推薦系統模型之 DeepFM
Preliminary
在一些推薦系統中,為了追求總點擊次數最大化,會根據點擊率 (click-through rate, CTR) 來排序回傳給用戶的商品串列;而在廣告推薦的場景中,商品順序是通過"點擊率 x 單次點擊收益" (CTR x bid) 來給定的,因此預測點擊率,即評估用戶點擊某個推薦商品的可能性,在推薦系統中十分關鍵,
推薦系統的輸入一般包括 4 部分特征:
- 用戶特征 - 比如性別 (男/女),是否高消費群體,成為平臺用戶多久了等
- 商品特征 - 比如價格,類別等
- 用戶的實時行為 - 比如登陸平臺時長,商品瀏覽記錄等
- 背景關系特征 - 比如當前時間 (早上/晚上),商品的展示位置等
用戶是否會點擊某個推薦商品是以上 4 類特征共同作用的結果 (也許還有一些關鍵特征沒采集到,但這并不在考慮范圍內了),而點擊行為與各個特征之間往往并不是線性關系,特征之間也存在邏輯關聯,這被稱為特征互動 (feature interaction),即學習兩個或多個原始特征之間的交叉組合 (特征交叉,feature crosses),
此外,按照資料的連續性和離散性,特征又可分為:
- 類別特征 (categorical field)
- 連續特征 (continuous field)
其中類別特征以獨熱編碼表示,然后與連續特征拼接,組成特征向量 \(x\)
\[x = [x_{field_1}, x_{field_2}, \cdots, x_{field_j}, \cdots, x_{field_m}] \]其中 \(x_{field_j}\) 為第 \(j\) 個特征,由于經過了離散化處理,特征向量 \(x\) 表征為高維、極度稀疏,
Contribution
提出的 DeepFM 網路結構既能處理低維的特征交叉,又能處理高維的特征交叉,且不需引入特征工程,是端到端的訓練,
- 低維特征交叉 (low-order feature interaction) - 兩個及以下的特征交叉組合
- 高維特征交叉 (high-order feature interaction) - 兩個以上的特征交叉組合
什么是端到端訓練 (end2end training)?
傳統的機器學習程序往往由多個獨立的模塊組成,被人為的分解成了若干子問題,比如影像識別問題往往通過分治將其分解為預處理,特征提取和選擇,分類器設計等若干步驟,每個步驟的結果好壞會影響到下一步驟,從而影響到整個訓練的效果,而在某一子問題上達到最優,也不一定能取得全域最優解,這是非端到端的,
深度學習的模型在訓練程序中,從輸入端喂入資料,到輸出端輸出預測結果,然后與真實值比較得到一個誤差,這個誤差會在模型中的每一層傳遞 (反向傳播),每一層的表示都會根據這個誤差來做調整,直到模型收斂或達到預期的效果才結束,整個程序可視為一個整體,這就是端到端,
