A題 疫苗生產問題
正太分布公式
第一問是從50次時間統計出均值、方差作為正太分布的引數,最值即是公式中的x區間范圍,
第一問的統計主要是得到不同疫苗在不同工序上的隨機時間的正太分布公式
Matlab自帶normrnd有部分問題,可以參考下下面我寫的自定義函式
function [a,b]=nor(u,o,m1,m2)%u為均值,o為標準差,m1為區間最小值,m2為區間最大值b=rand;while b>1/(sqrt(2*pi)*o)b=rand;endif rand>0.5a=u+sqrt(-2*o*o*log(b*sqrt(2*pi)*o));elsea=u-sqrt(-2*o*o*log(b*sqrt(2*pi)*o));endif a<m1a=m1;endif a>m2a=m2;end
每種疫苗必須按照CJ1-CJ2-CJ3-CJ4依次加工,題目沒有說幾條生產線,那么就默認1條,第二問YM1-YM10各100劑已知,疫苗生產也不允許插隊,就是說之后的工位也是按第一個工位的加工順序加工疫苗,那么第二問就直接通過randperm函式生成隨機序列就好,加工程序主要有兩種增大時間成本的情況:第一種是YM2在CJ1加工完成后YM1還在CJ2上加工,第二種是YM1在CJ2加工完成后,YM2還在CJ1上加工,
造成了等待時間和空擋時間,因此就需要找到一個最優的加工排序方法,在第二問每種疫苗在不同工位的加工時間以附件1中平均時間為依據,加工時間案例程式如下:
T=zeros(1,4);for j=1:10T(1)=T(1)+A(chrom(i,j),1);%CJ1時間直接累加就行for k=2:4if T(k)<T(k-1)%YM2在CJ1加工完成后YM1還在CJ2上加工這種情況程式中不用體現延遲時間%第二種是YM1在CJ2加工完成后YM2還在CJ1上加工程式中需要體現延遲時間T(k)=T(k-1);endT(k)=T(k)+A(chrom(i,j),k);endend
程式設計很簡單,每個個體就是randperm生成的序列,目標函式為總加工時間,優化演算法就套用遺傳演算法就行,但交叉變異函式需要重新寫下,下面是交叉變異函式案例,可以參考,
function x=jiaocha(x,n,a)if nargin < 3a=0.3;%未設定交叉率則默認為0.3endy=x(end:-1:1);b=randi(n); %生成隨機交叉點if rand<ax=[x(b:end),x(1:b-1)];end?function selchrom=bianyi(selchrom,n,a)if nargin < 3a=0.7;%未設定變異率則默認為0.7endfor i=1:length(selchrom)if rand<ab=randi(n);d=selchrom(i);c=find(selchrom==b);selchrom(i)=b;selchrom(c)=d;endEnd
第三問,時間改為滿足正態分布的隨機時間,但是要注意不同疫苗在不同工位加工時間的正態分布公式,其時間的區間范圍由附件1中的最值決定的,隨機產生時間請參閱前文自定義函式,加工時間案例如下
