【語意分割文獻閱讀】Segmentation from Natural Language Expressions
文章目錄
- 【語意分割文獻閱讀】Segmentation from Natural Language Expressions
- Abstract
- 1 Introduction
- 2 Related work
- Localizing objects with natural language
- Fully convolutional network for segmentation
- Attention and visual question answering
- 3 Our model
- 3.1 Spatial feature map extraction
- 3.2 Encoding expressions with LSTM network
- 3.3 Spatial classification and upsampling 空間分類和上采樣
- 4 Experiments
- 4.1 Baseline methods
- Combination of per-word segmentation
- Foreground segmentation from bounding boxes.
- Classification over segmentation proposals
- Whole image
- 4.2 Evaluation on ReferIt dataset
- Results
- Speed
- Conclusion
- Acknowledgments
Abstract
本文探討了一個基于自然語言表達的影像分割新問題,這不同于在一組預定義的語意類別上的傳統語意分割,例如,短語“坐在右邊長凳上的兩個人”需要只分割坐在右邊長凳上的兩個人,而沒有人站在或坐在另一個長凳上,以前適用于此任務的方法僅限于一組固定的類別和/或矩形區域,為了對語言表達進行像素化分割,我們提出了一個端到端的可訓練遞回和卷積網路模型,該模型可以聯合學習處理視覺和語言資訊,在我們的模型中,遞回LSTM網路用于將參考運算式編碼為矢量表示,而完全卷積網路用于從影像中提取空間特征圖并輸出目標物件的空間回應圖,在一個基準資料集上,我們證明了我們的模型可以從自然語言運算式中產生高質量的分割輸出,并且在很大程度上優于基線方法,
1 Introduction
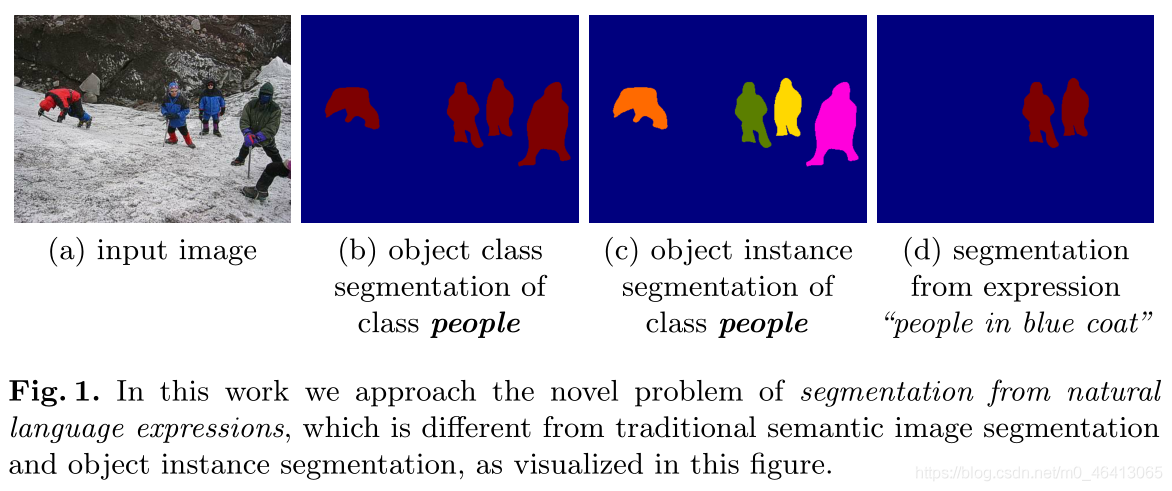
語意影像分割是計算機視覺中的一個核心問題,基于卷積神經網路[1,2,3,4,5,6]的大規模視覺資料集和豐富的表示方法已經取得了重大進展,雖然這些現有的分割方法可以為“train”或“cat”等查詢類別預測精確的像素級掩碼,但它們不能為更復雜的查詢預測分割,例如自然語言運算式“汽車右側穿著黑色襯衫的兩個人”,在本文中,我們解決了以下問題:給定一幅影像和一個描述影像某一部分的自然語言運算式,我們希望分割覆寫該運算式所描述的視覺物體的相應區域, 例如,如圖1 (d)所示,對于短語“穿藍色外套的人”,我們希望預測一個包括中間穿著藍色外套的兩個人,但不包括其他兩個人的分割,這個問題與語意分割的核心計算機視覺問題相關但不同(例如PASCAL VOC對20個物件類的分割挑戰[7]),其涉及預測預定義的一組物件或素材類別的像素化標簽(圖1,b),以及實體分割(例如[8]),其另外區分物件類的不同實體(圖1,c),它也不同于與語言無關的前景分割(例如[9]),后者的目標是在前景(或最顯著的)物件上生成遮罩,本文的目標不是像在語意影像分割中那樣為影像中的每個像素分配語意標簽,而是基于給定的運算式為感興趣的視覺物體產生分割掩模,自然語言描述不是固定在一組物件和材料類別上,還可能涉及諸如“黑色”和“平滑”等屬性、諸如“奔跑”等動作、諸如“右邊”等空間關系以及諸如“騎馬的人”等不同視覺物體之間的互動,
從自然語言運算式中分割影像的任務有著廣泛的應用,例如建立基于語言的人機界面,向機器人發出“拿起蘋果旁邊桌子上的罐子”等指令,在這里,能夠使用多詞參考運算式來區分不同的物件實體是很重要的,但與僅使用邊界框相比,獲得精確的分割也很重要,尤其是對于非網格對齊的物件(例如,參見圖2),這對于互動式照片編輯來說也很有意思,在互動式照片編輯中,人們可以用自然語言來指代要處理的影像的某些部分或物件,例如“模糊穿紅色襯衫的人”,或者參考你的一餐的某些部分來估計他們的營養,“兩大塊培根”,以更好地決定是否應該吃它,而不是像[10]中那樣吃一頓飽飯,
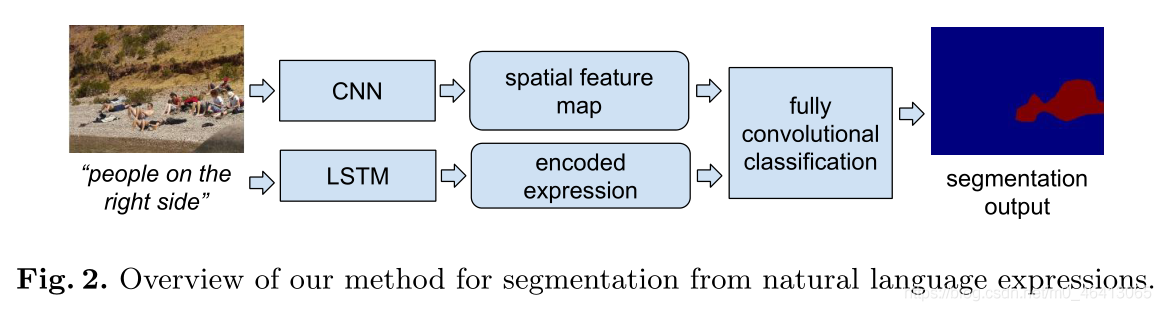
如第2節中更詳細的描述,適用于此任務的現有方法被限制為僅決議影像中的邊界框[11,12,13],和/或被限制為先驗確定的固定類別集[1,3,4,6],在本文中,我們提出了一個端到端的可訓練遞回卷積網路模型,該模型聯合學習處理視覺和語言資訊,并為自然語言運算式描述的目標影像區域產生分割輸出,如圖2所示,我們通過遞回LSTM網路將運算式編碼成固定長度的向量表示,并使用卷積網路從影像中提取空間特征圖,編碼的運算式和特征圖然后由多層分類器網路以完全卷積的方式進行處理,以產生粗回應圖,該粗回應圖用反卷積[1,5]進行上采樣,以獲得目標影像區域的像素級分割掩模,在基準資料集上的實驗結果表明,我們的模型能夠從自然語言運算式中生成高質量的分割預測,并且顯著優于基線方法,我們的模型是使用標準反向傳播進行訓練的,并且在測驗時比以前依賴于對每個邊界框進行評分的方法更有效,
2 Related work
我們的作業涉及以下幾個方面,
Localizing objects with natural language
用自然語言定位物件,我們的作業與最近關于自然語言的物件定位的作業有關,其中的任務是根據自然語言描述定位場景中的目標物件(通過在其上畫一個邊界框),在[11]和[13]中報道的方法建立在影像字幕框架如LRCN [14]或mRNN [15]的基礎上,并且通過選擇運算式具有最高概率的邊界框來定位物件, 我們的模型不同于[11]和[13],因為我們不必學習從影像區域生成運算式,在[12]中,作者提出了一個模型,通過關注短語能夠被最好地重構的區域來定位文本短語,在[16]中,利用典型相關分析(CCA)學習視覺特征和單詞的聯合嵌入空間,給定一個自然語言查詢,通過在聯合嵌入空間中尋找與文本序列最近的區域來定位對應的目標物件,
