前言:
本專欄在保證內容完整性的基礎上,力求簡潔,旨在讓初學者能夠更快地、高效地入門TensorFlow2 深度學習框架,如果覺得本專欄對您有幫助的話,可以給一個小小的三連,各位的支持將是我創作的最大動力!
系列文章匯總:TensorFlow2 入門指南
Github專案地址:https://github.com/Keyird/TensorFlow2-for-beginner
文章目錄
- 一、資料型別
- (1) 字串型
- (2) 布爾型別
- (3) 整型、浮點型
- (4) 張量轉換
- (5) 數值型別
- (6) 待訓練張量
- 二、創建張量Tensor
- (1) 創建全0、全1張量
- (2) 創建自定義數值張量
- (3) 創建已知分布的張量
- (4) 創建序列
- (5) 從 Numpy、List 物件創建張量
- 三、索引與切片
- (1) 索引
- (2) 切片
- 四、維度變換
- 五、廣播機制
- 六、數學運算
- 七、前向傳播實戰
- (1) 匯入相關庫:
- (2) 資料集準備:
- (3) 初始化變數
- (4) 迭代訓練
TensorFlow2 是一個面向于深度學習演算法的科學計算庫,內部資料均以張量形式保存,所有的運算操作也都是基于張量進行的,復雜的神經網路演算法本質上就是各種張量相乘、相加等基本運算操作的組合,所以在學習神經網路演算法之前,我們先來了解一下 TensorFlow2 張量的基礎操作方法~

一、資料型別
(1) 字串型
通過tf.constant()即可創建字串型別的張量:
s = tf.constant('Hello, TensoeFlow2!')
在 tf.strings 模塊中,提供了常見的字串型的工具函式,如拼接 join(),長度 length(),切分 split(),轉換小寫lower() 等等:
tf.strings.lower(s)
深度學習演算法主要還是以數值型別張量運算為主,字串型別的資料使用頻率較低,我們不做過多闡述,
(2) 布爾型別
布爾型別張量的創建方式如下:
a = tf.constant(True)
傳入布爾型別的向量:
a = tf.constant([True, False])
需要注意的是,TensorFlow 的布爾型別和 Python 語言的布爾型別并不對等,不能通用,
(3) 整型、浮點型
創建一個數值型別為整型的張量:
a = tf.constant(12, dtype=tf.int16)
創建一個數值型別為浮點型的張量:
b = tf.constant(12.5698, dtype=tf.float32)
(4) 張量轉換
當然,我們也能對張量中資料的精度以及型別進行轉換:
對精度進行轉換:
a = tf.constant(12.5698, dtype=tf.float32)
a = tf.cast(a, tf.float64)
對型別進行轉換:
b = tf.constant(12, dtype=tf.int16)
tf.cast(b, tf.double)
(5) 數值型別
數值型別的張量是 TensorFlow 的主要資料載體,主要分為:標量、向量、矩陣、張量(維度大于2)
創建標量,注意必須通過 TensorFlow 規定的方式去創建張量,而不能使用 Python 語言的標準變數創建方式,
a = tf.constant(1.2)
創建兩個元素的向量:
b = tf.constant([1,2, 3.])
