目錄
- 一、引入
- 1.1 特征匹配
- 1.2 問題:Bad Example
- 1.2.1 “鬼影”
- 1.2.2 錯誤匹配的干擾
- 1.3 解決:Simple Example
- 1.3.1 擬合消除噪聲點
- 1.3.2 引數求解:RAndom SAmple Consensus
- 1.3.3 APAP演算法
- 1.3.4 尋找最佳拼接縫
- 1.4 影像拼接
- 1.4.1 整體流程
- 1.4.2 multi-blending策略
- 二、全景拼接
- 2.1 RANSAC
- 2.2 穩健的單應性矩陣估計
- 2.3 拼接影像
- 2.3.1 具體實作
- 2.3.2 結果及分析
- 2.4 小結
- 結論、問題(及解決方法)
一、引入
1.1 特征匹配
在上篇博客中已經對影像到影像的映射(SIFT演算法,Harris角點檢測演算法等)、地理標記影像進行了詳細的介紹,引路:【Python計算機視覺】影像到影像的映射(單應性變換、影像扭曲)
1.2 問題:Bad Example
1.2.1 “鬼影”


- 鬼影問題:影像拼接后出現重影;
- “鬼影”的產生原因:影像映射是全域的單應性變換,但是影像場景中各個物體往往具有不同的深度,如果采用處于不同深度物體的特征點進行全域單應性變換,由于此時影像中的物體無法滿足近似于同一平面的條件,計算得到的單應性矩陣會有較大的誤差,僅僅由一個全域的單應性變換無法完全描述兩幅影像之間的變換關系,
1.2.2 錯誤匹配的干擾
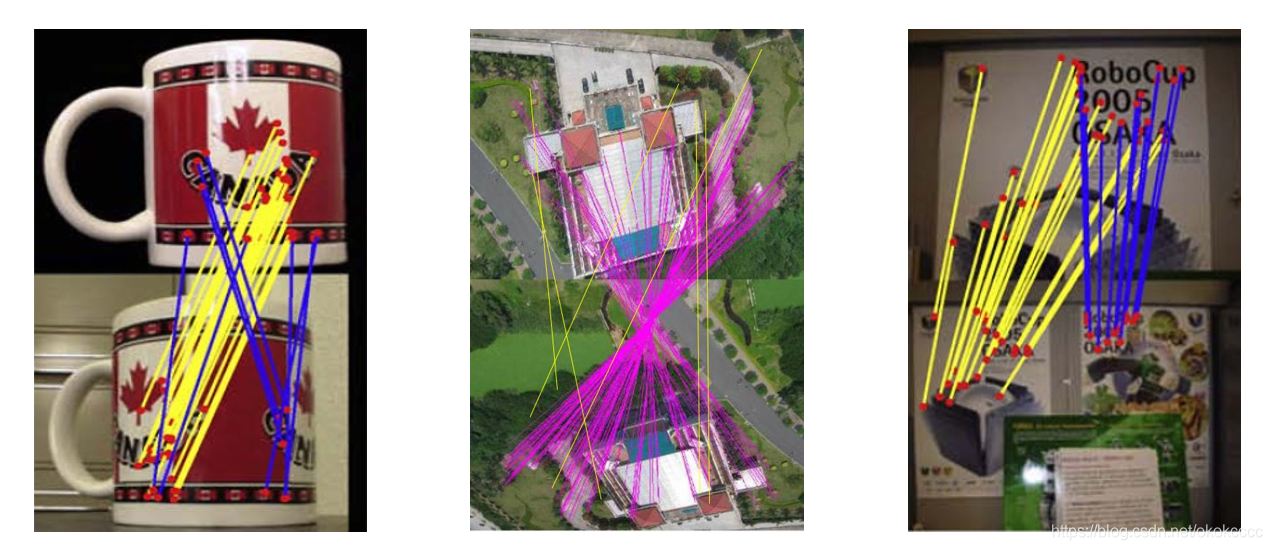
- 在進行SIFT特征點匹配時,往往會出現一個問題:如果影像的噪聲太大,就會使得特征點的匹配發生了偏差,匹配到了錯誤的點,這種不好的匹配效果,會對后面的影像拼接產生很大的影響,
- ①錯配特征帶來的影響,
- ②結構化影響,
1.3 解決:Simple Example
1.3.1 擬合消除噪聲點
要消除特征點的噪聲,可以通過擬合特征點,找到一個合適的擬合線,然后消除噪聲點,
- 直線擬合:
給定若干二維空間中的點,求直線y=ax+b,使得該直線對空間點的擬合誤差最小:
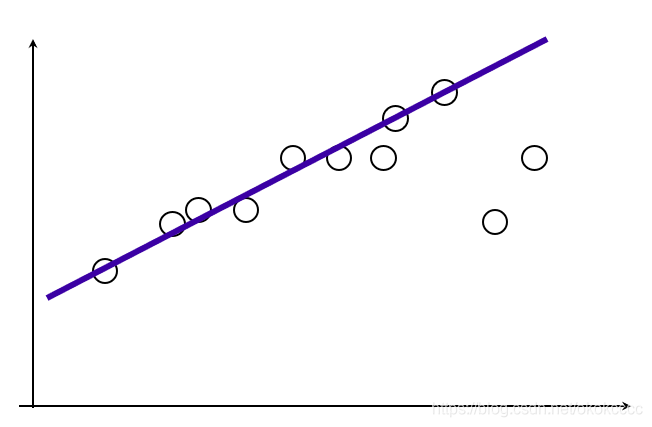
①隨機選擇兩個點;
②根據該點構造直線;
③給定閾值【設定一個超引數】,計算inliers數量【即比較近的點】
- 圓擬合:
三點可以確定一個圓,隨機選取三個點,確定經過這三個點的圓,然后計算這個圓上的點的數量,達到指定閾值就可以確定要擬合的圓,
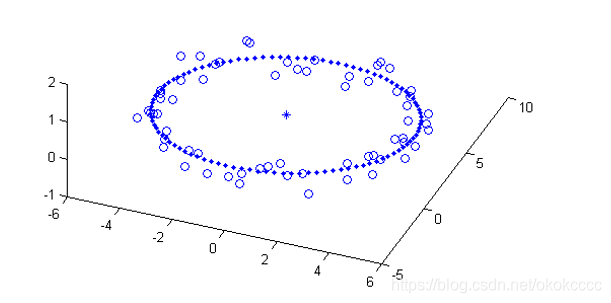
- 復雜方程擬合:
通過求解多項式,解出未知引數,得到曲線上的點,確定擬合曲線,
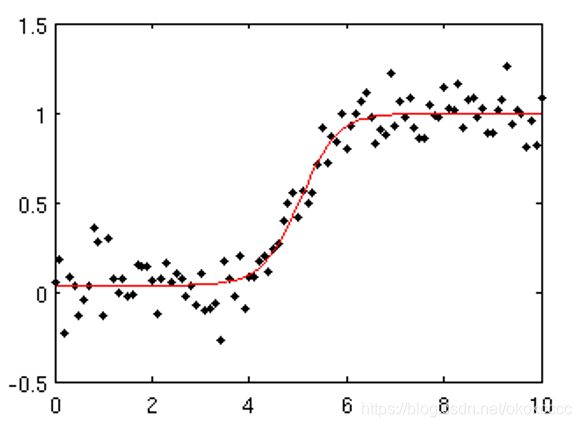
1.3.2 引數求解:RAndom SAmple Consensus
對于這些壞的匹配點,我們應該怎么辦呢?
- 不斷選擇一對匹配的特征點,然后計算由這對特征點確定的數學模型的inliers,

- 當inliers達到閾值條件,擬合出了數學模型后,便計算兩幅對應所有特征點的偏移量,求出偏移量的平均值,進行影像拼接,

1.3.3 APAP演算法
- 2013年,Julio Zaragoza等人發表了一種新的影像配準演算法APAP(As-Projective-As-Possible Image Stitching with Moving DLT)解決鬼影現象可以采用APAP演算法,
- APAP演算法流程:
①SIFT得到兩幅影像的匹配點對;
②通過RANSAC剔除外點,得到N對內點;
③利用DLT和SVD計算全域單應性;
④將源圖劃分網格,取網格中心點,計算每個中心點和源圖上內點之間的歐式距離和權重;
⑤將權重放到DLT演算法的A矩陣中,構建成新的W*A矩陣,重新SVD分解,自然就得到了當前網格的區域單應性矩陣;
⑥遍歷每個網格,利用區域單應性矩陣映射到全景畫布上,就得到了APAP變換后的源圖;
⑦最后就是進行拼接線的加權融合,
1.3.4 尋找最佳拼接縫
- 很多情況下,使用一個全域單應變換并不能準確對齊影像,需要一些后處理來削弱拼接的痕跡,比如尋找最佳拼接縫【如下圖所示】,

