先上證書:

剛看了下我們小群的歷史訊息,居然大半都是類似于“干飯干飯”這樣()
我們隊是在美賽前重組的,(之前和kana醬是同一組,同組男隊員實在太拉了,不管性格還是能力).
三人實戰經驗無い,指導老師組織模擬過三次,我和小劉是氣象學的同班同學.
小劉年級前1%,kana醬是計算機學院的年級前1%,我:(平平無奇二次元)
我們之前在不同組,國賽都拿了省三
小劉想靠美賽加分保研,kana醬和我一直沒拿到什么耀眼的成績,想在本科最后一次數模比賽中出一口惡氣.
小劉之前做A題多一些,沒碰過統計,我和kana一直選c但沒做出什么成績,嚴重缺乏自信心,所以出成績第二天,剛起床,看到拿了Finalist(震驚)(不是眼花了吧.jpg)
然后開始分析題目和講一下我們的解題方法和思路吧!
第一問:預測有害生物隨時間的傳播和準確度
(這題是小劉做的,我來簡要闡述)
隨時間傳播,必然要考慮到空間上和數量上,小劉選用(48.5N°-49.5N°, 123.5W°-121.5W°) 用于后續分析和預測,考慮到胡蜂分布與巢位密切相關,用NAA(Predict the range of activity from original nest to new nest)模型來定位巢穴并預測蜂的活動范圍,兼并考慮華盛頓州的地形作用,來改進原有NAA模型,并構建誤差矩陣來計算準確性和靈敏度.我則使用了基于資訊擴散和人口增長的Fick-logistic擴散模型來解決數量增長問題.
NAA模型基本思路:對空間進行離散處理后,基于往年胡蜂位置的歷史資料,以及胡蜂覓食的特性,構建胡蜂出現概率p與位置離散點的分段函式p(i,j),然后通過聚類演算法將空間點分為兩類,自然,p較大的一類的空間點即為nest可能出現的位置,個數即為預計的巢穴位置的總數,
同時引入queen的經驗建巢距離,以達成根據方程組預測新巢位置的目的.同時考慮到一般覓食在2km以內,為了增加2km范圍內黃蜂出現概率,對公式加入訂正因子.
最后得到的結果也很好,預測范圍包含所有實測范圍!且預測其主要向東南方向擴散,但考慮地形,華盛頓州西部有大片林地,有利于Asian giant hornets 筑巢繁衍,所以其更有可能向南進一步擴散,
最終構建的方程組如下:(另外,推薦在建模的程序中由簡入繁,從模型簡單到復雜完善化的程序全部po在論文上,這樣看起來思路完整)
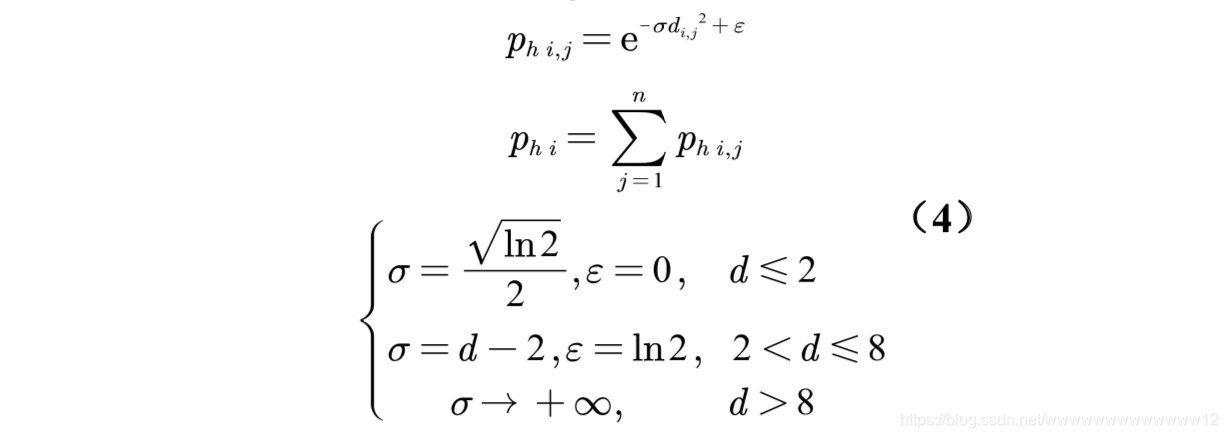
構建誤差矩陣計算準確性的程序比較基礎,如下,不再贅述:
數量預測方面(我做的):
基于胡蜂的種群數量動態特征,將胡蜂的數量增長分為兩類:某蜂群內部的受精繁殖程序稱為“內部增長”,將不同的兩個群落之間互相影響而相互受精繁殖的程序稱為“外部增長”,再耦合:
-
logistic 模型——自然狀況下的,種內競爭加劇,的世代重疊的連續種群增長模型
-
Fick 擴散模型——“菲克第二定律”:在物理學中,“擴散”是指某種物質分子通過一 個濃度梯度或濃度差異移動的現象,即物質分子由高濃度區域移至低濃度區域,至分子均勻分布為止 .
