泰迪杯 A 題
- 資料讀取
- 分析資料
- 資料型別和缺失值
- 缺失值處理
- 畫圖與統計描述
- 計算各列的統計資訊
- 轉換資料集(省記憶體走起)
- 畫圖
- KDE 圖
- 頻率柱狀圖
- 資料預處理
- 對 int、類別 型別的資料,查看其取值個數:
- 報告截止日期 vs 截止日期?——單位是天嗎?
- 第一問(以‘制造業’為例)
- 給資料加上行業標簽
- 離群資料處理
- 標準化處理
- 篩選指標
- 根據偏相關系數進行篩選
- 配合 FLAG 篩選
- 原始資料?
- 不變?顯著大于?
- 機器學習模型?
- 特征權重?
- 結果
- 第二問
- 代碼和檔案
文章用到的 Python 第三方庫有:
import pandas as pd
import numpy as np
import dask.array as da
import dask.dataframe as dd
謝絕互粉、互贊、互拍馬屁 那些一眼沒看就亂吹的,請自覺繞道,本人**不會回粉**的 本人是學生,請不要用抱團內卷的那一套影響我,謝謝 有問題請在評論區留言
如果本篇博文對您有所幫助,請不要吝嗇您的點贊 ??
資料讀取
原本這里采用 dask 庫讀取 csv 檔案,因為 dask 庫的好處是:1、分塊;2、并行化計算
然而:我先嘗試了用 pandas 讀取資料,讀入整個 CSV 占用記憶體 76 MB,算是比較小的了,鑒于其可直接放入記憶體之中,因此就不需要分塊了,因為反而會因為與硬碟互動,消耗 CPU 資源,
經過測驗,用 dask 讀取資料,雖然可以分塊,但需要啟動并行化客戶端,所以占用記憶體共 490 MB,而用 pandas 讀取,僅占用了 230 MB,因此,選擇 pandas 庫,
%%time
df = dd.read_csv(r'../泰迪杯/泰迪杯 A 題/附件/附件2.csv')
df # 可視化頭五行資料
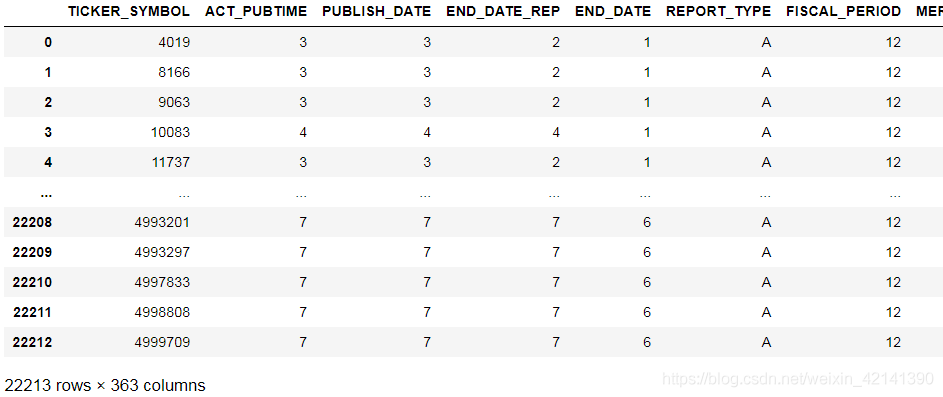
(補:本人讀取完資料后,CPU 已經占用 78% 了… 慚愧)
分析資料
資料型別和缺失值
print(df.dtypes) # 查看各行的型別
各列的型別如下所示:
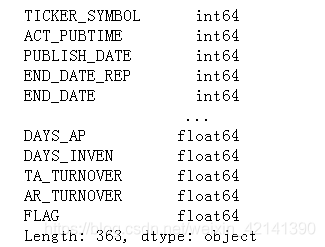
為何要沒事找事,列印出資料型別呢?為了節省記憶體呀…,這里先按下不表,
