以下文章摘錄自:
《機器學習觀止——核心原理與實踐》
京東: https://item.jd.com/13166960.html
當當:http://product.dangdang.com/29218274.html
(由于博客系統問題,部分公式、圖片和格式有可能存在顯示問題,請參閱原書了解詳情)
1.1 CV發展簡史
我們首先來了解一下計算機視覺(CV)領域的發展簡史,
從動物學家針對化石的研究中,人們發現生物的視覺系統大概起源于5億4千3百萬年(543 million years)前——在那之前,地球上只存活著非常少的一些物種,而之后短短的1000萬年間,物種數量卻呈現出了爆炸式的增長(也就是“Evolution’s Big Bang”,參見下面所示的Stanford cs231n的課件資料),雖然人們還無法完全揭曉那一段歷史時期內所發生的具體事情,但業界目前一個普遍的觀點就是:視覺系統的出現和不斷完善迫使不同物種間的競爭加劇,進而極大地縮短了它們的進化時間,最終導致了“Big Bang”現象的出現,

圖 ? 543million years, B.C.
視覺系統對于哺乳動物,特別是人類的重要性是不言而喻的,經過漫長的進化程序,視覺已經成為了我們感知世界最為重要的一個神經系統了,
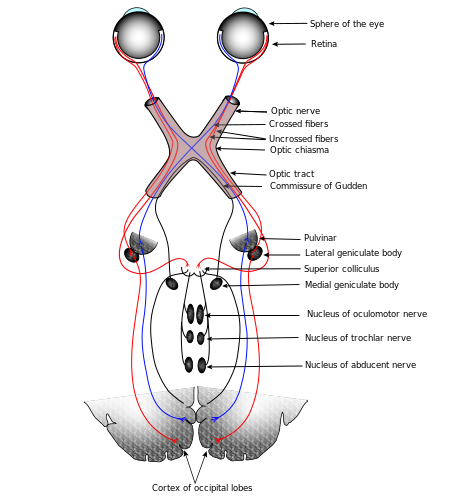
圖 ? 人類視覺系統簡圖(wikipedia)
相對于生物視覺系統漫長的進化歷程,計算機視覺(computer vision)顯然是“非常年輕而且稚嫩”的——因為人們是從上世紀50年代才開始嘗試賦予計算機系統這一重要的感知能力,而且這個學科的涉及面比較寬泛,它不光依賴于計算機科學知識,同時還需要我們在生物學、數學、神經科學等多個領域有所狩獵,
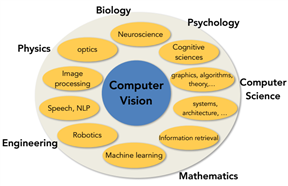
圖 ? 計算機視覺是一門交叉學科
探索計算機視覺的道路可以說是非常曲折的,即便到了今天人們也不敢拍著胸脯說已經解決了這個領域的所有問題——甚至恰恰相反,我們認為計算機視覺仍然有很多障礙和瓶頸還未清除完畢,例如對于人類而言非常簡單的影像識別任務,對于計算機來講卻困難重重(部分圖片參考自stanford提供的材料),典型難點如下所示:
l 典型難點1:光照問題

可以看到,不同光照條件下的物體形態各異,這將大大增加計算機系統的識別難度
l 典型難點2:遮擋問題

遮擋在計算機視覺中也是一個常見的問題,對于人類而言,即便只能看到貓的身體的一部分(比如尾巴、頭),他們也能夠快速、準確地識別出來,
l 典型難點3:背景干擾

l 典型難點4:姿勢形態

等等
當然,這并不代表人類在這個領域一無所獲,應該說人們在多年的探索程序中,已經取得了不少階段性的進展了,包括但不限于:
l 50年代:研究生物視覺作業原理
人們總是在探索著他們所處世界中的萬事萬物——這其中當然包括人類自身,上世紀50年代左右,生物學家們做了很多努力來試圖理解動物的視覺系統,其中比較有名的是Hubel和Wiesel的一些研究成果,他們從電生理學(electrophysiology)的角度來分析貓(據說選擇貓的原因在于它和人類的大腦比較相近)的視覺皮層系統,從中發現了視覺通路中的資訊分層處理機制,并提出了感受野的概念,他們也因此獲得了諾貝爾生理學或醫學獎,
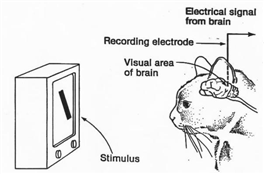
圖 ? Hubel和Wiesel的實驗示意圖
l 60年代
嚴格意義上來講,計算機視覺是在60年代逐步發展起來的,這個時期還誕生了人類歷史上的第一位計算機視覺博士,即Larry Roberts,他在1963年撰寫的論文《machine perception of three-dimensional solids》中將物體簡化為幾何形狀(立方體、棱柱體等)來加以識別(參見下面的示意圖),當時人們相信只要提取出物體形狀并加以空間關系的描述,那么就可以像“搭積木”般拼接出任何復雜的三維場景,人們的研究熱情空前高漲,研究范圍遍布角點特征、邊緣、顏色、紋理提取以及推理規則建立等很多方面,