生成關于種群密度的,兩種模型的混合模型,以偏微分方程組的形式,再設定初邊界條件,以求解偏微分方程.
可圈可點的是,我使用了數值模擬生物實驗的程序以得到華盛頓州內胡蜂種群密度,因為美國于 2020 年九月份于加拿大不列顛哥倫比亞省溫哥華島(49°23‘𝑁, 123°06′𝑊) 第一次發現了胡蜂巢,故以此為源點,且時間序列從 2020 年九月開始統計胡蜂的出現量.
在如下引數設定下進行了蒙特卡洛數值模擬仿真實驗:
-
初始密度𝜙(𝑥, 0):由開始傳播前的密度估計量所決定. 𝜙(𝑥, 0) = 8.231
-
內部繁殖率 r:根據已經確定的引數與混合模型,對 r 進行多次擬合,得到
r=0.02735(with 95% confidence bounds (0.0265,0.0282))
-
環 境 所 能 容 納 的 最 大 限 度 N:N=42.34(with 95% confidence bounds
(11.26,73.84)).
-
外部增長率 d:其反應任意兩個蜂群之間的互相繁殖增長率,因為隨著時間的
推移,群體與群體之間繁殖擴散的程度會逐漸趨于均勻,即外部引數是看作 時間 t 的遞減函式,如下等式所定義:
𝑑(𝑡) =1.4𝑒J<.K(LJ<) + 0.25
根據上述引數設定,對胡蜂群落的增長程序進行了數值仿真模擬, 并改變傳播引數模 擬美國 2020 年 10 月下半月進行的清剿巢穴活動對種群密度的影響作用.執行仿真 程序的步驟如下:
1. 輸入初始引數(與估計出的 2019 年 9 月種群密度一致),時間上限設為 400 天,設定仿真計數引數為1
2. 計算 t=i+1 時的種群密度,更新 N(t)并記錄
3. 重復執行步驟 2,直到到達清剿巢穴活動開始的時間點(i=375)
4. 清剿巢穴的作用不但在于直接減少種群密度,還在于削減了不同蜂群之間的交流繁殖,對外部增長率 d 有明顯衰減作用.減少 d 來模擬此程序. 5. 重復計算 t=i+1 時的種群密度,更新𝜙(t)并記錄,直到達到仿真上限時間.
