【系列推薦閱讀】
- 【資料結構之順序表】用圖和代碼讓你搞懂順序結構線性表
- 【資料結構之鏈表】看完這篇文章我終于搞懂鏈表了
- 【資料結構之堆疊】用詳細圖文把「堆疊」搞明白(原理篇)
- 【資料結構之佇列】詳細圖解!在學習佇列?看這一篇就夠了!
- 【資料結構之鏈表】詳細圖文教你花樣玩鏈表
- 【資料結構之二叉樹】一文看懂二叉樹的概念和原理
- 【資料結構之二叉樹】二叉樹的創建及遍歷實作
- 【資料結構之線索二叉樹】線索二叉樹的原理及創建
1. 為什么要用到線索二叉樹?
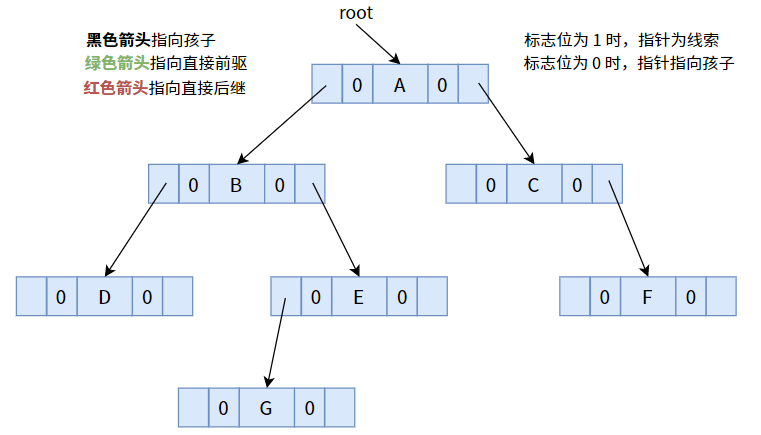
我們先來看看普通的二叉樹有什么缺點,下面是一個普通二叉樹(鏈式存盤方式):
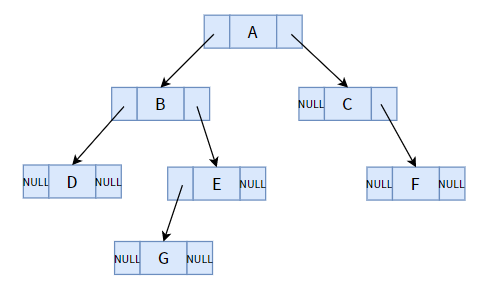
乍一看,會不會有一種違和感?整個結構一共有 7 個結點,總共 14 個指標域,其中卻有 8 個指標域都是空的,對于一顆有 n 個結點的二叉樹而言,總共會有 n+1 個空指標域,這個規律使用所有的二叉樹,
這么多的空指標域是不是顯得很浪費?我們學習資料結構和演算法的重點就是在想法設法地提高時間效率和空間利用率,這么多的指標域就這么白白浪費了,太敗家了!
所以我們要想法子好好利用它們,利用它們來幫助我們更好地使用二叉樹這個資料結構,
那么如何利用呢?
前面已經強調過很多次了,遍歷二叉樹的實質是將二叉樹中非線性結構的結點轉化為線性的序列,然后才能方便我們遍歷,
比如上圖的中序遍歷序列為:DBGEACF,
對于一個線性序列(線性表)來說,它有直接前驅和直接后繼的概念(在【什么是線性表?】中介紹過),比如在中序遍歷序列中,B 的直接前驅為 D,直接后繼為 G,
我們之所以能知道 B 的直接前驅和直接后繼,是因為我們按照中序遍歷的演算法,把二叉樹的中序遍歷序列寫出來了,然后根據這個順序序列說誰的前驅是誰、后繼是誰,
直接前驅和直接后繼是不能完全直接通過二叉樹得到的,因為二叉樹中只有雙親和孩子結點之間的直接關系,即二叉樹的結點指標域中只存盤了其孩子結點的地址,
現在的需求是,我想能直接從二叉樹上得到某結點在中序遍歷方式下的直接前驅和直接后繼,
這時候就需要用到線索二叉樹了,
2. 什么是線索二叉樹?