圖 ? Block world
隨后的1966年,MIT舉辦了一個名為“Summer Vision project”的活動,與會人員“雄心勃勃”地希望在一個暑假的時間里徹底解決計算機視覺問題,雖然這個活動沒能達到預期的目的,但隨后幾十年人們對于計算機視覺的熱情卻在持續高漲,其影響范圍也蔓延到了全世界
l 70-80年代
MIT的人工智能實驗室在這一時期的計算機視覺領域中發揮了相當積極的推動作用,一方面,它于70年代設定了Machine Vision課程;同時AI Lab還吸引了全球很多研究人員參與到了計算機視覺的理論和實踐研究中,
其中David Marr教授在計算機視覺理論方面做出了非常多的貢獻,他融合了心理學、神經生理學、數學等多門學科,提出了有別于前人的計算機視覺分析理論,并在前后二十年的時間里影響了這一領域的發展,他的主要著作是《Vision: A computational investigation into the human representation and processing of visual information》(由于David在1980年不幸病逝,這本書據說是由其學生歸納總結出來的),書中將視覺識別程序劃分為3個階段,如下圖所示:
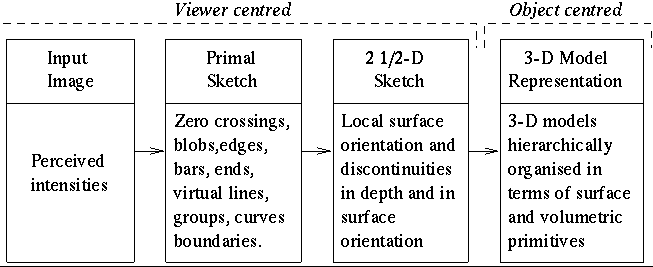
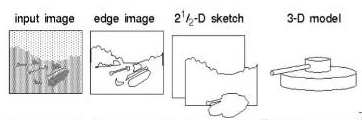
圖 ? David Marr所理解的計算機視覺表示
l 80年代
上世紀80年代,邏輯學和知識庫等理論在人工智能領域占據了主導地位,人們試圖建立專家系統來存盤先驗知識,然后再與實際專案中提取的特征進行規則匹配,這種思想也同樣影響了計算機視覺領域,于是誕生了很多這方面的方法,例如David G. Lowe在論文《Three-Dimensional Object Recognition from Single Two-Dimensional Images》中提出了knowledge-based vision的概念,有興趣的讀者可以下載論文了解詳情,
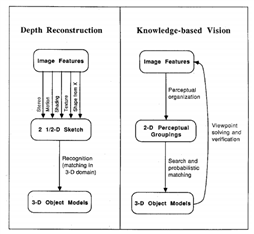
圖 ? Knowledge-based vision
l 90年代
此時計算機視覺雖然已經發展了幾十年了,但仍然沒有得到大規模的應用,很多理論還處于實驗室的水平,離商用要求相去甚遠,人們逐漸認識到計算機視覺是一個非常難的問題,以往的嘗試似乎都過于“復雜”,于是有的學者開始“轉向”另一個看上去更簡單點的方向——image segmentation,后者的目標在于運用一些影像處理方法將物體分離出來,以此做為影像分類的第一步,
另外,伴隨著統計學理論在人工智能中的逐漸“走紅”,計算機視覺在90年代也同樣經歷了這個轉折,學者們利用統計學手段來提取描述物體的本質特征,而不是由人工去定義這些規則,這一時期產生的多種基礎理論直到現在還有廣泛的應用,例如影像搜索引擎
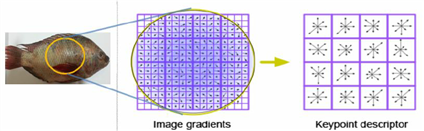
圖 ? SIFT Descriptor
l 本世紀初
隨著機器學習的興起,CV領域開始取得一些實際的應用進展,例如Paul Viola和Michael Johns等人利用Adaboost演算法出色完成了人臉的實時檢測,并被Fujifilm公司應用到商用產品中;同時SPM、HoG、DPM等經典演算法也如“雨后春筍”般涌現了出來

圖 ? HoG
l 2010年之后:CNN大放異彩
大家有幸正在經歷人工智能大爆發的這個歷史階段——包括計算機視覺在內的多項人工智能領域取得了長足的進步,從其它章節的學習中,我們知道這主要歸功于如下幾個原因:
1) 計算機運算能力呈現指數級的增長
2) ImageNet、PASCAL等超大型圖片資料庫使得深度學習訓練成為可能(注:大型圖片資料庫雖然在2000年后期就已經出現了,但真正大放異彩還是在最近十年),同時,業界一些極具影響力的競賽專案(例如ILSVRC)激勵了全世界范圍內的學者們競相加入,從而催生了一個又一個優秀的深度學習框架


3) 模型演算法的不斷演進革新
本章后續內容中,我們將圍繞視覺識別這個任務,有選擇性地剖析業界的一些經典的CNN模型框架,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280685.html
標籤:其他