Samples


Overview
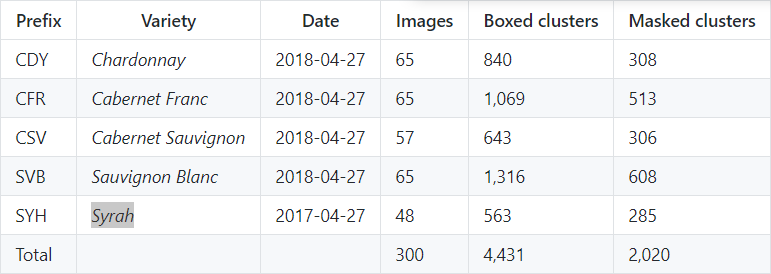
該資料集含有300張葡萄簇影像,用于物件檢測和實體分割,葡萄簇分為5類,共有4432個葡萄簇通過bounding box標記出來(一張圖上含有多個葡萄簇),其中有2020個葡萄簇進行了實體分割,詳情如下表所示
Data Format
從云盤下載解壓后如下圖所示
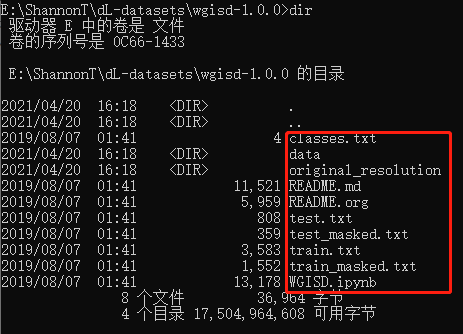
其中:
data -- 含有所有的圖片(jpg)、檢測框坐標(txt)以及影像掩碼標簽(npz)
original_resolution -- 葡萄簇的原圖(用于影像檢測、分割的圖片像素調低 )
train.txt/test.txt -- 官方推薦的用于物件檢測的訓練和測驗圖片
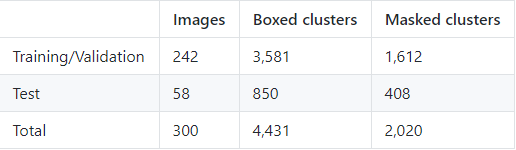
train_masked.txt/test_masked.txt -- 官方推薦的用于實體分割的訓練和測驗影像,詳情見下表
重點介紹下檢測框的資料格式
檢測框標簽采用txt檔案,每一行為一個葡萄簇,檢測框格式采用的是“YOLO format”
CLASS CX CY W H其中CLASS為整數,由于資料集不用作分類,故全為0,檢測框中心點坐標為:(CX,CY),采用浮點數的形式(0,1),如果要獲得絕對坐標,可以使用(2048CX,1365CY)(每張影像的寬*高均為2048*1365)
更多關于資料集的詳細資訊可以參考專案
https://github.com/thsant/wgisd
Dataset Maintenance
The dataset is hosted at Embrapa Agricultural Informatics and all comments or requests can be sent to Thiago T. Santos (maintainer).
掃碼關注后,后臺回復 grape 即可獲得

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281352.html
標籤:其他
上一篇:阿里云OSS C++SDK在VS15編譯提示無法識別外部鏈接GetObjectW的解決辦法
下一篇:C語言遞回函式分析