基于Ubuntu系統下的Hadoop平臺搭建
- 1.更換阿里源(因為訪問archive.ubuntu太慢,所以換成國內源,訪問更快)
- 2.鏈接xshell
- 1.安裝SSH服務端
- 2.鏈接xhsell
- 3.安裝JAVA環境
- 4.創建Hadoop用戶
- 4.1創建新用戶并設定密碼
- 4.2為hadoop用戶添加管理員權限
- 5.設定SSH免密登錄
- 5.1登錄localhost
- 5.2設定為無密碼登錄
- 6.Hadoop安裝
- 6.1解壓到我們的Ubuntu系統中
- 6.2切換到Hadoop用戶
- 6.3解壓Hadoop
- 6.4偽分布式模式配置
- 6.4.1修改組態檔
- 6.4.2執行名稱節點格式化
- 6.5啟動hadoop
- 6.6使用瀏覽器查看HDFS資訊
- 6.7運行偽分布式實體
- 6.8關閉Hadoop
- 6.9相關命令
1.更換阿里源(因為訪問archive.ubuntu太慢,所以換成國內源,訪問更快)
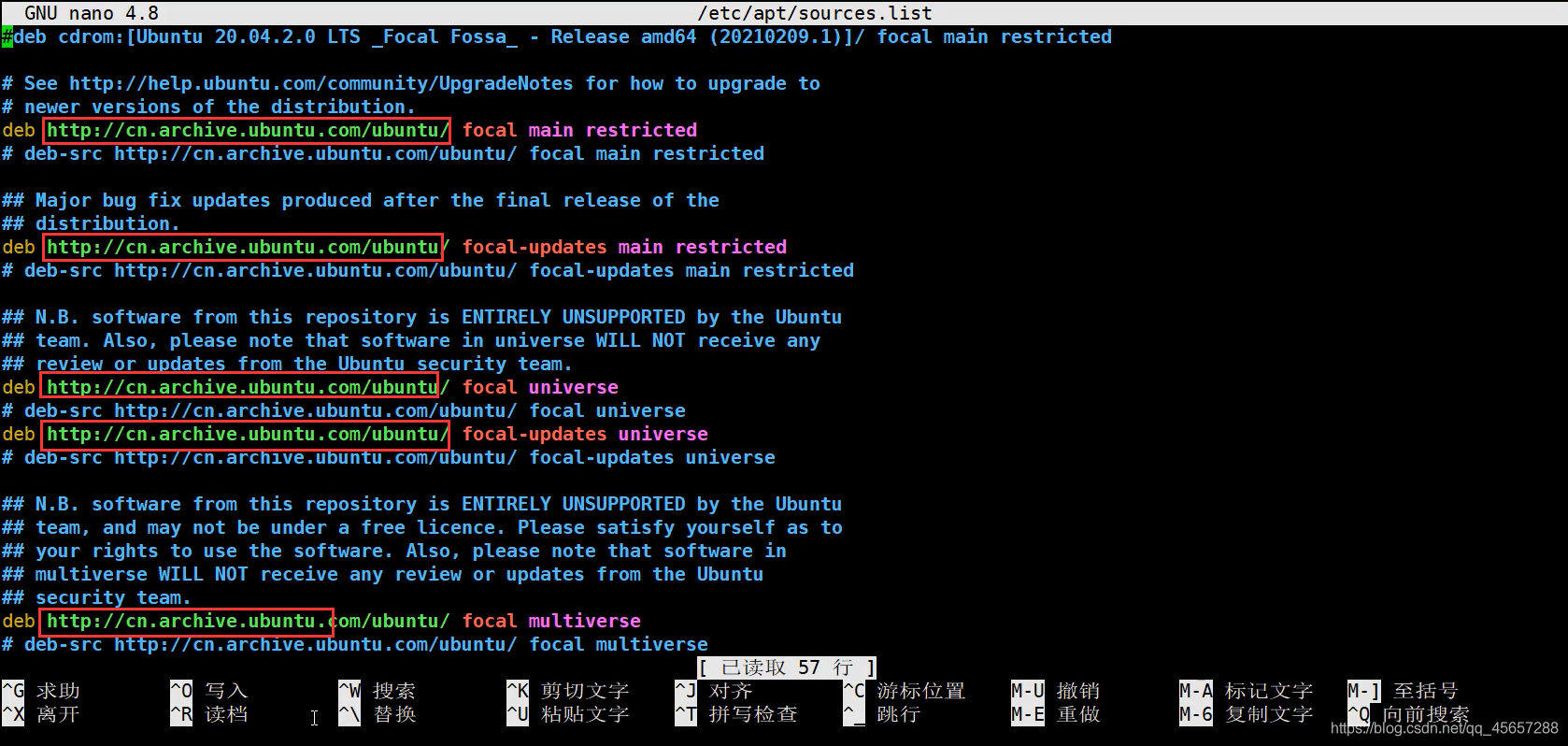
- 輸入命令列
sudo nano /etc/apt/sources.list