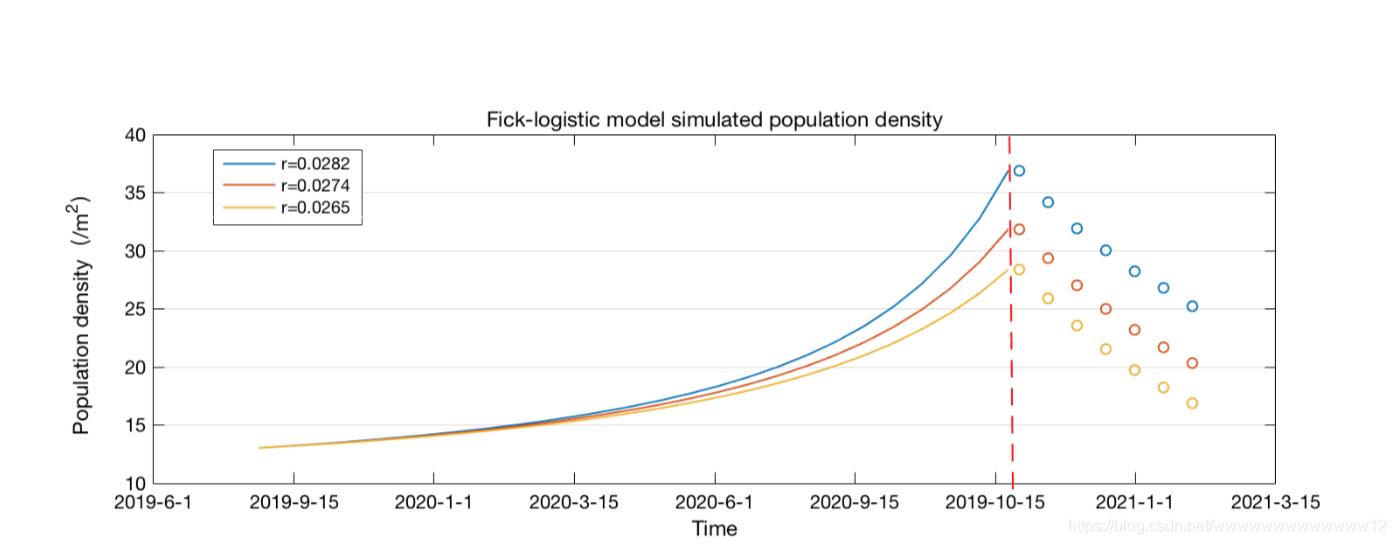
可以看出,政府若不實行清剿行動,每 15 天蜂群密度擴張將呈現指數型增長.
然后計算預測準確率的評價函式,通過三次樣條將資料插值,得到不 同時間對應不同距離上種群密度的預測準確率情況(結果不錯):

至此,第一問結束.
可以改進的部分:
我是學氣象的啊啊啊,一定是專業課沒學好的緣故,當時沒有想到暖濕氣流對胡蜂的分布狀況也具有影響(冬季,胡蜂對暖濕的地區具有傾向性,可以在NAA以及數量擴散加入影響因子),如果考慮了過落基山的風速風向以及下沉氣流是焚風還是布拉風,只需要下載NCEP資料,截出美國的經緯度矩陣...再做一點中尺度的分析,總體上來說一定更完備.
寫得太慢了還復不復習考研了()
準備把第二三四放在一起寫:(這三題是我和kana醬一起做的)
第二問:利用影像集和文本資料集,對胡蜂進行分類,分析準確性
第三問:用訓練好的分類模型分類unverified和unprocessed(其實就是應用以及建立好的模型分類未知資料)
第四問:在有新報告加入的情況下更新分類模型
我先對影像和comments資料進行了清洗和處理,將影像全部整理成jpg格式(matlab程式批處理,個別自己手動調的),并洗掉了detection date中的亂碼日期和1980年的資訊條,隱藏了submission date.然后在一本關于影像處理的古籍上看到了影像配準的黑科技,它可以處理影像的扭曲變形,輸入一張標準參考影像,可以使得未經處理的影像與標準影像視角一致,有利于后期影像的量化,效果如下:

然后kana醬學過影像處理,就交給她量化了....!

