MapReduce提升
- Reduce負載過高
- 配置多個Reduce
- 動態指定
- 手動指定配置
- MapReduce磁區
- Shuffle自定義磁區
- 序列化與反序列化
- 多列資料
- 自定義資料類
- 拼接字串
- MapReduce程式的分類
- 三大階段
- 五大階段
- 排序
- 排序報錯
- 自定義資料類實作比較器介面
- 自定義資料型別實作自定義排序
- 自定義排序器實作自定義排序
MapReduce入門
Reduce負載過高
Input階段會讀取資料,并切片(split),之后Map程序中會有與切片數目相等的MapTask參與運算(一個split對應一個MapTask,MapTask的個數由split的個數決定),之前的案例都是單個Reduce運行,當單個ReduceTask處理的資料量過大時會導致負載很高、性能極差,當單機資源不足時(如:資料量>記憶體條容量)程式會執行失敗,這種情況就需要配置多個Reduce,
配置多個Reduce
動態指定
job.setNumReduceTasks(1);
這句用來設定Reduce的個數(默認為1個,寫不寫這句話效果都一樣),可以設定更多個(比如:設定2就是2個),
手動指定配置
conf.set("mapreduce.job.reduces","1");
這句會修改組態檔,影響使用該組態檔的所有程式,最好還是使用動態指定的方式(耦合度更低,靈活性更好),
MapReduce磁區
每個Reduce就是一個磁區,當有多個Reduce時,會按照一定的規則將所有Map的資料分配給不同的Reduce,在Map輸出后正常情況會進入Shuffle階段(五大階段的情況,,,當然三大階段的情況下會跳過Shuffle和Redue階段,直接Output),每一條Map階段輸出的資料(已經是KV鍵值對)都會呼叫磁區器來計算自己屬于哪個磁區(即歸屬哪個Reduce進行處理),
在idea按兩下shift搜索numpartition:
在這個Java類:
C:\Program Files\apache-maven-3.3.9\Maven_Repository\org\apache\hadoop\hadoop-mapreduce-client-core\2.7.5\hadoop-mapreduce-client-core-2.7.5.jar!\org\apache\hadoop\mapred\MapTask.class
的1345~1376行:
private static class OldOutputCollector<K, V> implements OutputCollector<K, V> {
private final org.apache.hadoop.mapred.Partitioner<K, V> partitioner;
private final MapOutputCollector<K, V> collector;
private final int numPartitions;
OldOutputCollector(MapOutputCollector<K, V> collector, JobConf conf) {
this.numPartitions = conf.getNumReduceTasks();
if (this.numPartitions > 1) {
this.partitioner = (org.apache.hadoop.mapred.Partitioner)ReflectionUtils.newInstance(conf.getPartitionerClass(), conf);
} else {
this.partitioner = new org.apache.hadoop.mapred.Partitioner<K, V>() {
public void configure(JobConf job) {
}
public int getPartition(K key, V value, int numPartitions) {
return numPartitions - 1;
}
};
}
this.collector = collector;
}
public void collect(K key, V value) throws IOException {
try {
this.collector.collect(key, value, this.partitioner.getPartition(key, value, this.numPartitions));
} catch (InterruptedException var4) {
Thread.currentThread().interrupt();
throw new IOException("interrupt exception", var4);
}
}
}
可以看到MapReduce的磁區原始碼,this.numPartitions = conf.getNumReduceTasks();會獲取Reduce的個數,作為磁區個數,如果磁區個數>1,就會通過反射的方式構建一個磁區器的實體,呼叫計算磁區編號的方法,如果reduce的個數=1,磁區只有1個,編號=0,所有資料都會放入編號為0的磁區,
collect就是在呼叫磁區器的磁區方法對K2和V2計算磁區,
在idea按2下shift搜索HashPartitioner:
在這個路徑:
C:\Program Files\apache-maven-3.3.9\Maven_Repository\org\apache\hadoop\hadoop-mapreduce-client-core\2.7.5\hadoop-mapreduce-client-core-2.7.5.jar!\org\apache\hadoop\mapred\lib\HashPartitioner.class
可以看到:
@Public
@Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public HashPartitioner() {
}
public void configure(JobConf job) {
}
public int getPartition(K2 key, V2 value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
MapReduce中默認的磁區器呼叫的是HashPartitioner,key的哈希值與一個最大值相與(運算后的數一定<這個最大值,確保不會有資料溢位的問題),之后在對ReduceTask的個數取余,這樣就可以給資料打標簽(后續分配給對應編號的ReduceTask),
這種方式可以使Key相同的資料保存在同一個Reduce中,減少后續排序和分組的作業量,