- 開始替換


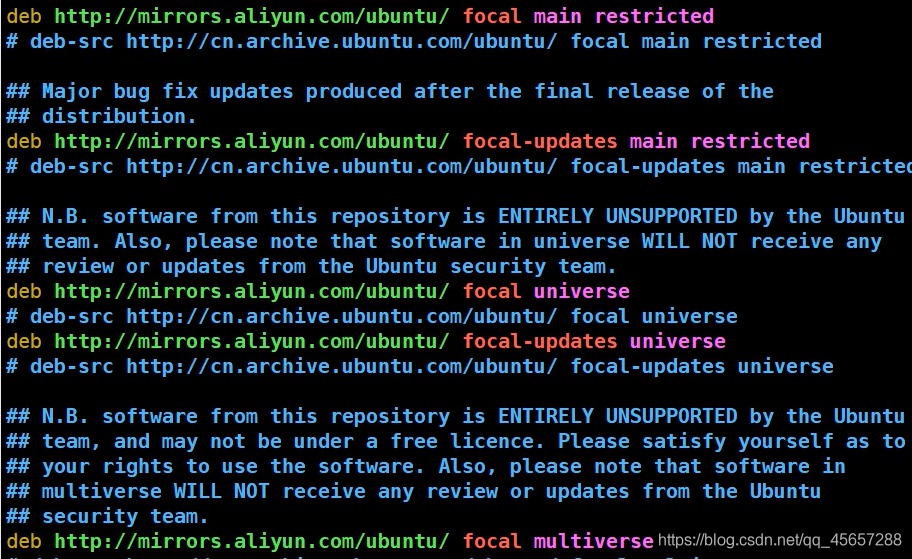
- 替換完畢
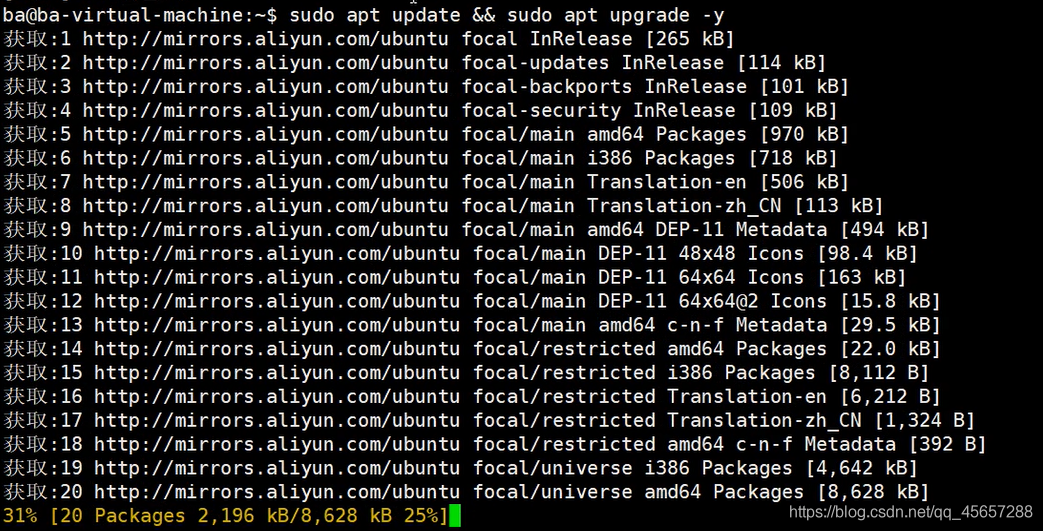
- 進行更新
sudo apt update && sudo apt upgrade
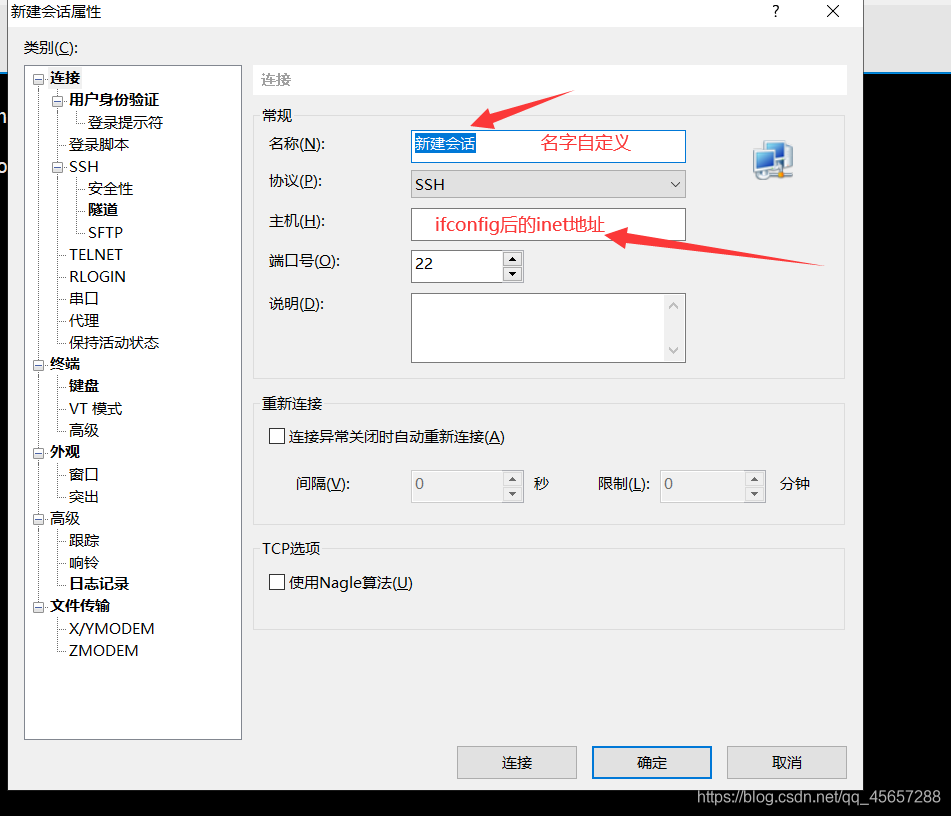
