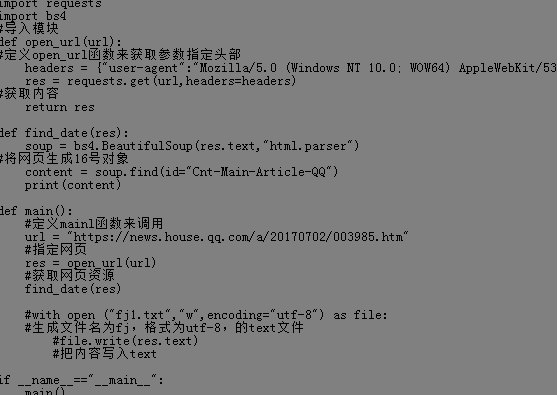
把查到的content,輸出一個fj2.txt,代碼如下
import requests
import bs4
#匯入模塊
def open_url(url):
#定義open_url函式來獲取引數指定頭部
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
res = requests.get(url,headers=headers)
#獲取內容
return res
def find_date(res):
soup = bs4.BeautifulSoup(res.text,"html.parser")
#將網頁生成16號物件
content = soup.find(id="Cnt-Main-Article-QQ")
#print(content)
def main():
#定義mainl函式來呼叫
url = "https://news.house.qq.com/a/20170702/003985.htm"
#指定網頁
res = open_url(url)
#獲取網頁資源
find_date(res)
with open ("fj2.txt","w",encoding="utf-8") as file:
#生成檔案名為fj,格式為utf-8,的text檔案
file.write(res.text)
#把內容寫入text
if __name__=="__main__":
main()
新手小白,望請教,最好詳細一點
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280043.html
下一篇:繪圖