但是!!!不同Key的Hash值可能相同,取余的結果當然也可能相同,大量Key值相同的資料都由一個reduce處理,會有reduce空閑(浪費資源),負載并不平衡,
Shuffle自定義磁區
先自定義一個磁區器(繼承和重寫磁區器Partitioner):
package com.aa.partition;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
//自定義磁區器
//必須指定K2和V2的型別,重寫getPartition方法必須指定型別
public class UserPartition extends Partitioner<Text, IntWritable> {
/*
Map輸出的每一條資料會呼叫一次
K2為Map輸出的Key,V2為Map輸出的Value
numPartition為reduce個數
return回傳的是磁區的編號
*/
@Override
public int getPartition(Text K2, IntWritable V2, int numPartition) {//第三個引數為實作方法時自動生成,原抽象方法自帶,貌似暫時還沒什么卵用
//獲取當前地區
String region = K2.toString();
//判斷這個地區是否為浦東
if("浦東".equals(region)){
return 0;
}else
return 1;
}
}
在代碼中指定磁區器:
package com.aa.partition;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class SecondHouseCount extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(this.getConf(), "second house numb");
job.setJarByClass(SecondHouseCount.class);
job.setInputFormatClass(TextInputFormat.class);//可以不指定,默認是TextInputFormat
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\secondhouse.csv");//使用本地路徑作為程式輸入
TextInputFormat.setInputPaths(job, inputPath);
job.setMapperClass(SecondMapper.class);//用來設定Mapper類
job.setMapOutputKeyClass(Text.class);//設定K2的型別
job.setMapOutputValueClass(IntWritable.class);//設定V2的型別
job.setPartitionerClass(UserPartition.class);//設定磁區器
//job.setSortComparatorClass(null);//設定排序器
//job.setGroupingComparatorClass(null);//設定分組器
//job.setCombinerClass(null);//設定Map端聚合
job.setReducerClass(SecondReducer.class);//設定呼叫Reduce的類
job.setOutputKeyClass(Text.class);//設定K3的型別
job.setOutputValueClass(IntWritable.class);//設定V3的型別
job.setNumReduceTasks(2);//設定ReduceTask的個數,默認為1個
job.setOutputFormatClass(TextOutputFormat.class);//默認是使用TextOutputFormat
//設定輸出的路徑
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result1");
//判斷輸出路徑是否存在,存在就洗掉
FileSystem fs = FileSystem.get(this.getConf());
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
TextOutputFormat.setOutputPath(job, outputPath);
return job.waitForCompletion(true) ? 0 : -1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new SecondHouseCount(), args);
System.out.println("status = " + status);
System.exit(status);
}
public static class SecondMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//輸出K2
Text outputKey = new Text();
//輸出V2
IntWritable outputValue = new IntWritable(1);//不設定會導致結果=0
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//取出地區
String region = value.toString().split(",")[3];
//取出作為K2
this.outputKey.set(region);
//輸出
context.write(this.outputKey,this.outputValue);
}
}
//計算個數
//由于是陣列,可以把價格陣列求和/陣列長度=均價
public static class SecondReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//輸出V3
IntWritable outputValue=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
this.outputValue.set(sum);
context.write(key,this.outputValue);
}
}
}
和上一篇稿子的主要區別就是:
job.setPartitionerClass(UserPartition.class);//設定磁區器
job.setNumReduceTasks(2);//設定ReduceTask的個數,默認為1個
執行后:
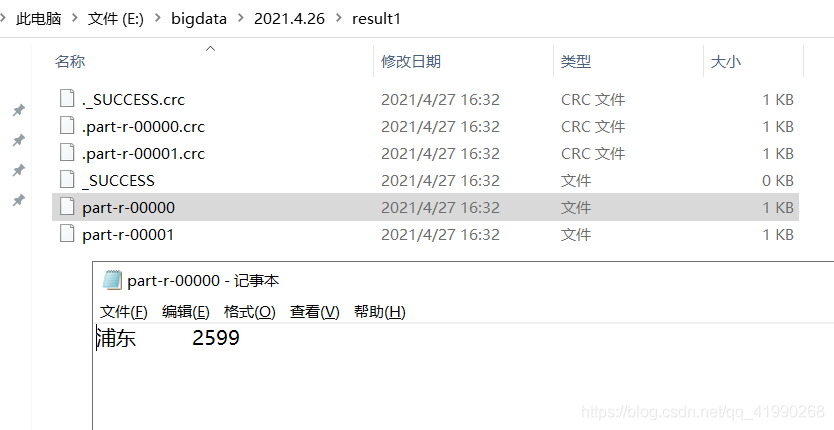
