Python網路爬蟲(二):請求庫的使用
學習爬蟲,最初的操作便是模擬瀏覽器向服務器發出請求,我們需要可以先從使用最基本的HTTP庫,比如urllib、httplib2、requests、treq等,本章我們主要介紹urllib和requests,在本章的博客中,我們主要講解基本概念,由于代碼部分內容有點多,所以上傳至GitHub,可以自行下載,格式為.ipynb,
鏈接為:
https://github.com/Yuchen-Zhou/SpiderLearning
1.urllib
在Python中,我們可以使用urllib庫來實作請求的發送,其官方檔案鏈接為:https://docs.python.org/3/library/urllib.html
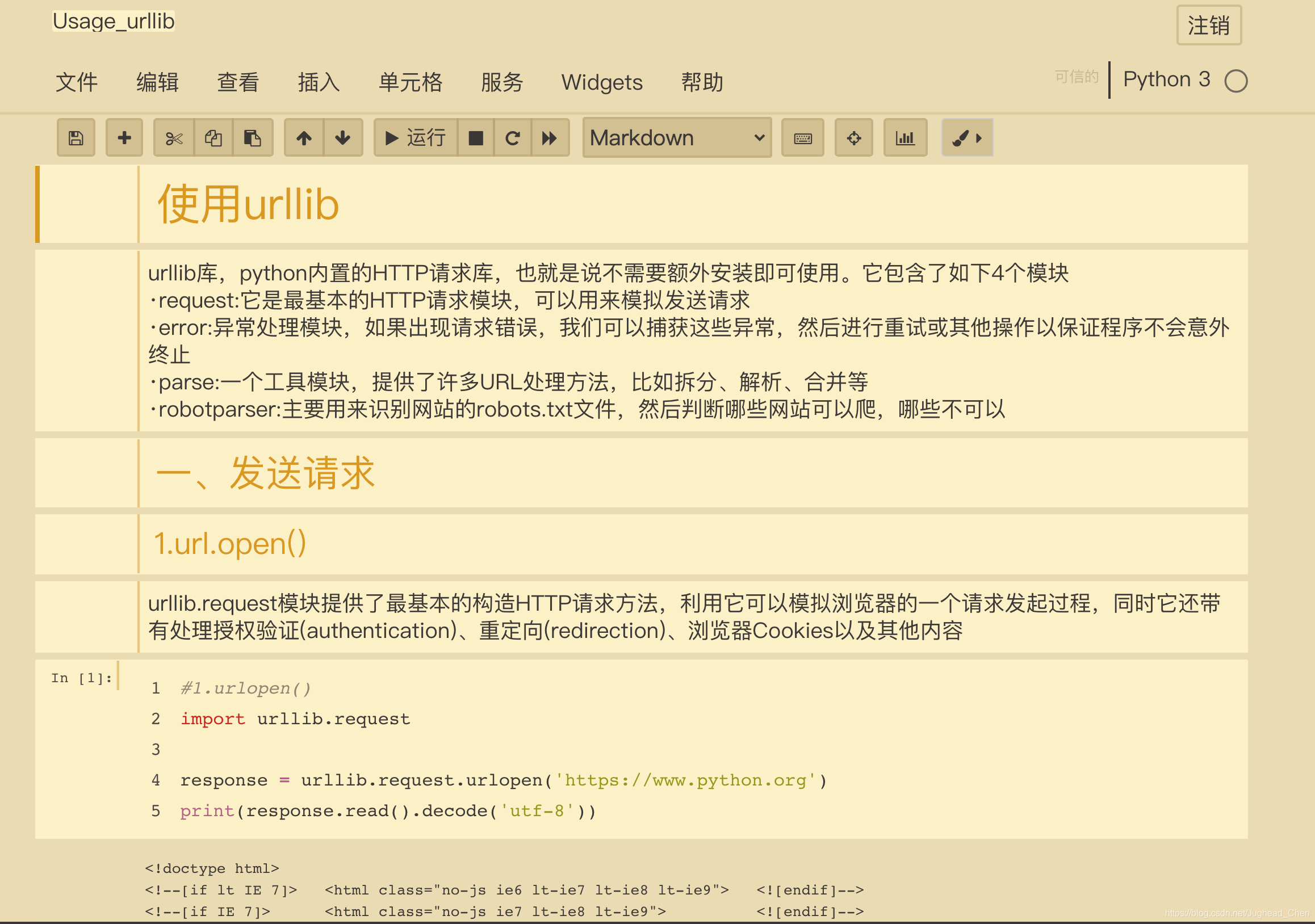
本節內容的html鏈接:https://github.com/YuchenZhou/SpiderLearning/blob/main/Usage_StanderLib/Usage_urllib.html
2.requests
上一節中,我們了解了urllib的基本用法,但是其中確實有不方便的地方,為了更加方便地實作這些操作,就有了更為強大的庫requests,
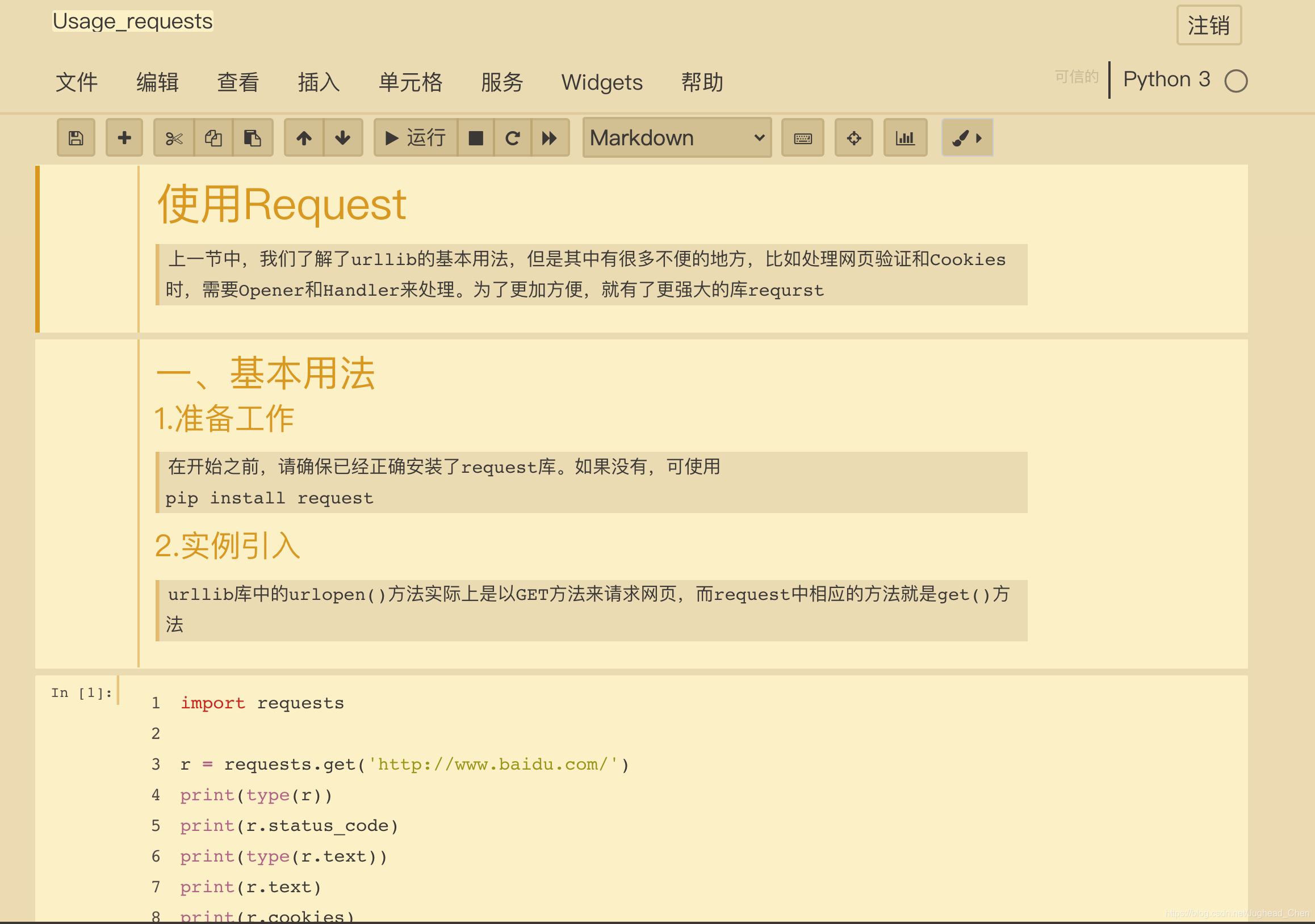
本節內容html檔案鏈接:
https://github.com/Yuchen-Zhou/SpiderLearning/blob/main/Usage_StanderLib/Usage_requests.html