而由誤差理論知道,誤差傳播的途徑本身會導致誤差的累積,分為多個模塊一定會導致誤差累積,因此端到端訓練能減少誤差傳播的途徑,聯合優化,
Methodology
DeepFM 采用了一種并行的結構,使用 FM (Factorization Machine) 學習低維的特征交叉,同時通過一個 DNN 來組合高維的特征交叉,兩個組件使用相同的輸入和嵌入向量,
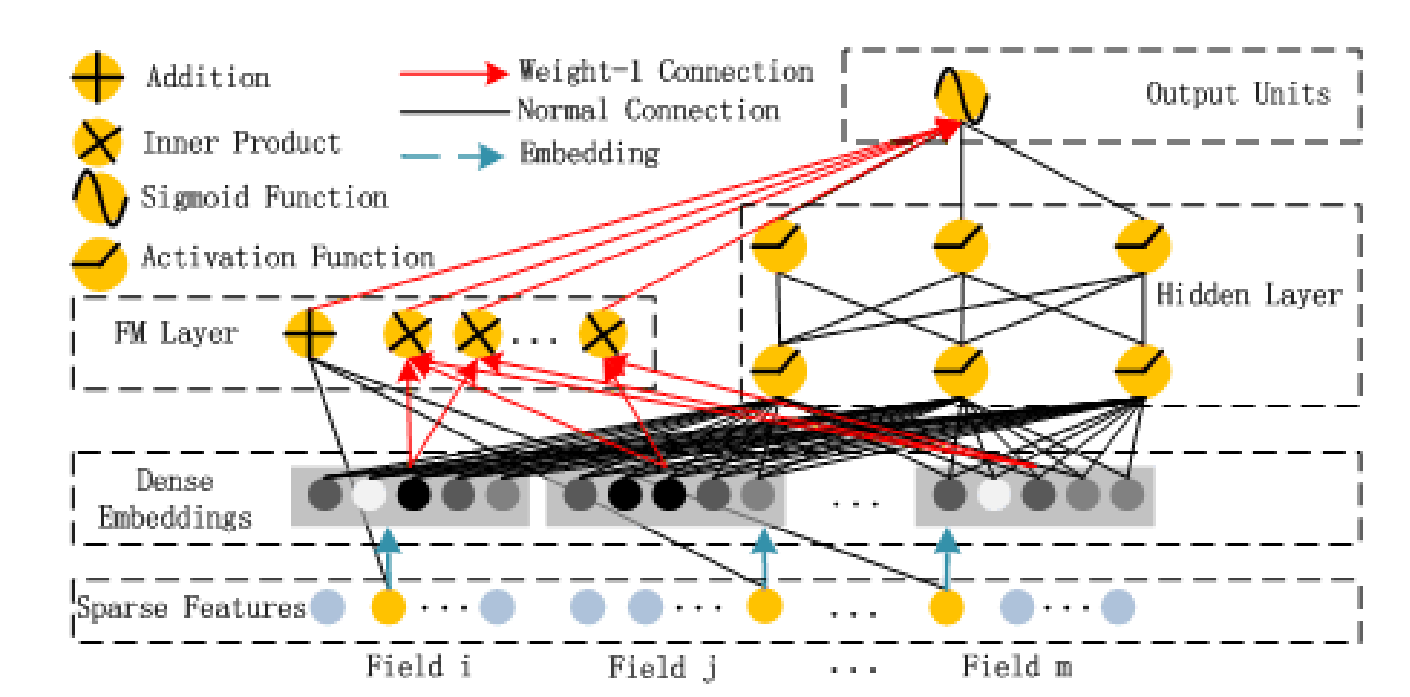
因此 CTR 的預測值可表示為:
\[\hat{y}=sigmoid(y_{FM}+y_{DNN}),\ \hat{y} \in \{0,1\} \]其中 \(y_{FM}\) 為 FM 部分的輸出,\(y_{DNN}\) 為 DNN 部分的輸出,這里可以加上一個偏置項 bias 來調整輸出,也可不用引入這樣的計算節點,因為 FM 和 DNN 兩個組件中都包含了各自的 bias 項,
FM Component
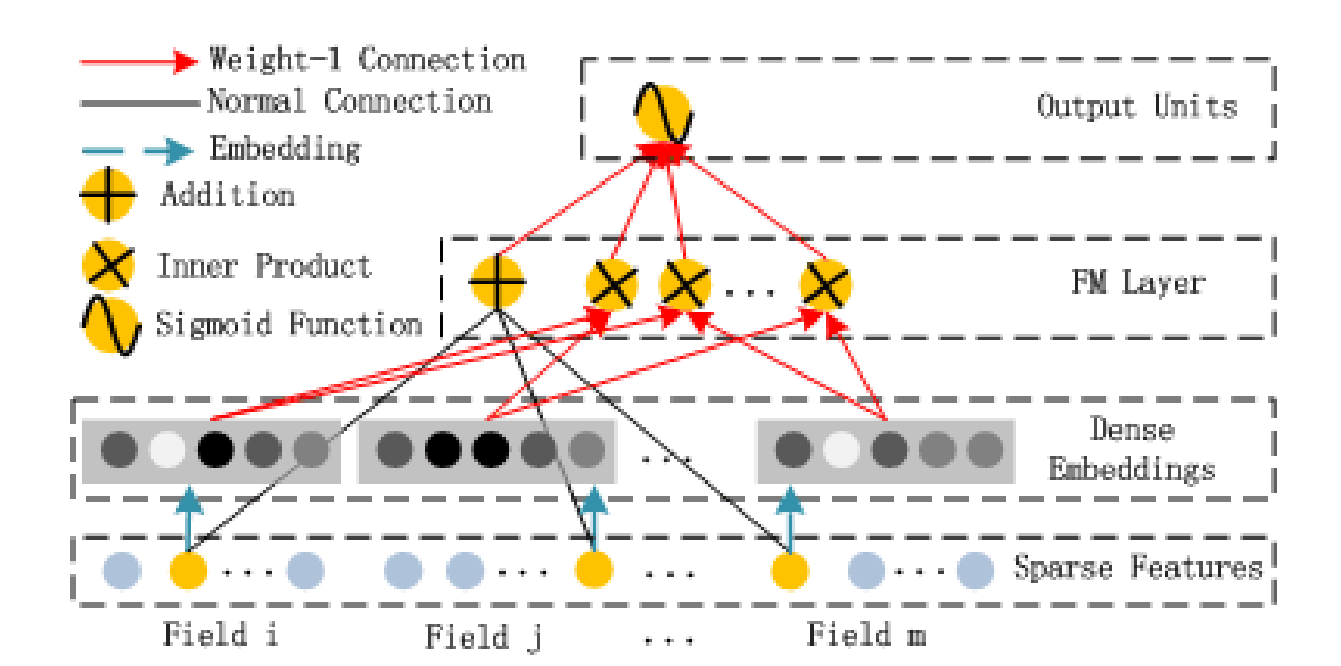
FM 組件被用來學習低維的特征交叉 (order-1 and order-2),有
\[y_{FM} = w_0 + \langle W, X \rangle + \sum_{i=1}^{n} \sum_{j=i+1}^n \langle V_i, V_j \rangle x_i x_j \]其中 \(w_0\) 為偏置項, \(X,W \in \mathbb{R}^{n\times1}\), \(V\) 為特征潛在向量 (feature latent vector) 且 \(V \in \mathbb{R}^{n\times k}\)
FM 模型原理
不同于多元線性回歸模型
\[\hat{y} = W^T X = w_0 + \sum_{i=1}^n w_i x_i \]只考慮了特征之間的線性關系 (尤其在特征向量極為稀疏的場景中刻畫能力不強),
FM 對特征進行二項組合,引入新的特征,從而挖掘到了更加隱秘的資訊,
\[\hat{y} = w_0 + \sum_{i=1}^n w_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^n w_{i,j} x_i x_j \]其中特征引數 \(w_{i,j} \in \mathbb{R}^{n \times n}\),而由于特征可能非常稀疏,比如 \(n\) 的取值在百萬以上,這導致特征交叉后得引數數量極為龐大,需要難以計數的訓練樣本才能保證演算法收斂,為了降低運算開銷,FM 又引入了特征潛在向量 \(V\) 來計算特征引數:
\[w_{i,j} = \langle V_i, V_j \rangle \]其中 \(V_i, V_j \in \mathbb{R}^{n \times k}\),\(k\) 為超引數,不需要設定得非常大,從而大大減少了特征引數的數量,
以上演算法的時間復雜度為 \(O(n^2)\),還可通過變形推導進一步優化至 \(O(n)\):
\[\begin{aligned} &\quad \sum_{i=1}^n \sum_{j=i+1}^n \langle V_i, V_j \rangle x_i x_j \\ &= \frac{1}{2}\Big(\sum_{i=1}^n \sum_{j=1}^n \langle V_i, V_j \rangle x_i x_j - \sum_{i=1}^n \langle V_i, V_i \rangle x_i x_i \Big)\\ &= \frac{1}{2}\Big( \sum_{i=1}^n \sum_{j=1}^n \sum_{f=1}^k v_{i,f} \cdot v_{j,f}\cdot x_i \cdot x_j - \sum_{i=1}^n\sum_{f=1}^k v_{i,f}\cdot v_{i,f} \cdot x_i \cdot x_i \Big) \\ &= \frac{1}{2}\sum_{f=1}^k \Big (\big ( \sum_{i=1}^n v_{i,f}\cdot x_i \big) \big( \sum_{j=1}^n v_{j,f}\cdot x_i\big) - \sum_{i=1}^n v_{i,f}^2 \cdot x_i^2 \Big) \\ &= \frac{1}{2}\sum_{f=1}^k\Big(\big( \sum_{i=1}^n v_{i,f}\cdot x_i \big)^2 - \sum_{i=1}^n v_{i,f}^2 \cdot x_i^2\Big) \end{aligned} \]從而有:
\[\hat{y} = w_0 + \sum_{i=1}^n w_i x_i + \frac{1}{2}\sum_{f=1}^k\Big(\big( \sum_{i=1}^n v_{i,f}\cdot x_i \big)^2 - \sum_{i=1}^n v_{i,f}^2 \cdot x_i^2\Big) \]這部分的實作細節:
""" https://github.com/Leavingseason/OpenLearning4DeepRecsys/deepFM.py """ # bias preds = bias # order-1 feature intreaction preds += tf.sparse_tensor_dense_matmul(_x, w_linear, name='contr_from_linear') # ... # order-2 feature interaction preds = preds + 0.5 * tf.reduce_sum(tf.pow(tf.sparse_tensor_dense_matmul(_x, w_fm), 2) - tf.sparse_tensor_dense_matmul(_xx, tf.pow(w_fm, 2)), 1, keep_dims=True)