- 如何找?
使用最大流最小割演算法尋找拼接縫:【找最小割與找最大流在本質上是等價的】

1.4 影像拼接
1.4.1 整體流程
- 根據給定影像/集,實作特征匹配;
- 通過匹配特征計算影像之間的變換結構;
- 利用影像變換結構,實作影像映射;
- 針對疊加后的影像,采用APAP之類的演算法,對其特征點;
- 通過圖割方法,自動選取拼接縫;
- 根據multu-blending策略實作融合,
1.4.2 multi-blending策略
- multi-band bleing策略采用Laplacian(拉普拉斯)金字塔,通過對相鄰兩層的高斯金字塔進行差分,將原圖分解成不同尺度的子圖,對每一個之圖進行加權平均,得到每一層的融合結果,最后進行金字塔的反向重建,得到最終融合效果程序,融合之后可以得到較好的拼接效果,
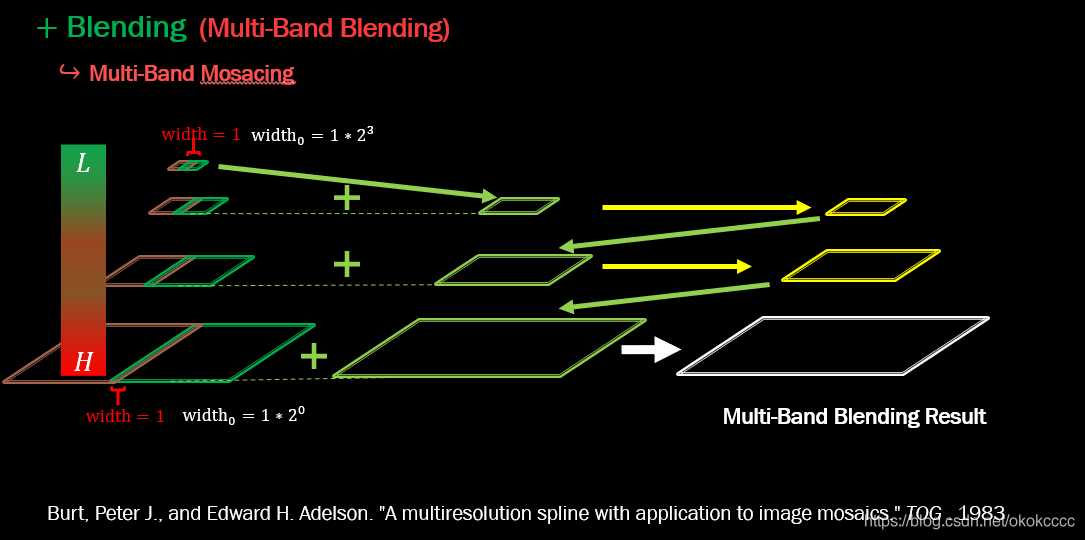
- 如下圖所示:

二、全景拼接
2.1 RANSAC
- RANSAC 是“RANdom SAmple Consensus”(隨機一致性采樣)的縮寫,該方法是用來找到正確模型來擬合帶有噪聲資料的迭代方法,給定一個模型,例如點集之間的單應性矩陣,RANSAC 基本的思想是,資料中包含正確的點和噪聲點,合理的模型應該能夠在描述正確資料點的同時摒棄噪聲點,
- RANSAC的基本假設:
①資料由“局內點”組成,例如:資料的分布可以用一些模型引數來解釋;
②“局外點”是不能適應該模型的資料;
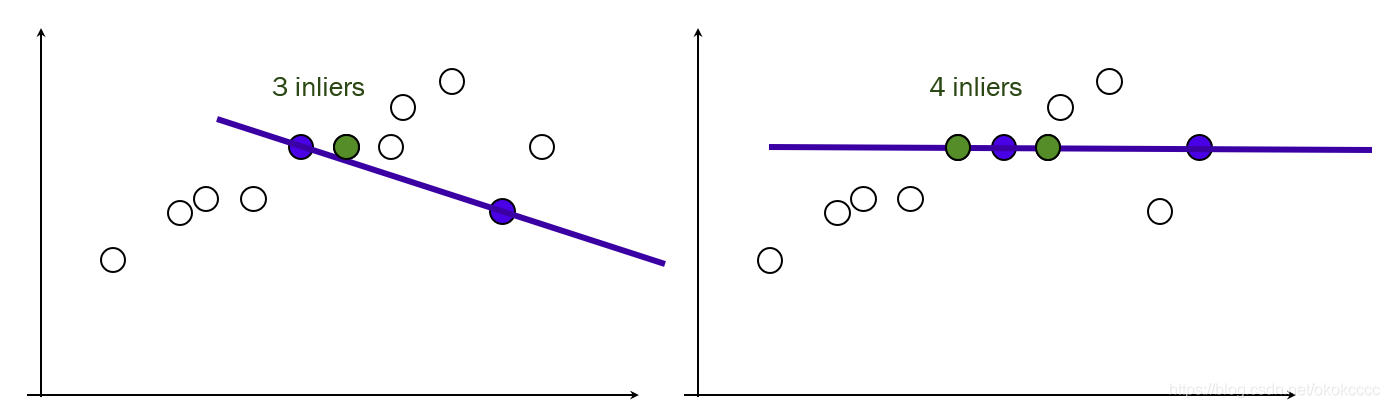
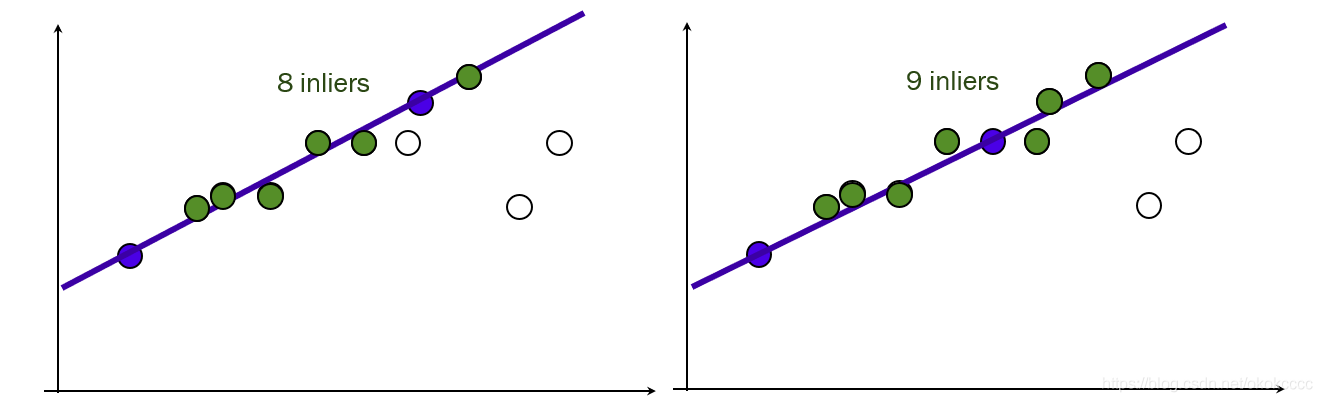
③除此之外的資料屬于噪聲, - RANSAC演算法基本思想:(如上面直線擬合)
①隨機選取兩個點;
②根據隨機選取的兩個點構造方程y=ax+b;
③將所有的資料點套到這個模型中計算誤差;
④給定閾值,計算inliers數量;
⑤不斷重復上述程序,直到達到一次迭代次數后,選擇inliers數量最多的直線方程,作為問題的解, - RANSAC求解單應性矩陣
①隨機選擇四對匹配特征(選擇4對特征點因為單應性矩陣有8個自由度,至少需要8個線性方程求解,對應到點位置資訊上,一組點對可以列出兩個方程,則至少包含4組匹配點對)
②根據直接線性變換解法DLT計算單應性矩陣H(唯一解)
③對所匹配點,計算映射誤差
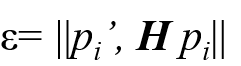
④根據誤差閾值,確定inliers
⑤針對最大的inliers集合,重新計算單應性矩陣H - RANSAC 的標準例子:用一條直線擬合帶有噪聲資料的點集,簡單的最小二乘在該例子中可能會失效,但是 RANSAC 能夠挑選出正確的點,然后獲取能夠正確擬合的直線,
使用RANSAC演算法用一條直線來擬合包含噪聲點資料點集如下(源自http://www.scopy.org/Cookbook/RANSAC)
【代碼】
import numpy
import scipy # use numpy if scipy unavailable
import scipy.linalg # use numpy if scipy unavailable
## Copyright (c) 2004-2007, Andrew D. Straw. All rights reserved.
## Redistribution and use in source and binary forms, with or without
## modification, are permitted provided that the following conditions are
## met:
## * Redistributions of source code must retain the above copyright
## notice, this list of conditions and the following disclaimer.
## * Redistributions in binary form must reproduce the above
## copyright notice, this list of conditions and the following
## disclaimer in the documentation and/or other materials provided
## with the distribution.
## * Neither the name of the Andrew D. Straw nor the names of its
## contributors may be used to endorse or promote products derived
## from this software without specific prior written permission.
## THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
## "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
## LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
## A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
## OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
## SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
## LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
## DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
## THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
## (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
## OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
def ransac(data,model,n,k,t,d,debug=False,return_all=False):
"""fit model parameters to data using the RANSAC algorithm
This implementation written from pseudocode found at
http://en.wikipedia.org/w/index.php?title=RANSAC&oldid=116358182
{{{
Given:
data - a set of observed data points
model - a model that can be fitted to data points
n - the minimum number of data values required to fit the model
k - the maximum number of iterations allowed in the algorithm
t - a threshold value for determining when a data point fits a model
d - the number of close data values required to assert that a model fits well to data
Return:
bestfit - model parameters which best fit the data (or nil if no good model is found)
iterations = 0
bestfit = nil
besterr = something really large
while iterations < k {