據我們所知,所有這些先前的定位方法只能回傳目標物件的邊界框,并且先前的作業沒有學會直接輸出給定自然語言描述的物件的分割掩碼作為查詢, 作為比較,在第4.1節中,我們還評估了在[11]和[12]的邊界框預測上使用前景分割,
Fully convolutional network for segmentation
語意分割的全卷積網路,完全卷積網路是僅由卷積(和匯集)層組成的卷積神經網路,是在一組預定義的語意類別[1,3,4,6]上進行語意分割的最新方法,完全卷積網路的一個很好的特性是空間資訊保留在輸出中,這使得這些網路適合需要空間網格輸出的分割任務, 在我們的模型中,特征提取和分割輸出都是通過完全卷積網路實作的,在第4.1節中,我們還使用全卷積網路作為每字切分的基線,
Attention and visual question answering
注意力和視覺問答,最近,注意力模型已經被用于包括影像識別、影像字幕和視覺問題回答在內的幾個領域,在[17]中,通過聚焦于每個單詞的特定影像區域來生成影像標題,在最近的視覺問題回答模型[18,19]中,通過關注一個或多個影像區域來確定答案,[20]的作者提出了一種可視化的問答方法,通過對句子進行決議,為“黑”和“貓”生成注意圖,可以學會回答“黑貓在哪里”等物件參考問題,
這些注意力模型與我們的作業相關,因為它們也學習生成空間網格“注意力地圖”,這些地圖通常覆寫感興趣的物件,然而,這些注意力模型不同于我們的作業,因為它們只學習生成粗略的空間輸出,并且注意力圖的目的是促進其他任務,例如影像字幕,而不是精確地分割出物件,
3 Our model
給定一個影像和一個自然語言運算式作為查詢,目標是為運算式描述的視覺物體輸出一個分割掩碼, 這個問題需要對影像和表達的視覺和語言理解,為了實作這一目標,我們提出了一個具有三個主要組成部分的模型:基于遞回LSTM網路的自然語言運算式編碼器,提取區域影像描述符并生成空間特征圖的全卷積網路,以及將編碼運算式和空間特征圖作為輸入并輸出像素級分割掩碼的全卷積分類和上采樣網路, 圖3顯示了我們的方法的概要;我們在第3.1、3.2和3.3節中介紹了這些組件的細節,用于特征圖提取和分類的網路體系結構類似于FCN模型[1],該模型已被證明對于語意影像分割是有效的,
與相關作業[11,13]相比,我們沒有明確地產生對應于給定視覺表示的物件描述的單詞序列,因為我們感興趣的是從表達預測影像分割,而不是預測表達,這樣,與[11,13]相比,我們的模型具有更少的引數,因為它不必學習預測下一個單詞,這可能是一項艱巨的任務,
3.1 Spatial feature map extraction
給定場景的影像,我們希望獲得它的區別特征表示,同時保留表示中的空間資訊,以便更容易預測空間分割掩模,這是通過類似于FCN-32s [1]的完全卷積網路模型實作的,其中影像通過一系列卷積(和匯集)層饋送,以獲得作為特征表示的空間地圖輸出,給定大小為W × H的輸入影像,我們在影像上使用卷積網路來獲得w × h的空間特征圖,特征圖上的每個位置包含 D i m D_{im} Dim?通道(Dimcdimensional local descriptor),
