目錄
Transformation
官網API串列
基本操作-略
map
flatMap
???????keyBy
???????filter
???????sum
???????reduce
???????代碼演示
???????合并-拆分
???????union和connect
???????split、select和Side Outputs
磁區
rebalance重平衡磁區
???????其他磁區
Transformation
官網API串列
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/
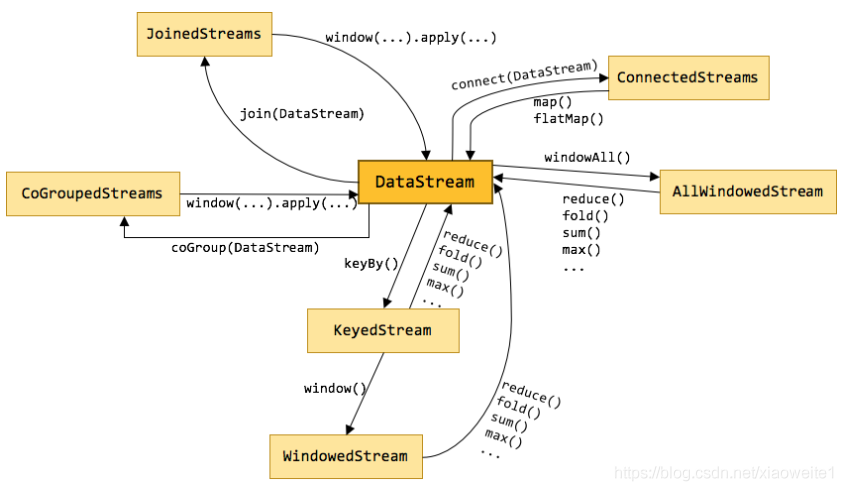
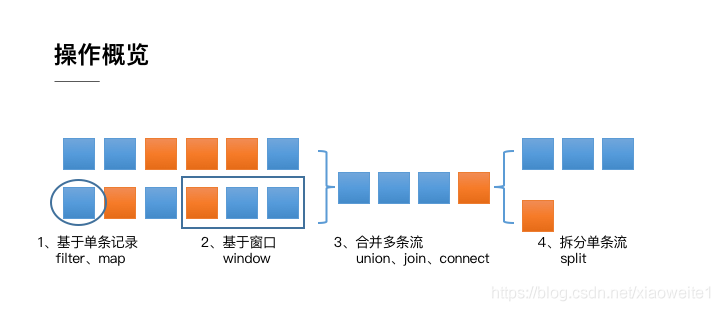
整體來說,流式資料上的操作可以分為四類,
l第一類是對于單條記錄的操作,比如篩除掉不符合要求的記錄(Filter 操作),或者將每條記錄都做一個轉換(Map 操作)
l第二類是對多條記錄的操作,比如說統計一個小時內的訂單總成交量,就需要將一個小時內的所有訂單記錄的成交量加到一起,為了支持這種型別的操作,就得通過 Window 將需要的記錄關聯到一起進行處理
l第三類是對多個流進行操作并轉換為單個流,例如,多個流可以通過 Union、Join 或 Connect 等操作合到一起,這些操作合并的邏輯不同,但是它們最終都會產生了一個新的統一的流,從而可以進行一些跨流的操作,
l最后, DataStream 還支持與合并對稱的拆分操作,即把一個流按一定規則拆分為多個流(Split 操作),每個流是之前流的一個子集,這樣我們就可以對不同的流作不同的處理,
基本操作-略
map
- API
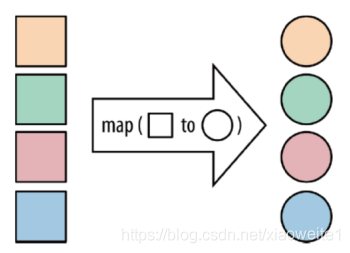
map:將函式作用在集合中的每一個元素上,并回傳作用后的結果
???????flatMap
- API
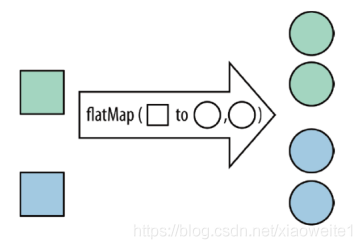
flatMap:將集合中的每個元素變成一個或多個元素,并回傳扁平化之后的結果
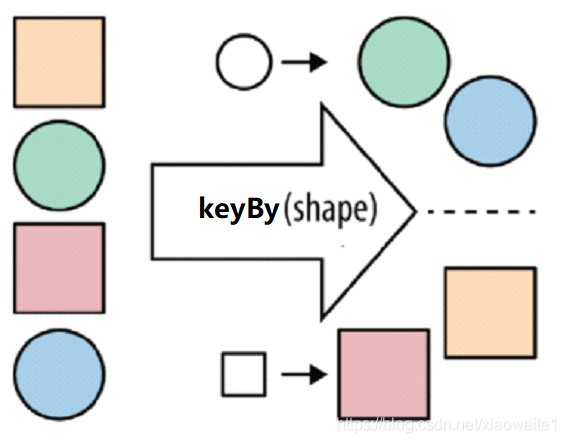
???????keyBy
按照指定的key來對流中的資料進行分組,前面入門案例中已經演示過
注意:
流處理中沒有groupBy,而是keyBy
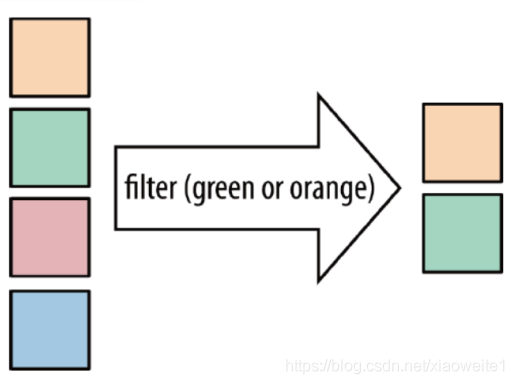
???????filter
- API
filter:按照指定的條件對集合中的元素進行過濾,過濾出回傳true/符合條件的元素
???????sum
- API
sum:按照指定的欄位對集合中的元素進行求和
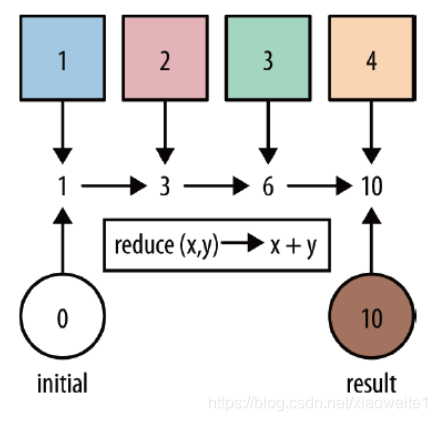
???????reduce
- API
reduce:對集合中的元素進行聚合
???????代碼演示
- 需求:
對流資料中的單詞進行統計,排除敏感詞TMD
- 代碼演示
package cn.itcast.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Author itcast
* Desc
*/
public class TransformationDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStream<String> linesDS = env.socketTextStream("node1", 9999);
//3.處理資料-transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value就是一行行的資料
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//將切割處理的一個個的單詞收集起來并回傳
}
}
});
DataStream<String> filtedDS = wordsDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return !value.equals("heihei");
