Hadoop集群部署及簡單測驗
- 部署模式
- 本地模式
- 偽分布模式
- 完全分布式
- 節點規劃
- HDFS規劃
- YARN規劃
- 實作部署
- 解壓安裝
- 修改配置
- 修改環境變陣列態檔~env.sh
- 修改屬性組態檔~-site.xml
- 修改core-site.xml
- 修改hdfs-site.xml
- 修改mapred-site.xml
- 修改yarn-site.xml
- 修改從節點組態檔
- 節點分發
- 3個節點的環境變數配置
- 格式化HDFS
- 出錯后
- 啟動測驗
- 啟動Hadoop集群
- 啟動NameNode
- 第一臺
- 三臺集群
- 訪問HDFS的網頁界面
- 啟動ResourceManager~node3
- 啟動NodeManager
- YARN的Web監控
- ResourceManager啟動
- HDFS測驗
- 需求
- 實作
- MapReduce和YARN測驗
- MapReduce程式
- YARN運行環境
- 基準測驗
- 寫入基準
- 讀取基準
- 洗掉測驗檔案
搭建虛擬機集群
配置ZooKeeper
部署模式
本地模式
只有MapReduce,將代碼放在一個獨立的JVM行程中運行,一般用作測驗代碼的邏輯,
偽分布模式
只有1臺機器的分布式,貌似只會用于機器性能極差的艱苦學習環境的測驗,
完全分布式
多臺機器構成的分布式,這才是生產環境中實際作業的分布式環境,
節點規劃
ZooKeeper中誰作Leader,誰作Follower并不由人決定,且ZooKeeper是公平節點架構,一般不會窮到只用1臺ZooKeeper服務器,也不會豪到用7臺以上的ZooKeeper服務器,那么3臺/5臺組成的ZooKeeper集群,其實誰作Leader是無所謂的,并不需要關心,
HDFS中有2種節點:NameNode和DataNode,
YARN中有2種節點:ResourceManager和NodeManager,
分布式存盤與分布式計算,Worker節點的可替代性很強,所有機器都做Worker節點也無妨,但是Manger節點具有決策作用,筆者手頭只有3個虛擬機搭建的機器,顯然都得同時是2種Worker節點,但是不能允許同一個虛擬機同時是2種Manager節點和2種Worker節點(單節點負載太高容易卡死,負載過于不平衡也就失去了分布式的意義,不管是從性能講,還是從宕機的影響講,這種做法都是不合理的),