對于特征地圖上的每個空間位置,我們對該位置的二維區域描述符應用L2歸一化,以便獲得更魯棒的特征表示,這樣,我們可以提取一個 w × h × D i m w × h × D_{im} w×h×Dim?的空間特征圖作為每幅影像的表示,
此外,為了允許模型推理空間關系,例如圖3中的“合適的女人”,向特征地圖添加了兩個額外的通道:每個空間位置的x和y坐標,我們使用相對坐標,其中要素地圖的左上角和右下角分別表示為(1,1)和(+1,+1),這樣,我們獲得了包含區域影像描述符和空間坐標的
w
×
h
×
(
D
i
m
+
2
)
w × h × (D_{im}+2)
w×h×(Dim?+2)表示,
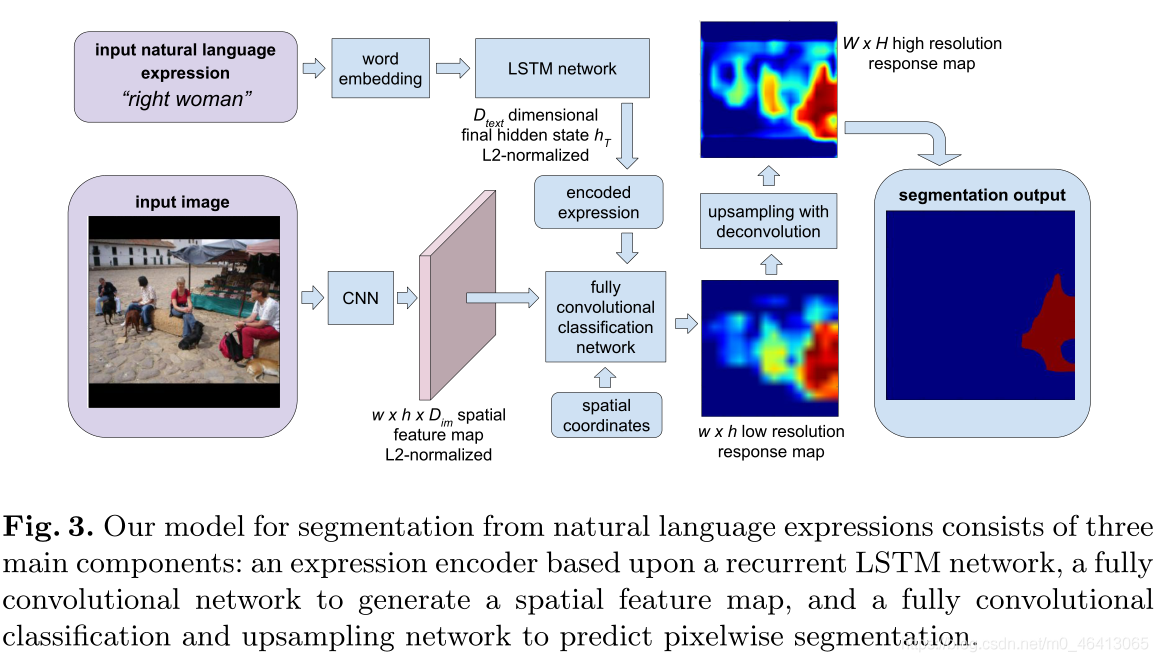
在我們的實作中,我們采用VGG-16體系結構[21]作為我們的完全卷積網路,將fc6、fc7和fc8視為卷積層,輸出 D i m D_{im} Dim?= 1000維區域描述符,生成的要素圖大小為w = W/s,h = H/s,其中s = 32是fc8圖層輸出上的像素跨度,空間特征地圖上的單元具有384像素的非常大的感受野,因此我們的方法具有聚集來自附近區域的背景關系資訊的潛力,這可以幫助推斷視覺物體之間的互動 ,例如“桌子旁邊的人”,
3.2 Encoding expressions with LSTM network
對于描述影像區域的輸入自然語言運算式,我們希望將文本序串列示為向量,因為處理固定長度的向量比處理可變長度的序列更容易,為了實作這一目標,我們采用了編碼器的方法,依次對學習方法進行排序[22,23],在我們的自然語言表達編碼器中,我們首先通過一個單詞嵌入矩陣將每個單詞嵌入到一個向量中,然后使用一個具有離散隱藏狀態的遞回長短期記憶(LSTM) [24]網路來掃描嵌入的單詞序列,對于文本序列S = (w1,…wn)在每個時間步長T,LSTM網路將來自單詞嵌入矩陣的嵌入單詞向量作為輸入,在LSTM網路已經看到整個文本序列之后的最后時間步t = T,我們使用LSTM網路中的隱藏狀態作為運算式的編碼向量表示, 類似于第3.1節,我們還對hT中的資料維度進行了L2歸一化,在我們的實作中,我們使用了一個LSTM網路,它的隱態為1000維,
3.3 Spatial classification and upsampling 空間分類和上采樣
在從第3.1節中的影像和第3.2節中的編碼運算式提取空間特征圖之后,我們想要確定特征圖上的每個空間位置是否屬于前景(由自然語言運算式描述的視覺物體),在我們的模型中,這是由區域影像描述符和編碼運算式上的完全卷積分類器完成的,我們首先平鋪并連接空間網格中每個空間位置的本地描述符,以獲得包含視覺和語言特征的 w × h × D ∑ ( 其 中 D ∑ = D i m + D t e x t + 2 ) w×h×D∑(其中D∑= D_{im}+D_{text}+2) w×h×D∑(其中D∑=Dim?+Dtext?+2)空間地圖,然后,我們訓練一個兩層分類網路,其中有一個二維隱藏層,該隱藏層在輸入時采用D∫維表示,并輸出一個分數來指示一個空間位置是否屬于目標影像區域, 我們在實作中使用 D c l s D_{cls} Dcls?= 500,