同樣的方法來定義矩陣:
c = tf.constant([[1,2],[3,4]])
三維張量可以定義為:
d = tf.constant([[[1,2],[3,4]],[[5,6],[7,8]]])
(6) 待訓練張量
在深度學習網路訓練程序中,需要通過TensorFlow來建立梯度更新環境,用來對引數進行更新,為了區分需要計算梯度資訊的張量與不需要計算梯度資訊的張量,TensorFlow 增加了一種專門的資料型別來支持梯度資訊的記錄:tf.Variable,
tf.Variable 型別在普通的張量型別基礎上添加了 name,trainable 等屬性來支持計算圖的構建,由于梯度運算會消耗大量的計算資源,而且會自動更新相關引數,對于不需要的優化的張量,如神經網路的輸入 X,不需要通過 tf.Variable 封裝;相反,對于需要計算梯度并優化的張量,如神經網路層的W和𝒃,需要通過 tf.Variable 包裹以便 TensorFlow 跟蹤相關梯度資訊,
下面,通過 tf.Variable()函式可以將普通張量轉換為待優化張量:
a = tf.constant([-1, 0, 1, 2])
a = tf.Variable(a)
當然,也可以直接創建待訓練張量:
a = tf.Variable([[1,2],[3,4]])
待優化張量可看做普通張量的特殊型別,普通張量也可以通過 GradientTape.watch()方法臨時加入跟蹤梯度資訊的串列,
二、創建張量Tensor
(1) 創建全0、全1張量
創建全 0 和全 1 的向量:
tf.zeros([1]), tf.ones([1])
創建全 0 和全 1 的矩陣:
tf.zeros([2,2]), tf.ones([3,2])
通過 tf.zeros_like, tf.ones_like 可以方便地新建與某個張量 shape 一致,內容全 0 或全 1 的張量,例如,創建與張量 a 形狀一樣的全 0 張量:
a = tf.ones([4,5])
tf.zeros_like(a)
創建與張量 a 形狀一樣的全 1 張量:
a = tf.ones([4,5])
tf.ones_like(a)
(2) 創建自定義數值張量
除了初始化為全 0,或全 1 的張量之外,有時也需要全部初始化為某個自定義數值的張量,比如將張量的數值全部初始化為-1 等,通過 tf.fill(shape, value)可以創建全為自定義數值 value 的張量,
創建所有元素為-1 的向量:
tf.fill([1], -1)
創建所有元素為 9 的矩陣:
tf.fill([2,2], 9)
(3) 創建已知分布的張量
正態分布(Normal Distribution)和均勻分布(Uniform Distribution)是最常見的分布之一,創建采樣自這 2 種分布的張量非常有用,比如在卷積神經網路中,卷積核張量 W 初始化為正態分布有利于網路的訓練;在對抗生成網路中,隱藏變數 z 一般采樣自均勻分布,
通過 tf.random.normal(shape, mean=0.0, stddev=1.0)可以創建形狀為 shape,均值為mean,標準差為 stddev 的正態分布,例如,創建均值為 0,標準差為 1的正太分布:
tf.random.normal([2,2])
創建均值為 1,標準差為 2 的正太分布:
tf.random.normal([2,2], mean=1,stddev=2)
通過 tf.random.uniform(shape, minval=0, maxval=None, dtype=tf.float32)可以創建采樣自 [𝑚𝑖𝑛𝑣𝑎𝑙, 𝑚𝑎𝑥𝑣𝑎𝑙] 區間的均勻分布的張量,
例如創建采樣自區間[0,1],shape 為[2,2]的矩陣:
tf.random.uniform([2,2])
創建采樣自區間[0,10],shape 為[2,2]的矩陣:
tf.random.uniform([2,2],maxval=10)
如果需要均勻采樣整形型別的資料,必須指定采樣區間的最大值 maxval 引數,同時制定資料型別為 tf.int* 型:
tf.random.uniform([2,2],maxval=100,dtype=tf.int32)
(4) 創建序列
在回圈計算或者對張量進行索引時,經常需要創建一段連續的整形序列,可以通過tf.range()函式實作,tf.range(limit, delta=1)可以創建[0,𝑙𝑖𝑚𝑖𝑡)之間,步長為 delta 的整形序列,不包含 limit 本身,
例如,創建 0~99,步長為 1 的整形序列:
tf.range(100)
創建 0~99,步長為 2 的整形序列:
tf.range(100, 2)
通過 tf.range(start, limit, delta=1)可以創建[𝑠𝑡𝑎𝑟𝑡, 𝑙𝑖𝑚𝑖𝑡),步長為 delta 的序列,不包含 limit 本身,例如,創建5~99,步長為2的序列:
tf.range(5,100,delta=2)
(5) 從 Numpy、List 物件創建張量
通過 tf.convert_to_tensor 可以創建新 Tensor,并將保存在 Python List 物件或者 Numpy Array 物件中的資料匯入到新 Tensor 中,
從List物件創建張量:
tf.convert_to_tensor([1,2.])