2.鏈接xshell
1.安裝SSH服務端
$ sudo apt-get install openssh-server
2.鏈接xhsell
3.安裝JAVA環境
- 安裝jdk
sudo apt install openjdk-8-jdk -y
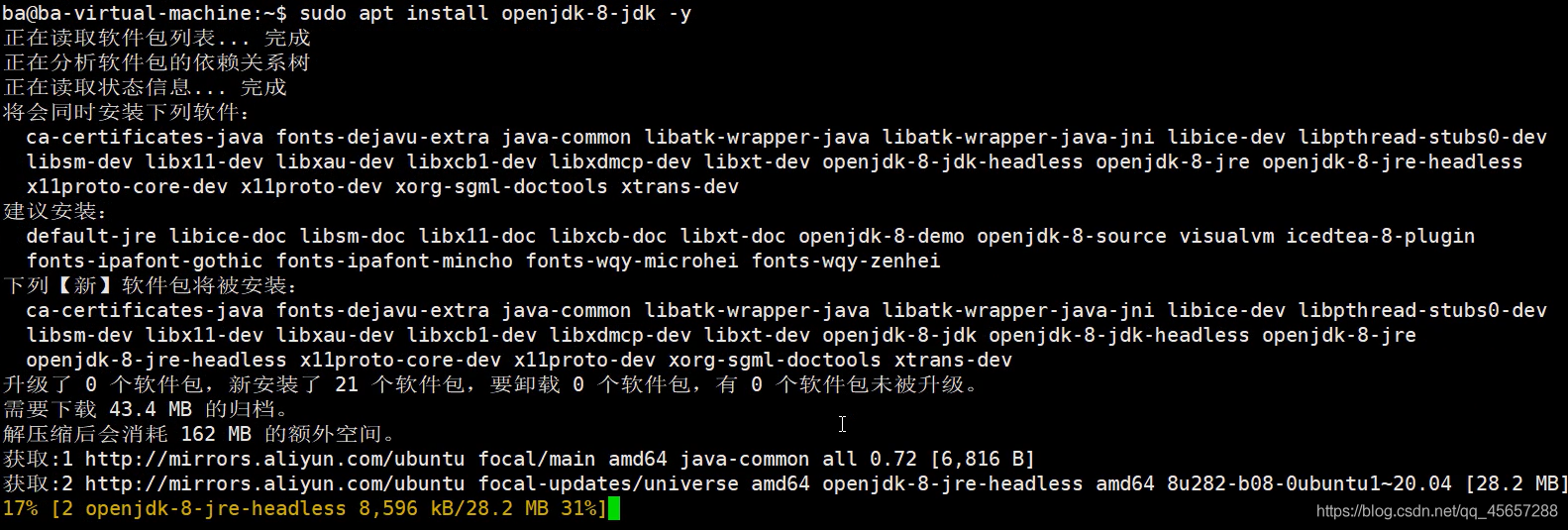
- 配置環境變數