該分類網路以完全卷積的方式應用于底層w×h特征映射,作為兩個1×1卷積層(它們之間的ReLU不呈線性),全卷積分類網路輸出一個包含分類分數的w ×h粗低解析度回應圖,可以看作是參考運算式的低解析度分段,如圖3所示,
為了獲得更高解析度的分割掩模,我們通過反卷積(交換卷積運算的前向和后向程序)[1,5]進一步執行上采樣,這里我們使用一個2s × 2s反卷積濾波器,其步長為s(其中s = 32,適用于我們使用的VGG-16網路架構),類似于FCN-32s模型[1],反卷積操作產生與輸入影像具有相同大小的W ×H高解析度回應圖,并且高解析度回應圖上的值表示像素是否屬于目標物件的置信度,我們使用像素分類結果(即回應圖上的值是否大于0)作為最終的分割預測
在訓練時,我們訓練集中的每個訓練實體都是一個元組(I,S,M),其中I是一個影像,S是描述該影像中一個區域的自然語言運算式,M是該區域的二進制分割掩碼,訓練期間的損失函式定義為像素級損失的平均值
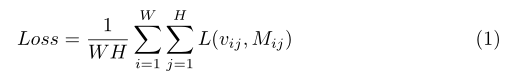
其中,W和H是影像寬度和高度,vijis是高解析度回應圖上的回應值(分數),Mijis是像素(I,j)處的二進制地面真實標簽,l是每像素加權邏輯回歸損失,如下所示
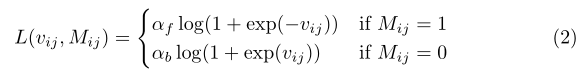
其中αf和α表示前景和背景像素的損失權重,在實踐中,我們發現對前景像素使用更高的損失權重訓練收斂得更快,并且我們在
L
(
v
i
j
,
M
i
j
)
L(v_{ij},M_{ij})
L(vij?,Mij?)中使用
α
f
=
3
和
α
b
=
1
α_f= 3和α_b= 1
αf?=3和αb?=1,特征圖提取網路中的引數從1000級ILSVRC分類任務[25]中預處理的VGG-16網路[21]初始化,用于上采樣的反卷積濾波器從雙線性插值初始化,我們模型中的所有其他引數,包括單詞嵌入矩陣、LSTM引數和分類器引數,都是隨機初始化的,整個網路使用帶動量的SGD進行標準反向傳播訓練,
4 Experiments
與PASCAL VOC [7]等影像分割中廣泛使用的資料集相比,只有少數公開可用的資料集在分割后的影像區域上帶有自然語言注釋,在我們的實驗中,我們在參考資料集[26]上用視覺物體的自然語言描述和它們的分割掩碼來訓練和測驗我們的方法,參考資料集[26]建立在IAPR TC-12資料集[27]的基礎上,有20,000幅影像,在96,654個分割的影像區域上注釋有130,525個運算式(一些區域用多個運算式注釋),在這個資料集中,地面真實分割來自SAIPR-12資料集[28],參考資料集中的運算式對區域是有區別的,因為它們是在一個兩人游戲中收集的,該游戲的目標是通過運算式使目標區域容易與影像的其余部磁區分開來,在撰寫本文時,參考資料集[26]是最大的公開可用的資料集,它包含在分割影像區域上注釋的自然語言運算式,