貌似負載不均衡:
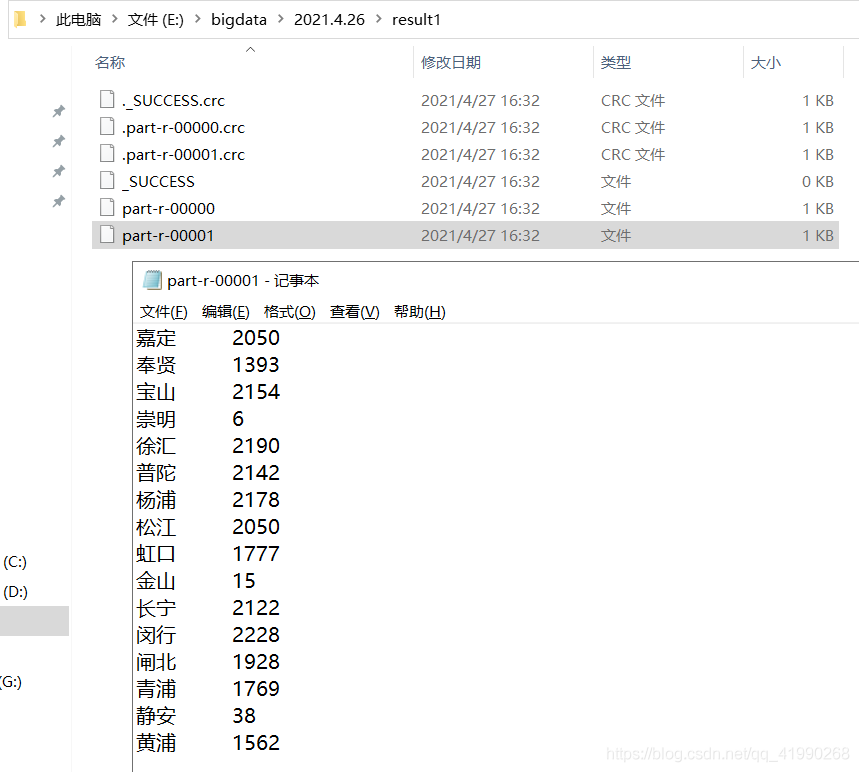
但依然成功分開了!!!
序列化與反序列化
Java傳遞資料時可以將數值直接賦值,但是傳遞物件時就沒那么直接了,,,好在Java可以使用序列化的方式將物件轉換為位元組,再通過反序列化的方式決議為物件,
例如可以這樣,先實作Writable再重寫序列化方法write和反序列化方法readFields獲得自定義資料型別的封裝類:
package com.aa.userbean;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//自定義資料型別實作3列輸出
public class Userbean1 implements Writable {
//給定屬性
private String firstKey;
private int secondKey;
//get 和 set
public String getFirstKey() {
return firstKey;
}
public void setFirstKey(String firstKey) {
this.firstKey = firstKey;
}
public int getSecondKey() {
return secondKey;
}
public void setSecondKey(int secondKey) {
this.secondKey = secondKey;
}
//toString方法
@Override
public String toString() {
return this.firstKey+"\t"+this.secondKey;
}
//序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.firstKey);
dataOutput.writeInt(this.secondKey);
}
//反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.firstKey= dataInput.readUTF();
this.secondKey= dataInput.readInt();
}
}
呼叫這個自定義資料類,由于其是字串+整型的雙列資料型別,可以實作3列輸出:
package com.aa.userbean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//自定義資料型別實作3列輸出
public class WordCountUserbean1 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountConcatString");
job.setJarByClass(WordCountUserbean1.class);
//配置Input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//配置Reducer
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Userbean1.class);
job.setOutputValueClass(IntWritable.class);
//配置Output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result3");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf,new WordCountUserbean1(),args);
System.exit(status);
}
public static class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//輸出的K2
Text outputKey = new Text();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.set(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<Text,IntWritable,Userbean1,IntWritable> {
//輸出K3
Userbean1 outputKey = new Userbean1();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.setFirstKey(key.toString());
this.outputKey.setSecondKey(key.toString().length());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
執行后:

需要注意的是:序列化時型別必須指定,反序列化時順序必須與序列化時一致,
多列資料
MapReduce中只能傳遞KV鍵值對,默認的資料型別只能各存盤一列導致只能處理雙列資料,實際上經常要處理多列資料,
自定義資料類
上述的自定義資料量是一個好辦法,
拼接字串
大體上還是一致的:
package com.aa.WordCountConcatString;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//連接字串實作3列輸出
public class WordCountConcatString extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountConcatString");
job.setJarByClass(WordCountConcatString.class);
//配置Input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//配置Reducer
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//配置Output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result2");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf,new WordCountConcatString(),args);
System.exit(status);
}
public static class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//輸出的K2