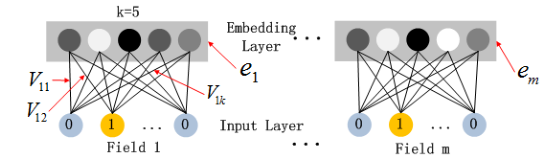
Embedding Layer
Embedding 層的作用是將高維的稀疏特征壓縮成低維的稠密向量,
- 每個稀疏特征的長度不同,但它們的嵌入向量長度相同 (均為 k)
- 在 FM 組件中引入的特征潛在向量 \(V\) 也被用來壓縮特征,作為映射時的權重向量
# feature latent vector
w_fm = tf.Variable(tf.truncated_normal([feature_cnt, dim], stddev=init_value / math.sqrt(float(dim)), mean=0), name='w_fm', dtype=tf.float32)
# ...
# embedding layer
w_fm_nn_input = tf.reshape(tf.gather(w_fm, _ind) * tf.expand_dims(_values, 1), [-1, field_cnt * dim])
如何處理連續性特征?
Deep Component
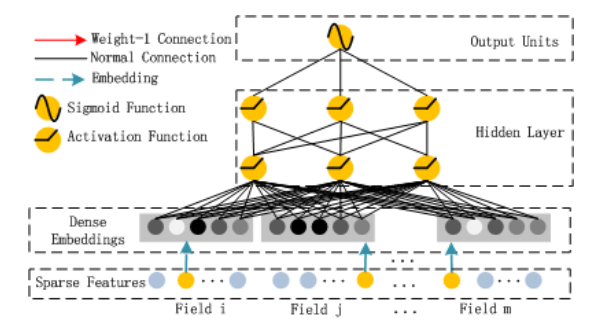
這部分是一個典型的神經網路,從代碼上看,它由 2 層全連接層組成,
# y_hat = sigmoid(y_FM + y_DNN)
preds += nn_output
# ...
preds = tf.sigmoid(preds)
Reference
以下是寫作中所參考的資料:
[1] 吃透論文——推薦演算法不可不看的DeepFM模型
[2] 什么叫end-to-end learning?
[3] 什么是端到端的訓練或學習?
[4] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
[5] 想做推薦演算法?先把FM模型搞懂再說
[6] Factorization Machines
[7] OpenLearning4DeepRecsys
[8] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, IJCAI 2017
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280613.html
標籤:其他
上一篇:使用rider除錯lua
下一篇:0701-資料處理