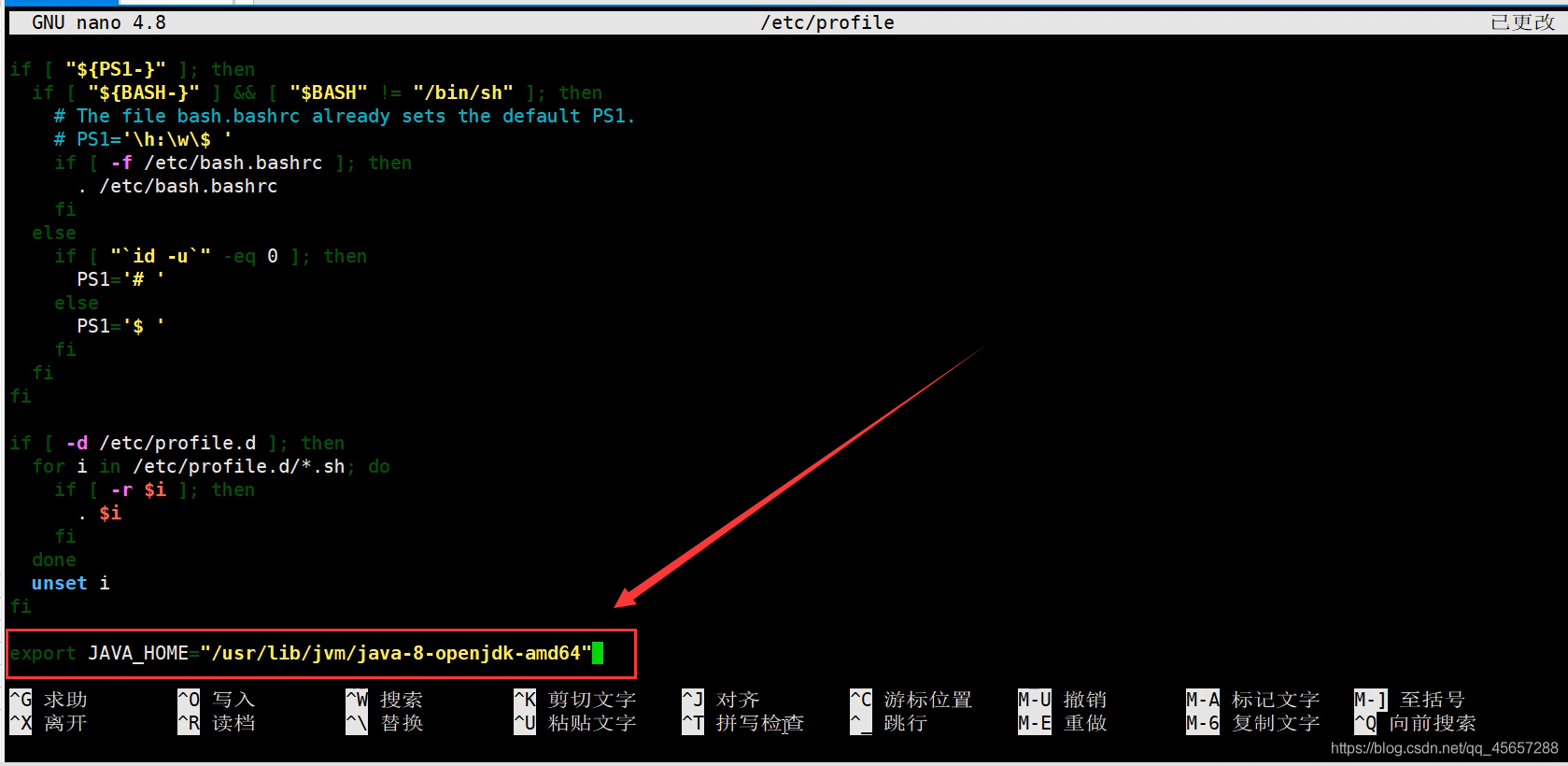
- 添加完之后,更新環境變數
1.# 更新環境變數
2.source ~/.bashrc
- 配置成功