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = filtedDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value就是進來一個個的單詞
return Tuple2.of(value, 1);
}
});
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
DataStream<Tuple2<String, Integer>> result1 = groupedDS.sum(1);
DataStream<Tuple2<String, Integer>> result2 = groupedDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value1.f1);
}
});
//4.輸出結果-sink
result1.print("result1");
result2.print("result2");
//5.觸發執行-execute
env.execute();
}
}
???????合并-拆分
???????union和connect
- API
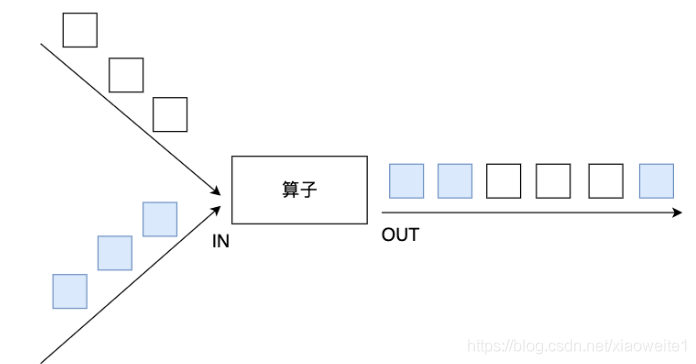
union:
union算子可以合并多個同型別的資料流,并生成同型別的資料流,即可以將多個DataStream[T]合并為一個新的DataStream[T],資料將按照先進先出(First In First Out)的模式合并,且不去重,
connect:
connect提供了和union類似的功能,用來連接兩個資料流,它與union的區別在于:
connect只能連接兩個資料流,union可以連接多個資料流,
connect所連接的兩個資料流的資料型別可以不一致,union所連接的兩個資料流的資料型別必須一致,
兩個DataStream經過connect之后被轉化為ConnectedStreams,ConnectedStreams會對兩個流的資料應用不同的處理方法,且雙流之間可以共享狀態,
- 需求
將兩個String型別的流進行union
將一個String型別和一個Long型別的流進行connect
- 代碼實作
package cn.itcast.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
* Author itcast
* Desc
*/
public class TransformationDemo02 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//3.Transformation
DataStream<String> result1 = ds1.union(ds2);//合并但不去重 https://blog.csdn.net/valada/article/details/104367378
ConnectedStreams<String, Long> tempResult = ds1.connect(ds3);
//interface CoMapFunction<IN1, IN2, OUT>
DataStream<String> result2 = tempResult.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String value) throws Exception {
return "String->String:" + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long->String:" + value.toString();
}
});
//4.Sink
result1.print();
result2.print();
//5.execute
env.execute();
}
}
???????split、select和Side Outputs
- API
Split就是將一個流分成多個流
Select就是獲取分流后對應的資料
注意:split函式已過期并移除
Side Outputs:可以使用process方法對流中資料進行處理,并針對不同的處理結果將資料收集到不同的OutputTag中
- 需求:
對流中的資料按照奇數和偶數進行分流,并獲取分流后的資料
- 代碼實作:
package cn.itcast.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* Author itcast
* Desc
*/
public class TransformationDemo03 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//3.Transformation
/*SplitStream<Integer> splitResult = ds.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
//value是進來的數字
if (value % 2 == 0) {
//偶數
ArrayList<String> list = new ArrayList<>();
list.add("偶數");
return list;
} else {
//奇數
ArrayList<String> list = new ArrayList<>();
list.add("奇數");
return list;
}
}
});
DataStream<Integer> evenResult = splitResult.select("偶數");
DataStream<Integer> oddResult = splitResult.select("奇數");*/
//定義兩個輸出標簽
OutputTag<Integer> tag_even = new OutputTag<Integer>("偶數", TypeInformation.of(Integer.class));
OutputTag<Integer> tag_odd = new OutputTag<Integer>("奇數"){};
//對ds中的資料進行處理
SingleOutputStreamOperator<Integer> tagResult = ds.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception {
if (value % 2 == 0) {
//偶數
ctx.output(tag_even, value);
} else {
//奇數
ctx.output(tag_odd, value);
}
}
});
//取出標記好的資料
DataStream<Integer> evenResult = tagResult.getSideOutput(tag_even);
DataStream<Integer> oddResult = tagResult.getSideOutput(tag_odd);
//4.Sink
evenResult.print("偶數");
oddResult.print("奇數");
//5.execute
env.execute();
}
}
磁區
rebalance重平衡磁區
- API
類似于Spark中的repartition,但是功能更強大,可以直接解決資料傾斜
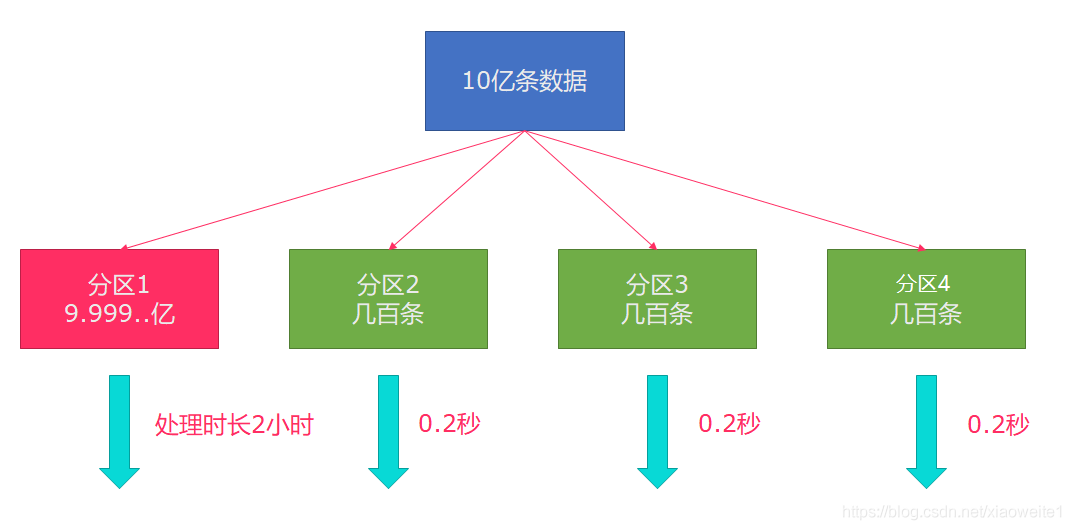
Flink也有資料傾斜的時候,比如當前有資料量大概10億條資料需要處理,在處理程序中可能會發生如圖所示的狀況,出現了資料傾斜,其他3臺機器執行完畢也要等待機器1執行完畢后才算整體將任務完成;
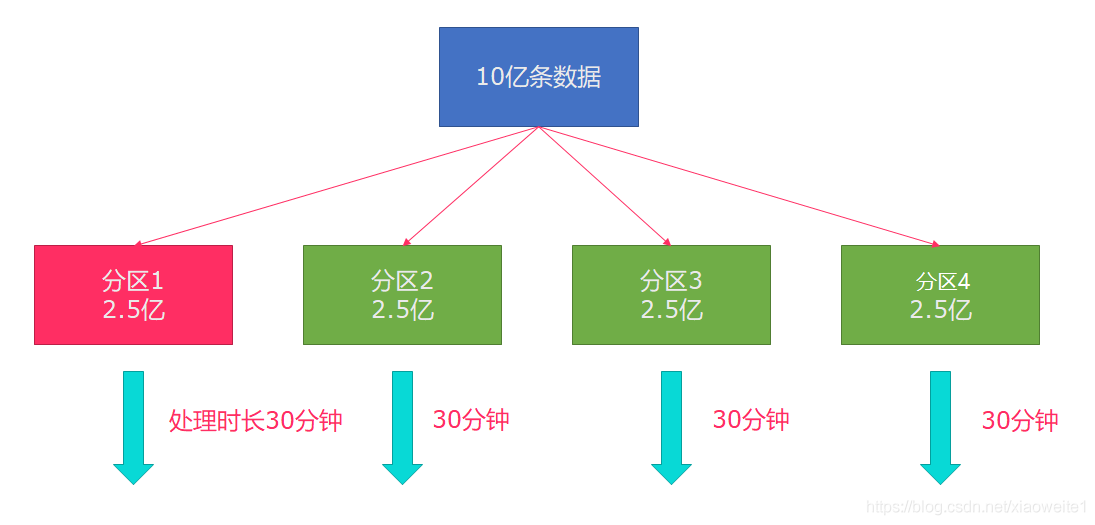
所以在實際的作業中,出現這種情況比較好的解決方案就是rebalance(內部使用round robin方法將資料均勻打散)
- 代碼演示:
package cn.itcast.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author itcast
* Desc
*/
public class TransformationDemo04 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC).setParallelism(3);
//2.source
DataStream<Long> longDS = env.fromSequence(0, 100);
//3.Transformation
//下面的操作相當于將資料隨機分配一下,有可能出現資料傾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
