語音信號(音頻;聲音)是模擬信號,現實生活中表現為連續的、平滑的波形,其橫坐標為時間軸,縱坐標表示聲音的強弱,
我們需要將其保存為數字信號再進行處理,
1. 聲音三要素
1.1 音調
人耳對聲音高低的感覺稱為音調,音調主要與聲波的頻率有關,聲波的頻率高,則音調也高,
人耳聽覺音頻范圍是20Hz-20000Hz

1.2 音量
人耳對聲音強弱的主觀感覺稱為響度,響度和聲波的振幅有關,一般說來,聲波振動幅度越大則響度也越大,

1.3 音色
音色是人們區別具有同樣響度、同樣音調的兩個聲音之所以不同的特性,或者說是人耳對各種頻率、各種強度的聲波的綜合反應,
音色與聲波的振動波形有關,或者說與聲音的頻譜結構有關,
2.語音信號四個重要引數
2.1 聲道數
為了播放聲音時能夠還原真實的聲場,在錄制聲音時在前后左右幾個不同的方位同時獲取聲音,每個方位的聲音就是一個聲道,
主要分為單聲道、雙聲道
2.2 采樣率(Sample rate)
每秒內對聲音信號采樣樣本的總數目,一般采樣率有8kHz、16kHz、32kHz、44.1kHz、48kHz等, (8kHz=8k/s, 每秒采樣8k個點)
采樣頻率越高,聲音的還原就越真實越自然,當然資料量就越大,
2.3 量化位數(Bit depth)
也稱為“位深”,每個采樣點中資訊的位元(bit)數,
2.4 碼率
也叫位元率,是指每秒傳送的bit數,單位為 bps(Bit Per Second),位元率越高,每秒傳送資料就越多,音質就越好,
碼率計算公式: 碼率 = 采樣率 * 采樣大小 * 聲道數
在對音頻進行壓縮時,位元率就成為了我們的一個要選的選項了,越高的位元率,其音質也就越好,
3. 冗余資訊
冗余資訊包括人類聽覺范圍之外的音頻信號和被掩蔽掉的音頻信號,
什么是被掩蔽的信號呢?信號的掩蔽分為頻域掩蔽和時域掩蔽,
3.1 時域掩蔽效應
在時間上相鄰的聲音之間有掩蔽現象,稱為時域掩蔽,
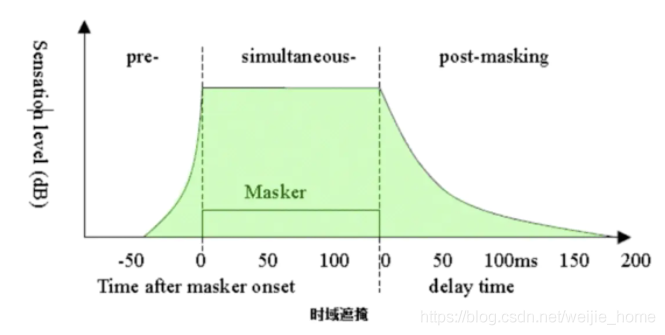
時域掩蔽又分為超前掩蔽和滯后掩蔽,如下圖所示,產生時域掩蔽的主要原因是人的大腦處理資訊需要花費一定的時間,
一般來說,超前掩蔽很短,只有大約5~20ms,而滯后掩蔽可以持續50~200ms,
3.2 頻域掩蔽效應
人類聽覺范圍是20-20000Hz,但這并不意味著只要是這個頻率范圍內的聲音都可以聽到,能否聽到還與聲音的分貝大小有關,
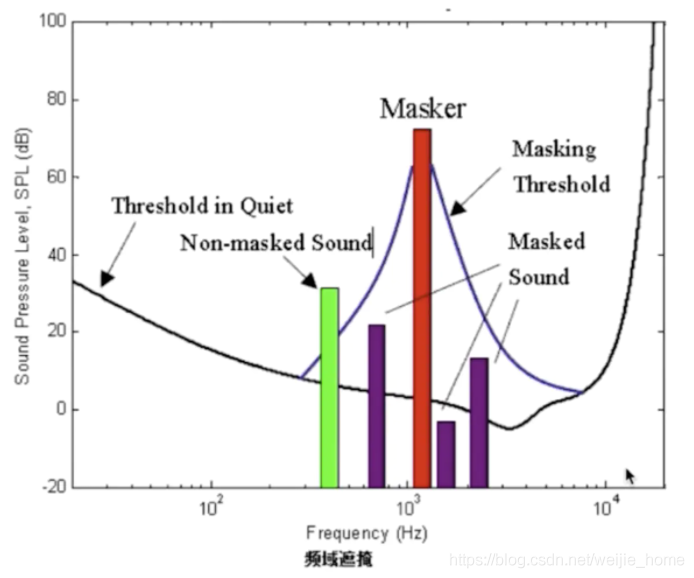
1)有個分貝臨界值,高于臨界值的聲音才能聽到,低于臨界值的聲音就聽不到,在不同的頻率下這個臨界值是不一樣的,
如下圖所示,橫坐標為頻率,縱坐標為分貝值,圖中的黑色曲線就是這個臨界值曲線,所以位于曲線下方的聲音是聽不到的,
2)還有一種情況,比如2個音調(頻率)差不多的人同時說話,一個聲音很大,一個聲音很小,聲音小的會受到聲音大的影響,導致聲音小的無法被聽到,
如下圖所示,紅色柱子是一個很大分貝的聲音,它會產生掩蔽效應將與它頻率相近的小分貝的聲音掩蔽掉,紅柱子兩邊的藍色曲線就是它的掩蔽范圍曲線,紫色柱子在它的掩蔽范圍內,所以聽不到的;而綠色柱子不在,所以可聽到,
4. python讀取音頻檔案的庫
4.1 wave
import wave
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示符號
file='E:/MEAD/database/MEAD-W017/audio/angry/0.wav'
# 檔案讀取
wave_read = wave.open(file,mode="rb")
# 回傳聲音信號的引數(聲道數、量化位數、采樣頻率、采樣點數、壓縮型別、壓縮型別的描述)
params = wave_read.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