4.創建Hadoop用戶
4.1創建新用戶并設定密碼
- 用戶名為hadoop,使用/bin/bash作為shell
$ sudo useradd -m hadoop -s /bin/bash

4.2為hadoop用戶添加管理員權限
sudo adduser hadoop sudo

5.設定SSH免密登錄
- Hadoop并沒有提供SSH密碼登錄的形式,所以需要將所有機器配置為無密碼登錄
5.1登錄localhost
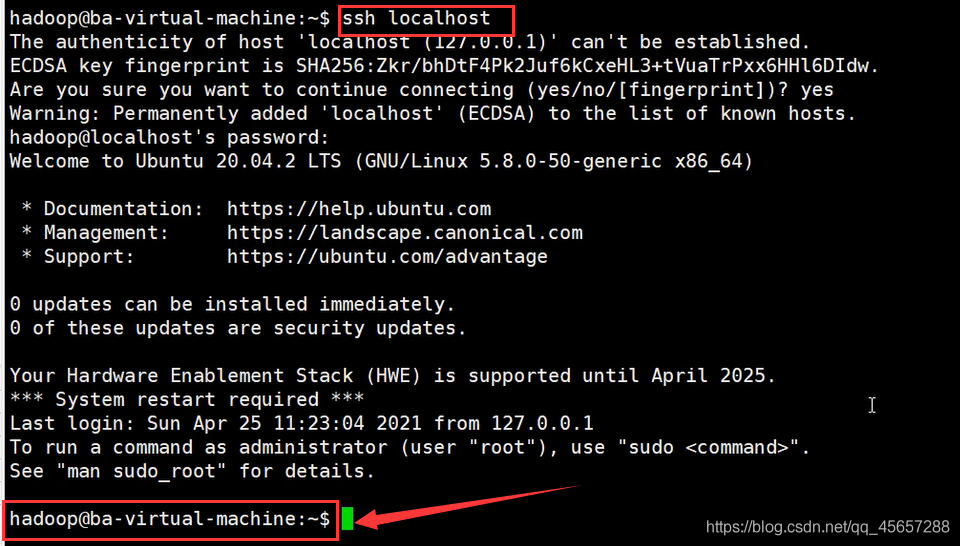
5.2設定為無密碼登錄

