MapReduce概述及其Wordcount案例
- 一、MapReduce簡介
- 二、MapReduce核心思想
- 三、MapReduce實體行程
- 四、MapReduce程式組成
- 五、WordCount實作
一、MapReduce簡介
- Mapreduce是一個分布式運算程式的編程框架,是用戶開發“基于hadoop的資料分析應用”的核心框架;其思想來源于Google的MapReduce,Mapreduce核心功能是將用戶撰寫的業務邏輯代碼和自帶默認組件整合成一個完整的分布式運算程式,并發運行在一個hadoop集群上,
二、MapReduce核心思想
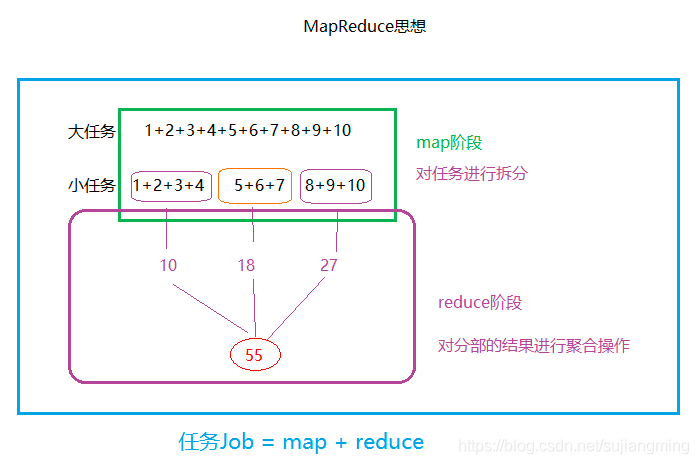
- 簡單而言,就是拆分的思想,即“分而治之”,大任務被拆分成小的任務并行計算,具體如下:
- 1)分布式的運算程式往往需要分成至少2個階段,
- 2)第一個階段的maptask并發實體,完全并行運行,互不相干,
- 3)第二個階段的reduce task并發實體互不相干,但是他們的資料依賴于上一個階段的所有maptask并發實體的輸出,
- 4)MapReduce編程模型只能包含一個map階段和一個reduce階段,如果用戶的業務邏輯非常復雜,那就只能多個mapreduce程式,串行運行,
三、MapReduce實體行程
- 一個完整的mapreduce程式在分布式運行時有三類實體行程:

四、MapReduce程式組成
- 用戶撰寫的程式分成三個部分:Mapper,Reducer,Driver(提交運行mr程式的客戶端)

五、WordCount實作
-
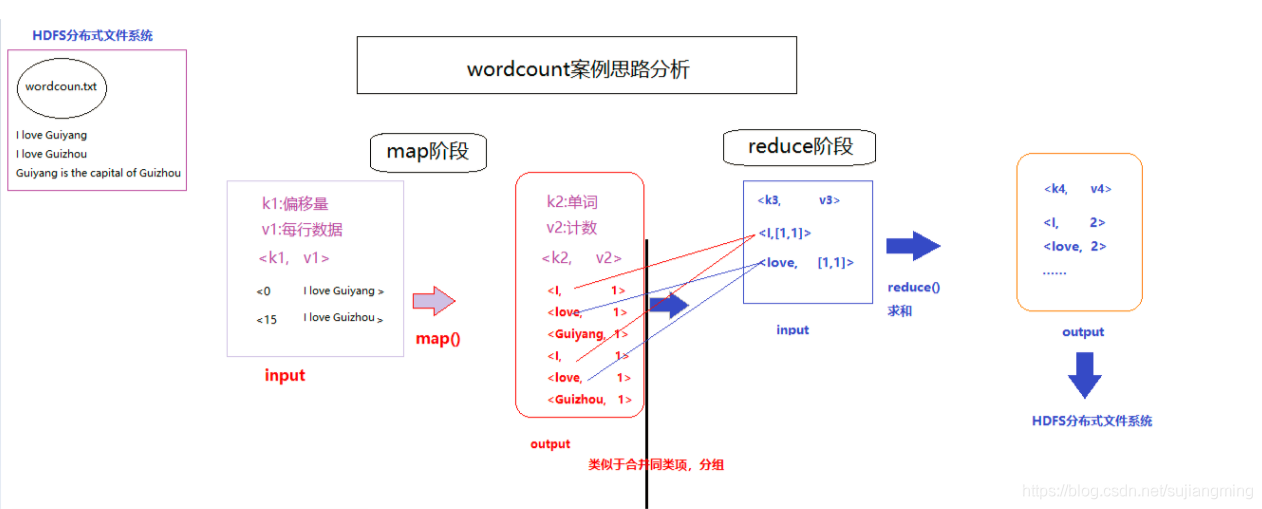
分析MapReduce經典案例Wordcount的設計思路及資料處理程序
-
測驗資料,如wordcount.txt文本,內容如下:
I love Guiyang I love Guizhou Guiyang is the capical of Guizhou -
定義
WordCountMapper,繼承于Hadoop的Mapperimport org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // key 偏移量 value 每行文本:I love Guiyang // 按照空格對每行文本進行分詞操作:[I,love,Guiyang] String line = value.toString(); // 資料型別的轉換 String[] words = line.split(" "); // 對字串進行拆分 [I,love,Guiyang] for (int i = 0; i < words.length; i++) { // (I,1) Text word = new Text(words[i]); IntWritable value2 = new IntWritable(1); context.write(word,value2); } } } -
定義
WordCountReducer,繼承于Hadoop的Reducerimport org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> { @Override protected void reduce(Text k3, Iterable<IntWritable> v3, Context context) throws IOException, InterruptedException { // 進行求和操作,需要計算v3的長度 // <I,[1,1]> int count = 0; for (IntWritable v: v3) { int value = v.get(); count += value; } context.write(k3,new IntWritable(count)); } } -
定義
WordCountJobimport org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountJob { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 實列化Job Job job = Job.getInstance(); job.setJarByClass(WordCountJob.class); // 設定Mapper job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 設定Reducer job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 指明輸入檔案的路徑 FileInputFormat.setInputPaths(job,new Path("d:/wordcount.txt")); // 指明輸出檔案的路徑 FileOutputFormat.setOutputPath(job,new Path("d:/mr_result/wc01")); // 開始運行任務 boolean completion = job.waitForCompletion(true); if (completion){ System.out.println("程式運行成功~"); }else { System.out.println("程式運行失敗~"); } } } -
本地運行,測驗其功能是否正常
打開結果檔案part-r-00000,內容如下:

-
將程式打包,上傳到服務器,利用hadoop命令執行程式(讀者自行打包)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281440.html
標籤:其他