# 讀取N個音頻資料(以取樣點為單位),回傳字串格式
str_data = wave_read.readframes(nframes) # ‘\x00\x00....’
# 關閉檔案
wave_read.close()
# 將字串轉換為陣列,得到一維的short型別的陣列
# 如果聲音檔案是雙聲道的,則它由左右兩個聲道的取樣交替構成:LR
wave_data = np.fromstring(str_data, dtype=np.short) # len: 采樣點數*2
# 賦值的歸一化
wave_data = wave_data * 1.0 / (max(abs(wave_data)))
# 整合左聲道和右聲道的資料
wave_data = np.reshape(wave_data, [nframes, nchannels])
# 最后通過采樣點數和取樣頻率計算出每個取樣的時間
time = np.arange(0, nframes) * (1.0 / framerate)
plt.figure()
# 左聲道波形
plt.subplot(2, 1, 1)
plt.plot(time, wave_data[:, 0])
plt.xlabel("時間/s",fontsize=14)
plt.ylabel("幅度",fontsize=14)
plt.title("左聲道",fontsize=14)
plt.grid() # 標尺
plt.subplot(2, 1, 2)
# 右聲道波形
plt.plot(time, wave_data[:, 1], c="g")
plt.xlabel("時間/s",fontsize=14)
plt.ylabel("幅度",fontsize=14)
plt.title("右聲道",fontsize=14)
plt.tight_layout() # 緊密布局
plt.show()4.2 scipy.io.wavfile
import numpy as np
import scipy.io.wavfile
from matplotlib import pyplot as plt
# 讀取資料,回傳采樣率和audio資料,如果是多通道signal為多維向量
file='E:/MEAD/database/MEAD-W017/audio/angry/0.wav'
sample_rate, signal = scipy.io.wavfile.read(file) # len: 采樣數
signal=signal[:,0]
original_signal = signal[0:int(1*sample_rate)]
sample_num = np.arange(len(original_signal))
# 繪圖
plt.figure(figsize=(11,7), dpi=500)
plt.subplot(212)
plt.plot(sample_num/sample_rate, original_signal, color='blue')
plt.xlabel("Time (sec)")
plt.ylabel("Amplitude")
plt.title("1s signal of Voice ")
plt.savefig('audio.png')4.3 librosa
import librosa
#回傳audio data 和采樣率; 回傳結果是經過歸一化處理的
#如果sr 預設,會默認以22050的采樣率讀取音頻
y, sr = librosa.load(file, sr=None) # len: 采樣數
# 可以讀取雙通道資料
# mono:該值為true時候是單通道、否則為雙通道
y, sr = librosa.core.load(file, sr=None,mono=False) # y:[2,采樣數]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281350.html
標籤:其他