在這個資料集上,我們使用與[11,12]中相同的訓練值和測驗分割,有10000張圖片用于訓練和驗證,10000張圖片用于測驗,參考資料集中帶注釋的區域既包含“物件”區域,如汽車、人和瓶子,也包含“素材”區域,如天空、河流和山脈,
雖然[13]還收集了一個單獨的Google-RefExp資料集,該資料集包含帶有可從MS COCO資料集注釋獲得的分段區域的自然語言運算式[29],但該資料集僅包含來自COCO中80個物件類別的物件注釋,并且不包含“填充”區域,如雪,
因為據我們所知,還沒有直接學習基于自然語言運算式預測分割的前期作業,為了評估我們的方法,我們構建了幾個強基線方法,如第4.1節所述,并將我們的方法與這些方法進行比較,
4.1 Baseline methods
Combination of per-word segmentation
在該基線方法中,不是首先用遞回LSTM網路編碼整個運算式,而是單獨分割運算式中的每個單詞,然后組合每個單詞的分割結果以獲得最終的預測, 這種方法可以看作是用一個“詞袋”來表示運算式,我們在參考資料集中選取N個最常出現的單詞(在手動洗掉一些停止詞如“the”和“towards”)并訓練一個FCN模型[1]來分割每個單詞,類似于PASCAL VOC分詞挑戰[7],在這種方法中,每個單詞都被視為一個獨立的語意類別,然而,與PASCAL VOC分割不同,這里一個像素可以同時屬于多個類別(單詞),因此具有多個標簽,在訓練程序中,我們為訓練集中的每個訓練樣本(一個影像和一個運算式)生成一個每個單詞的像素化標簽圖,對于一個給定的運算式,相應的前景像素用一個N維二進制向量l來標記,其中li= 1當且僅當單詞I出現在運算式中,背景像素用等于全零的l來標記,在我們的實驗中,我們使用N = 500,并從PASCAL VOC 2011分段任務[1]中預處理的FCN-32s網路初始化網路,并用單詞上的多標簽邏輯回歸損失訓練整個網路,
在測驗時,給定影像和自然語言運算式作為輸入,網路輸出N個單詞的像素級分數圖,并且進一步組合每個單詞的分數以獲得輸入運算式的分段,在我們的實作中,我們實驗了三種不同的方法來組合每個單詞的分割:對于那些出現在運算式中的單詞(在N個單詞串列中),我們
a)取它們的分數的平均值
b)取它們預測的交集
c)取它們預測的并集,
在一些罕見的情況下(2.83%的測驗樣本),運算式中沒有一個單詞在N最常見的詞,我們不輸出該運算式的任何分割,即所有像素都被預測為背景,
Foreground segmentation from bounding boxes.
在這種基線方法中,我們首先使用基于自然語言輸入的定位方法[11,12]來獲得給定運算式的包圍盒定位,然后使用GrabCut [9]從包圍盒中提取前景分割,給定影像和自然語言運算式,我們使用最近提出的兩種方法SCRC [11]和基勒[12]從影像和運算式獲得包圍盒預測,在SCRC [11]中,作者使用了一個改編自影像字幕的模型,并通過找到運算式接收概率最高的候選包圍盒來定位參考運算式,在GroundeR [12]中,候選包圍盒上的注意力模型被用于以無監督的方式通過找到能夠最好地重建運算式的區域來對參考運算式進行基礎(定位),或者以有監督的方式直接訓練模型來關注最佳包圍盒,在[11,12]之后,我們使用100個得分最高的邊界框[30]作為每個影像的一組候選邊界框,在測驗時,給定一個輸入運算式,我們使用SCRC [11]或基勒[12]計算100個邊界框建議的得分,并評估兩種方法:要么使用得分最高的邊界框的整個矩形區域,要么使用GrabCut [9]從中分割前景,我們在實驗中使用了[12]的監督版本,
