本次我們繼續生產問題的疑難雜癥排查系統的文章,在開始我們下一次集中討論Redis的問題之前,本文與《疑難雜癥:系統雪崩到底是為什么》和《疑難雜癥: 遇到一個殺不掉,追不到,找不著的行程怎么破?》共同作為下次博客的前序鋪墊,經大家普及一下基礎知識,
當然這個情況我們還是以一個案例,引入今天的話題,最近Redis通過其極佳的性能而火爆全球,作為記憶體快取資料庫方面Redis幾乎沒有任何對手,因此Redis的問題往往是比較經典需要我們仔細推敲的,一般來講我們都比較推薦在使用Redis時將其默認的MaxMemory配置為系統同存總量的90%左右,并且關掉Linux的OOM以保證Redis行程不會被作業系統的記憶體釋放機制所殺掉,但是我們在生產上還是遇到了由于記憶體問題造成Redis無法正常啟動的問題,具體的現象如下:
- Redis在運行一段時間之后就會崩潰,
- 如果關閉Linux作業系統的OOM,則作業系統有可能出現問題,
- 如果打開OOM則Redis會被殺掉
- Redis的最大記憶體占用專案(MAXMEMORY)配置為60G,實際物理記憶體大小為64G,經查詢日志未發現Redis記憶體使用超過60G限度的問題,
資料區域性原理產生的回圈
我在《疑難雜癥:系統雪崩到底是為什么》曾經介紹過,資料的訪問往往都有區域性,比如記憶體單元A被訪問了,那么他的鄰居A’和A’’被訪問到的可能性也會極大的增加,因此CPU的高速快取、硬碟的快取都會將這些集中資料訪問進行優化,這種優化機制也強化了連續資料的訪問性能,比如讀取連續的磁盤空間通常性能能比隨機讀高三、四個數量級;記憶體也是同樣,讀取連續空間比讀取非連續空間要快得多,其機制就是硬碟及CPU快取一般會將要快取單元的鄰居也一并呼叫到快取當中,
而要搞清我們剛剛所說的Redis問題成因,還要把記憶體管理的模型以及物理記憶體分配的演算法講清楚,如果把計算機比成一個酒店,那記憶體就是客房,行程就是住戶而CPU就是酒店的管家,從這個角度上理解邏輯地址、線性地址以及物理地址是最為簡單的,
邏輯地址:應用行程直接用指令給出的地址其實就是邏輯地址,邏輯地址的引入其實就是讓行程之間彼此相互不會影響,都以為自己獨享整個客房,而屏蔽了底層物理地址的硬體細節 ,
線性地址(Linear Address)也叫虛擬地址(virtual address):這層的引入其實基本上是由于英特爾對于x86向前兼容的需要,按照原有的英特爾規劃,線性地址是暴露給作業系統管理的,也就是應用所在的邏輯地址空間會映射到一個大的線性空間,方便作業系統統一呼叫管理,而像Linux等目前主流的作業系統內核,全部啟用分頁機制進行行程之間的記憶體隔離與保護,線性地址其實就是邏輯地址,
物理地址:這就是真正的CPU地址總線訪問記憶體使用的址了,由硬體電路控制(現在這些硬體是可編程的了)其具體含義,物理地址中很大一部分是留給記憶體條中的記憶體的,但也常被映射到其他存盤器上(如顯存、BIOS等),
在實際地址映射時,CPU要利用其段式記憶體管理單元,先將為個邏輯地址轉換成一個線性地址,再利用其分頁功能,轉換為最終物理地址,也就是行程訪問的邏輯地址可能是相同的,但是最終他們訪問到的物理地址完全不同,當然這個轉換其實一次就夠了,之所以這樣冗余,正如前文所說完全是為了X86的向前兼容,
而物理記憶體是要盡量保證記憶體分配的連續性,雖然在各用戶行程的看到的連續邏輯地址也完全可以映射為不連續的物理記憶體上,但是這樣做的代價就是大幅犧牲執行效率,因為CPU快取只會針對物理記憶體做區域性優化,邏輯地址是CPU看不到也不關心的,這樣才能有效提速,因此一般作業系統都會保證將用戶行程申請的記憶體區域,映射到連續的物理記憶體上去,
最直接的方案就是將個記憶體區域多個固定大小的磁區,每個磁區容納一個行程,當一個磁區空閑時,可以將記憶體調入記憶體,等待執行,這是最簡單的記憶體分配方案,但是這種方案存在很多問題,我們并不知道每個行程需要多大的空間,如果空間過小,那么我們的行程就存不下,如果行程都很小,但是我們磁區很大的話,那么會造成很大程度的浪費,這些在每個磁區未被利用的空間,我們稱之為碎片,
伙伴演算法出場