從Numpy物件創建張量:
tf.convert_to_tensor(np.array([[1,2.],[3,4]]))
三、索引與切片
(1) 索引
在 TensorFlow 中,支持基本的[𝑖][𝑗]…標準索引方式,也支持通過逗號分隔索引號的索引方式,
考慮輸入張量 x 為 8 張 32x32 大小的彩色3通道圖片,即 shape 為 [4,32,32,3] 的張量:
# x使用隨即分布模擬產生
x = tf.random.normal([4,32,32,3])
接下來我們使用索引方式讀取張量的部分資料,
取第 1 張圖片的資料:
x[0] # 索引是從0開始的
取第 1 張圖片的第 10 行:
x[0][10]
取第 1 張圖片,第 10 行,第 8 列的像素:
x[0][10][8]
取第 3 張圖片,第 10 行,第 8 列的像素,B 通道(第 2 個通道)顏色強度值:
x[0][10][8][2]
當然,也可以采用它的等價寫法:
x[0, 10, 8, 2]
(2) 切片
通過𝑠𝑡𝑎𝑟𝑡: 𝑒𝑛𝑑: 𝑠𝑡𝑒𝑝切片方式可以方便地提取一段資料,其中 start 為開始讀取位置的索引,end 為結束讀取位置的索引(不包含 end 位),step 為讀取步長,
我們還是以上面 shape 為 [4,32,32,3] 的影像為例,首先創建一個張量:
# x使用隨即分布模擬產生
x = tf.random.normal([4,32,32,3])
讀取第 2,3 張圖片:
x[1:3]
start: end: step切片方式有很多簡寫方式,其中 start、end、step 3 個引數可以根據需要選擇性地省略,全部省略時即::,表示從最開始讀取到最末尾,步長為 1,即不跳過任何元素,
如 x[0,::]表示讀取第 1 張圖片的所有行,其中::表示在行維度上讀取所有行,它等于x[0]的寫法:
x[0,::]
為了更加簡潔,::可以簡寫為單個冒號:,如取所有圖片,隔行采樣,隔列采樣,所有通道資訊,相當于在圖片的高寬各縮放至原來的 50%:
x[:, 0:28:2, 0:28:2, :]
特別地,step 可以為負數,考慮最特殊的一種例子,step = ?1時,表示逆序讀取元素,
當張量的維度數量較多時,不需要采樣的維度一般用單冒號:表示采樣所有元素,比如讀取第一張圖片:
x[0,:,:,:]
在TensorFlow中,為了避免出現像 𝑥[0, : , : , : ] 這樣出現過多冒號的情況,可以使用...符號表示取多個維度上所有的資料,其中維度的數量需根據規則自動推斷,例如上面的例子就可以寫成:
x[0,...]
四、維度變換
TensorFlow中對張量維度進行變換的操作函式有以下幾種:
- tf.reshape(x, [ b, w, h, c ]),按照 [b, w, h, c]的維度對輸入張量x進行變換,
- tf.transpose(x, perm=[0, 1, 3 , 2]),按照perm對維度進行轉置,比如原來x的維度資訊是[4,3,2,1],經過轉置后,維度資訊變為[4,3,1,2],如果沒有設定perm,那么x按照默認轉置方式,變換后的維度為[1,2,3,4],
- tf.expand_dims(x, axis=0),在第0軸增加一個維度,比如原來x的維度是[28,28,3],增加第0維度后,x的維度變為[1,28,28,3].,
- tf.squeeze(x),僅僅減去所有通道數為1的維度,比如原來x的維度是[1,28,28,1],處理后維度變為[28,28],
- tf.squeeze(x, axis=0),指定減去某個通道數為1的維度,比如原來x的維度是[1,28,28,1],處理后維度變為[28,28,1],
五、廣播機制
廣播機制,即 Broadcasting,它能很方便的解決不同維度張量間的運算問題,廣播操作類似tf.tile()對資料進行復制擴張,不同的是,tf.tile()是真的復制,而 Broadcasting 并不會立即復制資料,它只是在邏輯上改變張量的形狀,使得視圖上變成了復制后的形狀,
Broadcasting 會通過深度學習框架的優化手段避免實際復制資料而完成邏輯運算,相對比于 tf.tile 函式而言,減少了大量計算代價,而作用卻和 tf.tile 一樣,所以建議在運算程序中,盡量使用 Broadcasting 來提高計算效率,
下圖展示了幾種不同情形下,不同維度張量間執行加法元素時的廣播操作,如下圖所示:
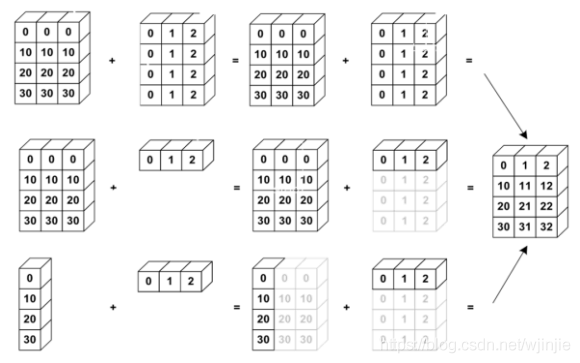