當然,我們肯定需要借助結點的指標域來保存直接前驅和直接后繼的地址,
其實,在上圖的普通二叉樹中(以中序遍歷得到的序列),部分結點(指標域不為空的結點)是可以找到其直接前驅或后繼的,比如結點 E 的左孩子 G 就是結點 E 的直接前驅;結點 A 的右孩子 C 就是結點 A 的直接后繼,
但部分結點(指標域為空)是行不通的,比如結點 G 的直接后繼是 E,直接前驅是 B,但在二叉樹中卻不能得出這樣的結論,怎么辦呢?我們注意到,結點 G 的兩個指標域都為 NULL,并未被利用,那么我們使用這兩個指標,分別指向其前驅和后繼不就好了嗎?
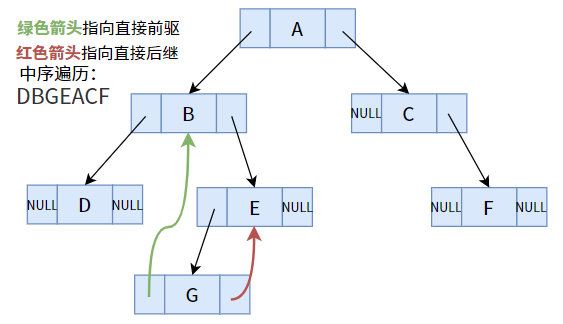
實在是兩全其美,天作之合!但是問題并沒有解決!
因為我們是利用空指標域來指向前驅或后繼的,對于那些指標域不為空的結點,這樣是矛盾的,比如結點 E 和結點 B,
既然有矛盾,那么我們就發現產生矛盾的根源,解決矛盾,
產生矛盾的根源是:結點的指標域為空和不為空時,指標的指向矛盾,即,指標不為空時指向孩子和指標為空時指向前驅或后繼之間的矛盾,
那么我們對癥下藥,把指標域為空和不為空給區分出來,清晰地告訴指標:不為空時指向孩子,為空時指向前驅或后繼,這就需要我們給兩個指標各添加一個標志位,
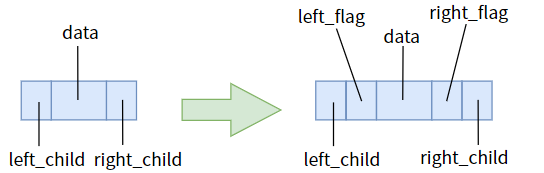
并約定以下規則:
left_flag == 0時,指標left_child指向左孩子left_flag == 1時,指標left_child指向直接前驅right_flag == 0時,指標right_child指向右孩子right_flag == 1時,指標right_child指向直接前驅
二叉樹的結點要有所變化:
/*線索二叉樹的結點的結構體*/
typedef struct Node {
char data; //資料域
struct Node *left_child; //左指標域
int left_flag; //左指標標志位
struct Node *right_child; //右指標域
int right_flag; //右指標標志位
} TTreeNode;
有了標志位,一切就能理清了,我們稱指向直接前驅和后繼的指標為線索,標志位為 0 的指標是指向孩子的指標,標志位為 1 的指標是線索,
一個二叉鏈表樹,結點結構如上,我們將所有空指標都變為線索,這樣的二叉樹就是二叉線索樹,
3. 如何創造線索二叉樹?