安裝具有主從架構的工具,需要進行節點規劃,
HDFS規劃
HDFS事實上有3種節點,NameNode會將元資料存盤到記憶體,并在SecondaryNameNode協助下獲取快照到硬碟,故NameNode很消耗記憶體,
參考:SecondaryNameNode
千萬不要被字面內容誤導!!!
SecondaryNameNode可不是作為備份的NameNode,這就像可鍛鑄鐵(malleable cast iron)實際不可以鍛造(會崩碎),高速鋼(high speed steel,只能用于低速切削)實際上并不能承受高速切削(3w rpm,這時候一般用粉末冶金/帶涂層的硬質合金,或干脆使用PCD刀具)時的高溫,,,
| 行程/節點 | node1 | node2 | node3 |
|---|---|---|---|
| NameNode | √ | ||
| DataNode | √ | √ | √ |
| SecondaryNameNode | √ |
YARN規劃
node1作為NameNode使用后相對負載已經變高,為了均衡負載,ResourceManager應該放在node2或者node3,筆者放在node3,
| 行程/節點 | node1 | node2 | node3 |
|---|---|---|---|
| ResourceManager | √ | ||
| NodeManager | √ | √ | √ |
實作部署
解壓安裝
將編譯好的Hadoop的安裝包上傳到node1的/export/software目錄下,并解壓到/export/server:
cd /export/software
rz
tar -zxvf hadoop-2.7.5.tar.gz -C /export/server/
切換到Hadoop解壓目錄:
cd /export/server/hadoop-2.7.5/
可以看到有很多檔案:
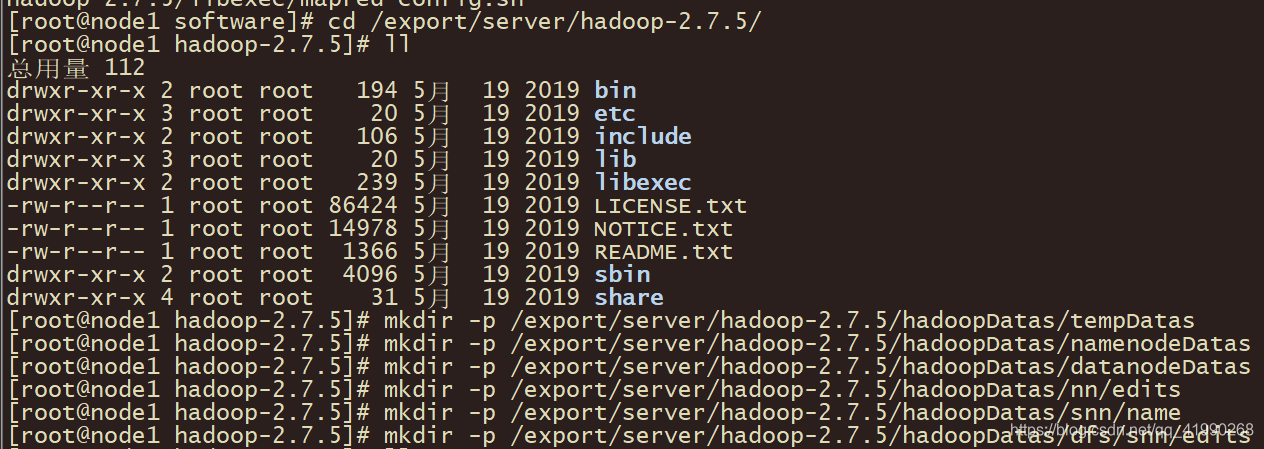
bin:客戶端的命令腳本,