再看資料各列的缺失值數量如何:
print(df.isna().sum()) #缺失值計算
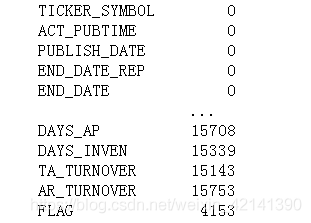
經過詳細分析,可以看到附件二還是挺良心的,一些基本的資料基本沒有缺失值,但一些型別為 float 的資料,就有較多的缺失值了,那些型別基本為 int 的資料,沒有缺失值,如下圖所示:
for i in range(10):
print(f'列名為{df.columns[i]} 包含的缺失值個數為:{df.iloc[:,i].isna().sum()}')

再看, FLAG(有無造假標簽)居然也有缺失值,結合題目,那些帶有缺失值的, 應該是需要我們在第二題、第三題中求解的 ,所以,在資料預處理完畢后,我們還需要對表格,根據有無 FLAG 進行拆分,
先來計算一下有多少資料沒有 FLAG 吧:

可以看到,有 4153 條資料是沒有 FLAG 的,
缺失值處理
除了 FLAG 列以外,由于那些資料型別為字串(object)的列不包括缺失值,因此,用 0 代替缺失值,不會造成過大影響,且能與現有的資料情況相匹配,本人曾將資料轉為 excel 表格,并從中發現,有些資料雖然沒有缺失值,但卻用 0 去代替了,如下圖所示:
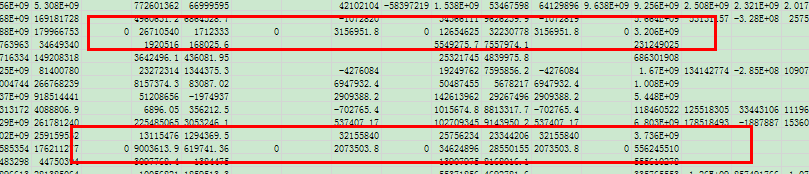
所以,這里也用 0 去替代缺失值(除了 FLAG 除外)
畫圖與統計描述
計算各列的統計資訊
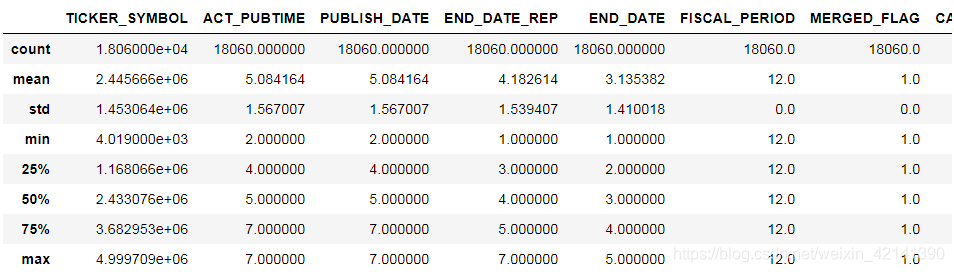
我們從中得出如下資訊:
- 由于股票代碼最大編號>65536,所以在接下來的記憶體轉換中,要用 uint64,
- 各列的量綱、以及方差都各不相同,需要我們進行標準化
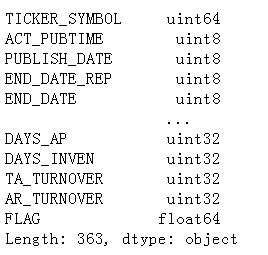
轉換資料集(省記憶體走起)
根據之前的各列的型別輸出,我們可以在資料存盤上再拉緊褲腰帶,我們修改資料集的型別:
畫圖
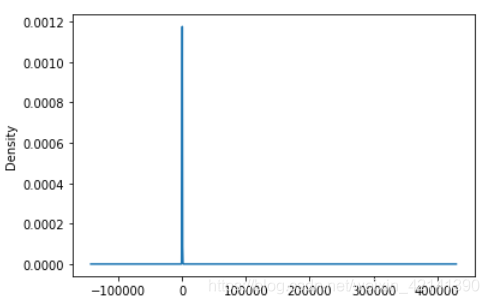
KDE 圖
挑選 TFA_TURNOVER 列畫出資料的 KDE 圖(密度分布圖):
頻率柱狀圖
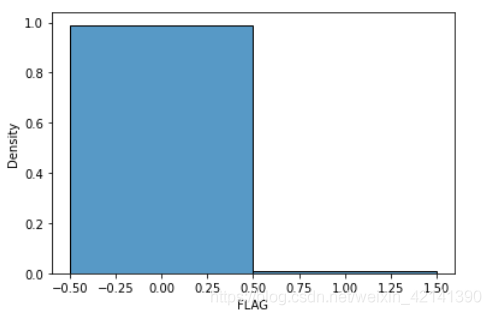
從這張圖中可以看出:造假的企業和沒有造假的企業,在數量上極度不均衡!