- 此時就可以使用
ssh localhost無密碼登錄
6.Hadoop安裝
- 這里為大家掛上網盤鏈接,也可以去官網下載地址點這里
- 鏈接:https://pan.baidu.com/s/1HiO6SPp9UmUlQEXHlvzU-A
- 提取碼:q7rd
6.1解壓到我們的Ubuntu系統中
- 先安裝
lrzsz(可能有的人裝完系統后,這條命令無法使用,可以執行的話請自動略過)
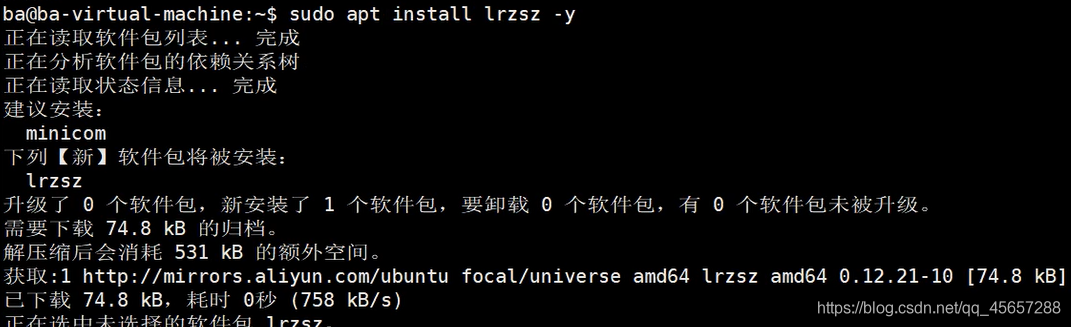
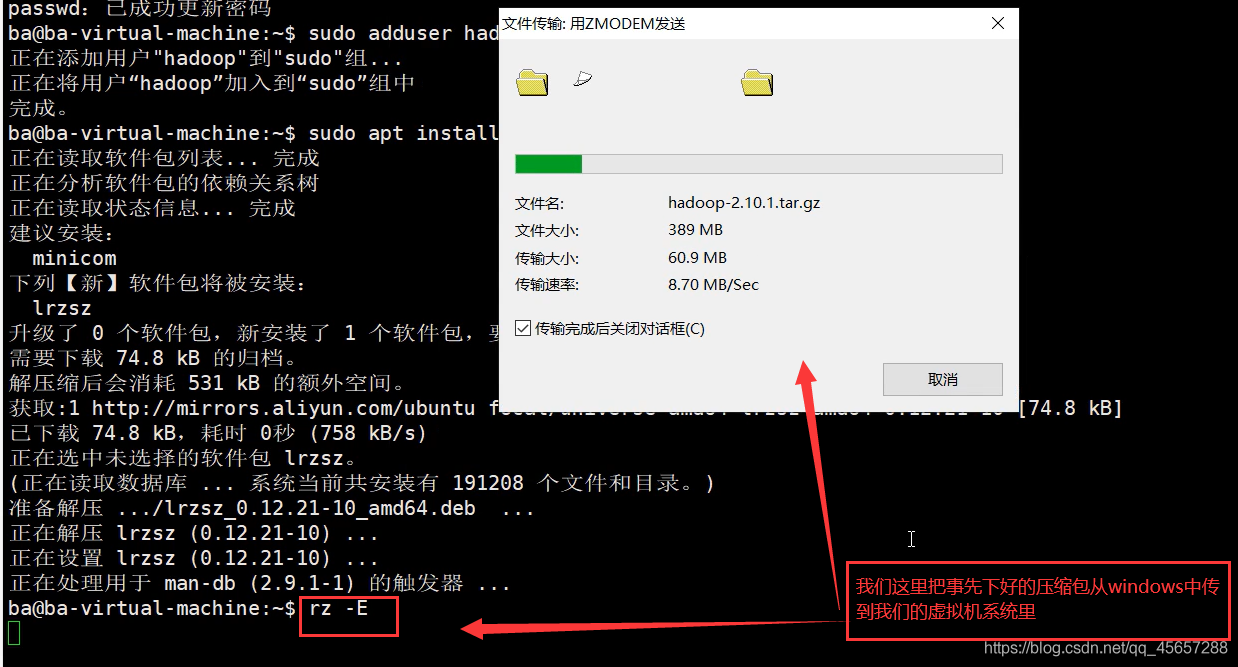
- 把下載好的
Hadoop壓縮包從windows系統中傳到我們的虛擬機系統中
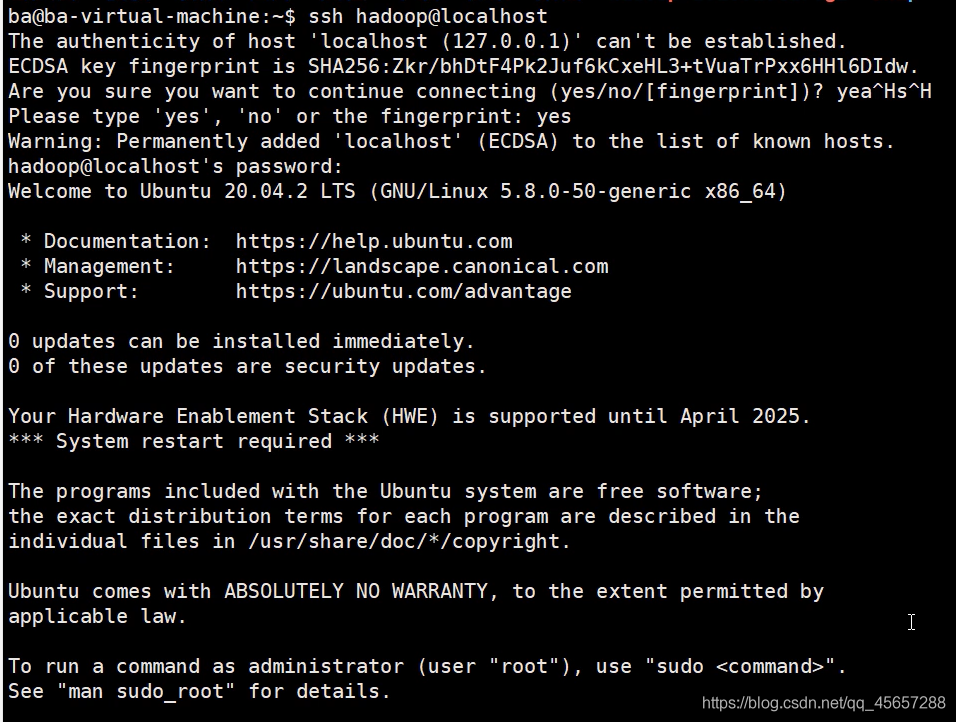
6.2切換到Hadoop用戶
ssh hadoop@localhost
6.3解壓Hadoop
- 因為我們剛剛是把壓縮包傳到了
ba這個用戶上,現在我們把它move到hadoop這個用戶上