Classification over segmentation proposals
在這種基線方法中,我們首先使用MCG [31]提取一組候選分割建議,然后訓練二進制分類器來確定候選分割建議是否與運算式匹配,在這個基線中,我們使用了與監督版本[12]相似的管道,首先,從每個建議中提取視覺特征,并與編碼句子連接,然后,在級聯特征上訓練分類網路,以將分割建議分類為前景或背景,我們使用來自MCG的100個得分最高的分割建議,并通過首先將其大小調整到224 × 224(分割區域之外的那些像素用通道平均值填充)來從每個分割中提取視覺特征,然后使用在ILSVRC分類任務上預處理的VGG-16網路從調整后的分割中提取視覺特征,然后對整個網路進行端到端的培訓,該基線和我們的方法之間的主要區別在于,我們的方法通過完全卷積網路執行像素分類,而該基線需要另一種建議方法來獲得候選區域,
Whole image
作為一個額外的瑣碎基線,我們還評估使用整個影像作為每個運算式的分割,
4.2 Evaluation on ReferIt dataset
我們在參考資料集[26]中的10,000個訓練影像上訓練我們的模型和第4.1節中的基線方法(留出一小部分用于驗證),遵循與[11]中相同的分割,在我們的實作中,我們將所有影像和地面真實分割調整大小并填充到固定大小W × H(其中我們設定W = H = 512),保持它們的縱橫比并用零填充外部區域,并將分割輸出映射回原始影像大小以獲得最終分割,
在我們的實驗中,我們使用兩階段訓練策略:我們首先訓練我們模型的低解析度版本,然后從中微調以獲得最終的高解析度模型(即圖3中的完整模型),在我們的低解析度版本中,我們沒有在第3.3節中添加反卷積濾波器,因此該模型僅輸出圖3中的w×h = 16×16粗回應圖,我們還將地面真值標簽下采樣到w × h,并直接在粗回應圖上訓練以匹配下采樣的標簽,在訓練低解析度模型后,我們通過添加一個步長為s = 32的2s × 2s反卷積濾波器來構建最終的高解析度模型,如第3.3節所述,并通過雙線性插值來初始化濾波器權重(所有其他引數都從低解析度模型初始化),然后,在訓練集上使用W × H地面真實分割掩碼標簽對高解析度模型進行微調,我們根據經驗發現,這兩個階段的訓練比直接訓練我們的完整模型來預測高解析度分割更快收斂,
我們在測驗集中的10,000幅影像上評估了我們的模型和第4.1節中的基線方法的性能,以下兩個指標用于評估:整體交-并(IoU)指標和精度指標,總IoU是總相交面積除以總并集面積,其中相交面積和并集面積都是在所有測驗樣本上累積的(每個測驗樣本是一個影像和一個參考運算式),雖然整體IoU指標是PASCAL VOC分割[11]中使用的標準指標,但我們的評估略有不同,因為我們希望衡量模型在背景下分割輸入運算式描述的前景區域的準確性,而整體IoU指標有利于天空和地面等大區域,因此,我們還用精度指標從易到難對5個不同的IoU閾值進行評估:0.5、0.6、0.7、0.8、0.9,精度指標是預測值和地面真實值之間的IoU超過閾值的測驗樣本的百分比,例如,precision@0.5是預測分割與基礎真實區域重疊至少50% IoU的運算式的百分比,