maybeinliers = n randomly selected values from data
maybemodel = model parameters fitted to maybeinliers
alsoinliers = empty set
for every point in data not in maybeinliers {
if point fits maybemodel with an error smaller than t
add point to alsoinliers
}
if the number of elements in alsoinliers is > d {
% this implies that we may have found a good model
% now test how good it is
bettermodel = model parameters fitted to all points in maybeinliers and alsoinliers
thiserr = a measure of how well model fits these points
if thiserr < besterr {
bestfit = bettermodel
besterr = thiserr
}
}
increment iterations
}
return bestfit
}}}
"""
iterations = 0
bestfit = None
besterr = numpy.inf
best_inlier_idxs = None
while iterations < k:
maybe_idxs, test_idxs = random_partition(n,data.shape[0])
maybeinliers = data[maybe_idxs,:]
test_points = data[test_idxs]
maybemodel = model.fit(maybeinliers)
test_err = model.get_error( test_points, maybemodel)
also_idxs = test_idxs[test_err < t] # select indices of rows with accepted points
alsoinliers = data[also_idxs,:]
if debug:
print 'test_err.min()',test_err.min()
print 'test_err.max()',test_err.max()
print 'numpy.mean(test_err)',numpy.mean(test_err)
print 'iteration %d:len(alsoinliers) = %d'%(
iterations,len(alsoinliers))
if len(alsoinliers) > d:
betterdata = numpy.concatenate( (maybeinliers, alsoinliers) )
bettermodel = model.fit(betterdata)
better_errs = model.get_error( betterdata, bettermodel)
thiserr = numpy.mean( better_errs )
if thiserr < besterr:
bestfit = bettermodel
besterr = thiserr
best_inlier_idxs = numpy.concatenate( (maybe_idxs, also_idxs) )
iterations+=1
if bestfit is None:
raise ValueError("did not meet fit acceptance criteria")
if return_all:
return bestfit, {'inliers':best_inlier_idxs}
else:
return bestfit
def random_partition(n,n_data):
"""return n random rows of data (and also the other len(data)-n rows)"""
all_idxs = numpy.arange( n_data )
numpy.random.shuffle(all_idxs)
idxs1 = all_idxs[:n]
idxs2 = all_idxs[n:]
return idxs1, idxs2
class LinearLeastSquaresModel:
"""linear system solved using linear least squares
This class serves as an example that fulfills the model interface
needed by the ransac() function.
"""
def __init__(self,input_columns,output_columns,debug=False):
self.input_columns = input_columns
self.output_columns = output_columns
self.debug = debug
def fit(self, data):
A = numpy.vstack([data[:,i] for i in self.input_columns]).T
B = numpy.vstack([data[:,i] for i in self.output_columns]).T
x,resids,rank,s = scipy.linalg.lstsq(A,B)
return x
def get_error( self, data, model):
A = numpy.vstack([data[:,i] for i in self.input_columns]).T
B = numpy.vstack([data[:,i] for i in self.output_columns]).T
B_fit = scipy.dot(A,model)
err_per_point = numpy.sum((B-B_fit)**2,axis=1) # sum squared error per row
return err_per_point
def test():
# generate perfect input data
n_samples = 500
n_inputs = 1
n_outputs = 1
A_exact = 20*numpy.random.random((n_samples,n_inputs) )
perfect_fit = 60*numpy.random.normal(size=(n_inputs,n_outputs) ) # the model
B_exact = scipy.dot(A_exact,perfect_fit)
assert B_exact.shape == (n_samples,n_outputs)