為了盡可能的減少碎片,伙伴演算法正式出場,伙伴演算法,簡而言之,就是將記憶體分成若干塊,然后動態管理他們,Linux 便是采用這著名的伙伴系統演算法來解決外部碎片的問題,同linux將所有的空閑頁框分組為 11 塊鏈表,每一塊鏈表分別包含大小為1,2,4,8,16,32,64,128,256,512 和 1024 個連續的頁框,對1024 個頁框的最大請求對應著 4MB 大小的連續RAM 塊,
滿足以下條件的兩個塊稱為伙伴:
- 兩個塊具有相同的大小,記作 b
- 它們的物理地址是連續的
該演算法是迭代的,如果它成功合并所釋放的塊,它會試圖合并 2b 的塊,以再次試圖形成更大的塊,
下面通過一個例子,來深入地理解一下伙伴演算法的真正內涵(下面這個例子并不嚴格表示Linux 內核中的實作,是闡述伙伴演算法的實作思想):
假設系統中有 1MB 大小的記憶體需要動態管理,按斬訓伴演算法的要求:需要將這1M大小的記憶體進行劃分,這里,我們將這1M的記憶體分為 64K、64K、128K、256K、和512K 共五個部分,如下圖:
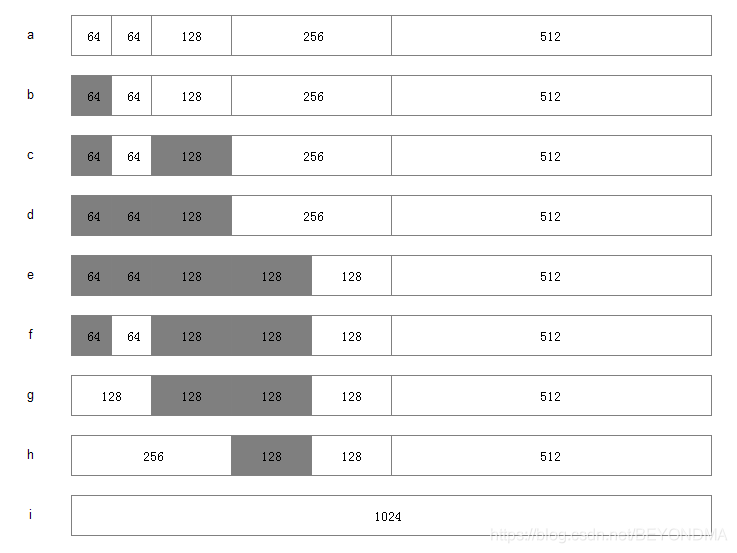
分配記憶體步驟:
1.尋找大小合適的記憶體塊(大于等于所需大小并且最接近2的冪,比如需要27,實際分配32)
1.如果找到了,分配給應用程式,
2.如果沒找到,分出合適的記憶體塊,
1.對半分離出高于所需大小的空閑記憶體塊
2.如果分到最低限度,分配這個大小,
3.回溯到步驟1(尋找合適大小的塊)
4.重復該步驟直到一個合適的塊
釋放記憶體:
1.釋放該記憶體塊
1.尋找相鄰的塊,看其是否釋放了,
2.如果相鄰塊也釋放了,合并這兩個塊,重復上述步驟直到遇上未釋放的相鄰塊,或者達到最高上限(即所有記憶體都釋放了),
理解不了伙伴演算法也沒關系,只要了解下面幾個結論就好,
1作業系統會在行程申請或者釋放記憶體的同時進行記憶體碎片的整理,
2在記憶體使用率比較高的情況下去申請或者釋放記憶體都可能造成作業系統頻繁進行記憶體頁的合并或者切割,而這樣的操作都是加鎖保護的,一般會使系統整體的運行效率大幅下降,
3在記憶體還有足夠空閑的情況下也有可能申請不到記憶體塊,
回到Redis的記憶體問題
有了上述背景知識我們再來看剛剛提到的redis問題,
我們知道redis有最大記憶體占用也就是maxmemory的配置,一旦達到或者超過最大記憶體有以下幾種策略可選擇
noeviction: 不進行置換,表示即使記憶體達到上限也不進行置換,所有能引起記憶體增加的命令都會回傳error
allkeys-lru: 優先洗掉掉最近最不經常使用的key,用以保存新資料
volatile-lru: 只從設定失效(expire set)的key中選擇最近最不經常使用的key進行洗掉,用以保存新資料
allkeys-random: 隨機從all-keys中選擇一些key進行洗掉,用以保存新資料
volatile-random: 只從設定失效(expire set)的key中,選擇一些key進行洗掉,用以保存新資料
volatile-ttl: 只從設定失效(expire set)的key中,選出存活時間(TTL)最短的key進行洗掉,用以保存新資料
我們當時選擇的是lru策略,當然有關redis的問題排查我計劃專題介紹,他的lru實作其實是分組策略,而不是全面的大排行,這明顯是參考了快取中組連接策略的精髓,當然這里不加贅述了,
而當時的情況下,redis在系統記憶體使用本身就比較高的情況下,還在頻繁進行記憶體的釋放與申請操作,這種情況下如果系統開了oom killer那么redis會被殺掉,如果沒開那么系統會由于過大的記憶體整理損耗而崩潰,
兩點啟示
1如果想保證redis服務的平安,選擇noeviction也就是不替換原有key的策略是最穩的,
2 如果無法選擇noeviction策略,那么盡量打開系統的oom策略,這樣更有利于問題的排查,以免錯誤的把原因歸結為作業系統問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280305.html
標籤:AI
上一篇:低代碼開發不靠譜?其實我錯了
下一篇:10種編程語言實作Y組合子