T=zeros(1,4);i=1;for j=1:10B(j,1)=chrom(i,j);B(j,2)=T(1);[a,b]=nor(A(chrom(i,j),1),2*S(chrom(i,j),1),Mi(chrom(i,j),1),Mx(chrom(i,j),1));D1(j,1)=a;D2(j,1)=b;T(1)=T(1)+a;%CJ1時間直接累加就行for k=2:4if T(k)<T(k-1)%YM2在CJ1加工完成后YM1還在CJ2上加工這種情況程式中不用體現延遲時間%第二種是YM1在CJ2加工完成后YM2還在CJ1上加工程式中需要體現延遲時間T(k)=T(k-1);end[a,b]=nor(A(chrom(i,j),k),2*S(chrom(i,j),k),Mi(chrom(i,j),1),Mx(chrom(i,j),1));D1(j,k)=a;D2(j,k)=b;T(k)=T(k)+a;endB(j,3)=T(end);end
本問的程式架構與第二問一致,只不過將第二問遺傳演算法作為外回圈,對內某個個體回圈進行k次蒙塔卡羅實驗模擬,根據k次隨機加工時間下的結果去評判這些個體的優劣,實驗結束保留最優情況,
同時將模擬實驗存在時間縮短5%以上個體作為優先排序條件,排序函式可以用sortrows函式實作多個從大到小或者從小到大優先級排序,
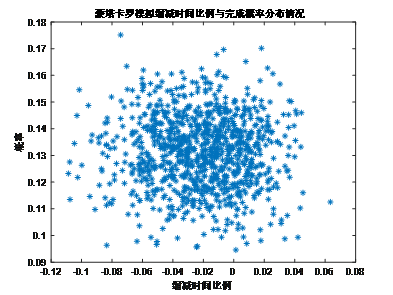
第三問還說找縮短的時間比例和最大概率之間的關系,先尋優出最優個體,然后基于該個體進行K次蒙特卡羅模擬實驗,可以得到不同縮減比每次實驗的分布情況,統計概率后可以通過最小二乘非線性擬合得到關系曲線和關系式,
第四問,每種型別疫苗的生產任務不可以拆分,相當于一種疫苗不間斷生產,那么還是按randperm對10種不同疫苗產生隨機序列用優化演算法尋優,這里也需要注意下,每種疫苗其實是分成若干個100劑的且是連續加工的,全部加工完了一種疫苗后才換下一個序號的疫苗,同樣采用第三問程式來做,
第五問,可以對任務進行拆分,將任務拆分并編號,同時記錄疫苗種類,可以通過randperm產生隨機序列,程式中將算目標函式的for回圈改為while回圈,終止條件為>100天,目標函式改為銷售額,
B題 消防救援問題
第一問首先從附件中篩選出每年2月、5月、8月、11月中第一天三個時間段救援次數,基數是三個時間段至少5人,其他的按歷史救援次數比例安排值班人員,當然這里也可以假設一次出警人數,一次出警時間,按時間點統計下歷史資料中該時間段需求最多的人數,也可以結合區域的人口密度,設定不同的出警人數,可以假設的方面很多,第一問也只是說每年2月、5月、8月、11月中第一天的三個時間段各應安排多少人值班,根據歷史資料統計就行,不需要進行預測,
第二問可以直接用神經網路、時間序列的方法來做,或者拆成每日用馬爾可夫預測最后在按月求和,最后做下誤差分析,資料不是很有規律,多嘗試幾種預測方法,
第三問,觀察發現資料基本無規律性,比較像隨機事件,本問比較科學的做法是預測次數和預測事件發生分開來做,按月的角度去預測之后每月救援的次數,預測時間的發生就不按時間點來了,直接通過馬爾可夫演算法(其中有轉移概率矩陣,比較適合解本問)預測后續時間發生的序列,最后得到每月不同時間發生的次數,
第四問,先計算各地區2016-2020年不同事件的密度(按每周統計[事件密度指每周每平方公里內的事件發生次數]),根據圖1,求與連接區域不同事件密度資料的相關性,比如拿A區事件1與B區事件1求其密度歷史每周資料的相關性(皮爾遜、余弦相似度等),給出兩個連接區域間相關性最強的事件是哪一類,題目說圖1中空間上的相關性,應該指的是相連通的區域,
第五問,本問的各類事件密度就取每周的平均值,然后分每一類事件求其時間密度與對應區域人口密度的關系,這里就可以用簡單的回歸分析演算法,主要是體現整體趨勢,