# add a little gaussian noise (linear least squares alone should handle this well)
A_noisy = A_exact + numpy.random.normal(size=A_exact.shape )
B_noisy = B_exact + numpy.random.normal(size=B_exact.shape )
if 1:
# add some outliers
n_outliers = 100
all_idxs = numpy.arange( A_noisy.shape[0] )
numpy.random.shuffle(all_idxs)
outlier_idxs = all_idxs[:n_outliers]
non_outlier_idxs = all_idxs[n_outliers:]
A_noisy[outlier_idxs] = 20*numpy.random.random((n_outliers,n_inputs) )
B_noisy[outlier_idxs] = 50*numpy.random.normal(size=(n_outliers,n_outputs) )
# setup model
all_data = numpy.hstack( (A_noisy,B_noisy) )
input_columns = range(n_inputs) # the first columns of the array
output_columns = [n_inputs+i for i in range(n_outputs)] # the last columns of the array
debug = False
model = LinearLeastSquaresModel(input_columns,output_columns,debug=debug)
linear_fit,resids,rank,s = scipy.linalg.lstsq(all_data[:,input_columns],
all_data[:,output_columns])
# run RANSAC algorithm
ransac_fit, ransac_data = ransac(all_data,model,
50, 1000, 7e3, 300, # misc. parameters
debug=debug,return_all=True)
if 1:
import pylab
sort_idxs = numpy.argsort(A_exact[:,0])
A_col0_sorted = A_exact[sort_idxs] # maintain as rank-2 array
if 1:
pylab.plot( A_noisy[:,0], B_noisy[:,0], 'k.', label='data' )
pylab.plot( A_noisy[ransac_data['inliers'],0], B_noisy[ransac_data['inliers'],0], 'bx', label='RANSAC data' )
else:
pylab.plot( A_noisy[non_outlier_idxs,0], B_noisy[non_outlier_idxs,0], 'k.', label='noisy data' )
pylab.plot( A_noisy[outlier_idxs,0], B_noisy[outlier_idxs,0], 'r.', label='outlier data' )
pylab.plot( A_col0_sorted[:,0],
numpy.dot(A_col0_sorted,ransac_fit)[:,0],
label='RANSAC fit' )
pylab.plot( A_col0_sorted[:,0],
numpy.dot(A_col0_sorted,perfect_fit)[:,0],
label='exact system' )
pylab.plot( A_col0_sorted[:,0],
numpy.dot(A_col0_sorted,linear_fit)[:,0],
label='linear fit' )
pylab.legend()
pylab.show()
if __name__=='__main__':
test()
【結果】
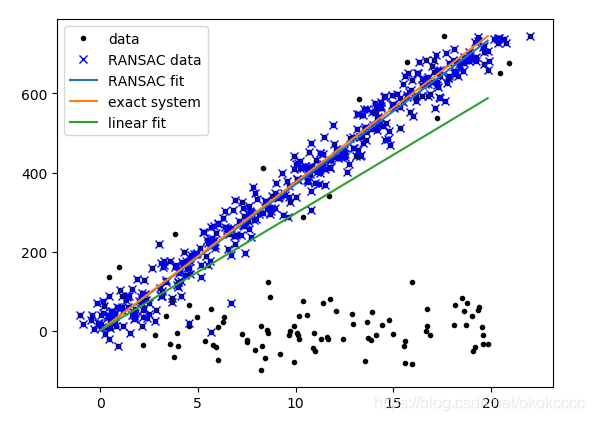
【分析】
之所以RANSAC能在有大量噪音情況仍然準確,主要原因是隨機取樣時只取一部分可以避免估算結果被離群資料影響,
- RANSAC演算法的輸入為:
- 觀測資料 (包括內群與外群的資料)
- 符合部分觀測資料的模型 (與內群相符的模型)
- 最少符合模型的內群數量 判斷資料是否符合模型的閾值(資料與模型之間的誤差容忍度)
- 迭代運算次數 (抽取多少次隨機內群)
- RANSAC演算法的輸出為:
- 最符合資料的模型引數 (如果內群數量小于輸入第三條則判斷為資料不存在此模型)
- 內群集 (符合模型的資料)
- 優點:
能在包含大量外群的資料中準確地找到模型引數,并且引數不受到外群影響, - 缺點:
計算引數時迭代次數沒有上限,得出來的引數結果有可能并不是最優的,甚至可能不符合真實內群,所以設定 RANSAC引數的時候要根據應用考慮“準確度與效率”哪一個更重要,以此決定做多少次迭代運算,設定與模型的最大誤差閾值也是要自己調,因應用而異,還有一點就是RANSAC只能估算一個模型,
2.2 穩健的單應性矩陣估計
- 在任何模型中都可以使用 RANSAC 模塊,在使用 RANSAC 模塊時,我們只需要在相應 Python 類中實作fit()和get_error()方法,剩下就是正確地使用ransac.py,我們這里使用可能的對應點集來自動找到用于全景影像的單應性矩陣,下面是使用SIFT特征自動找到匹配對應:
【 代碼】
featname = ['C:/Users/ltt/Documents/Subjects/大三下/計算機視覺(蔡國榕)/onepic/match-pic1/' + str(i + 1) + '.sift' for i in range(5)]
imname = ['C:/Users/ltt/Documents/Subjects/大三下/計算機視覺(蔡國榕)/onepic/match-pic1/' + str(i + 1) + '.jpg' for i in range(5)]
# extract features and m
# match
l = {}
d = {}
for i in range(5):
sift.process_image(imname[i], featname[i])
l[i], d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(4):
matches[i] = sift.match(d[i + 1], d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(4):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i + 1]))
figure()
sift.plot_matches(im2, im1, l[i + 1], l[i], matches[i], show_below=True)
【結果】