資料預處理
對 int、類別 型別的資料,查看其取值個數:
將附件三轉為 Python 的字典變數,方便之后操作:
df_mean = pd.read_excel(r'../泰迪杯/泰迪杯 A 題/附件/附件3.xlsx', engine='openpyxl').iloc[:,:-1]
df_mean = df_mean.set_index('欄位名').T
df_mean_tmp = df_mean.to_dict('list')
df_mean = {}
for k,v in df_mean_tmp.items():
df_mean[k] = v[0]
df_mean # 輸出結果
del df_mean_tmp # 釋放記憶體
然后,查看資料型別為 int 和 category 的那些列,他們的取值共有多少個,以及列出他們的取值:
for i in ['ACT_PUBTIME','PUBLISH_DATE','END_DATE_REP','END_DATE','REPORT_TYPE',
'FISCAL_PERIOD','MERGED_FLAG','ACCOUTING_STANDARDS','CURRENCY_CD']:
ch_mean = df_mean[i]
print(f'列 {i} 即 {ch_mean} 的取值個數共{len(df[i].unique())}個.\n取值為:{list(df[i].unique())}')
結果如下:
列 ACT_PUBTIME 即 實際披露時間 的取值個數共6個.
取值為:[3, 4, 2, 5, 6, 7]
列 PUBLISH_DATE 即 發布時間 的取值個數共6個.
取值為:[3, 4, 2, 5, 6, 7]
列 END_DATE_REP 即 報告截止日期 的取值個數共7個.
取值為:[2, 4, 3, 1, 5, 6, 7]
列 END_DATE 即 截止日期 的取值個數共6個.
取值為:[1, 2, 3, 4, 5, 6]
列 REPORT_TYPE 即 報告型別 的取值個數共1個.
取值為:[‘A’]
列 FISCAL_PERIOD 即 會計區間 的取值個數共1個.
取值為:[12]
列 MERGED_FLAG 即 合并標志:1-合并,2-母公司 的取值個數共1個.
取值為:[1]
列 ACCOUTING_STANDARDS 即 會計準則 的取值個數共1個.
取值為:[‘CHAS_2007’]
列 CURRENCY_CD 即 貨幣代碼 的取值個數共1個.
取值為:[‘CNY’]
從這里大家可以看出什么呢?
- 造假標準肯定和那些取值僅一個的無關,也即可以直接排除:{ 報告型別、會計區間 、合并標志、會計準則、貨幣代碼 }
- 第二題中的“第六年”,到底指的是:ACT_PUBTIME,還是 PUBLISH_DATE? 個人覺得應取發布時間,這點大家可以在論文中宣告一下,
- 洗掉完=={ 報告型別、會計區間 、合并標志、會計準則、貨幣代碼 }==后,那些型別為 category 的列就沒有了,所以,在后面的操作中,不需要進行 one-hot 編碼,
大家也可以按照同樣的方法,去判斷權益乘數,但其取值有 6000+ 多個呢,所以就別將他轉為類別變數了,
反手就把上面沒用的列刪掉:
no_relation_cols = ['REPORT_TYPE','FISCAL_PERIOD','MERGED_FLAG','ACCOUTING_STANDARDS','CURRENCY_CD']
df_with_flag = df_with_flag.loc[:,~df_with_flag.columns.isin(no_relation_cols)]
df_without_flag = df_without_flag.loc[:,~df_without_flag.columns.isin(no_relation_cols)]
然后,大家請思考:考慮那些沒被洗掉的日期資料,他們可以轉換為 category 型別嗎? 這個問題還是先掛著,下一節分曉,
這里,我們來看到,發布時間有 2-7 年,那么,是不是每一個企業,都有 2-7 年的資料呢?