- 再解壓
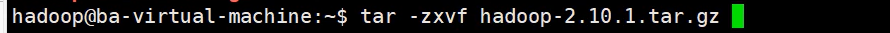
- 此時就轉移并解壓完成了

- 查看一下版本
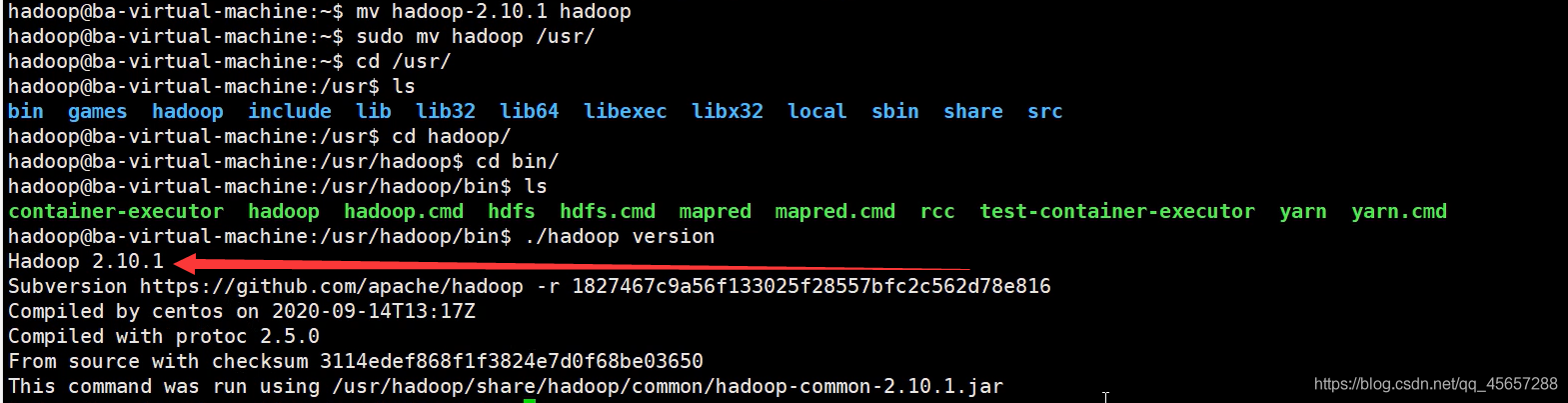
- 配置環境變數方便打開

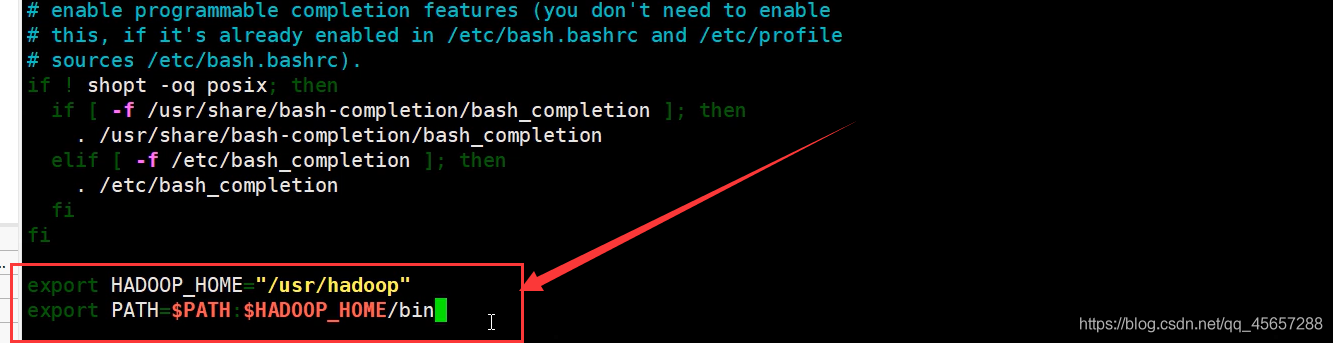
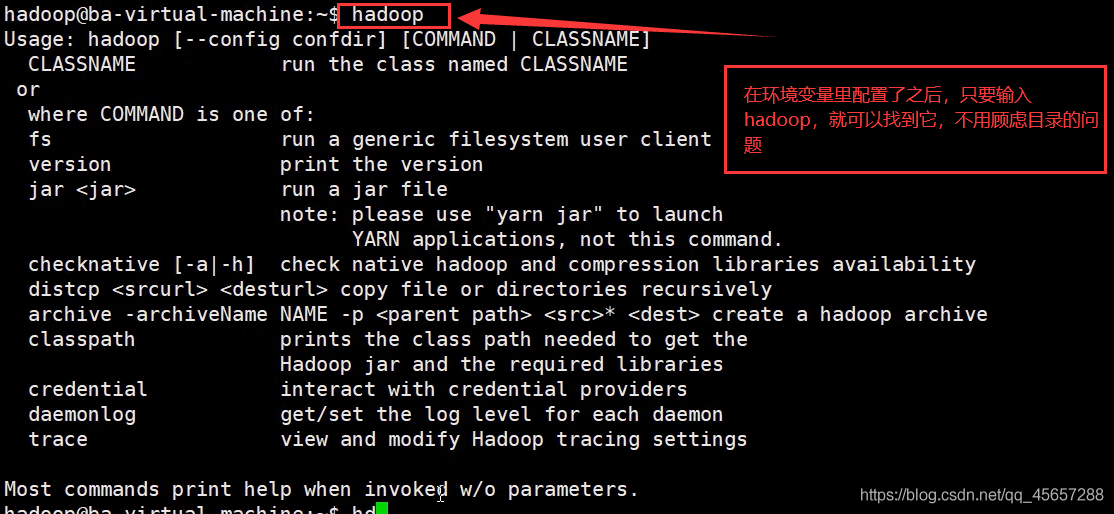
6.4偽分布式模式配置
- 在單個節點(一臺機器上)以偽分布式的方式運行
6.4.1修改組態檔
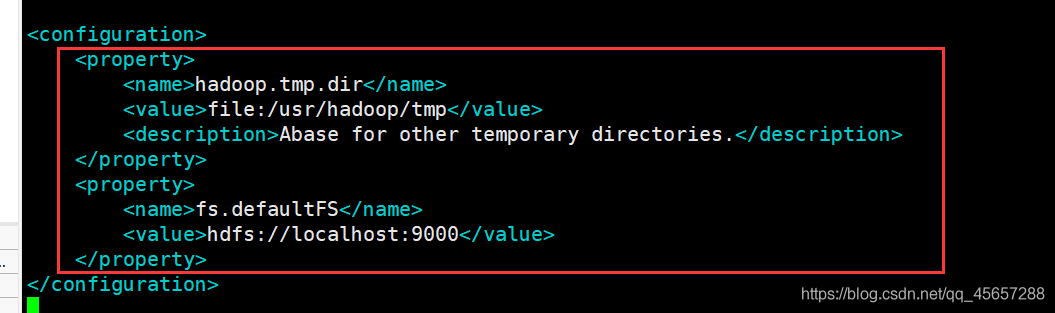
需要修改/usr/local/hadoop/etc/hadoop/檔案夾下的core-site.xml和hdfs-site.xml檔案

core-site.xml
將
<configuration>
</configuration>
改為
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

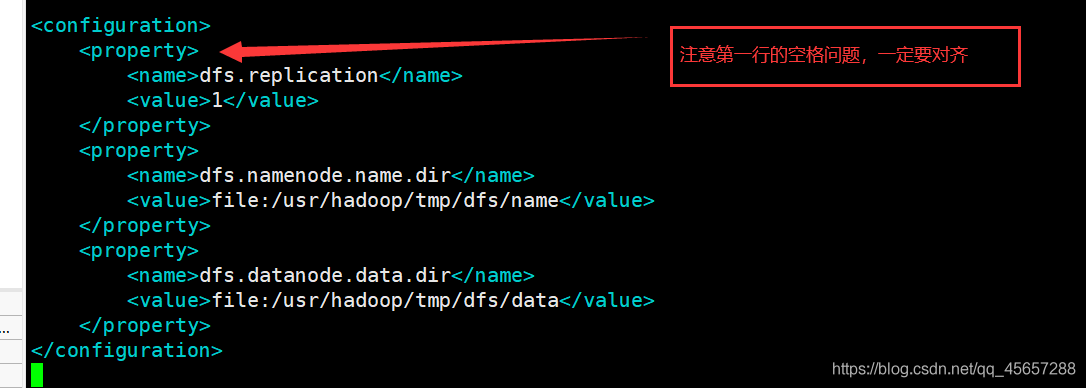
hdfs-site.xml
將
<configuration>
</configuration>
修改為
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/data</value>
</property>
</configuration>

6.4.2執行名稱節點格式化
$ cd /usr/hadoop
$ ./bin/hdfs namenode -format
6.5啟動hadoop
$ cd /usr/hadoop
$ ./sbin/start-dfs.sh