Text outputKey = new Text();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.set(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
//輸出K3
Text outputKey = new Text();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.set(key.toString()+"\t"+key.toString().length());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
重點是:
this.outputKey.set(key.toString()+"\t"+key.toString().length());
給字串追加了新內容,使得可以傳遞多列資料,但是這種方式使用不便,筆者更傾向于使用自定義資料類,
MapReduce程式的分類
三大階段
正常的程式執行都是三步走:輸入資料,運算,輸出顯示,MapReduce的三大階段是Input、Map、Output,閹割了Suffle和Reduce,∴速度更快,但是基本失去了統計分析資料的能力,適用于ETL資料清洗這類一對一的,不需要分組聚合/全域排序的操作,
還是使用之前的自定義資料類,
package com.aa.mapDirectOutput;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//自定義資料型別實作3列輸出
public class WordCountUserbean2 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountConcatString");
job.setJarByClass(WordCountUserbean2.class);
//配置Input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//配置Reducer
//job.setReducerClass(WCReducer.class);
//job.setOutputKeyClass(Userbean1.class);
//job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(0);//不走shuffle和reduce程序
//配置Output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result4");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf,new WordCountUserbean2(),args);
System.exit(status);
}
public static class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//輸出的K2
Text outputKey = new Text();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.set(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<Text,IntWritable, Userbean1,IntWritable> {
//輸出K3
Userbean1 outputKey = new Userbean1();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.setFirstKey(key.toString());
this.outputKey.setSecondKey(key.toString().length());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
僅僅這么一句:
job.setNumReduceTasks(0);//不走shuffle和reduce程序
就干掉了Shuffle和Reduce程序,,,
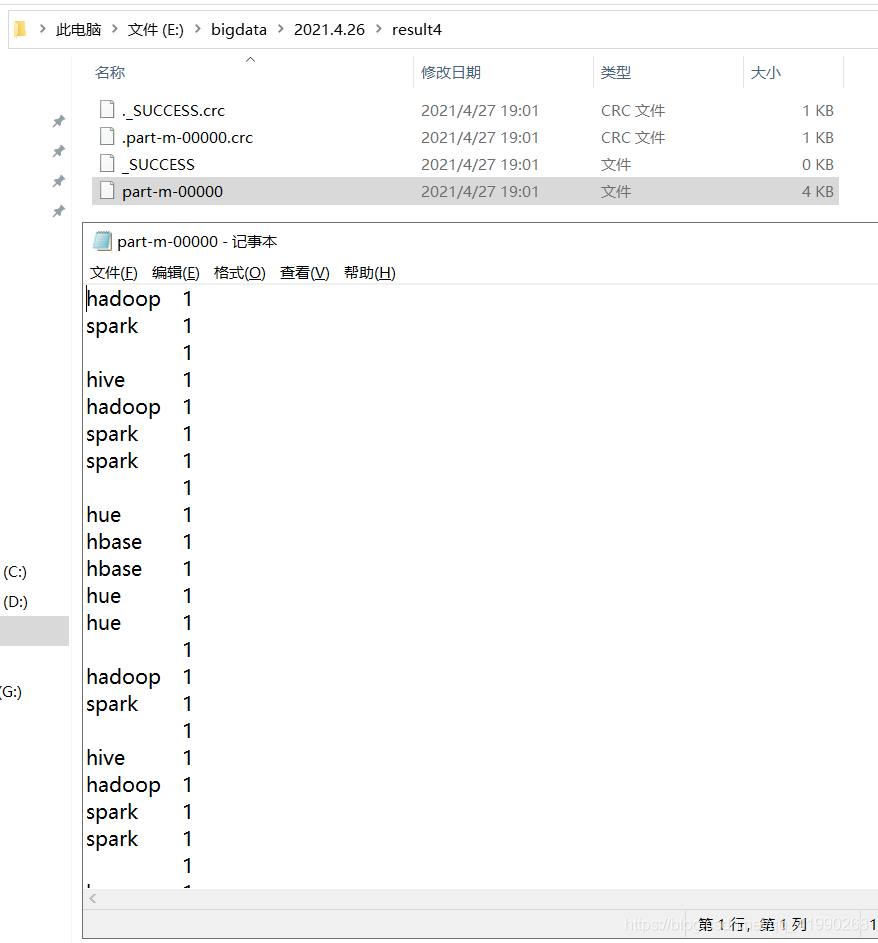
可以看出,排序、合并之類的操作都沒做,,,
五大階段
比三大階段多了:分組排序(Shuffle)和聚合(Reduce),速度慢,適合需要分組聚合/全域排序的操作,各種統計分析類的資料一般是這種多對一的,例如:統計平均值、最大值、最小值、個數,,,
只要有Reduce,之前必定有Shuffle,Shuffle對Map后的鍵值對資料進行了先排序后分組(提升了分組效率)的操作,分組后才能Reduce,
排序
排序報錯
還是使用之前的自定義資料類:
package com.aa.writableComparableDemo;
import com.aa.userbean.Userbean1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//自定義資料型別實作3列輸出
//故意報錯
public class WordCountUserbean1 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountConcatString");
job.setJarByClass(WordCountUserbean1.class);
//配置Input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Userbean1.class);
job.setMapOutputValueClass(IntWritable.class);
//配置Reducer
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Userbean1.class);
job.setOutputValueClass(IntWritable.class);
//配置Output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result5");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf,new WordCountUserbean1(),args);
System.exit(status);
}
public static class WCMapper extends Mapper<LongWritable, Text, Userbean1, IntWritable> {