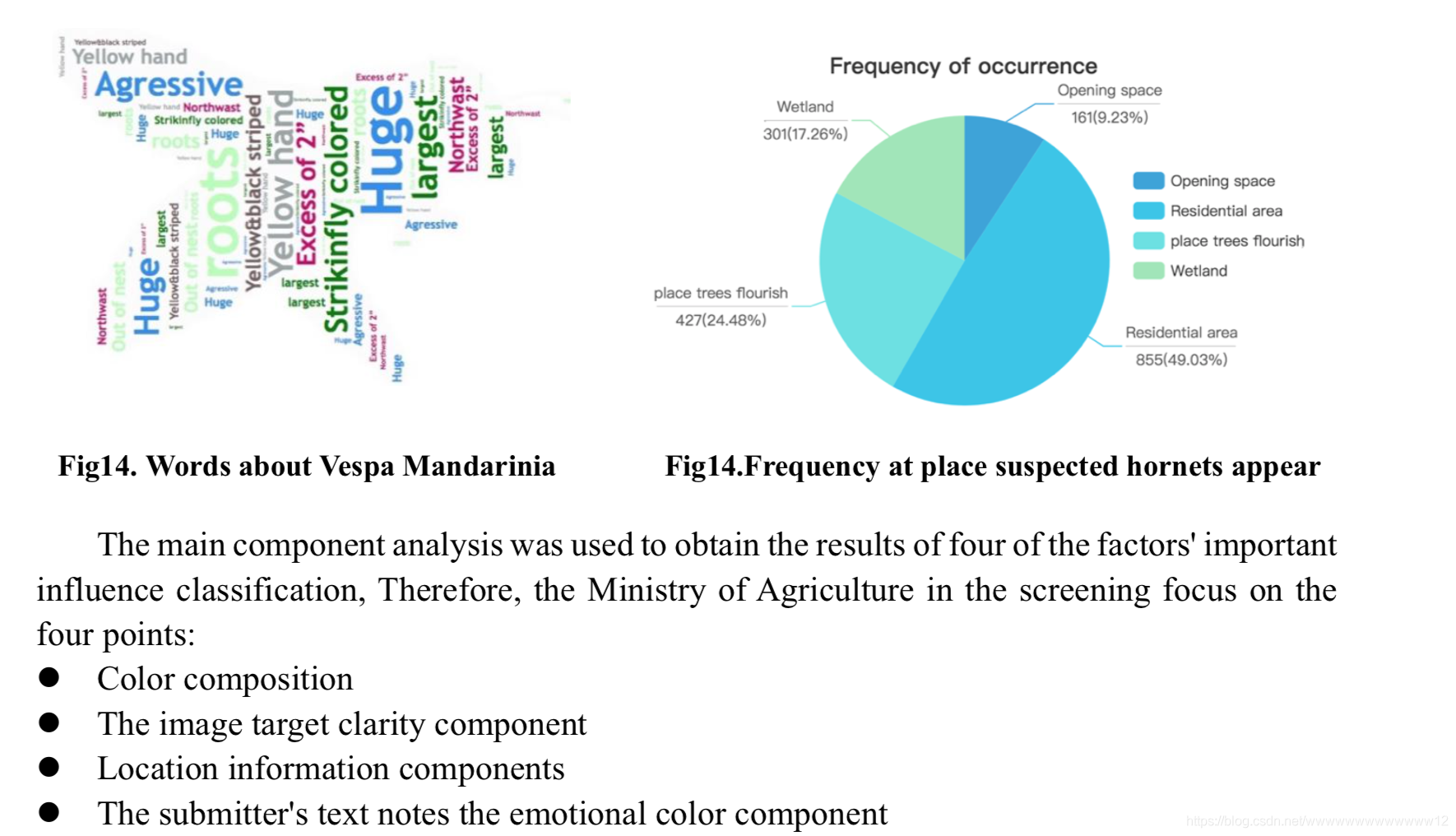
她運用了主成分分析,得到四個主成分:顏色成分,圖片目標清晰度成分,位置資訊,notes情感色彩成分,以便農業部在進行篩選時著重注意以上四點.
然后整理出了用于分類的訓練資料集,格式如下:

構建貝葉斯分類器(機器學習那一卦的,python直接調包),第二題用十折交叉驗證(Bayes包里的一句命令)算準確率(68%)和召回率(93%)
第三題:Classification of unverified and unprocessed events
也許因為指標多,資料充足,樸素貝葉斯分類器分類性能很好,結果分出七個陽性.
第四題,一種基于賦權淘汰更新機制的集成分類器
將訓練資料分為等大的單位資料塊,每個資料塊中包含數量相同的樣本資料. 集成分類,對基分類器實作動態更新和為基分類器分配合適的權重,即集成分類器的動態 迭代更新,可以在此基礎上提出一個加權函式,對具有不同引數特征的資料流進行有針對 性的獲得基分類器的最佳權重,從而提升集成分類器的整體性能.
