乍看之下,感覺像是一個文本語意相似度的問題,
但想了一想,應該是一個機器學習的監督學習問題,實際上資料集就是 附件 2 嘛,問題編號對應的兩個文本作為輸入,標簽作為輸出嘛,
我們先來看一下附件二:
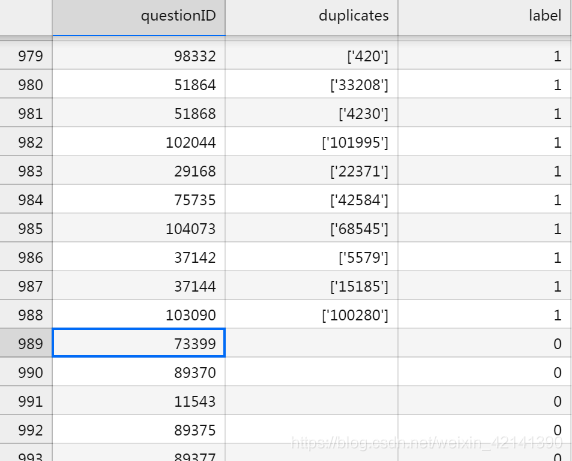
可以看到,標簽有1 的,duplicate 那一系列都有值,標簽為 0 的,duplicate 沒有值,換句話說:那些標簽為 0 的,等于 他(以 73399 為例)和其他問題都不重復嘛,我們知道,問題 ID 一共 729
所以,機器學習模型的資料集的大小應該為 7294*7294+988 咯,輸入是兩兩組合,輸出是 label
然后問題的難點在于類別不均衡(重復的資料太少,不重復的組合太多了),第二是特征工程,即將文本轉換為結構化的向量…
前者用過采樣、欠采樣;后者用英文的 NLP(不建議用中文來做,因為中文分詞很麻煩的)
當然,這個思路不現實的地方就在于資料量比較大,畢竟有 1 億條資料嘛,而標簽為 1 的只有 1000 條左右, 10 W:1 啊,
所以,肯定是需要預處理的,至于如何預處理,哎,一言難盡…
先占個坑吧,比賽結束再詳細討論唄,希望大家都能取得好成績,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282278.html
標籤:其他