//輸出的K2
Userbean1 outputKey = new Userbean1();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.setFirstKey(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<Userbean1,IntWritable,Userbean1,IntWritable> {
//輸出K3
Userbean1 outputKey = new Userbean1();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(Userbean1 key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.setFirstKey(key.toString());
this.outputKey.setSecondKey(key.toString().length());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
運行時,會報錯ClassCastException(型別轉換失敗):
21/04/27 20:43:50 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
21/04/27 20:43:50 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
21/04/27 20:43:52 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
21/04/27 20:43:52 INFO input.FileInputFormat: Total input paths to process : 1
21/04/27 20:43:52 INFO mapreduce.JobSubmitter: number of splits:1
21/04/27 20:43:52 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local943870422_0001
21/04/27 20:43:52 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
21/04/27 20:43:52 INFO mapreduce.Job: Running job: job_local943870422_0001
21/04/27 20:43:52 INFO mapred.LocalJobRunner: OutputCommitter set in config null
21/04/27 20:43:52 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/04/27 20:43:52 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
21/04/27 20:43:52 INFO mapred.LocalJobRunner: Waiting for map tasks
21/04/27 20:43:52 INFO mapred.LocalJobRunner: Starting task: attempt_local943870422_0001_m_000000_0
21/04/27 20:43:52 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/04/27 20:43:52 INFO util.ProcfsBasedProcessTree: ProcfsBasedProcessTree currently is supported only on Linux.
21/04/27 20:43:52 INFO mapred.Task: Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@1432bb71
21/04/27 20:43:52 INFO mapred.MapTask: Processing split: file:/E:/bigdata/2021.4.26/wc_reduced.txt:0+2626
21/04/27 20:43:52 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
21/04/27 20:43:52 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
21/04/27 20:43:52 INFO mapred.MapTask: soft limit at 83886080
21/04/27 20:43:52 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
21/04/27 20:43:52 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
21/04/27 20:43:52 WARN mapred.MapTask: Unable to initialize MapOutputCollector org.apache.hadoop.mapred.MapTask$MapOutputBuffer
java.lang.ClassCastException: class com.aa.userbean.Userbean1
at java.lang.Class.asSubclass(Class.java:3404)
at org.apache.hadoop.mapred.JobConf.getOutputKeyComparator(JobConf.java:887)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1004)
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:402)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:698)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:770)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
21/04/27 20:43:52 INFO mapred.LocalJobRunner: map task executor complete.