簡單的說,就是選一個性能較好的傳統分類器,比如NB,SVM什么的,對默認引數進行調整,整合出適合我們自己的基分類器(馬克思中國化(什)),綜合所有原因,且基于風險最小化的 SVM 對小資料量分類很友好,由上分析,最終選用 SVM 分類演算法.
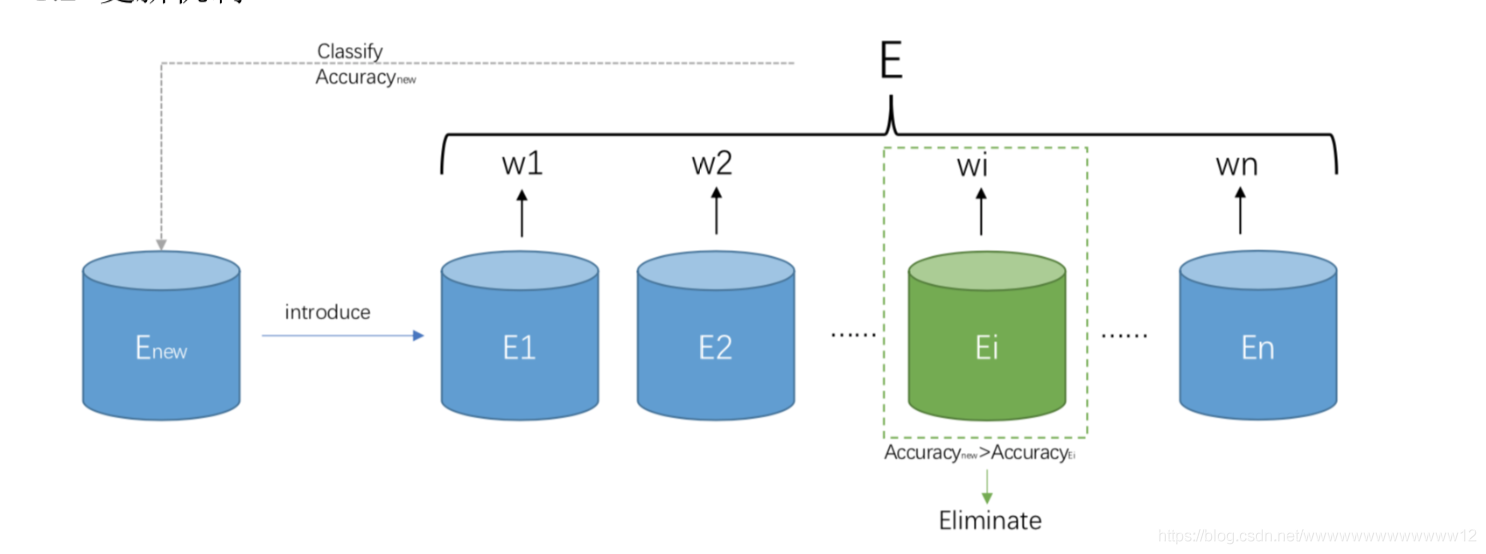
對下一個到來的資料塊,先利用集成分類器{𝐸#, 𝐸%, 𝐸&, ... , 𝐸(}對每個資料分類,得到新 資料塊的分類準確率,將舊基分類器的準確率與新分類器的進行比較,淘汰掉效果不好的基分類器.
初始權重全定義為1,有資料塊投入后將分錯率的倒數作為基分類器的權重. 將所有分類結果進行加權平均作為集成模型的最終結果,若有新報告被提交,則在累積夠一個數
據塊所包含的最佳樣本數后,聚成一個資料塊投入集成分類器,后通過比較當前模型中各 集成分類器的分類準確率與此前已完成分類的資料塊來進行模型更新,淘汰掉已經不適 應現有資料概念的基分類器.
思想大致如上,至于最佳樣本數,毋庸置疑,可以用來解釋時效性,于是我們運行模型,討論每次引進的資料塊中所含提交報告數 n 對分類器性能的影響(即控制引數查看結果,相當于敏感性實驗)

由表清晰可得當每次輸入的新資料塊中含有 25 個資訊條時模型效果最好,即每次額外的新報告累積達到 25 條時,聚成一個資料塊投入分類器,此時集成分類器具有較高的分類準確率和較好的性能.即更新的頻率為每 25 條提交報告更新一次分類模型.第四題至此結束!
