read_xls_file('訓練.xls') 3 dataMat_Norm,labels_Norm, dataMat_minmax, labels_minmax = Norm(dataMat,labels) 4 err, b1, b2, w1, w2,maxepochs = BP(dataMat_Norm,labels_Norm,6) 5 dataMat_test = read_xls_testfile('測驗.xls') 6 diff, sampleoutminmax = show(dataMat_Norm,labels_minmax,labels,err,maxepochs) 7 pre(dataMat_test,dataMat_minmax,diff, sampleoutminmax ,w1,b1,w2,b2)
(9)、拓展
以上采用的是資料讀取,也可以直接定義,回傳的值是里面的資料以及label就可以了,可以自己實驗一下,
1 # 人數(單位:萬人) 2 population = [20.55, 22.44, 25.37, 27.13, 29.45, 30.10, 30.96, 34.06, 36.42, 38.09, 39.13, 39.99, 41.93, 44.59, 47.30, 3 52.89, 55.73, 56.76, 59.17, 60.63] 4 # 機動車數(單位:萬輛) 5 vehicle = [0.6, 0.75, 0.85, 0.9, 1.05, 1.35, 1.45, 1.6, 1.7, 1.85, 2.15, 2.2, 2.25, 2.35, 2.5, 2.6, 2.7, 2.85, 2.95, 6 3.1] 7 # 公路面積(單位:萬平方公里) 8 roadarea = [0.09, 0.11, 0.11, 0.14, 0.20, 0.23, 0.23, 0.32, 0.32, 0.34, 0.36, 0.36, 0.38, 0.49, 0.56, 0.59, 0.59, 0.67, 9 0.69, 0.79] 10 # 公路客運量(單位:萬人) 11 passengertraffic = [5126, 6217, 7730, 9145, 10460, 11387, 12353, 15750, 18304, 19836, 21024, 19490, 20433, 22598, 25107, 12 33442, 36836, 40548, 42927, 43462] 13 # 公路貨運量(單位:萬噸) 14 freighttraffic = [1237, 1379, 1385, 1399, 1663, 1714, 1834, 4322, 8132, 8936, 11099, 11203, 10524, 11115, 13320, 16762, 15 18673, 20724, 20803, 21804] 16 17 # 資料轉為矩陣 18 samplein = np.mat([population, vehicle, roadarea]) 19 sampleinminmax = np.array([samplein.min(axis=1).T.tolist()[0], samplein.max(axis=1).T.tolist()[0]]).transpose() # 3*2 20 sampleout = np.mat([passengertraffic, freighttraffic]) 21 sampleoutminmax = np.array( 22 [sampleout.min(axis=1).T.tolist()[0], sampleout.max(axis=1).T.tolist()[0]]).transpose() # 2*2
三、總結
1、整體代碼
注意:記得替換掉資料集,該程式只適用于資料集保存在表格里,如果其他格式,請參考python的其他檔案形式的讀取
1 from numpy import * 2 from mpl_toolkits.mplot3d import Axes3D 3 import matplotlib.pyplot as plt 4 import numpy as np 5 from pylab import * 6 import xlrd 7 8 # 資料讀取 9 def read_xls_file(filename): #讀取訓練資料 10 data =https://www.cnblogs.com/yangxunkai/p/ xlrd.open_workbook(filename) 11 sheet1 = data.sheet_by_index(0) 12 m = sheet1.nrows 13 n = sheet1.ncols 14 # 人口數量 機動車數量 公路面積 公路客運量 公路貨運量 15 pop,veh,roa,pas,fre=[],[],[],[],[] 16 for i in range(m): 17 row_data =https://www.cnblogs.com/yangxunkai/p/ sheet1.row_values(i) 18 if i > 0: 19 pop.append(row_data[1]) 20 veh.append(row_data[2]) 21 roa.append(row_data[3]) 22 pas.append(row_data[4]) 23 fre.append(row_data[5]) 24 dataMat = np.mat([pop,veh,roa]) 25 labels = np.mat([pas,fre]) 26 dataMat_old = dataMat 27 labels_old = labels 28 # 資料集合,標簽集合,保留資料集合,保留標簽集合 29 return dataMat,labels,dataMat_old,labels_old 30 31 # 讀取測驗集 32 def read_xls_testfile(filename): #讀取測驗資料 33 data =https://www.cnblogs.com/yangxunkai/p/ xlrd.open_workbook(filename) 34 sheet1 = data.sheet_by_index(0) 35 m = sheet1.nrows 36 n = sheet1.ncols 37 pop = [] 38 veh = [] 39 roa = [] 40 for i in range(m): 41 row_data =https://www.cnblogs.com/yangxunkai/p/ sheet1.row_values(i) 42 if i > 0: 43 pop.append(row_data[1]) 44 veh.append(row_data[2]) 45 roa.append(row_data[3]) 46 47 dataMat = np.mat([pop,veh,roa]) 48 return dataMat 49 50 # 由于資料數量級相差太大,我們要先對資料進行歸一化處理Min-Max歸一化 51 def Norm(dataMat,labels): 52 dataMat_minmax = np.array([dataMat.min(axis=1).T.tolist()[0],dataMat.max(axis=1).T.tolist()[0]]).transpose() 53 dataMat_Norm = ((np.array(dataMat.T)-dataMat_minmax.transpose()[0])/(dataMat_minmax.transpose()[1]-dataMat_minmax.transpose()[0])).transpose() 54 labels_minmax = np.array([labels.min(axis=1).T.tolist()[0],labels.max(axis=1).T.tolist()[0]]).transpose() 55 labels_Norm = ((np.array(labels.T).astype(float)-labels_minmax.transpose()[0])/(labels_minmax.transpose()[1]-labels_minmax.transpose()[0])).transpose() 56 return dataMat_Norm,labels_Norm,dataMat_minmax,labels_minmax 57 58 # 激活函式 59 def sigmod(x): 60 return 1/(1+np.exp(-x)) 61 62 # Back Propagation 63 def BP(sampleinnorm, sampleoutnorm,hiddenunitnum=3): 64 # 超引數 65 maxepochs = 60000 # 最大迭代次數 66 learnrate = 0.030 # 學習率 67 errorfinal = 0.65*10**(-3) # 最終迭代誤差 68 indim = 3 # 輸入特征維度3 69 outdim = 2 # 輸出特征唯獨2 70 # 隱藏層默認為3個節點,1層 71 n,m = shape(sampleinnorm) 72 w1 = 0.5*np.random.rand(hiddenunitnum,indim)-0.1 #8*3維 73 b1 = 0.5*np.random.rand(hiddenunitnum,1)-0.1 #8*1維 74 w2 = 0.5*np.random.rand(outdim,hiddenunitnum)-0.1 #2*8維 75 b2 = 0.5*np.random.rand(outdim,1)-0.1 #2*1維 76 77 errhistory = [] 78 79 for i in range(maxepochs): 80 # 激活隱藏輸出層 81 hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose() 82 # 計算輸出層輸出 83 networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose() 84 # 計算誤差 85 err = sampleoutnorm - networkout 86 # 計算代價函式(cost function)sum對陣列里面的所有資料求和,變為一個實數 87 sse = sum(sum(err**2))/m 88 errhistory.append(sse) 89 if sse < errorfinal: #迭代誤差 90 break 91 # 計算delta 92 delta2 = err 93 delta1 = np.dot(w2.transpose(),delta2)*hiddenout*(1-hiddenout) 94 # 計算偏置 95 dw2 = np.dot(delta2,hiddenout.transpose()) 96 db2 = 1 / 20 * np.sum(delta2, axis=1, keepdims=True) 97 98 dw1 = np.dot(delta1,sampleinnorm.transpose()) 99 db1 = 1/20*np.sum(delta1,axis=1,keepdims=True) 100 101 # 更新權值 102 w2 += learnrate*dw2 103 b2 += learnrate*db2 104 w1 += learnrate*dw1 105 b1 += learnrate*db1 106 107 return errhistory,b1,b2,w1,w2,maxepochs 108 109 110 def show(sampleinnorm,sampleoutminmax,sampleout,errhistory,maxepochs): # 圖形顯示 111 matplotlib.rcParams['font.sans-serif']=['SimHei'] # 防止中文亂碼 112 hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose() 113 networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose() 114 diff = sampleoutminmax[:,1]-sampleoutminmax[:,0] 115 networkout2 = networkout 116 networkout2[0] = networkout2[0]*diff[0]+sampleoutminmax[0][0] 117 networkout2[1] = networkout2[1]*diff[1]+sampleoutminmax[1][0] 118 sampleout = np.array(sampleout) 