sbin:服務端管理的命令腳本,如果沒有sbin,這些管理腳本也會放在bin目錄中,
etc:組態檔目錄,
lib:依賴庫,Hadoop的依賴庫不在這個目錄中,
share:Hadoop實際的依賴包的存放位置,
logs:服務端運行的日志,
修改配置
在node1創建配置時需要的目錄:
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
切換目錄,準備修改組態檔:
cd /export/server/hadoop-2.7.5/etc/hadoop/
可以看到有很多組態檔:
開始修改,,,
修改環境變陣列態檔~env.sh
這些env.sh結尾的檔案都是用來配置環境變數的,都要配置JAVA_HOME環境變數,
echo $JAVA_HOME
查看到之前配置的JAVA_HOME環境變數的位置:/export/server/jdk1.8.0_241,
vim hadoop-env.sh
修改25行的內容為上述路徑:


記得:wq保存,
vim mapred-env.sh
在這里添加內容或取消注釋后修改均可:

export JAVA_HOME=/export/server/jdk1.8.0_241

按:wq保存,
vim yarn-env.sh

按o在下方插入一行,同樣添加內容或取消注釋后修改均可:
export JAVA_HOME=/export/server/jdk1.8.0_241

按:x保存,
修改屬性組態檔~-site.xml
這一步非常麻煩,,,
以site.xml結尾的檔案都是用戶自定義配置(個性化設定)的組態檔,Hadoop有default.xml結尾的默認組態檔,啟動時會先加載這些默認組態檔,加載所有的默認配置(在Hadoop自帶的jar包中),再加載所有的用戶自定義組態檔,默認配置會被用戶自定義配置取代,
要修改的內容很多,繼續使用VIM修改會顯得很愚蠢,,,筆者使用Notepad++來修改,,,稍微容易些,
先切換UTF-8編碼:
修改core-site.xml
這是Hadoop全域屬性組態檔,可以進行IO、權限等的配置,
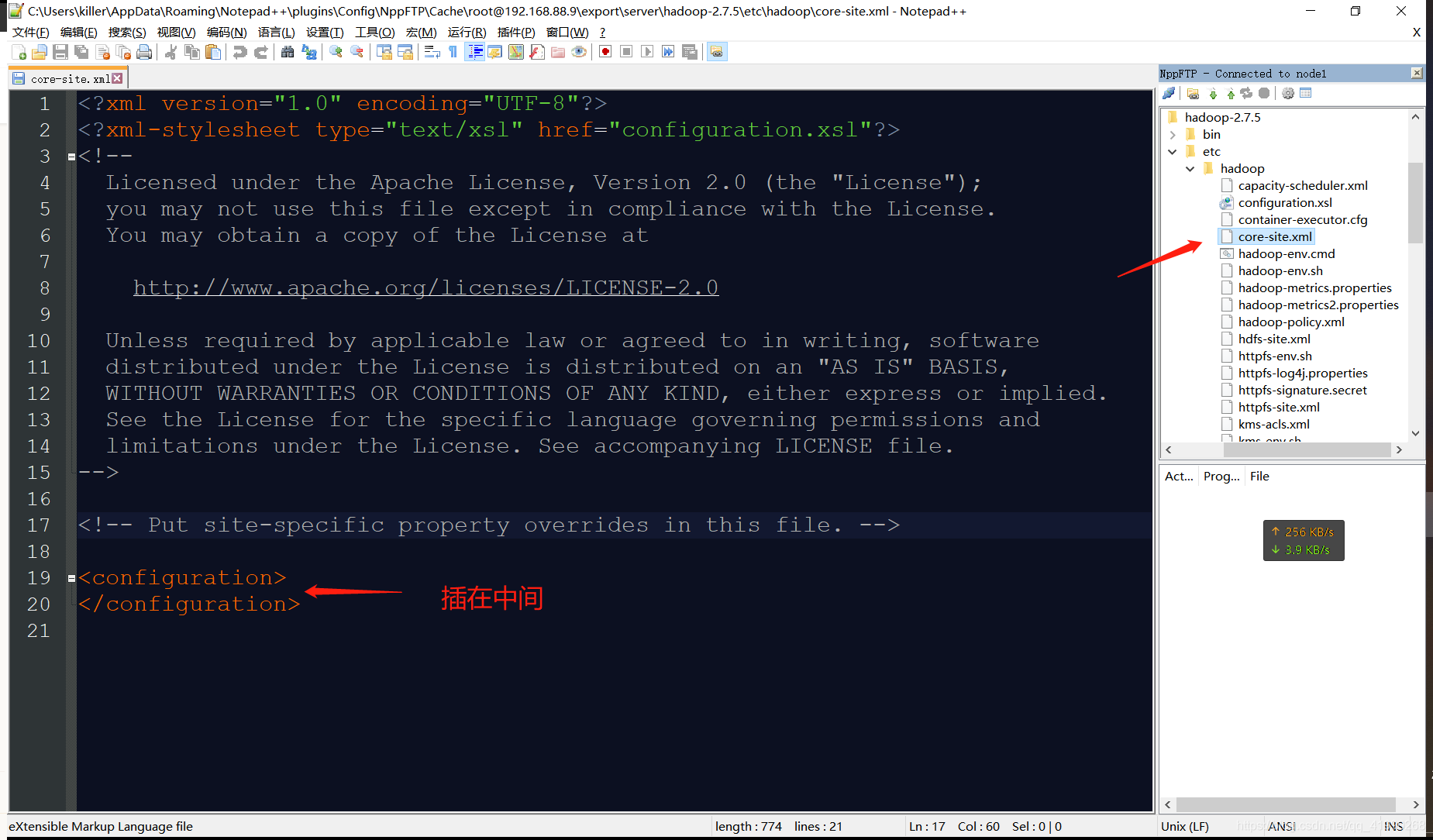
插入:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