可以改進的部分
是在短期氣候預測課上想到的,可以使用泰勒圖(Taylor diagram)來選取最優基分類器,其氣象應用是可以通過一張圖直觀衡量不同模式和真實觀測結果之間擬合程度,精度指標有相關系數,標準差以及均方根誤差(RMSE),可以依此來選出最佳模式.同理,可以用此圖來選擇最佳基分類器,如下:

第五題明早專業英語課上寫.....已經錯過飯點了嗚; ;
第五題:給出可以確定胡蜂在華盛頓州滅絕的證據
為了確定一個物種的滅絕,最有效與常用的手段就是持續檢測,監測時間的長短極大地影響了結果,時間過短,有可能造成“遺漏”,從而種群又重新增長起來;時間過長,又可能造成人力物力的浪費,所以需要合理的評價物種滅絕的模型來對二者進行權衡.
REA(Rapid eradication assessment快速根除估計)模型經常被用來評價一個物種被滅絕的可能性,因為構建檢測網格在線上無法實作(數值模擬大約需要很多計算資源以及復雜的方程式,我們不是此專業并不了解),所以我們參考了兩篇經濟學報文章:有關一次島嶼上的田鼠滅除記錄的資料,我們更多地監測可能來自于群眾的目擊,因此,我們僅借用REA中的Bayesian logic 來確定在無目擊情況下物種消除成功的條件概率P(success | no detection),構建P(success | no detection),與P(detection)t ( 在時間t至少發現一只 Asian giant hornet的概率)之間的關系式,從而,用描述民眾目擊到的胡蜂個數來判斷胡蜂是否已被根除.
我們對P(detection)t取不同值進行模擬,選取時的臨界值作為判斷the eradication of vespa mandarinia的第一判據;
得到在不同發現概率的情況下所對應的根除成功率:
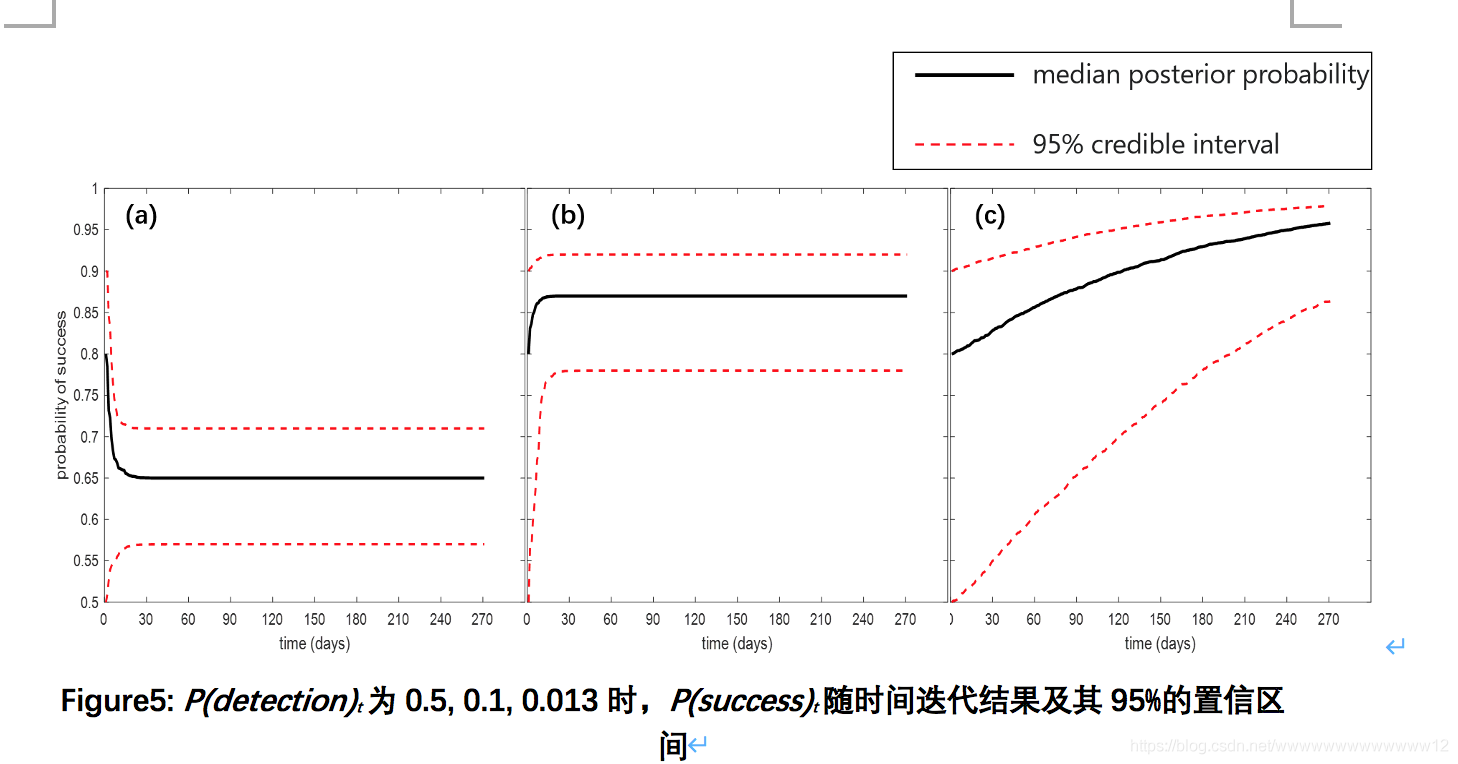
結果:顯然,當發現胡蜂的概率為0.013時,其確認滅除成功概率隨時間顯著遞增:
為此我們提出了判斷the eradication of vespa mandarinia的第一判據:一年中在華盛頓州發現Asian giant hornets的概率應小于0.013,即:每有1000個detetions,最終被證實存在Asian giant hornets的detection的數目應不超過13,
第二判據則參考實際情況,如果發現的是一只落單的胡蜂,但卻將其計入P_detection是不準確的,所以給出判斷此是否是一只落單胡蜂的判據二:
根據胡蜂的習性,它不會在距離巢穴八公里之外的地方覓食,以8km為半徑則以16km為直徑,那在其周圍的16km內若沒有發現其余的Asian giant hornet,我們可以近似認為這只Asian giant hornet是“被遺漏”的個體,且不具備繁殖能力,示意圖如下:
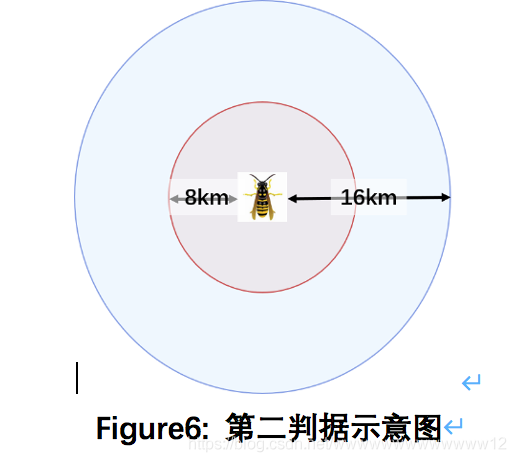
并以第二判據為基礎來修正第一判據.
綜合以上兩個判據提出最終的判別標準:
若公眾在一年以內觀察胡蜂出現概率,若其檢測概率小于1.3%(在95%置信區間下),且其周圍16km內均無發現新胡蜂,綜上兩者,可以順利地證明華盛頓州政府已經把有害生物的數量減少到一個安全的水平,政府可以公開宣布有害生物已經被徹底消滅,
至此,第五題結束.
總的來說,我覺得能拿到F的原因在于我們隊的論文有如下優點:
1.完整解決了題目中給出的問題
2.基于實用的角度和目標來著手做&回答問題
比如,在memo中插入了便于政府理解的圖片,以及在進行分類時顯著的分類特征:
即把題目當作正在解決的問題,以利于方便政府去著手處理的角度去寫論文.
3.學點機器學習(簡單又好用,直接調包大勝利)
可以找一些比較古老的書,里面說不定會有黑科技(比如影像配準)
4.最重要的,有靠譜的好隊友.
OVER~~!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281249.html
標籤:其他