- 用
jps命令查看是否啟動成功

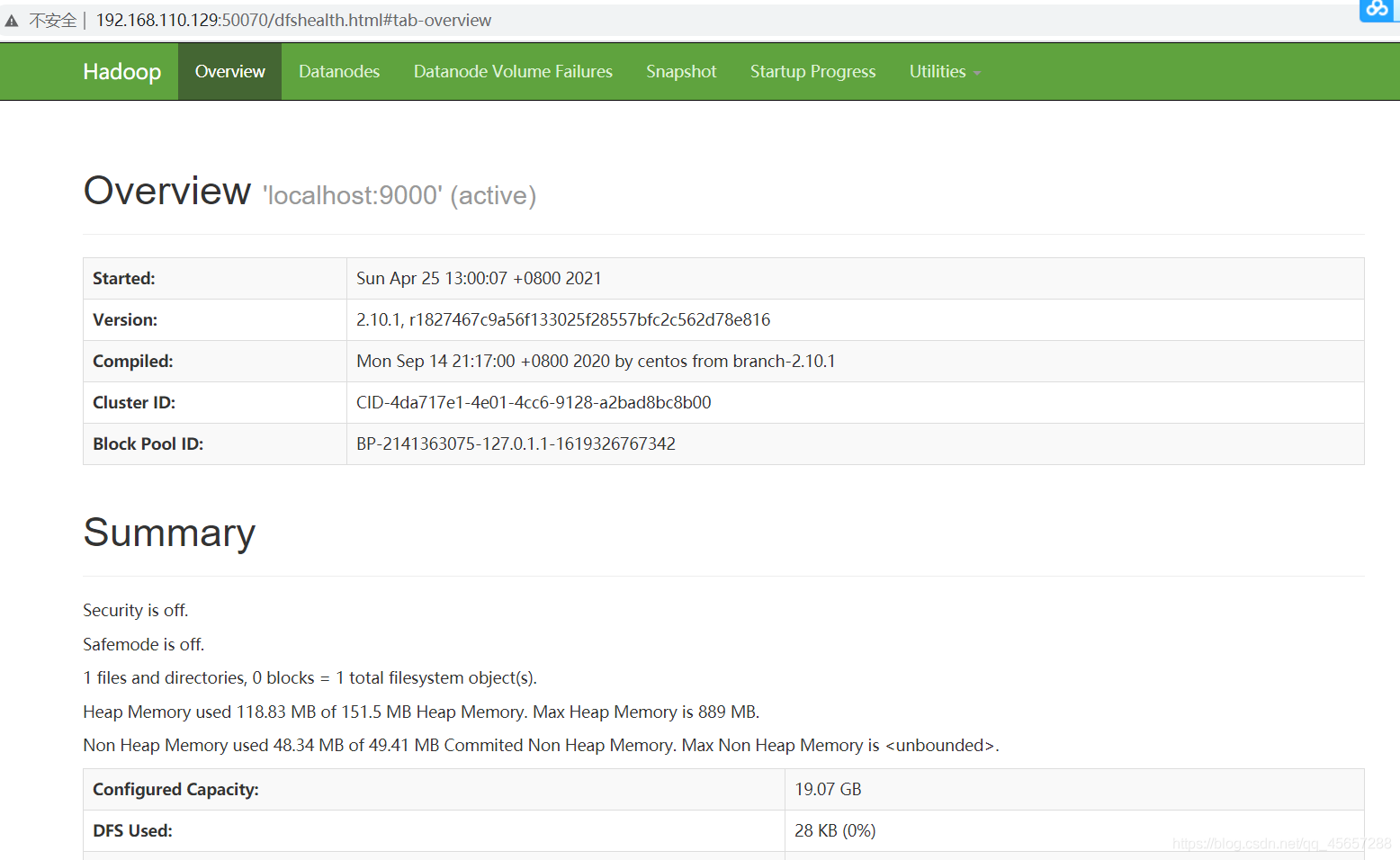
6.6使用瀏覽器查看HDFS資訊
ifconfig 命令即可查看自己的IP地址
6.7運行偽分布式實體
- 執行以下命令
cd /usr/hadoop
# 在HDFS中創建用戶目錄
./bin/hdfs dfs -mkdir -p /user/hadoop
#在HDFS中創建hadoop用戶對應的input目錄
./bin/hdfs dfs -mkdir input
#把本地檔案復制到HDFS中
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
#查看檔案串列
./bin/hdfs dfs -ls input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
#查看運行結果
./bin/hdfs dfs -cat output/*

- 如果要再次運行,需要洗掉
output檔案夾
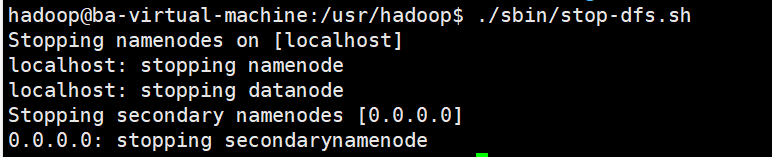
6.8關閉Hadoop
./sbin/stop-dfs.sh
6.9相關命令
$ cd /usr/hadoop
#格式化名稱節點 (這個命令只需只需一次)
$ ./bin/hdfs namenode -format
#啟動Hadoop
$ ./sbin/start-dfs.sh
#查看Hadoop是否成功啟動
$ jps
# 關閉Hadoop
$ ./sbin/stop-dfs.sh
# 洗掉 tmp 檔案,注意這會洗掉 HDFS中原有的所有資料
$ rm -r ./tmp
# 重啟
$ ./sbin/start-dfs.sh
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280590.html
標籤:其他
上一篇:Linux學習(一)