這個問題還是比較重要的,最完美的情況是,每一家企業都有 2-7 年的資料,這種情況下,在接下來的分析中,就不得不
考慮資料是否有時序性了,換句話說,今年造假,是否和去年的資料有關(即使去年沒造假),
基于這個理由,我們首先來看看,每一個企業是否真的都有2-7年的資料:
df.groupby(by='TICKER_SYMBOL').count()
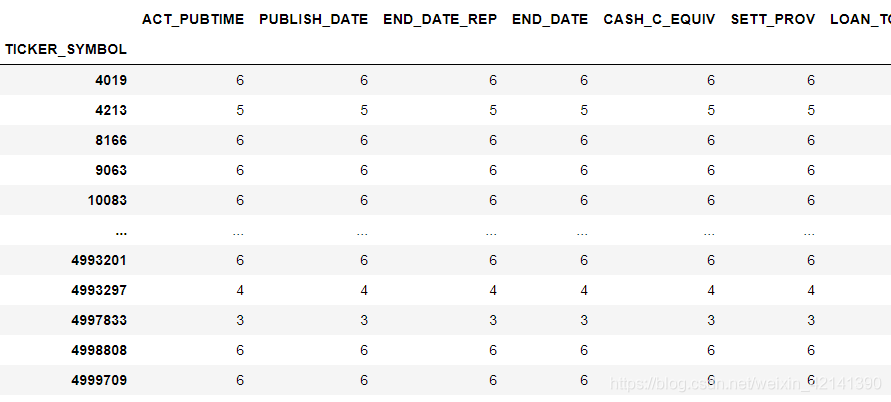 很讓人瑟瑟發抖的是:大部分的企業都有 6 組資料,
7
?
2
+
1
=
6
7-2+1 = 6
7?2+1=6,到底什么成分,你們應該知道了,所以,記住這個結論,之后我們解第一問、第二問、第三問,都必須考慮是否有時序性!
很讓人瑟瑟發抖的是:大部分的企業都有 6 組資料,
7
?
2
+
1
=
6
7-2+1 = 6
7?2+1=6,到底什么成分,你們應該知道了,所以,記住這個結論,之后我們解第一問、第二問、第三問,都必須考慮是否有時序性!
不過,結合常識,這個時序性肯定是逃不掉的,
報告截止日期 vs 截止日期?——單位是天嗎?
報告截止日期與截止日期,咋看之下好像是一樣的,但仔細觀察可以發現:報告截止日期總是大于截止日期,我們驗證一下:
np.any(df.END_DATE_REP > df.END_DATE)
結果為 True !
換句話說:我們是否可以理解為,截止日期是規定的審計結束日期,而報告截止日期是審計結束之后,審計單位整理報告上報的日期?
如果是這樣,那么(報告截止日期-截止日期),即企業拖拉癥狀,應該與截止日期無關才對,即兩者作為隨機變數應是相互獨立的,于是,我們就可以用列聯表的方式,用統計檢驗的方法,來考察考察兩者的分布,是否是獨立的,
若獨立,我們就可以將報告截止日期、截止日期,用(報告截止日期-截止日期)(即企業拖拉情況)來替換,因為一個企業拖拉的程度,更能夠體現出這個企業造假的態度,
這樣子的變換看上去似乎沒有太大意義,但要知道,我們的資料只有 2W,而行業大約 20 個,每一個企業還有 300+ 的列數,平均下來,每一列僅有 3 個資料(不嚴謹的說法),因此資料的密度是非常低的,能夠降低列數,不單單可以提高效率,也可以提高準確率!!!