第六問,如果是要依次新建消防站,就僅考慮當前情況,FCM演算法(可以參考下我公眾號的推文:演算法-Matlab版-FCM聚類)以點到相應聚類中心距離之和最短為目的,本問可以借鑒該思路,除了距離外,還可以考慮平均每年出警的次數以及人口密度等因素,去構建目標函式,本問區域個數較小,可以直接列舉出來確定最優選址,每新建一個消防站重新算一下新增消防站的最佳位置即可,
C題 資料驅動的例外檢測與預警問題
資料有些不連續波動且波動值很小可能是傳感器短時間發生例外,這類波動視為非風險性例外,如果是連續波動且偏移量較大,并且可能還對其他傳感器有一定的聯動性,那么基本上可以判定為風險性例外,給大家解釋下幾個方面,部分傳感器接收到的信號來源是一致的,也就是題目說道的聯動性,由于沒有歷史資料支撐,也不知道各傳感器的狀態,可以取初始前幾十行資料通過求相關性、聚類分析進行歸類,歸一下類別,之后如果出現例外資料聯動的時候可以多一個參考,聚類步驟可有可無,還有一點,傳感器一天內受天氣的影響肯定很多傳感器在早中晚時的資料差異比較明顯,因此最好不要直接用演算法檢測整列資料,比較科學的做法,我們拿半小時為例,大概有120個資料,程式里每次回圈向下增加一行,向上減少一行,一個時刻一個時刻的遍歷下去,對于單個傳感器,可以通過LOF離群度檢測演算法(可以參考下我公眾號的推文:演算法-Matlab版-LOF)
每新增一個資料就重新算一次離群度值,離群度這里可以設個臨界值,高于則視為例外資料,按理說如果是正常資料都是連續的,那么離群度就不會太高,如果是出現連續幾個偏差較大的資料那么就可以判斷疑似風險性例外,同時可以根據與之同類的傳感器資料的例外情況,如果存在例外聯動那么就判定為該時刻發生風險性例外,如果不存在例外聯動,就繼續遍歷,如果連續又增加了幾個高離群度的值,那么就可以判定為風險例外,例外檢測肯定是有延遲的,聚類步驟也只是輔助LOF演算法盡早發現風險例外,還有種情況,資料例外時間比較長,這里可以記錄下確認風險性例外前120個資料的平均值u和方差o,此時新增的資料的離群度就暫時以u和o來計算,此刻被定義為風險例外,可能在之后某一時刻作業人員恢復了資料,如何判斷恢復時刻,如果出現連續幾個資料小于與u<方差o那么可以視為恢復,考慮天氣、時間變化的影響,這里也可以加一個容錯系數p,那么就是<方差o+p視為恢復,從恢復時刻開始,前面的資料就可以摒棄了,就從恢復時刻開始一直到120個資料后再依次取下一120個數,依次遍歷下去,特別提醒下不管用什么例外檢測演算法一定要增加恢復時刻的判斷,否則遍歷到后面可能會將已恢復后的資料也判斷為風險性例外,
上述主要從演算法設計角度寫的,可以參考下,也可以更細化多增加一些判定條件,實作起來編程也確實要麻煩點,
第二問,第一問采用的是遍歷采樣的方式,每個傳感器每個時刻都會取前120個資料,第一問也設立了恢復時刻的判定,這里百分制打分就按離群度值/歷史出現最高離群度值,如果存在聯動例外則打分×(1+theta),打分模型可以自己根據第一問的演算法構建,這里只是舉了個簡單的例子,
第三問,預測演算法推薦使用粒子濾波演算法(可以參考下我公眾號的推文:演算法-Matlab版-粒子濾波),預測演算法帶入的資料最好是22:00-23:00的,時間久的資料參考意義不大,然后再接著第二問算下23:00-0:00的各時間點評分
第四問,注意這里是安全性評分了,并且是對時間段所有傳感器的整體情況進行評分,一般我們在企業里會有故障這一指標,在本問評分可以通過這個式子計算100*(1-故障總時長/所有設備開機時長)或者100*(1-故障設備數/該時段總設備作業數)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282556.html
標籤:AI