按ctrl+s保存,最好到命令列cat core-site.xml看看有木有保存成功,
fs.defaultFS:指定了HDFS入口的地址,用于讀寫請求,代表了NameNode的機器的地址,8020是讀寫內部請求埠,走RPC協議,
hadoop.tmp.dir:Hadoop的臨時資料存盤目錄,
fs.trash.interval:回收站的自動清理時間,如果為0,表示不開啟回收站,
修改hdfs-site.xml
這是HDFS組態檔,
相同的方式插入內容,不再贅述:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/server/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/server/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/server/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
保存,
dfs.namenode.secondary.http-address:SecondaryNameNode行程的地址和HTTP協議埠,
dfs.namenode.http-address:NameNode行程開放的HTTP協議埠,
50070:NameNode開放的HTTP協議埠,用于網頁訪問,
修改mapred-site.xml
這是MapReduce的組態檔,但是路徑下只有mapred-site.xml.template模板,先改名:
cd /export/server/hadoop-2.7.5/etc/hadoop
mv mapred-site.xml.template mapred-site.xml
再插入:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node2:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node2:19888</value>
</property>
mapreduce.framework.name:將MapReduce程式運行在YARN上,
修改yarn-site.xml
這貨是YARN的組態檔,
插入:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node3</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
yarn.resourcemanager.hostname:指定ResourceManager所在的機器,
yarn.nodemanager.aux-services:YARN上運行的程式的型別,
修改從節點組態檔
slaves決定了DataNode和NodeManager啟動在哪臺機器,默認為localhost(也就是127.0.0.1,顯然不是集群),修改內容為:
node1
node2
node3
節點分發
都切換目錄:
cd /export/server/
使用ll -ah查看3個節點的目錄內的內容正常(之前有相關路徑或檔案需要想辦法干掉,防止出問題),
scp -r hadoop-2.7.5 node2:$PWD
scp -r hadoop-2.7.5 node3:$PWD
使用node1分發給node2和node3,
再次使用ll -ah查看3個節點的目錄內的內容,確保成功分發,
3個節點的環境變數配置
3個節點同時:
vim /etc/profile
會看到:
先不慌,使用↓按鍵一直往下翻:
末尾按o添加:
#HADOOP_HOME
export HADOOP_HOME=/export/server/hadoop-2.7.5
export PATH=:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
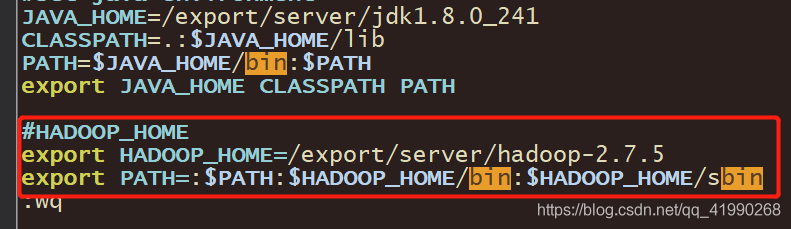
保存,
source /etc/profile
同時在命令列執行,3個節點都重置環境變數,
格式化HDFS
只有集群搭建好之后首次啟動才需要格式化HDFS,
在node1使用hdfs namenode -format執行格式化命令:
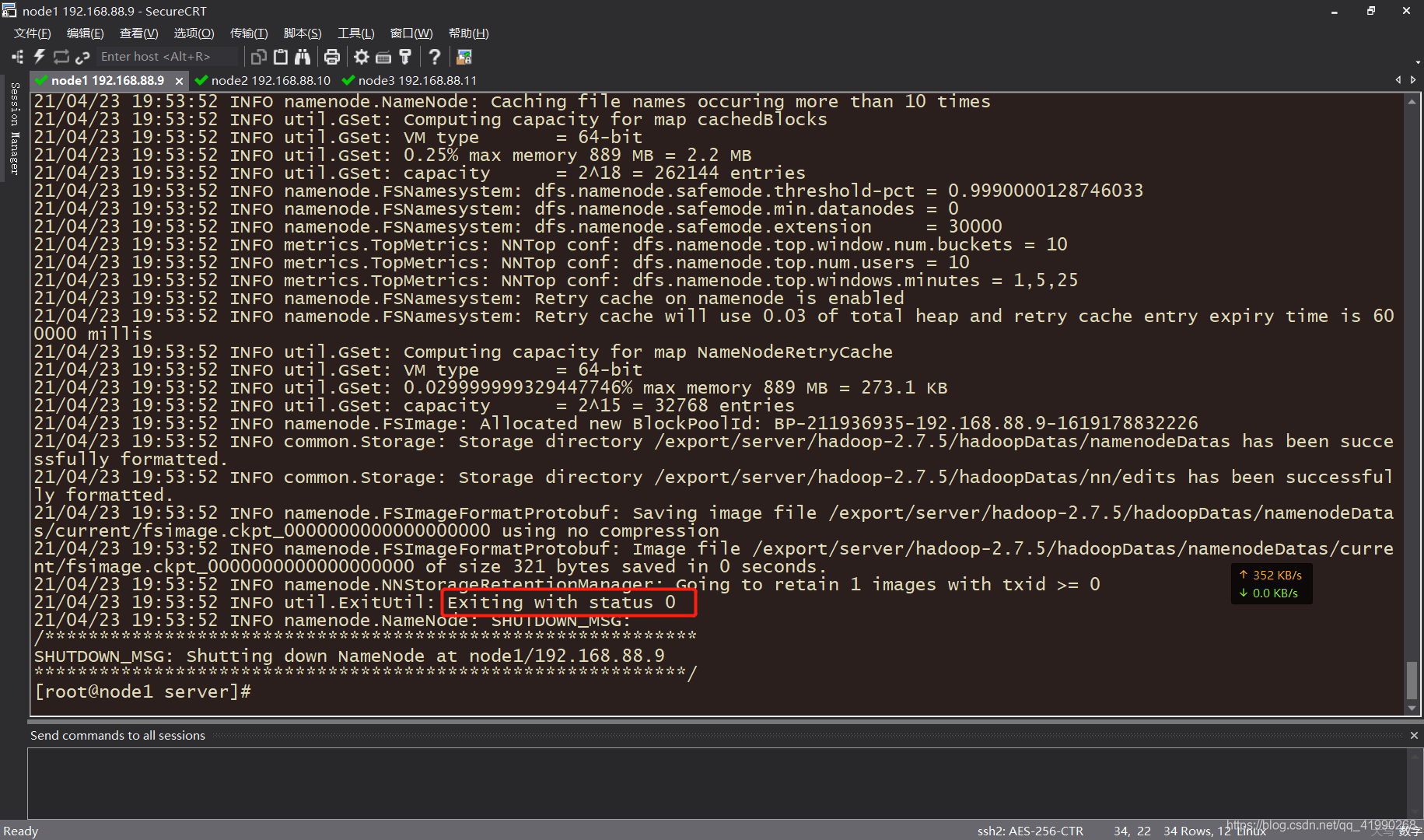
出現這個狀態0的正常退出,說明格式化成功,