//接下來使用map操作,將資料轉為(磁區編號/子任務編號, 資料)
//Rich表示多功能的,比MapFunction要多一些API可以供我們使用
DataStream<Tuple2<Integer, Integer>> result1 = filterDS
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//獲取磁區編號/子任務編號
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
DataStream<Tuple2<Integer, Integer>> result2 = filterDS.rebalance()
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//獲取磁區編號/子任務編號
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
//4.sink
//result1.print();//有可能出現資料傾斜
result2.print();//在輸出前進行了rebalance重磁區平衡,解決了資料傾斜
//5.execute
env.execute();
}
}
???????其他磁區
- API
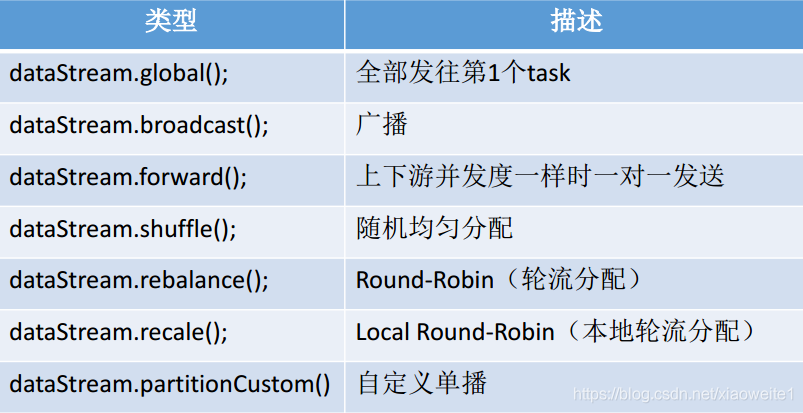
說明:
recale磁區,基于上下游Operator的并行度,將記錄以回圈的方式輸出到下游Operator的每個實體,
舉例:
上游并行度是2,下游是4,則上游一個并行度以回圈的方式將記錄輸出到下游的兩個并行度上;上游另一個并行度以回圈的方式將記錄輸出到下游另兩個并行度上,若上游并行度是4,下游并行度是2,則上游兩個并行度將記錄輸出到下游一個并行度上;上游另兩個并行度將記錄輸出到下游另一個并行度上,
- 需求:
對流中的元素使用各種磁區,并輸出
- 代碼實作
package cn.itcast.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Author itcast
* Desc
*/
public class TransformationDemo05 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> linesDS = env.readTextFile("data/input/words.txt");
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
//3.Transformation
DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();
DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();
DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();
DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();
DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();
DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();
DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
return key.equals("hello") ? 0 : 1;
}
}, t -> t.f0);
//4.sink
//result1.print();
//result2.print();
//result3.print();
//result4.print();
//result5.print();
//result6.print();
result7.print();
//5.execute
env.execute();
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281622.html
標籤:其他