3.正則運算式
本節,我們看一下正則運算式的相關用法,正則運算式是處理字串的強大工具,它有自己特定的語法結構,可以實作字串的檢索、替換、匹配驗證都不在話下
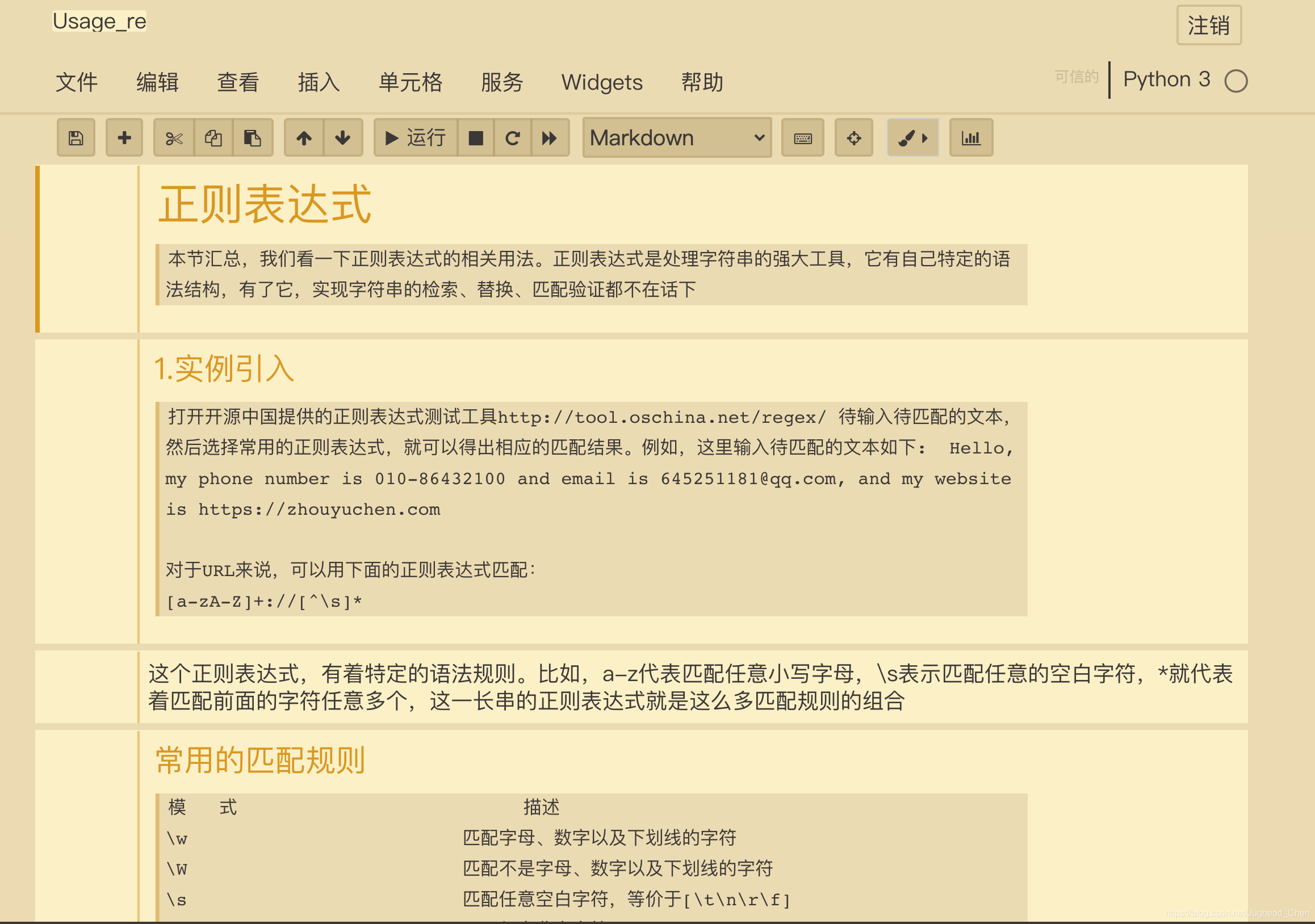
本節內容html檔案鏈接:
https://github.com/Yuchen-Zhou/SpiderLearning/blob/main/Usage_StanderLib/Usage_re.html
本周內容較多,CSDN里寫不下,就只能上傳到GitHub上了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282553.html
標籤:AI