2.3 拼接影像
- 估計出影像間的單應性矩陣(使用RANSAC演算法),現在我們需要將所有的影像扭曲到一個公共平面上,由于我們所有的影像是由照相機水平旋轉拍攝的,因此我們可以使用一個較簡單的步驟:將中心影像左邊或者右邊的區域填充0,以便為扭曲的影像騰出空間,
2.3.1 具體實作
【代碼】
from pylab import *
from numpy import *
from PIL import Image
# If you have PCV installed, these imports should work
from PCV.geometry import homography, warp
from PCV.localdescriptors import sift
"""
This is the panorama example from section 3.3.
"""
# set paths to data folder
featname = ['C:/Users/ltt/Documents/Subjects/大三下/計算機視覺(蔡國榕)/onepic/match-pic1/' + str(i + 1) + '.sift' for i in range(5)]
imname = ['C:/Users/ltt/Documents/Subjects/大三下/計算機視覺(蔡國榕)/onepic/match-pic1/' + str(i + 1) + '.jpg' for i in range(5)]
# extract features and m
# match
l = {}
d = {}
for i in range(5):
sift.process_image(imname[i], featname[i])
l[i], d[i] = sift.read_features_from_file(featname[i])
matches = {}
for i in range(4):
matches[i] = sift.match(d[i + 1], d[i])
# visualize the matches (Figure 3-11 in the book)
for i in range(4):
im1 = array(Image.open(imname[i]))
im2 = array(Image.open(imname[i + 1]))
figure()
sift.plot_matches(im2, im1, l[i + 1], l[i], matches[i], show_below=True)
# function to convert the matches to hom. points
# 將匹配轉換成齊次坐標點的函式
def convert_points(j):
ndx = matches[j].nonzero()[0]
fp = homography.make_homog(l[j + 1][ndx, :2].T)
ndx2 = [int(matches[j][i]) for i in ndx]
tp = homography.make_homog(l[j][ndx2, :2].T)
# switch x and y - TODO this should move elsewhere
fp = vstack([fp[1], fp[0], fp[2]])
tp = vstack([tp[1], tp[0], tp[2]])
return fp, tp
# estimate the homographies
# 估計單應性矩陣
model = homography.RansacModel()
fp, tp = convert_points(1)
H_12 = homography.H_from_ransac(fp, tp, model)[0] # im 1 to 2
fp, tp = convert_points(0)
H_01 = homography.H_from_ransac(fp, tp, model)[0] # im 0 to 1
tp, fp = convert_points(2) # NB: reverse order
H_32 = homography.H_from_ransac(fp, tp, model)[0] # im 3 to 2
tp, fp = convert_points(3) # NB: reverse order
H_43 = homography.H_from_ransac(fp, tp, model)[0] # im 4 to 3
# 扭曲影像
delta = 2000 # 用于填充和平移 for padding and translation
im1 = array(Image.open(imname[1]), "uint8")
im2 = array(Image.open(imname[2]), "uint8")
im_12 = warp.panorama(H_12, im1, im2, delta, delta)
im1 = array(Image.open(imname[0]), "f")
im_02 = warp.panorama(dot(H_12, H_01), im1, im_12, delta, delta)
im1 = array(Image.open(imname[3]), "f")
im_32 = warp.panorama(H_32, im1, im_02, delta, delta)
im1 = array(Image.open(imname[4]), "f")
im_42 = warp.panorama(dot(H_32, H_43), im1, im_32, delta, 2 * delta)
figure()
imshow(array(im_42, "uint8"))
axis('off')
show()
2.3.2 結果及分析
- 資料集1:

- 結果1:

- 資料集2:

- 結果2:

- 資料集3:

- 結果3:

【分析】 - 以上三組資料集拼接效果都還是可以的,但是由于光影的變化,導致天空的拼接效果不是特別理想,還具有瑕疵;
- 第一組圖是宿舍后方,由于照片拍攝的原因,右方距離圖片中心較遠,導致拼接效果在三組中最差,可以明顯的看出拼接的痕跡;
- 第二組圖是宿舍樓群,可以看出除了光影處,其余拼接效果較好,無明顯痕跡;
- 第三組圖是六社區五組團,同樣也是光影的問題導致拼接痕跡可以看出,
2.4 小結
結論、問題(及解決方法)
1.在資料集中,圖片需按照從右往左開始編號,否則會發生拼接的錯亂,如下圖所示:

2.圖片大小需要調整,否則尋找特征時會發生超出陣列索引,且原圖較大耗費時間長,最好進行壓縮調整;
3.選取資料集圖片時,要選取特征點明顯,較為好匹配的,且要遵循拼接圖片規則,否則會遇到這個錯誤:ValueError: did not meet fit acceptance criteria如下圖資料集便是不可取的:

4.正如以上實驗所看見的,影像曝光不同,在單個影像的邊界上存在邊緣效應,導致拼接痕跡較為明顯,(商業的創建全景影像軟體里有額外的操作來對強度進行歸一化,并對平移進行平滑場景轉換,以使得結果看上去更好,)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280353.html
標籤:其他