在普通二叉樹中,我們想要獲取某個結點在某種遍歷次序下的直接前驅或后繼,每次都需要遍歷獲取到遍歷次序之后才能知道,而在線索二叉樹中,我們只需要遍歷一次(創造線索二叉樹時的遍歷),之后,線索二叉樹就能“記住”每個結點的直接前驅和后繼了,以后都不需要再通過遍歷次序獲取前驅或后繼了,
我們按照某種遍歷方式,把普通二叉樹變為線索二叉樹的程序被稱為二叉樹的線索化,
接下來,我們用中序遍歷的方式,將下面的二叉樹線索化為線索二叉樹
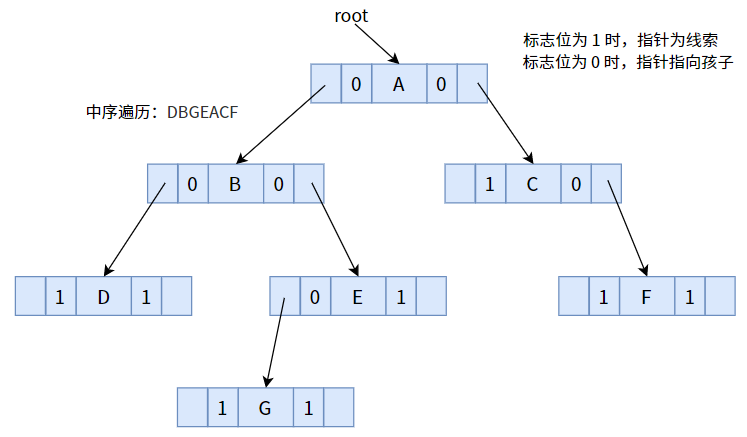
將標志位為 1 的指標,按照中序遍歷序列,使其指向前驅或后繼:
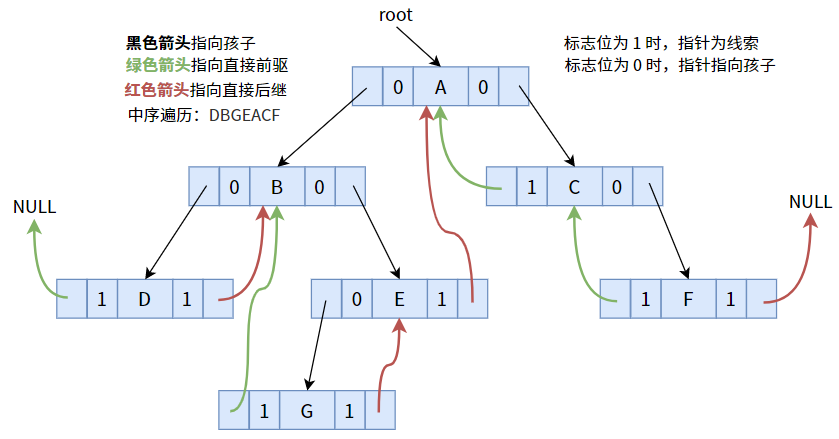
其中,結點 D 沒有直接前驅,結點 F 沒有直接后繼,故指標為 NULL,
到此,我們算是解決了擁有 n 個結點的二叉樹存在 n+1 個空指標域所造成的浪費,解決方式是給每個結點的指標增加一個標志位,以此來利用空指標域,標志位中存盤的是 0 或 1 的布林值,與浪費的空指標域相比,是相對比較劃算的,而且使二叉樹具有了一種新特性——二叉樹中能保存在某種遍歷次序下的結點之間的前驅和后繼關系,
4. 線索化的實作
請注意一點,線索二叉樹是由普通二叉樹得來的,而且是按某種遍歷順序得來的,因為線索是在知道某個結點的前驅和后繼的情況下才能設定,而前驅和后繼關系不能通過二叉樹直接體現,只能通過遍歷二叉樹得到的線性序列得出關系,所以要通過某種遍歷方式得到具有前驅和后繼關系的序列后,才能修改結點的空指標,進而設定線索,
即:線索化的實質是在按照某種遍歷次序進行遍歷二叉樹的程序中修改結點的空指標,使其指向其在該遍歷次序下的直接前驅或直接后繼的程序,
我們在【二叉樹的遍歷原理】和【二叉樹的遍歷實作】分別介紹了二叉樹四種遍歷方式的原理及代碼實作,當時我們是以列印為例來介紹遍歷的,但遍歷不止做列印的事,還可以做線索化的事,
所以,代碼的大體結構還是一樣的,我們只需把遍歷代碼中的列印代碼換成線索化的代碼,并作出一些其他改變即可,
下面以下圖為例,分別介紹三種線索化:
一顆未線索化的二叉樹,其所有標志位均默認為 0.