出錯后
如果報錯,大概率是組態檔寫錯了,但是不能直接重新格式化(元資料已經存盤了一些資訊,重新格式化會導致映射關系等出錯),正確的重新格式化順序:
先洗掉原先的資料檔案夾:
rm -rf hadoopDatas/
再重新創建所有目錄:
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/server/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
最后重新格式化:
hdfs namenode -format
啟動測驗
啟動Hadoop集群
啟動NameNode
第一臺
在node1的命令列:
hadoop-daemon.sh start namenode
三臺集群
集群的3個節點都需要:
hadoop-daemon.sh start datanode
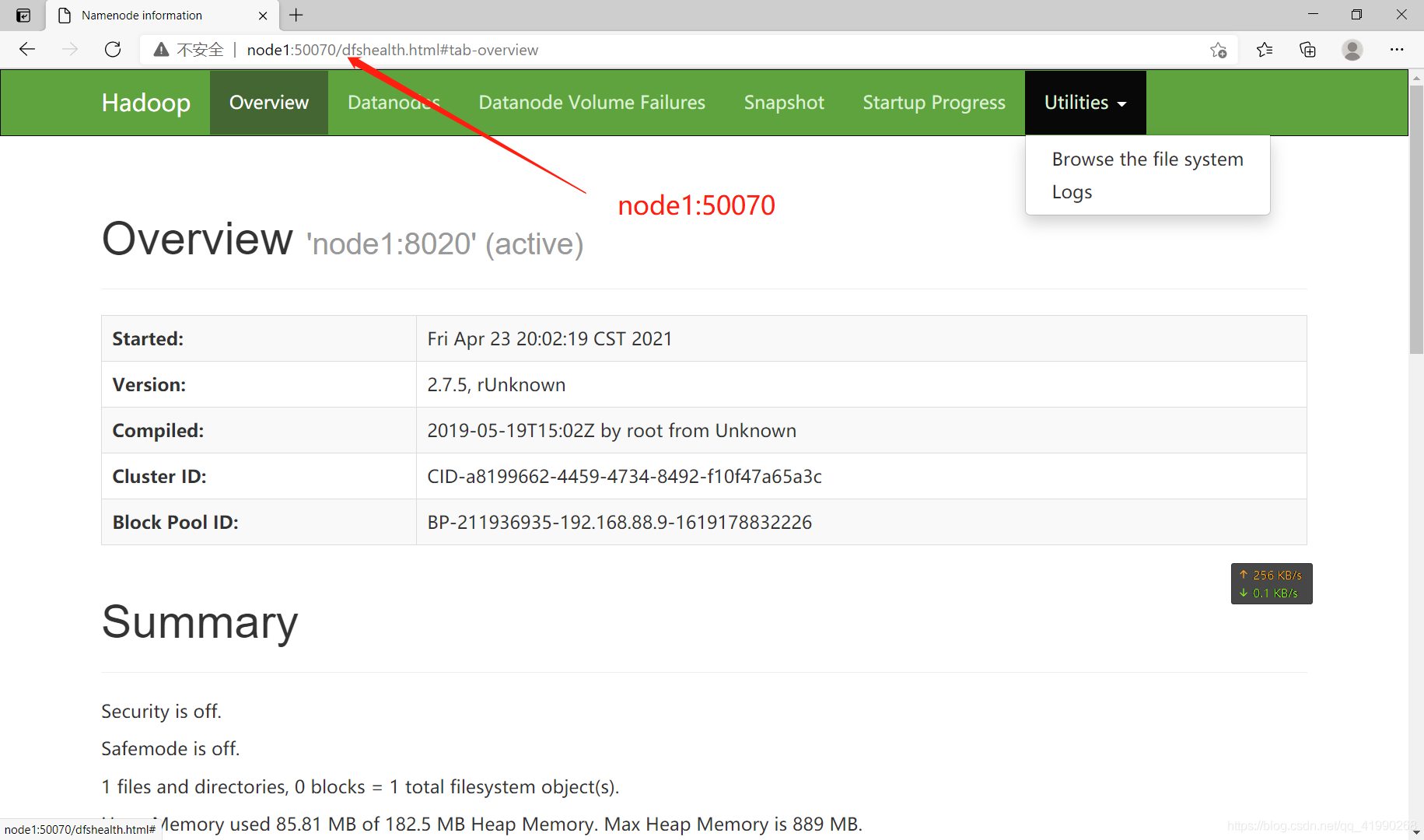
訪問HDFS的網頁界面
瀏覽器輸入:node1:50070
成功訪問:
啟動ResourceManager~node3
在node3的命令列:
yarn-daemon.sh start resourcemanager
啟動NodeManager
3個節點都需要:
yarn-daemon.sh start nodemanager
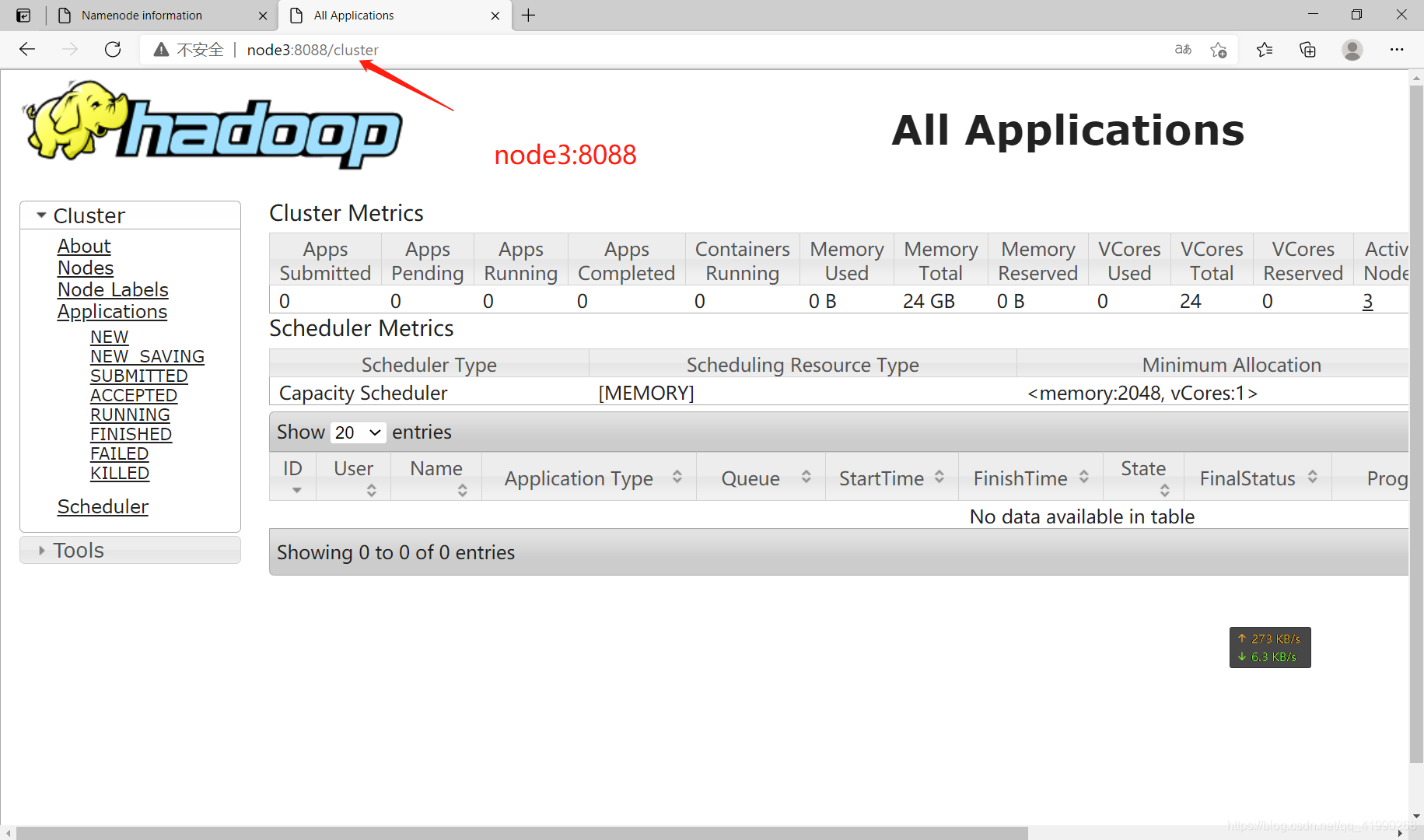
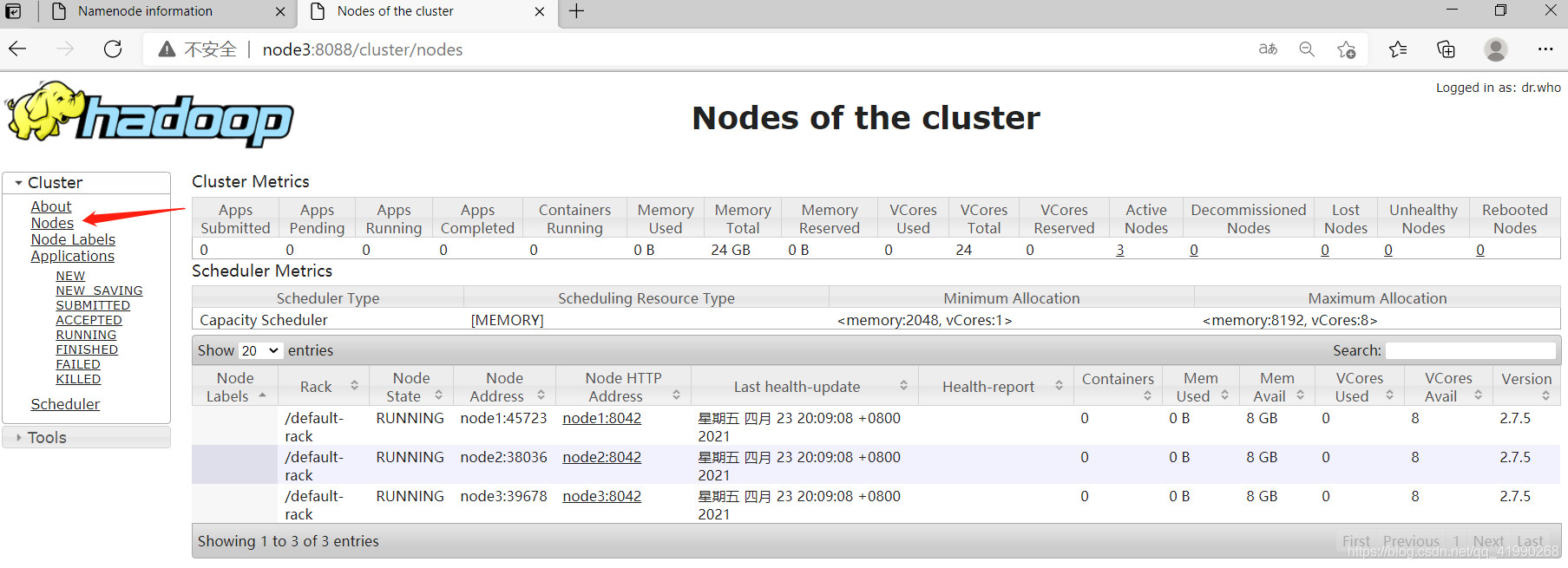
YARN的Web監控
ResourceManager啟動
瀏覽器訪問:node3:8088
8032:內部任務提交埠,走的RPC協議,
8088:網頁服務埠,走的HTTP協議
成功訪問:
HDFS測驗
需求
實作WordCount詞頻統計,統計檔案中每個單詞出現的次數,
實作
上傳檔案到node1:
cd /export/data/
rz上傳檔案,
創建HDFS目錄:
hdfs dfs -mkdir -p /wordcount/input
將存盤在node1的Linux系統存盤的檔案上傳到HDFS中:
hdfs dfs -put /export/data/wc.txt /wordcount/input/