21/04/27 20:43:52 WARN mapred.LocalJobRunner: job_local943870422_0001
java.lang.Exception: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :class com.aa.userbean.Userbean1
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522)
Caused by: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :class com.aa.userbean.Userbean1
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:415)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:698)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:770)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassCastException: class com.aa.userbean.Userbean1
at java.lang.Class.asSubclass(Class.java:3404)
at org.apache.hadoop.mapred.JobConf.getOutputKeyComparator(JobConf.java:887)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1004)
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:402)
... 10 more
21/04/27 20:43:53 INFO mapreduce.Job: Job job_local943870422_0001 running in uber mode : false
21/04/27 20:43:53 INFO mapreduce.Job: map 0% reduce 0%
21/04/27 20:43:53 INFO mapreduce.Job: Job job_local943870422_0001 failed with state FAILED due to: NA
21/04/27 20:43:53 INFO mapreduce.Job: Counters: 0
Process finished with exit code 1
這是因為Shuffle中需要做排序和分組,本質是做比較,底層會按照K2進行比較,將K2強轉為比較器物件,類必須實作比較器的方法才能轉成功,
自定義資料類實作比較器介面
繼承Writable只能實作序列化和反序列化,還想要實作能參與比較就需要實作比較器介面WritableComparable,
package com.aa.writableComparableDemo;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//實作自定義資料型別并實作排序介面
public class UserBean2 implements WritableComparable<UserBean2> {
//給定屬性
private String firstKey;
private int secondKey;
@Override
public String toString() {
return this.firstKey+"\t"+this.secondKey;
}
//構造方法
public UserBean2() {
}
//get 和 set
public String getFirstKey() {
return firstKey;
}
public void setFirstKey(String firstKey) {
this.firstKey = firstKey;
}
public int getSecondKey() {
return secondKey;
}
public void setSecondKey(int secondKey) {
this.secondKey = secondKey;
}
//重寫比較方法
@Override
public int compareTo(UserBean2 o) {
//先比較第一個屬性
int comp = this.getFirstKey().compareTo(o.getFirstKey());
if (comp == 0) {
return Integer.valueOf(this.getSecondKey()).compareTo(Integer.valueOf(this.getSecondKey()));
}
return comp;
}
//序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.firstKey);//型別必須一致
dataOutput.writeInt(this.secondKey);
}
//反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.firstKey = dataInput.readUTF();
this.secondKey = dataInput.readInt();
}
}
package com.aa.writableComparableDemo;
import com.aa.userbean.Userbean1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//自定義資料型別實作3列輸出
//實作自定義資料型別并實作排序介面
public class WordCountUserbean2 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountConcatString");
job.setJarByClass(WordCountUserbean2.class);
//配置Input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(UserBean2.class);
job.setMapOutputValueClass(IntWritable.class);
//配置Reducer
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(UserBean2.class);
job.setOutputValueClass(IntWritable.class);
//配置Output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result6");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf,new WordCountUserbean2(),args);
System.exit(status);
}
public static class WCMapper extends Mapper<LongWritable, Text, UserBean2, IntWritable> {
//輸出的K2
UserBean2 outputKey = new UserBean2();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.setFirstKey(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<UserBean2,IntWritable,UserBean2,IntWritable> {
//輸出K3
UserBean2 outputKey = new UserBean2();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(UserBean2 key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.setFirstKey(key.toString());
this.outputKey.setSecondKey(key.toString().length());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
重寫后即可正確運行,自定義資料類參與了K2排序,
MapReduce中排序(Shuffle)是很重要的一步,可以提高分組的性能,
排序實作時:先呼叫排序器,如果沒有排序器,呼叫K2的compareTo方法,
自定義資料型別實作自定義排序
package com.aa.sort;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//自定義資料型別比較器,倒序排列
public class UserBean3 implements WritableComparable<UserBean3> {
private String firstKey;
private int secondKey;
@Override
public String toString() {
return this.firstKey + "\t" + this.secondKey;
}
public String getFirstKey() {
return firstKey;
}
public void setFirstKey(String firstKey) {
this.firstKey = firstKey;
}
public int getSecondKey() {
return secondKey;