閑話少說,我們取原假設為:截止日期、(報告截止日期-截止日期)(下面用 Δ \Delta Δ代替)兩個變數相互對立,首先構建用于獨立檢驗的列聯表:
df_for_table = df.loc[:,['END_DATE_REP','END_DATE']]
df_for_table['Delta'] = df_for_table.iloc[:,0] - df_for_table.iloc[:,1]
df_for_table = df_for_table.groupby(by=['END_DATE','Delta']).count()
df_for_table
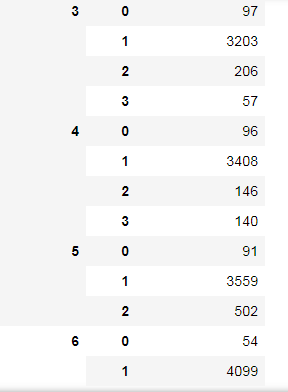
從結果表中,我們可以看出,END_DATE 取 5 和 6 的時候(此時單位我們還不知,可能是天、月、年), Δ \Delta Δ 最大值分別是 2 和 1,即,END_DATE_REP 的最大取值為 7,仔細回憶,我們的發布時間、實際披露時間的最大值也是為 7 的,
于是,不難得出,END_DATE 和 END_DATE_REP 的單位因為年!
為了分析方便,我們將 END_DATE 為 5 和 6 的洗掉,并構建列聯表:
obs = np.zeros((4,4))
for i in range(4):
tmp = df_for_table[4*i:4*(i+1)].values.reshape(-1)
obs[i,:] = tmp
obs

構建好列聯表后,進行假設檢驗,結果如下:
檢驗統計量的值為 3521.1458225666274
p-值為 0.0
根據假設檢驗的結果,由于 p值為 0,所以很遺憾,我們需要拒絕原假設,并有100%的把握,可以說拖延時間 Δ \Delta Δ 和截止時間是相關的,
不過,為了提高模型的辨識度(資料密度實在太低了),我們可以用 Δ \Delta Δ 去替換 END_DATE_REP,
同上述分析,我們也需要考慮 PUBLISH_DATE 和 ACT_PUBTIME 之間的關系,來判斷兩者之間,是不是實際發布時間,大于等于發布時間?
np.any(df.ACT_PUBTIME >= df.PUBLISH_DATE)
結果是 True,于是,我們是否也可以列一個發布拖延時間:(實際發布時間-發布時間),
如果判斷出發布拖延時間,與發布時間,作為隨機變數是相互獨立的,那么,不僅可以為我們省下一列,而且,如果我們不用考慮資料的時序性,至少在做簡單分析的時候可以這樣,之所以可以不考慮時序性,是因為延遲時間,一定程度上代表了時序性的作用!
話不多說,先搭建一個列聯表,結果如下:
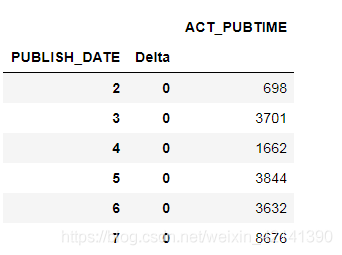
然而,從這個表可以看出,原來所有企業的實際發布時間,和發布時間都是相同的,不過也好,借此機會可以洗掉 ACT_PUBTIME 列,
df['Delta_Date'] = df['END_DATE_REP'] - df['END_DATE']
df.drop(['ACT_PUBTIME','END_DATE_REP'], inplace=True, axis=1)
同時我們也看到,PUBLISH_DATE 的取值為 2~7,應當是一個索引資料,用 SQL 語言的話說,它和 TICKET_SYMBOL 構成表格的主鍵,所以,不能將其轉為 category 型別,更不用說對他進行 one-hot 編碼了,
在接下來的問題中,它和股票代碼應是用來識別資料,不參與運算的,同時,它們兩個實際上對是否造假所起到的作用和資訊量,都包含在其他列里面了,所以,在之后的分析中,這兩列不參與分析,
但還是需要考慮,如果忽略了 PUBLISH_DATA(發布時間),那么就等于丟棄了資料的時序性,這樣好嗎?