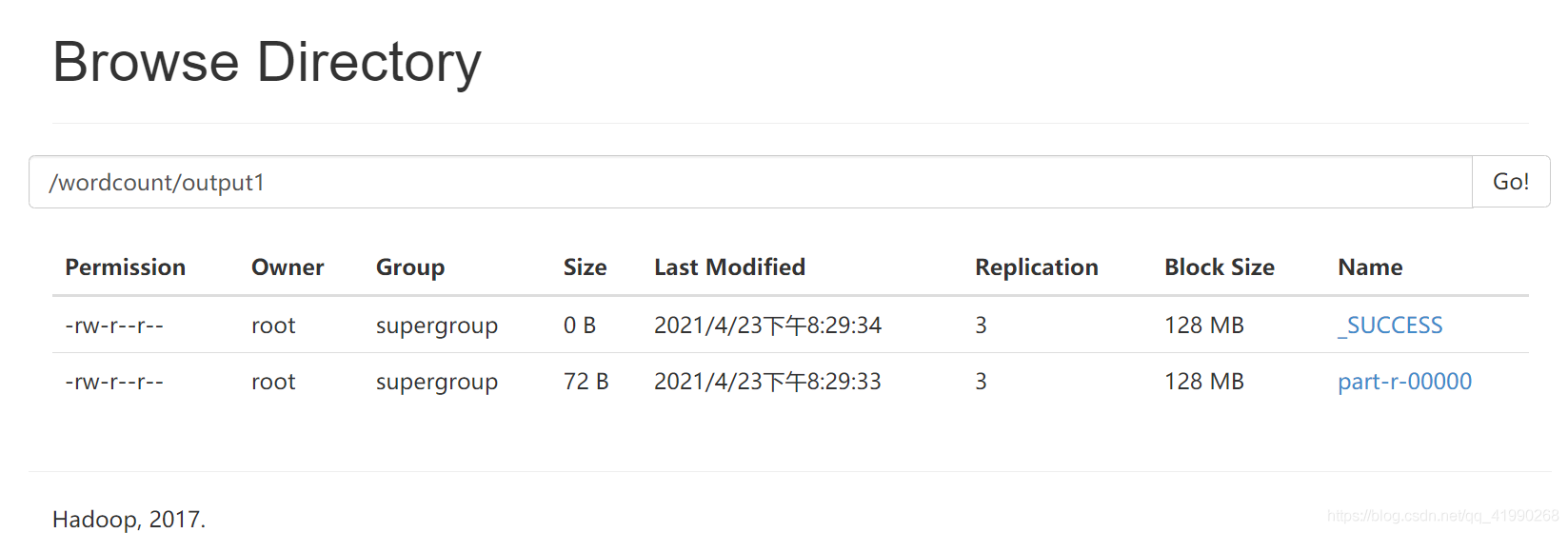
查看是否成功:
hdfs dfs -ls /wordcount/input

可以看出上傳成功,
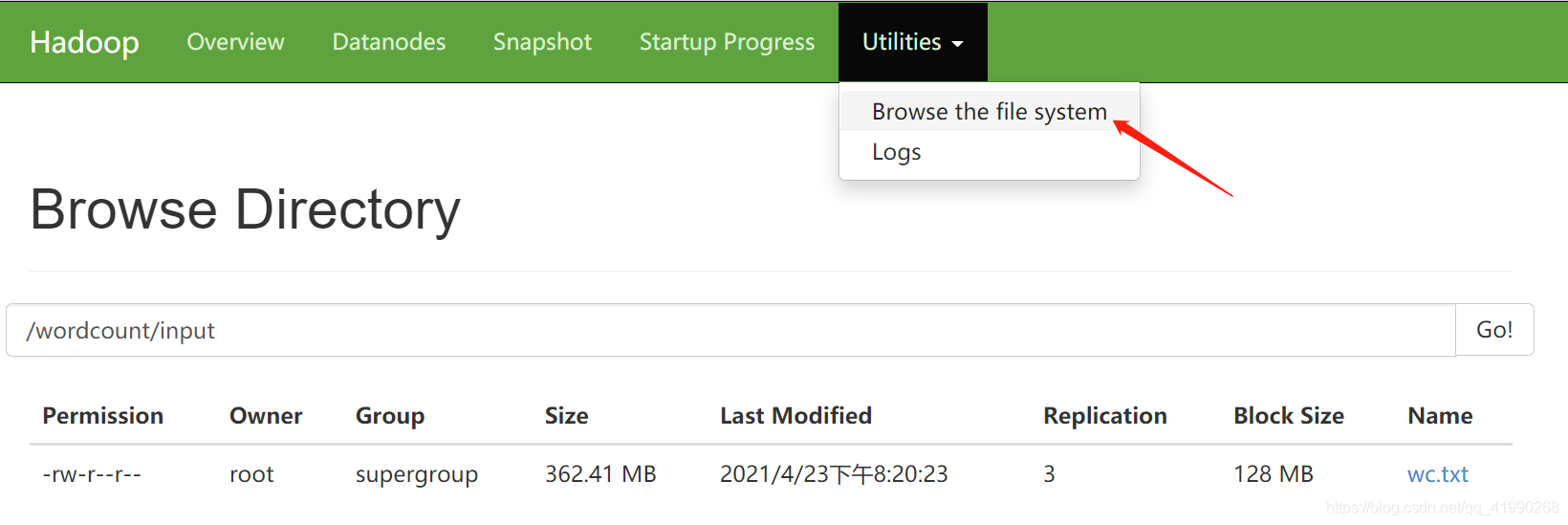
這里也可以看到上傳成功,
MapReduce和YARN測驗
MapReduce程式
Hadoop中自帶了這個MapReduce程式:
/export/server/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
YARN運行環境
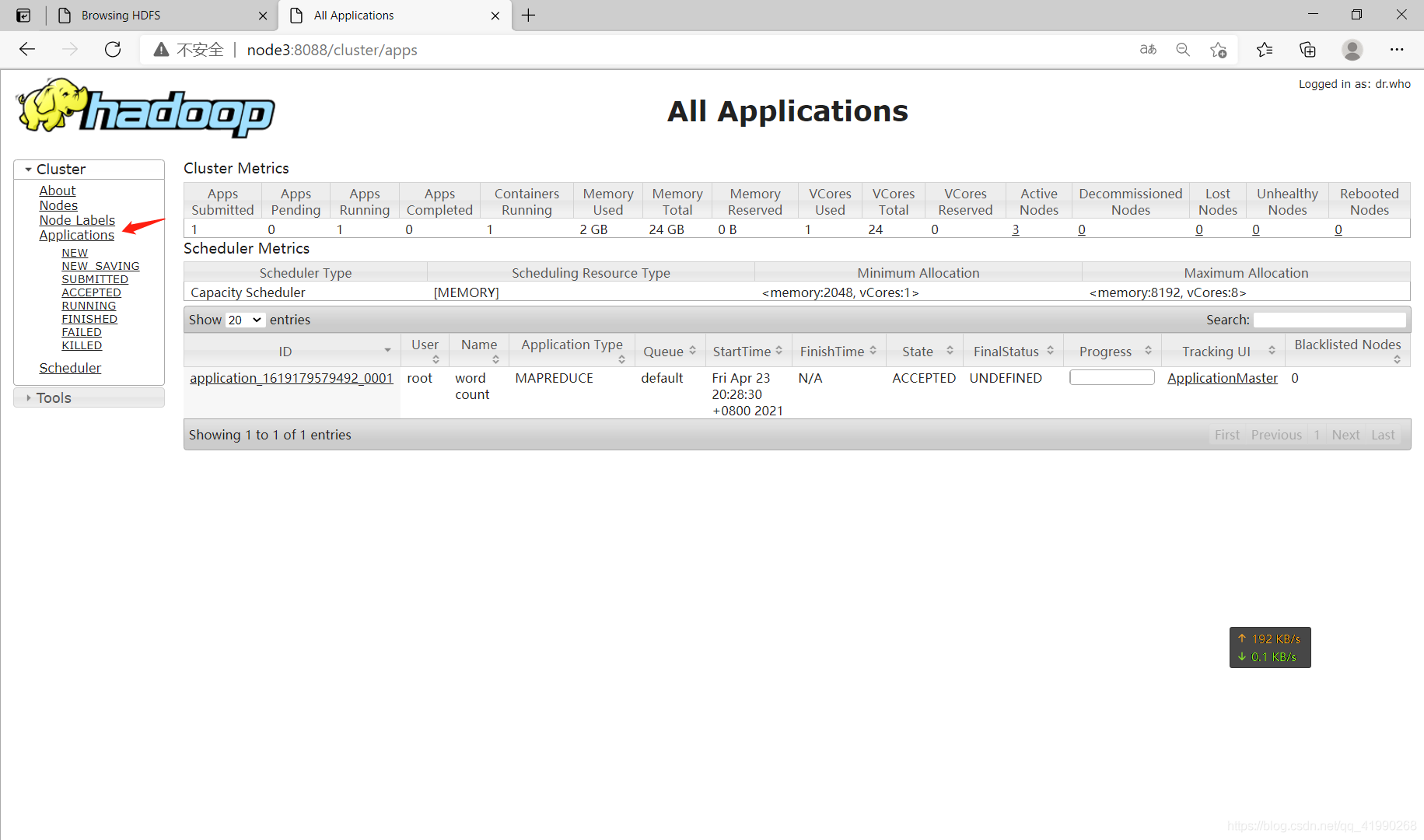
yarn jar /export/server/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wordcount/input/wc.txt /wordcount/output1
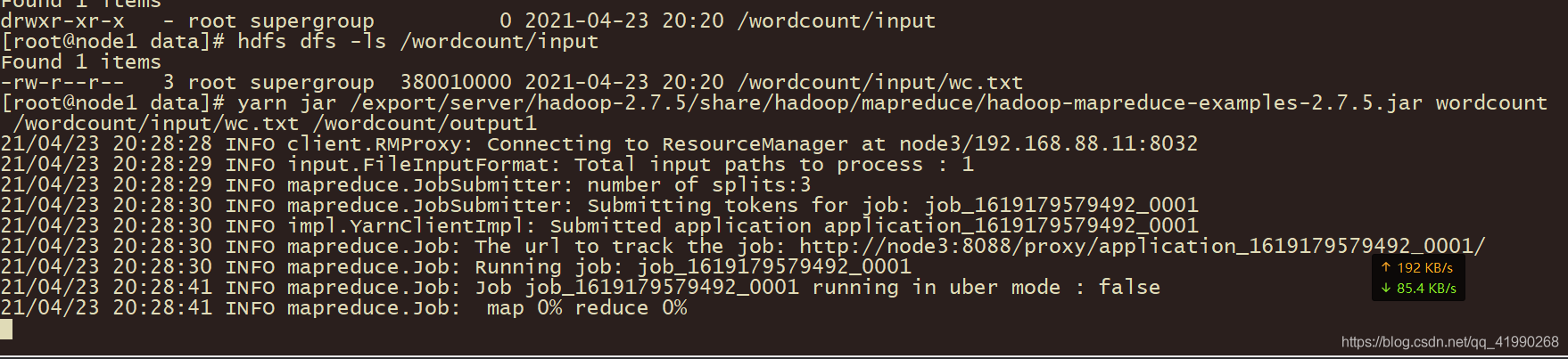
可以看出,Map完成后才會執行Reduce,
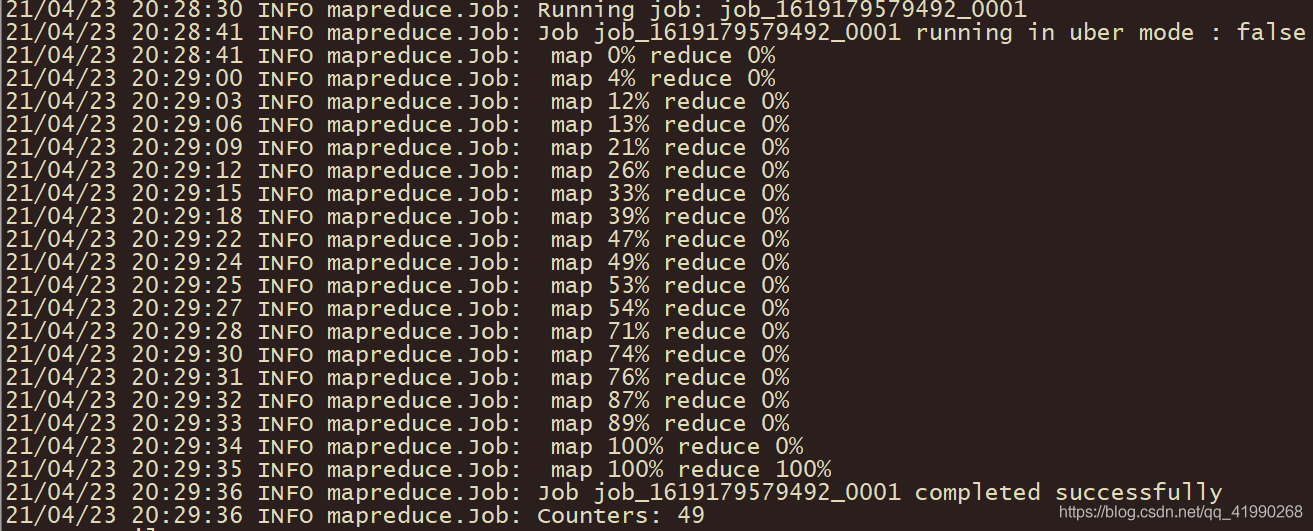
還有報表:
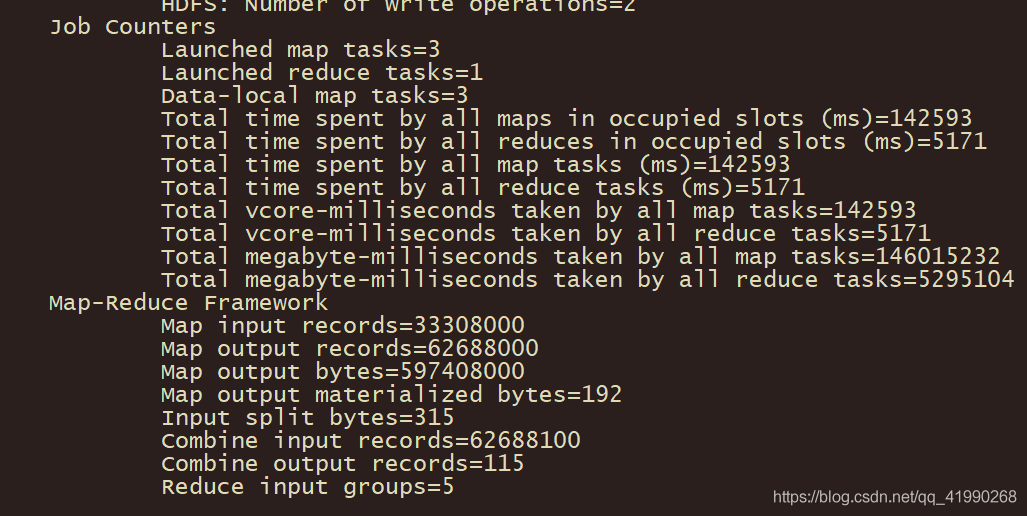
使用win10自帶的記事本打開wc.txt,好家伙,,,資料量再擴充幾倍,單機性能不足宿主機就要掛了,,,
基準測驗
寫入基準
切換目錄:
cd /export/server/hadoop-2.7.5/
開始寫入:
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar TestDFSIO -write -nrFiles 10 -size 10MB
計算完成后可以看到報表:

這還是扔SSD盤,寫入居然只有6M/s!!!這也太尼瑪慢了,,,
讀取基準
開始讀取:
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar TestDFSIO -read -nrFiles 10 -size 10MB
計算完成后看到報表:

也才100多M/s!!!