}
public void setSecondKey(int secondKey) {
this.secondKey = secondKey;
}
//無參構造方法
public UserBean3() {
}
@Override
public int compareTo(UserBean3 o) {
//先比較第一個屬性
int comp = this.getFirstKey().compareTo(o.firstKey);
if (comp == 0) {
return Integer.valueOf(this.secondKey).compareTo(Integer.valueOf(o.getSecondKey()));
}
return -comp;
}
//序列化方法
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.firstKey);//必須與序列化的順序保持一致
dataOutput.writeInt(this.secondKey);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.firstKey = dataInput.readUTF();
this.secondKey = dataInput.readInt();
}
}
package com.aa.sort;
import com.aa.writableComparableDemo.UserBean2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//自定義資料型別實作3列輸出
//實作自定義資料型別并實作排序介面,倒序排列
public class WordCountUserbean3 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountConcatString");
job.setJarByClass(WordCountUserbean3.class);
//配置Input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(UserBean3.class);
job.setMapOutputValueClass(IntWritable.class);
//配置Reducer
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(UserBean3.class);
job.setOutputValueClass(IntWritable.class);
//配置Output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result7");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf,new WordCountUserbean3(),args);
System.exit(status);
}
public static class WCMapper extends Mapper<LongWritable, Text, UserBean3, IntWritable> {
//輸出的K2
UserBean3 outputKey = new UserBean3();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.setFirstKey(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<UserBean3,IntWritable,UserBean3,IntWritable> {
//輸出K3
UserBean3 outputKey = new UserBean3();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(UserBean3 key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.setFirstKey(key.toString());
this.outputKey.setSecondKey(key.toString().length());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
大同小異,重點是重寫compareTo方法,由于MapReduce會按照比較器回傳的數值來排序,只需要+個負號就可以實作降序排列,
自定義排序器實作自定義排序
package com.aa.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
//自定義比較器排序
public class UserSort extends WritableComparator {
//注冊
public UserSort() {
super(Text.class,true);
}
//實作比較
@Override
public int compare(WritableComparable a, WritableComparable b) {
//將兩個比較器物件強轉為要比較的Text型別
Text t1 = (Text)a;
Text t2 = (Text)b;
//實作2個Text型別的比較,降序排序
return -t1.toString().compareTo(t2.toString());
}
}
package com.aa.sort;
import com.aa.userbean.Userbean1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//自定義比較器排序
public class WordCountUserSort extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//構建
Job job = Job.getInstance(this.getConf(),"WordCountUserSort");
job.setJarByClass(WordCountUserSort.class);
//配置
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path("E:\\bigdata\\2021.4.26\\wc_reduced.txt");
TextInputFormat.setInputPaths(job,inputPath);
//配置Map
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//配置shuffle
job.setSortComparatorClass(UserSort.class);
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path("E:\\bigdata\\2021.4.26\\result8");
FileSystem fs = FileSystem.get(this.getConf());
if(fs.exists(outputPath)){
System.out.println("--*********已經有該目錄********--");
//fs.delete(outputPath,true);
}
TextOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf =new Configuration();
System.exit(ToolRunner.run(conf,new WordCountUserSort(),args));
}
public static class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//輸出的K2
Text outputKey = new Text();
//輸出的V2
IntWritable outputValue = new IntWritable(1);//由于是平權的,使之恒=1便可以計數
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//將每行的內容分割得到每個單詞
String[] words = value.toString().split("\\s+");
//迭代取出每個單詞作為K2
for (String word : words) {
//將當前的單詞作為K2
this.outputKey.set(word);
//將K2和V2傳遞到下一步
context.write(outputKey,outputValue);
}
}
}
public static class WCReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
//輸出K3
Text outputKey = new Text();
//輸出V3
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//給K3賦值
this.outputKey.set(key.toString());
//給V3賦值
this.outputValue.set(sum);
//傳遞到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
Java中String可以表達其余的基本資料型別,對應地,MapReduce中Text也可以表示其余的基本資料型別,故可以先強制轉換為Text再進行比較,,,
雖然MapReduce已經接近淘汰,但其先分后合的設計思想現在看來還是值得深入學習和研究的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281436.html
標籤:其他