所謂人以類聚,物以群分,人們都喜歡跟自己性格相合,愛好相同的人在一起,
俗稱:處得來!靚仔, 我很中意你啊~

A 某和 B 某青梅竹馬,A 某通過 B 某認識了 C 某,發現興趣愛好出奇一致,這三人就搞到了一起,成為了一個形影不離的小團體,這個小團體的形成,是自下而上的迭代程序,
200 個人當中,可能有 10 個小團體,這些小團體的形成可能要好幾個月,
這種「找朋友」的程序,就是今天我們要講的主題:聚類演算法,
聚類
聚類演算法:就是把距離作為特征,通過自下而上的迭代方式(距離對比),快速地把一群樣本分成幾個類別的程序,
更嚴謹,專業一些的說法是:
將相似的物件歸到同一個簇中,使得同一個簇內的資料物件的相似性盡可能大,同時不在同一個簇中的資料物件的差異性也盡可能地大,即聚類后同一類的資料盡可能聚集到一起,不同資料盡量分離,

很顯然,聚類是一種無監督學習,
為了防止新手看不懂,這里簡單解釋一下:
-
對于有標簽的資料,我們進行有監督學習,常見的分類任務就是監督學習;
-
而對于無標簽的資料,我們希望發現無標簽的資料中的潛在資訊,這就是無監督學習,
聚類是一種非常常用,且好用的演算法,
舉個例子:
給你 1 萬張摳腳大漢的圖片和 1 萬張可愛萌妹的圖片,這 2 萬張圖片是混在一起的,

好了,我現在想把所有可愛萌妹的圖片全部扔掉,因為我只愛摳腳大漢!
這種時候,就可以用到聚類演算法,
這是一個比較好理解的例子,專業一點的需求場景,比如人臉識別,
人臉識別需要大量的人臉資料,在資料準備階段,就可以利用聚類演算法,輔助標注 + 清洗資料,