第一問(以‘制造業’為例)
確定資料是否造假的決定指標,本質上是一個資料降維的問題,首先,為了便于資料的處理,想要對資料進行標準化,
但在標準化前,首先應該考慮:資料標準化需不需要根據行業,采用不同的標準化基礎?還是將整個表格直接初始化?答案當然是前者,畢竟,不同行業間,我們很有理由認為量綱各不同,
給資料加上行業標簽
首先讀取附件1:
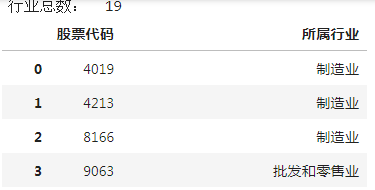
同時可以從附件1 中看出,給出的行業一共有 19 個,
要如何給資料附上標簽呢?這就要用到 SQL 里的 join 操作了,但要怎么 join 呢?是左連接、右連接,還是內連接?
由于有些企業沒有在附件一中有具體的分類,因此,可能有人再考慮用左連接的自然連接,但你要知道,問題二、問題三都是求其他行業的,所以如果你狠心一點,直接用 inner join(內連接),將那些沒有歸入行業的企業劃掉!!
附上標簽以后,就要著手標準化資料了,
準化的方式一般有兩種:
- 用最大值、最小值
- 用均值、方差
由于上述標準化都對離群值敏感,所以首先要排除離群資料:
離群資料處理
離群值資料,當然要以行業為單位考慮,畢竟,有些行業某個列的總體數值偏高,總不能把他們都刪了吧,
因為據分析,這些報表造假也好,詳細記錄的也好,應該都不會偏離正常值太多,但如果詳細記錄卻出現離群值的,一般是因為資料錄入出現錯誤,所以,在離群值識別的時候,我們要制定一個很寬松的標準,
然后,我們將離群資料洗掉!
這里采用的離群值識別演算法是:IQR 方法,若一整行中,若果全部行通過 IQR 診斷為離群值,則刪去,
標準化處理
這里采用均值、方差標準化處理,之所以采用這種方法,是因為最大、最小標準化難以體現資料的差異性,
但要注意,在這時候,要給資料分組了,也就是說,我們要根據有無 FLAG 將資料拆分成兩個部分,有 FLAG 的,用來分析,訓練機器學習模型,沒有 FLAG 的,用來解決問題,
同時,在標準化時,要根據行業分組進行,原因在于,每一個行業可能的量綱不同,
我們把資料拆分成兩部分:
- df_flag : 指那些帶有 FLAG 標簽的資料
- df_noflag:指那些 FLAG 為 NAN 的資料
然后,將 df_flag、df_noflag 按照行業,拆分成 19 個子集(行業共19個嘛),再對每一個子集進行標準化,
注意,在標準化的時候,要用 df_flag 計算均值、方差,然后再用所得的均值、方差來標準化 df_flag、df_noflag:
x
i
j
′
=
x
i
j
?
x
i
ˉ
s
t
d
(
x
i
)
x_{ij}^\prime = \frac{x_{ij}-\bar{x_i}}{std(x_i)}
xij′?=std(xi?)xij??xi?ˉ??
篩選指標
以后都會把輸入變數稱為特征哈1,
根據偏相關系數進行篩選
第一問叫我們找決定指標,而我們知道,一些指標(特征)自身相互決定,因此,或多或少帶有一定的冗余,所以在進行進一步地篩選之前,我們需要先洗掉多余的指標,
偏相關系數度量了兩個變數,在刨除其他變數后的線性相關特性2,所以,這里計算了指標將兩兩的相關性,構成一個偏相關系數矩陣:
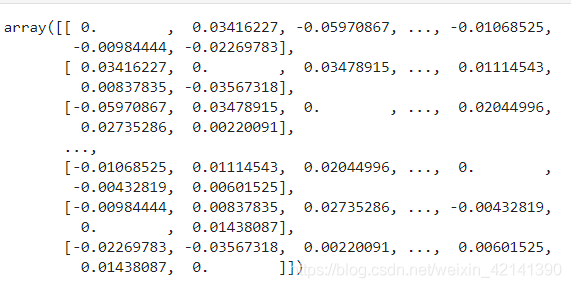
(上述矩陣將自身與自身的相關系數設為 0)然后,再根據相關系數矩陣,遍歷所有特征,若兩個特征相關性大于 0.8 ,則洗掉其中一個,
一頓操作下來,資料變成這樣(以制造業為例):
209 列還是加上了 (發布時間、股票代碼、所屬行業和 FLAG 的),所以最后特征只剩下 205 列,不過這個數字還是比較大的,
配合 FLAG 篩選
根據相關性的篩選是一種“窩里斗”的篩選,現在我們要結合 FLAG 來篩選了,
首先按照題目說的,決定企業是否造假的決定性指標,所以,如果我們搭建一個機器學習模型,而這個機器學習模型根據現有特征,和 FLAG 構成的資料進行訓練,然后得出模型的精確度為 s s s,然后再洗掉一些特征,再重復上一個程序,若模型的精確度不變,則刪去特征,直到精確度明顯降低為止:
原始資料?