4.1. 中序線索化
按照中序遍歷次序線索化后,可得下圖:

我們先再次明確以下內容:
-
我們是在遍歷二叉樹的程序中進行線索化的,
-
中序遍歷的順序為:左子樹 >> 根 >> 右子樹,
-
線索化修改兩個東西:空指標域和其對應的標志位,
-
如何修改?將空指標域置為直接前驅或后繼,
所以我們的問題變成了:
- 找到所有空指標域,
- 找到空指標域所屬結點,在先序次序下的直接前驅和直接后繼,
- 修改空指標域的內容,及其標志位,使該指標稱為線索,
說明:我們在遍歷二叉樹時,使用到了遞回,所以在進行線索化的時候,也會使用它,
具體代碼如下:
//全域變數 prev 指標,指向剛訪問過的結點
TTreeNode *prev = NULL;
/**
* 中序線索化
*/
void inorder_threading(TTreeNode *root)
{
if (root == NULL) { //若二叉樹為空,做空操作
return;
}
inorder_threading(root->left_child);
if (root->left_child == NULL) {
root->left_flag = 1;
root->left_child = prev;
}
if (prev != NULL && prev->right_child == NULL) {
prev->right_flag = 1;
prev->right_child = root;
}
prev = root;
inorder_threading(root->right_child);
}
4.2. 先序線索化
按照先序順序線索化后,可得下圖:

具體代碼如下:
// 全域變數 prev 指標,指向剛訪問過的結點
TTreeNode *prev = NULL;
/**
* 先序線索化
*/
void preorder_threading(TTreeNode *root)
{
if (root == NULL) {
return;
}
if (root->left_child == NULL) {
root->left_flag = 1;
root->left_child = prev;
}
if (prev != NULL && prev->right_child == NULL) {
prev->right_flag = 1;
prev->right_child = root;
}
prev = root;
if (root->left_flag == 0) {
preorder_threading(root->left_child);
}
if (root->right_flag == 0) {
preorder_threading(root->right_child);
}
}
4.3. 后序線索化
按照后序遍歷次序線索化后,可得下圖:

具體代碼如下:
//全域變數 prev 指標,指向剛訪問過的結點
TTreeNode *prev = NULL;
/**
* 后序線索化
*/
void postorder_threading(TTreeNode *root)
{
if (root == NULL) {
return;
}
postorder_threading(root->left_child);
postorder_threading(root->right_child);
if (root->left_child == NULL) {
root->left_flag = 1;
root->left_child = prev;
}
if (prev != NULL && prev->right_child == NULL) {
prev->right_flag = 1;
prev->right_child = root;
}
prev = root;
}
5. 總結
線索二叉樹充分利用了二叉樹中的空指標域,給予二叉樹一個新特性——通過一次遍歷進行線索化后,二叉樹中就能保存其結點之間的前驅和后繼關系,
所以,如果我們需要頻繁遍歷二叉樹,查找某個結點的直接前驅或后繼結點,使用線索二叉樹是非常合適的,
此外,由于代碼涉及到遞回,初次接觸可能不好理解,我們可以借助斷點進行除錯,細致觀察線索化的整個程序來幫助理解,
以上就是線索二叉樹的原理及創建
完整代碼請移步至 GitHub | Gitee 獲取,
如有錯誤,還請指正,
如果覺得寫的不錯,可以點個贊和關注,后續會有更多資料結構和演算法相關文章,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281147.html
標籤:其他