這是一種常規的資料挖掘手段,
我對一些常見的聚類演算法,進行了整理:
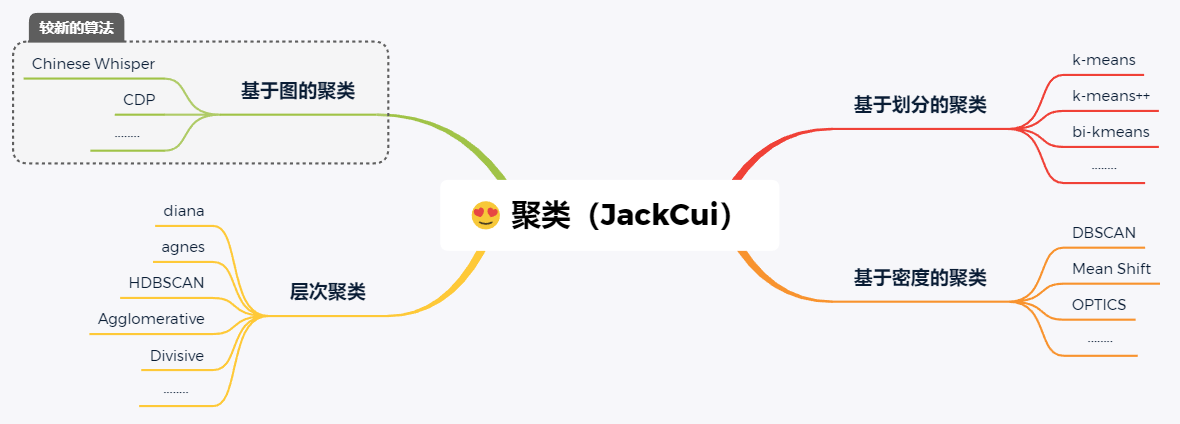
前面講到,聚類演算法是根據樣本之間的相似度,將資料進行歸類的,
而相似度的度量方法,可以大致分為:
-
距離相似性度量
-
密度相似性度量
-
連通相似性度量
不同型別的聚類演算法,采用的樣本間的相似度度量方法是不同的,
聚類演算法很多,一篇文章無法講述詳盡,今天帶大家從最基礎的 Kmeans 學起,
K-Means
K-Means 是一個非常經典的聚類演算法,別看它古老,但很實用,
這么說吧,我現在做專案,一些小功能,偶爾還會用到 K-Means,
K-Means 即K-均值,定義如下:
對于給定的樣本集,按照樣本之間的距離大小,將樣本集劃分為K個簇,讓簇內的點盡量緊密的連在一起,而讓簇間的距離盡量的大
K-Means 聚類的步驟如下:
-
隨機的選取K個中心點,代表K個類別;
-
計算N個樣本點和K個中心點之間的歐氏距離;
-
將每個樣本點劃分到最近的(歐氏距離最小的)中心點類別中——迭代1;
-
計算每個類別中樣本點的均值,得到K個均值,將K個均值作為新的中心點——迭代2;
-
重復步驟2、3、4;
-
滿足收斂條件后,得到收斂后的K個中心點(中心點不再變化),
K-Means 聚類可以用歐式距離,歐式距離很簡單,二維平面就是兩個點的距離公式,在多維空間里,假設兩個樣本為a(x1,x2,x3,x4...xn),b(y1,y2,y3,y4...yn),那么他們之間的歐式距離的計算公式是:
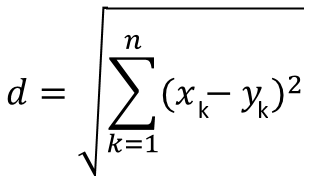
可以用下面的圖很好地說明:
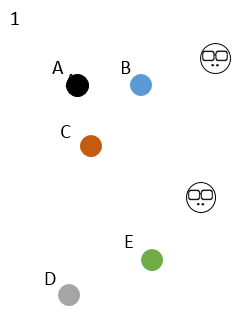
有 ABCDE 5個樣本,一開始選定右邊的 2 個初始中心點,K=2,大家顏色都不一樣,誰都不服誰;
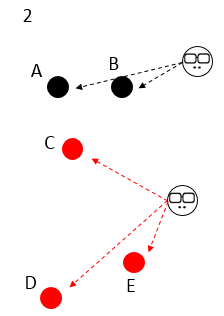
5 個樣本分別對比跟 2 個初始中心點的距離,選距離近的傍依,這時 5 個樣本分成紅黑 2 群;
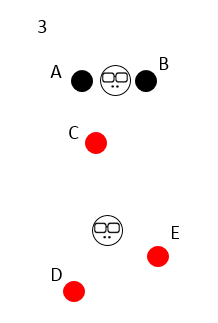
然后開始換老大啦,2 個初始中心點消失,重新在 2 個類分別中心的位置出現 2 個新的中心點,這 2 個新的中心點離類別里樣本的距離之和必須是最小的;
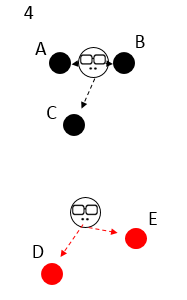
新的老大出現,類別的劃分也不一樣啦,C 開始叛變,傍依了新老大,因為他離新老大更近一點;
新的老大消失,新新老大出現,發現劃分的類別沒有變化,幫派穩定,于是收斂,
用代碼簡單實作一下:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets.samples_generator import make_blobs
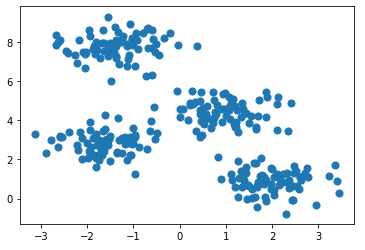
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.60, random_state=0)
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.show()
生成一些隨機點,
然后使用 K-Means 進行聚類,
from sklearn.cluster import KMeans
"""
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300,
tol=0.0001, precompute_distances='auto', verbose=0,
random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
Parameters:
n_clusters: 聚類個數
max_iter: 最大迭代數
n_init: 用不同的質心初始化值運行演算法的次數
init: 初始化質心的方法
precompute_distances:預計算距離
tol: 關于收斂的引數
n_jobs: 計算的行程數
random_state: 隨機種子
copy_x:是否修改原始資料
algorithm:“auto”, “full” or “elkan”
”full”就是我們傳統的K-Means演算法,
“elkan”elkan K-Means演算法,默認的
”auto”則會根據資料值是否是稀疏的,來決定如何選擇”full”和“elkan”,稠密的選 “elkan”,否則就是”full”
Attributes:
cluster_centers_:質心坐標
Labels_: 每個點的分類
inertia_:每個點到其簇的質心的距離之和,
"""
m_kmeans = KMeans(n_clusters=4)
from sklearn import metrics
def draw(m_kmeans,X,y_pred,n_clusters):
centers = m_kmeans.cluster_centers_
print(centers)
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=50, cmap='viridis')
#中心點(質心)用紅色標出
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5)
print("Calinski-Harabasz score:%lf"%metrics.calinski_harabasz_score(X, y_pred) )
plt.title("K-Means (clusters = %d)"%n_clusters,fontsize=20)
plt.show()
m_kmeans.fit(X)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=4, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
y_pred = m_kmeans.predict(X)
draw(m_kmeans,X,y_pred,4)
聚類運行結果:
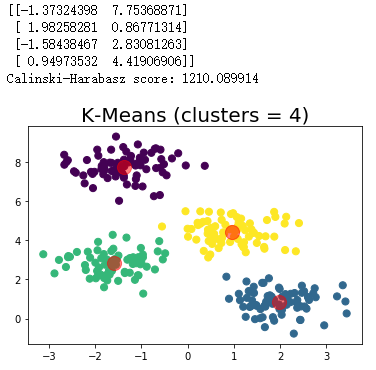
總結
K-Means 聚類是最簡單、經典的聚類演算法,因為聚類中心個數,即 K 是需要提前設定好的,所以能使用的場景也比較局限,
比如可以使用 K-Means 聚類演算法,對一張簡單的表情包圖片,進行前后背景的分割,對一張文本圖片,進行文字的前景提取等,
K-Means 聚類能使用的距離度量方法不僅僅是歐式距離,也可以使用曼哈頓距離、馬氏距離,思想都是一樣,只是使用的度量公式不同而已,
聚類演算法有很多,且看我慢慢道來,
最后載送大家一本幫助我拿到BAT 等一線大廠 offer 的資料結構刷題筆記,是一位 Google 大神寫的,對于演算法薄榷訓者需要提高的同學都十分受用(提起碼:m19c):
BAT 大佬分類總結的 Leetcode 刷題模版,助你搞定 90% 的面試
更加詳細的演算法學習路線,包括演算法、數學、編程語言、比賽等的學習方法和資料,可以看這篇內容:
我是如何成為演算法工程師的,超詳細的學習路線
想看我講解其他好玩實用的聚類演算法,例如 CDP 等,不妨來個三連,給我來點動力,
我是 Jack,我們下期見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280661.html
標籤:其他