在進行機器學習模型訓練的時候,由于資料的類別不均衡,所以需要我們通過采樣的方法,減少主類別的數量;增加次類別的數量,從而達到主類別、次類別的平衡,
舉個例子,假如 1% 的企業造假,99%的企業不造假,那么,一個只會回答 不造假 的模型,就能達到 99% 的精確度…
為了解決這個問題,這里采用單邊選擇法,先進行欠采樣,再用 ADASYN 法進行過采樣,最后然 造假:不造假 = 1:1.
一頓操作下來,資料變成這樣(以制造業為例):
資料量大約翻了一倍
不變?顯著大于?
若模型的精確度在洗掉特征前后不變,則保留?那么不變是什么意思呢?我們知道,模型的訓練演算法的收斂是具有偶然性的,所以每一次訓練的結果都不相同,精確度也自然不同,那么怎么才能叫不變呢?
首先,在訓練模型,獲得精確度的時候,當然不能做一次,這個程序,要重復做 10 次,怎么做呢?交叉驗證,最后得到 10 個精確度,洗掉特征后,再重復一次,再得到 10 個精確度,
然后,將這兩組精確度,進行 one-tail T 檢驗,原假設為:兩組資料的均值不變;備選假設為:洗掉前精確度的均值 > 洗掉后,
機器學習模型?
用什么機器學習模型呢?應該考慮如下幾點:
- 簡單,快速
- 能進行非線性分類
- 能評估每一個特征的權重(對結果的重要性)
綜上,我覺得可以用決策樹、SVC,但是 SVC 在非線性分類方面做得不是很好,且訓練比較復雜,所以本文用的決策樹,
特征權重?
若采用決策樹的話,特征權重就可以用每個特征的 Gini 系數來代替了,
若用 SVC 的話,可以考慮使用 SVC 模型的每個特征的系數,
結果
以“制造業”為例(強調了3次了),使用上述演算法,最后的篩選結果是:

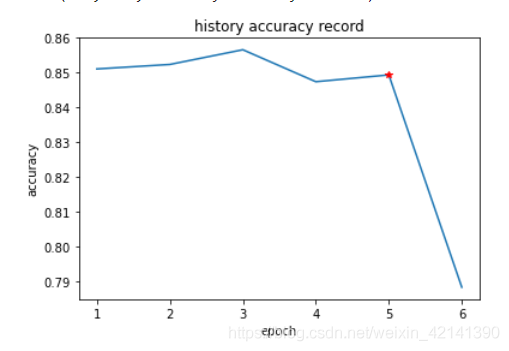
所以,最終篩選的指標是:‘END_DATE’, ‘OTH_NCA’, ‘BASIC_EPS’
第二問
待更新
代碼和檔案
私信我回復競賽(自動回復,不過可能自動回復在審核,手動回復的話比較慢,希望大家耐心)
%# 附件
%##
%## IQR 診斷法
%## 偏相關系數
%## 類別不均衡問題
%### 單邊選擇
%### ADASYN
%## 交叉驗證
特征 feature 是機器學習的術語,也就是輸入變數 ??
若變數呈正態分布,則相關性也指其他非線性相關性 ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280651.html
標籤:其他