119 120 fig,axes = plt.subplots(nrows=2,ncols=1,figsize=(12,10)) 121 line1, = axes[0].plot(networkout2[0],'k',markeredgecolor='b',marker = 'o',markersize=7) 122 line2, = axes[0].plot(sampleout[0],'r',markeredgecolor='g',marker = u'$\star$',markersize=7) 123 line3, = axes[0].plot(networkout2[1],'g',markeredgecolor='g',marker = 'o',markersize=7) 124 line4, = axes[0].plot(sampleout[1],'y',markeredgecolor='b',marker = u'$\star$',markersize=7) 125 axes[0].legend((line1,line2,line3,line4),(u'客運量預測輸出',u'客運量真實輸出',u'貨運量預測輸出',u'貨運量真實輸出'),loc = 'upper left') 126 axes[0].set_ylabel(u'公路客運量及貨運量') 127 xticks = range(0,22,1) 128 xtickslabel = range(1990,2012,1) 129 axes[0].set_xticks(xticks) 130 axes[0].set_xticklabels(xtickslabel) 131 axes[0].set_xlabel(u'年份') 132 axes[0].set_title(u'BP神經網路') 133 134 errhistory10 = np.log10(errhistory) 135 minerr = min(errhistory10) 136 plt.plot(errhistory10) 137 axes[1]=plt.gca() 138 axes[1].set_yticks([-2,-1,0,1,2,minerr]) 139 axes[1].set_yticklabels([u'$10^{-2}$',u'$10^{-1}$',u'$1$',u'$10^{1}$',u'$10^{2}$',str(('%.4f'%np.power(10,minerr)))]) 140 axes[1].set_xlabel(u'訓練次數') 141 axes[1].set_ylabel(u'誤差') 142 axes[1].set_title(u'誤差曲線') 143 plt.show() 144 145 plt.close() 146 147 return diff, sampleoutminmax 148 149 def pre(dataMat,dataMat_minmax,diff,sampleoutminmax,w1,b1,w2,b2): #數值預測 150 # 歸一化資料 151 dataMat_test = ((np.array(dataMat.T)-dataMat_minmax.transpose()[0])/(dataMat_minmax.transpose()[1]-dataMat_minmax.transpose()[0])).transpose() 152 # 然后計算兩層的輸出結果 153 # 隱藏層 154 hiddenout = sigmod((np.dot(w1,dataMat_test).transpose()+b1.transpose())).transpose() 155 # 輸出層 156 networkout1 = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose() 157 networkout = networkout1 158 # 計算結果 159 networkout[0] = networkout[0]*diff[0] + sampleoutminmax[0][0] 160 networkout[1] = networkout[1]*diff[1] + sampleoutminmax[1][0] 161 162 print("2010年預測的公路客運量為:", int(networkout[0][0]),"(萬人)") 163 print("2010年預測的公路貨運量為:", int(networkout[1][0]),"(萬噸)") 164 print("2011年預測的公路客運量為:", int(networkout[0][1]),"(萬人)") 165 print("2011年預測的公路貨運量為:", int(networkout[1][1]),"(萬噸)") 166 167 if __name__ == "__main__": 168 dataMat,labels,dataMat_old,labels_old = read_xls_file('訓練.xls') 169 dataMat_Norm,labels_Norm, dataMat_minmax, labels_minmax = Norm(dataMat,labels) 170 err, b1, b2, w1, w2,maxepochs = BP(dataMat_Norm,labels_Norm,6) 171 dataMat_test = read_xls_testfile('測驗.xls') 172 diff, sampleoutminmax = show(dataMat_Norm,labels_minmax,labels,err,maxepochs) 173 pre(dataMat_test,dataMat_minmax,diff, sampleoutminmax ,w1,b1,w2,b2)
2、結果展示
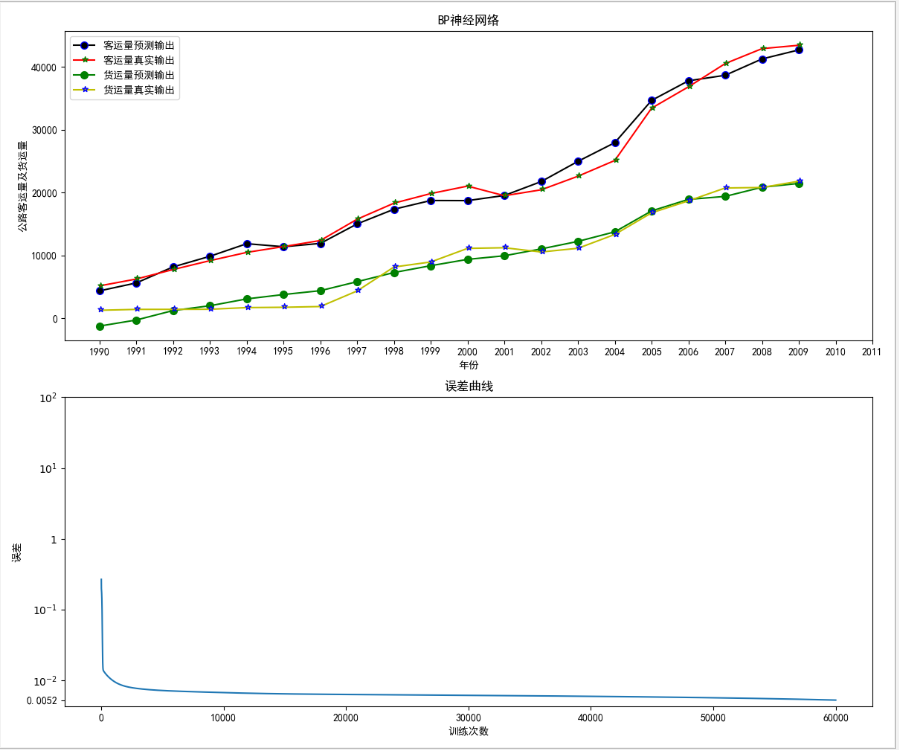
2010年預測的公路客運量為: 53980 (萬人)
2010年預測的公路貨運量為: 28513 (萬噸)
2011年預測的公路客運量為: 55716 (萬人)
2011年預測的公路貨運量為: 29521 (萬噸)
注:以上均為自己學習使用,希望可以幫助到你,感謝支持!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279792.html
標籤:其他
上一篇:0502-計算圖