洗掉測驗檔案
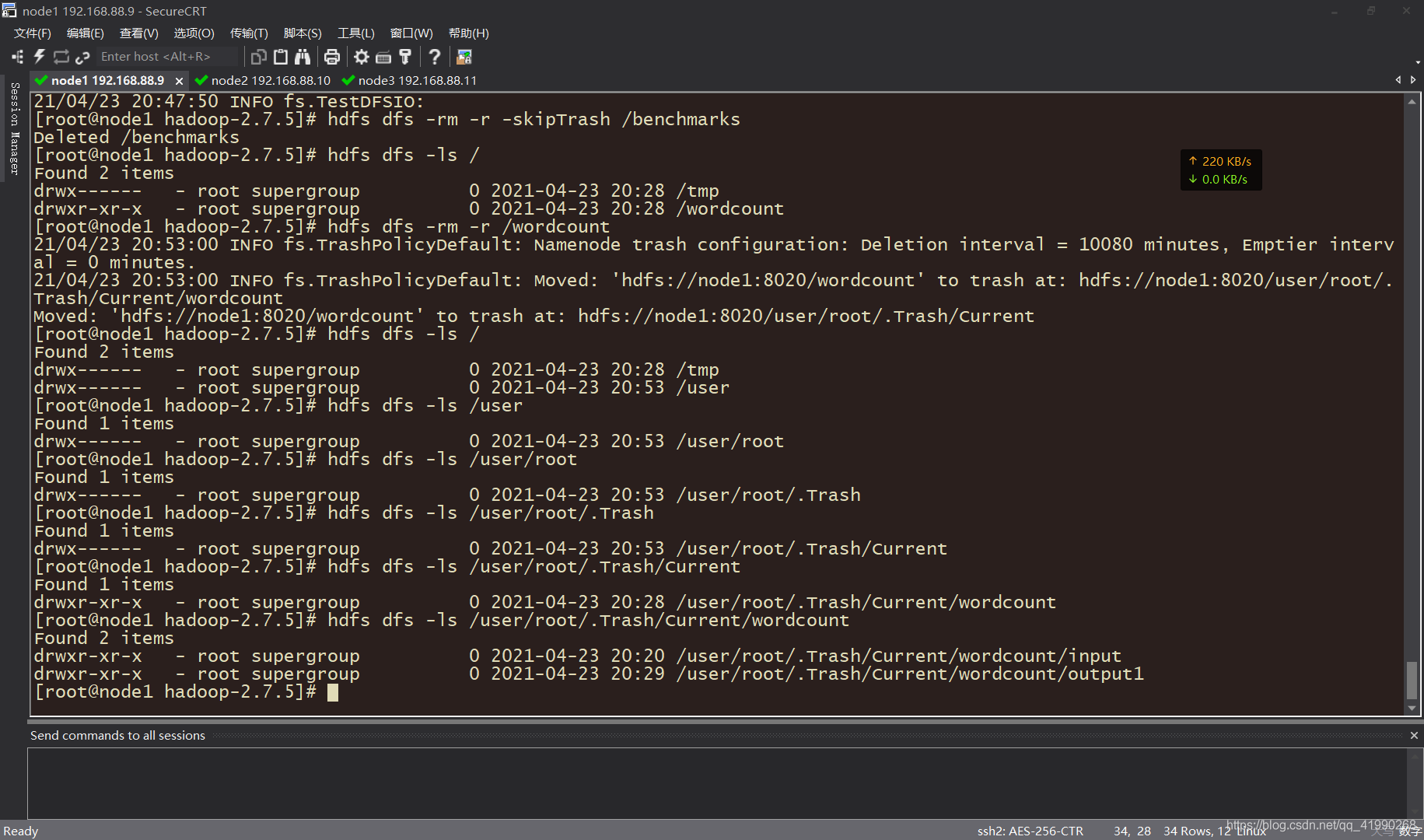
hdfs dfs -rm -r -skipTrash /benchmarks
順帶把之前wc.txt也干掉:
使用:
hdfs dfs -rm -r /wordcount
顯示:
[root@node1 hadoop-2.7.5]# hdfs dfs -rm -r /wordcount
21/04/23 20:53:00 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 10080 minutes, Emptier interval = 0 minutes.
21/04/23 20:53:00 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/wordcount' to trash at: hdfs://node1:8020/user/root/.Trash/Current/wordcount
Moved: 'hdfs://node1:8020/wordcount' to trash at: hdfs://node1:8020/user/root/.Trash/Current
握草!!!扔回收站了!!!
順著找到這個檔案:
hdfs dfs -ls /user/root/.Trash/Current/wordcount
這次強制洗掉:
hdfs dfs -rm -r -skipTrash /user/root/.Trash/Current/wordcount

直接洗掉方式應該是:
hdfs dfs -rm -r -skipTrash /wordcount/input
使用了-skipTrash后可以不經過回收站直接洗掉,可能Hadoop默認扔回收站的做法是安全的,,,但是刪2遍有時候很麻煩,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/279956.html
標籤:其他
上一篇:Docker的基本命令基礎介紹以及如何在Linux環境下安裝
下一篇:網路內外的新“網紅”