以神經網路中前向傳播的程序為例,網路中某一層的計算公式是:Y=X@W+b,假設該層X@W 的 shape 是 [100, 5],偏置 b 的 shape 是 [5],很明顯 X@W 和 b 的 shape 是不一樣的,所以不能直接相加,這個時候就需要先對 b 進行 Broadcasting,具體操作如下:
y = x@w + tf.broadcast_to(b,[100,5])
注意:之所以采用廣播操作,是為了優化計算,并且考慮到復制會占用記憶體,
六、數學運算
Tensorflow中張量a、b間的數學運算主要分為3大類:
- 張量中逐元素計算,比如:+、-、*、/、//、%,
- 對張量中某一個維度上的計算,比如:reduce_mean、max、min、sum,
- 張量整體計算,類似矩陣間的乘法一樣,比如@、matmul,
Tensorflow中用于數學運算的元素符以及函式:
- 對于逐元素計算:常用的運算子有:+、-、*、**、/、//、%;常用的函式有:tf.math.log()、tf.exp()、tf.pow()、tf.sqrt()、
- 整體上計算:a@b、tf.matmul(a,b)
七、前向傳播實戰
下面,我們將利用已經學到的知識來搭建三層神經網路,實作 MNIST 手寫數字識別,MNIST資料集在前面的文章中已經介紹過,這里就不再贅述,
(1) 匯入相關庫:
import tensorflow as tf
from tensorflow.keras import datasets
(2) 資料集準備:
# 加載資料集
(x, y), (x_test, y_test) = datasets.mnist.load_data()
# 轉為張量
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.float32)
# 構建每一個batch資料
train_db = tf.data.Dataset.from_tensor_slices((x, y)).batch(128)
train_iter = iter(train_db)
sample = next(train_iter)
print('batch:', sample[0].shape, sample[1].shape)
(3) 初始化變數
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
(4) 迭代訓練
for epoch in range(10):
# x:[128,28,28], y:[128]
for step, (x, y) in enumerate(train_db): # step = nums/batch
x = tf.reshape(x, [-1, 28*28])
# 構建梯度環境
with tf.GradientTape() as tape:
# 第一層: [b,784]*[784,256]+[256] => [b,256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# 第二層:[b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# 輸出層:[b, 128] => [b,10]
out = h2@w3 + b3
# 將輸出轉換成熱獨碼
y_onehot = tf.one_hot(y, depth=10)
# 建立mse損失函式
loss = tf.square(y_onehot - out)
loss = tf.reduce_mean(loss)
# 計算梯度
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# 引數更新
lr = 1e-3
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(epoch, step, 'loss: ', float(loss))
本教程所有代碼會逐漸上傳github倉庫:https://github.com/Keyird/TensorFlow2-for-beginner
如果對你有幫助的話,歡迎star收藏~
最好的關系是互相成就,各位的「三連」就是【AI 菌】創作的最大動力,我們下期見!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/281755.html
標籤:AI