Results
表1總結了我們評估的主要結果,只需回傳整個影像,就已經獲得了15%的整體IoU,這部分是由于ReferIt資料集包含一些大區域,如“天空”和“城市”,并且整體IoU指標對大區域賦予了更多權重,但是不出所料,整個影像基線的精度最低,
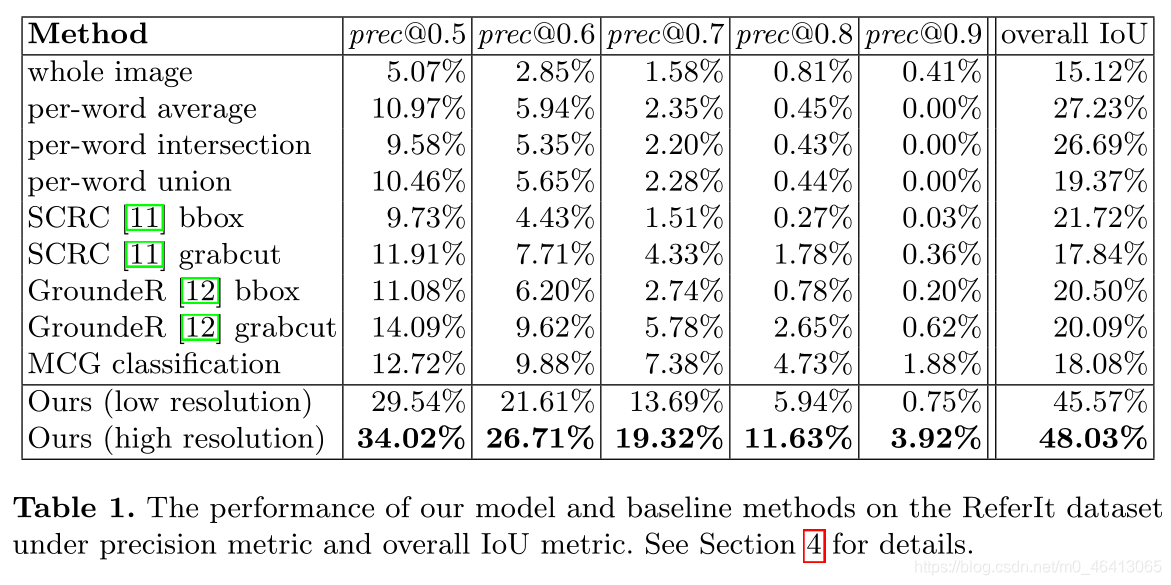
從表1可以看出,通過對每個單詞的分割并結合每個單詞的結果,可以得到一個合理的整體IoU,在第4.1節中三種不同的組合每個單詞結果的方法中,平均每個單詞的分數效果最好,使用來自SCRC[11] (“SCRC bbox” ) 或接地器[12] (“接地器bbox”)的整個包圍盒預測獲得了與平均每個單詞分割相當的精度,而它們在整體IoU方面更差,并且使用來自MCG的分割建議的分類(“MCG分類”)導致比這兩種方法稍高的精度,此外,可以看到,與使用整個邊界框區域相比,使用GrabCut [9]從邊界框中分割前景(“SCRC grabcut”和“地滾球GrabCut”)對SCRC和地滾球都產生了更高的精度,我們認為精度度量更能反映自然語言運算式分割方法的性能,因為在實際應用中,人們通常更關心參考運算式被正確分割的頻率,
在精度度量和整體IoU度量下,我們的模型在很大程度上優于所有基線方法,在表1中,倒數第二行(“低解析度”)對應于在來自我們的低解析度模型的粗略回應圖上直接使用雙線性上采樣,而最后一行(“高解析度”)顯示了我們的完整模型的性能,可以看出,與基線方法相比,我們的最終模型獲得了顯著更高的精度和整體IoU,圖4顯示了使用我們的模型和基線方法的一些分割例子,

參考資料集包含物件區域和填充區域,物件是那些具有明確定義的結構和封閉邊界的物體,如人、狗和飛機,而東西是那些沒有固定結構的物體,如天空、河流、道路和雪,盡管存在這種差異,但物件區域和填充區域都可以通過我們的模型使用相同的方法進行分割,圖5顯示了我們模型中物件區域的一些分割例子
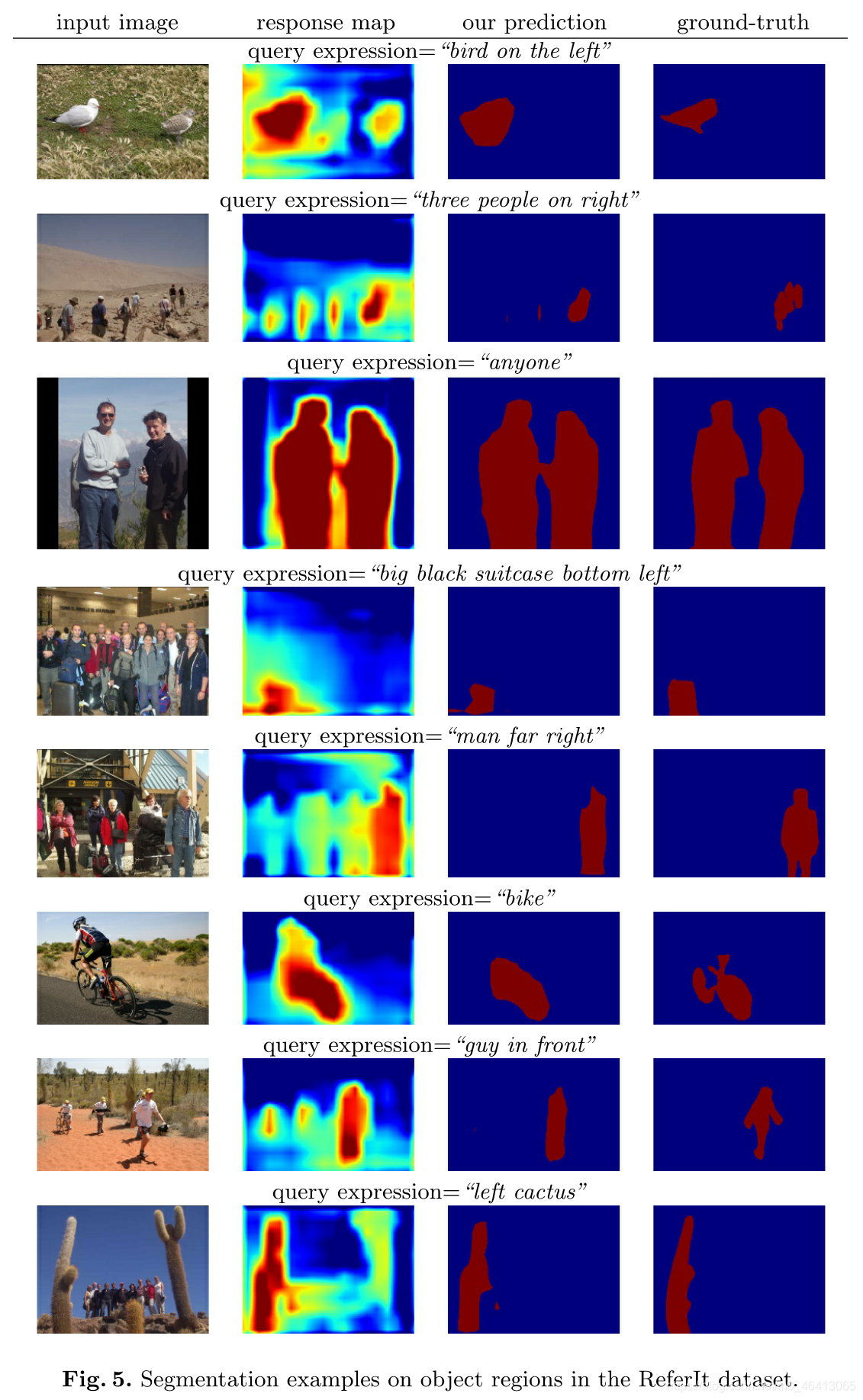
圖6顯示了填充區域的例子,
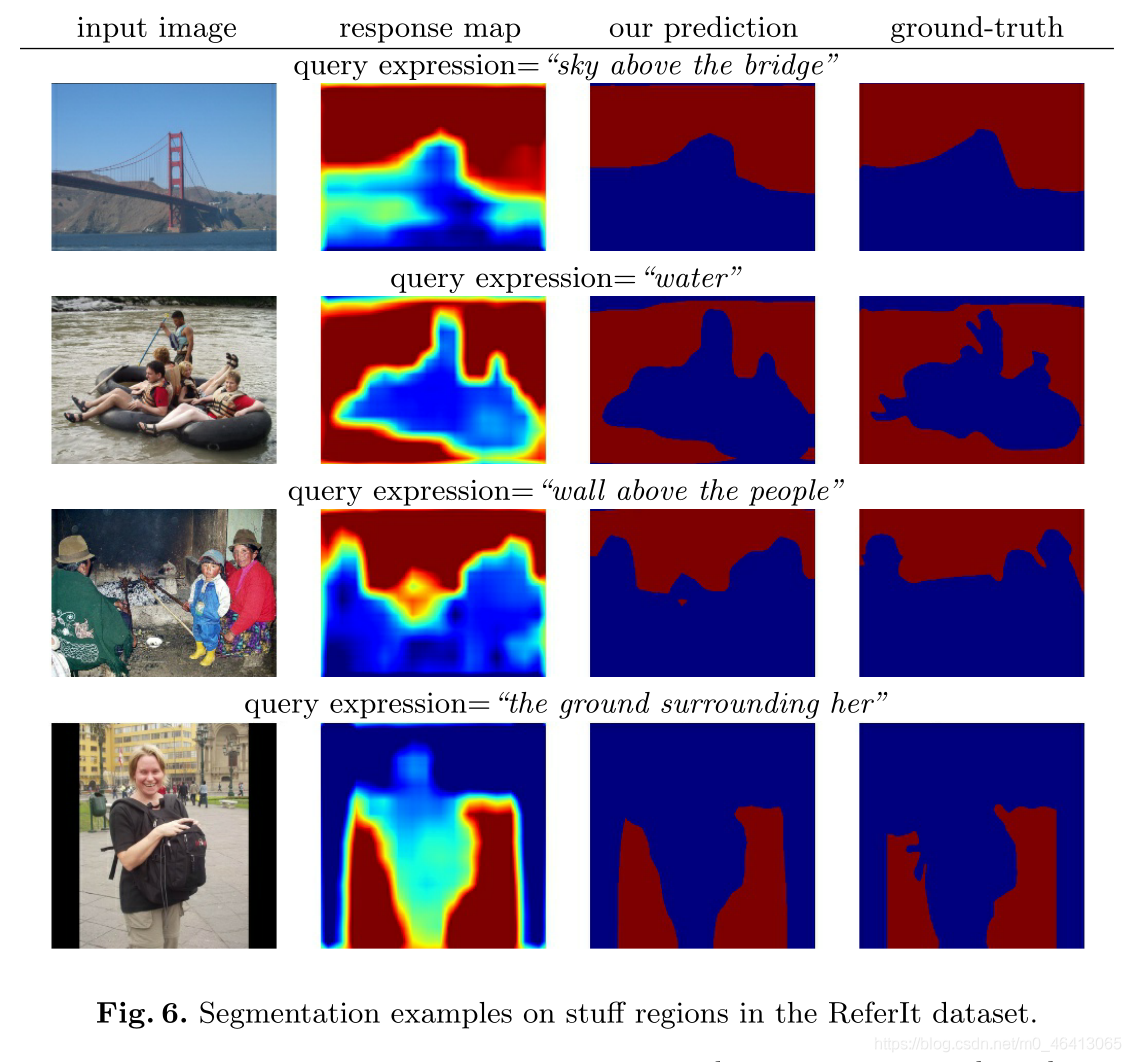
可以看出,我們的模型可以為“左邊的鳥”這樣的物件運算式和“橋上的天空”這樣的填充運算式預測合理的分割,
圖8顯示了同一張圖片上不同參考運算式的一些例子,
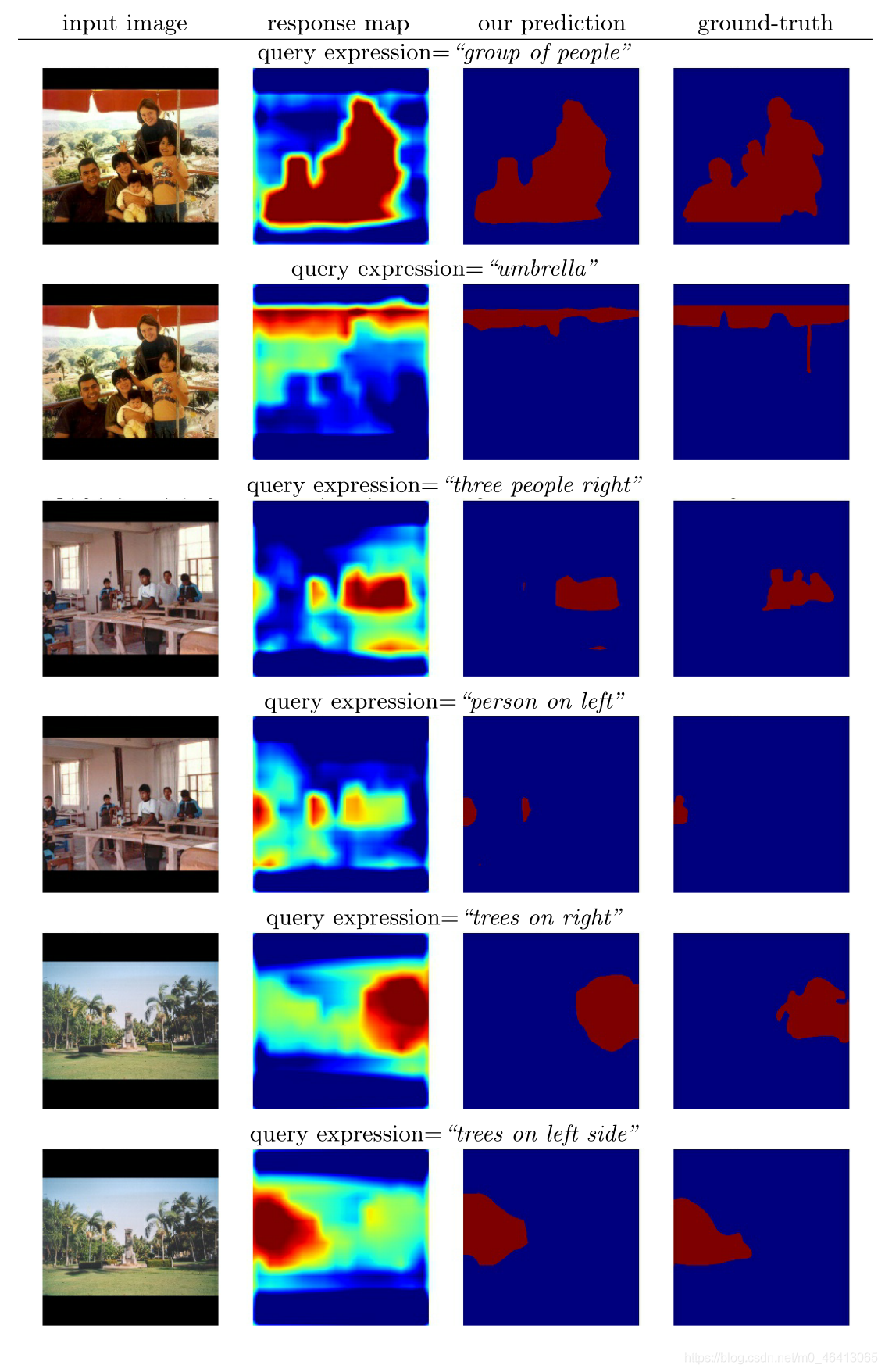
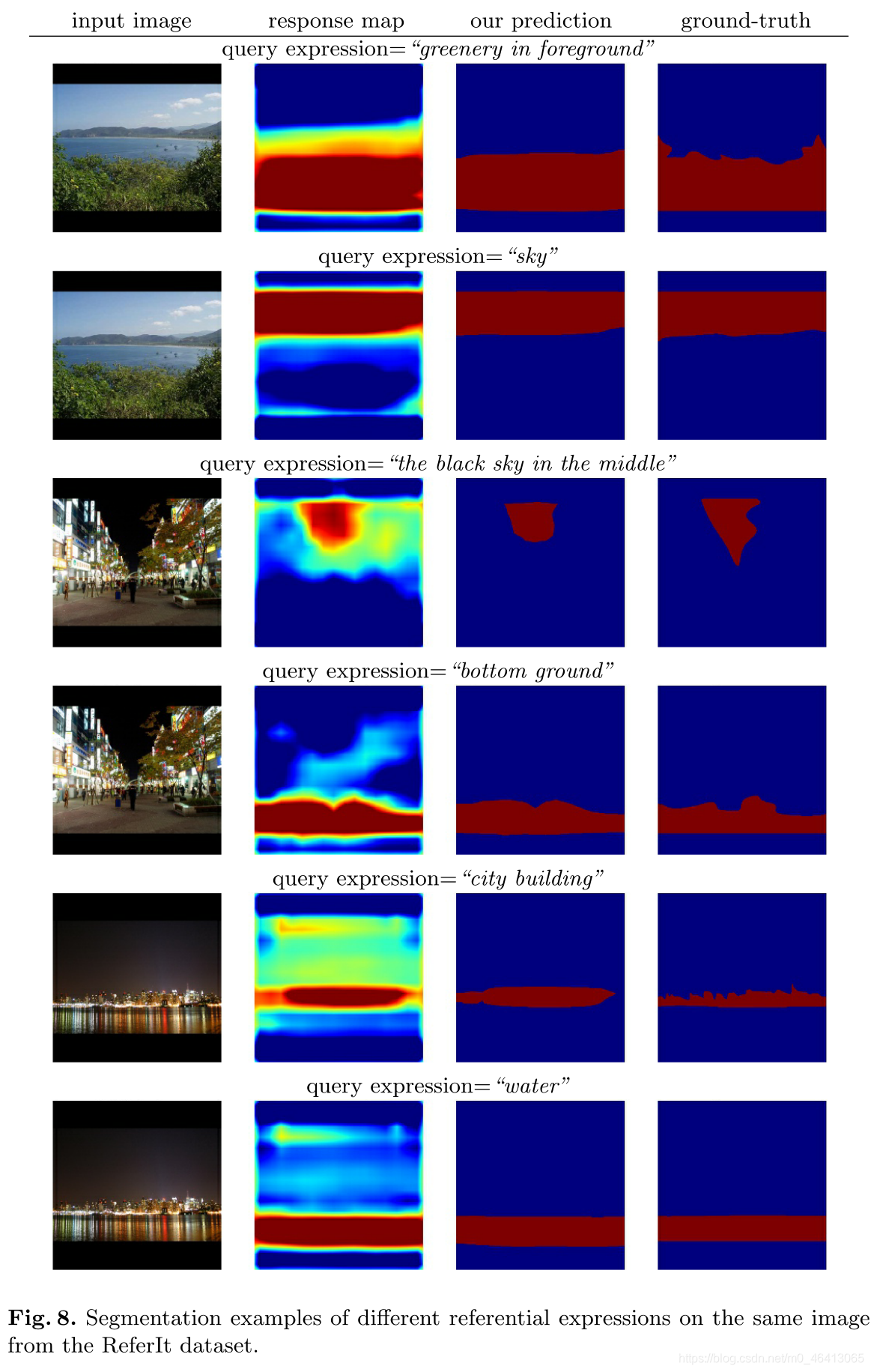
圖9和圖10顯示了更多關于物件和填充區域的分割示例,
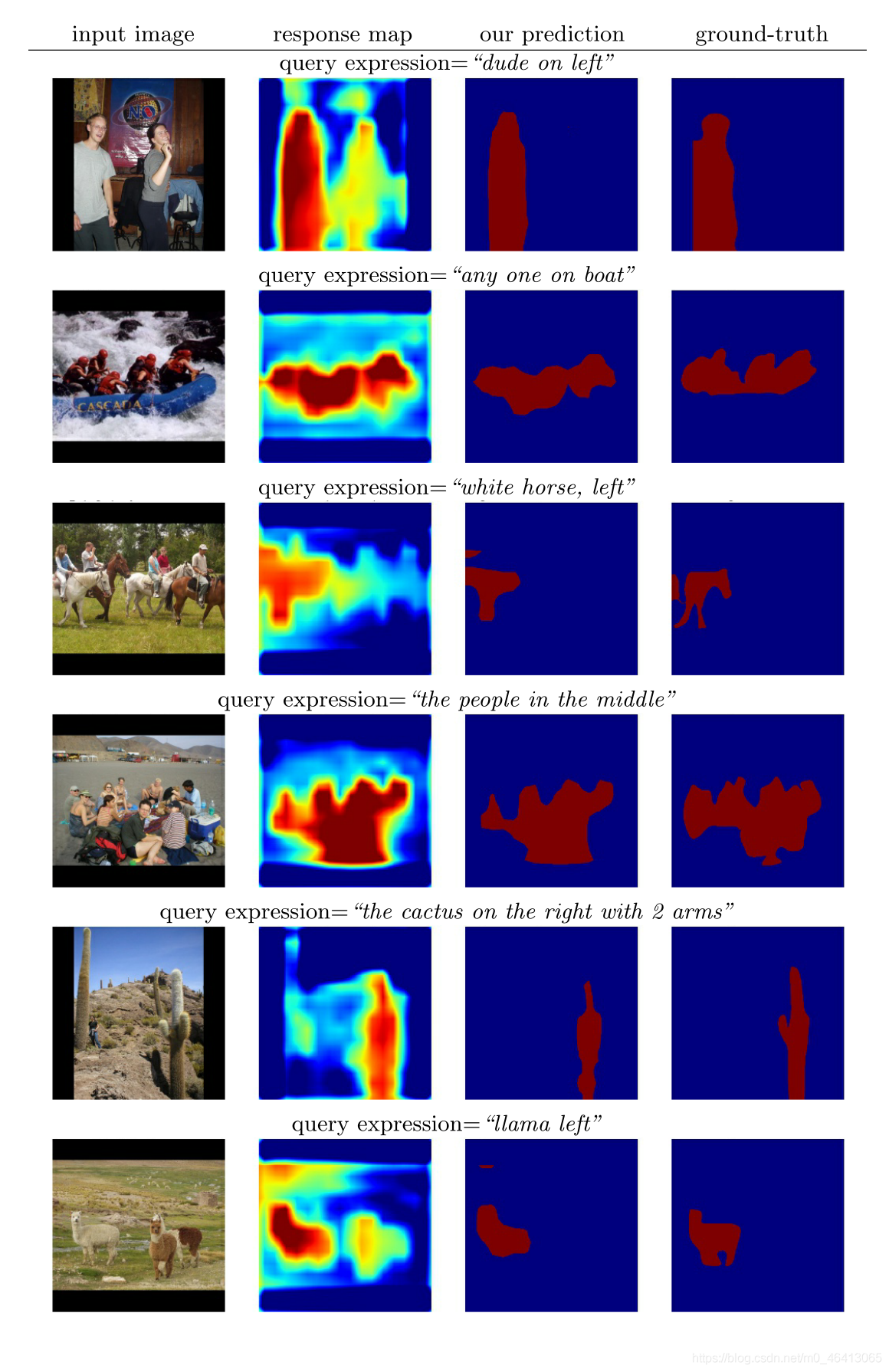
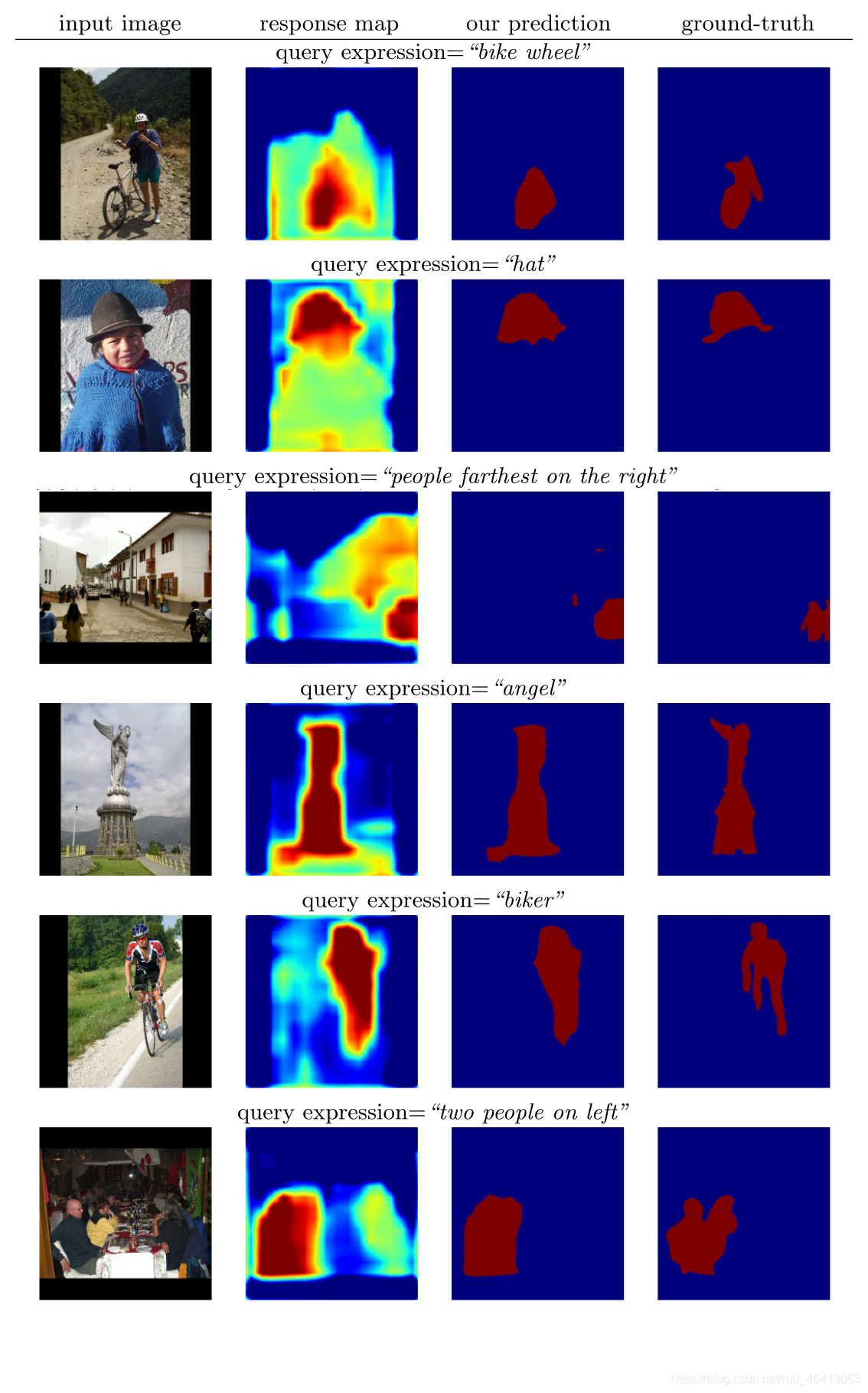
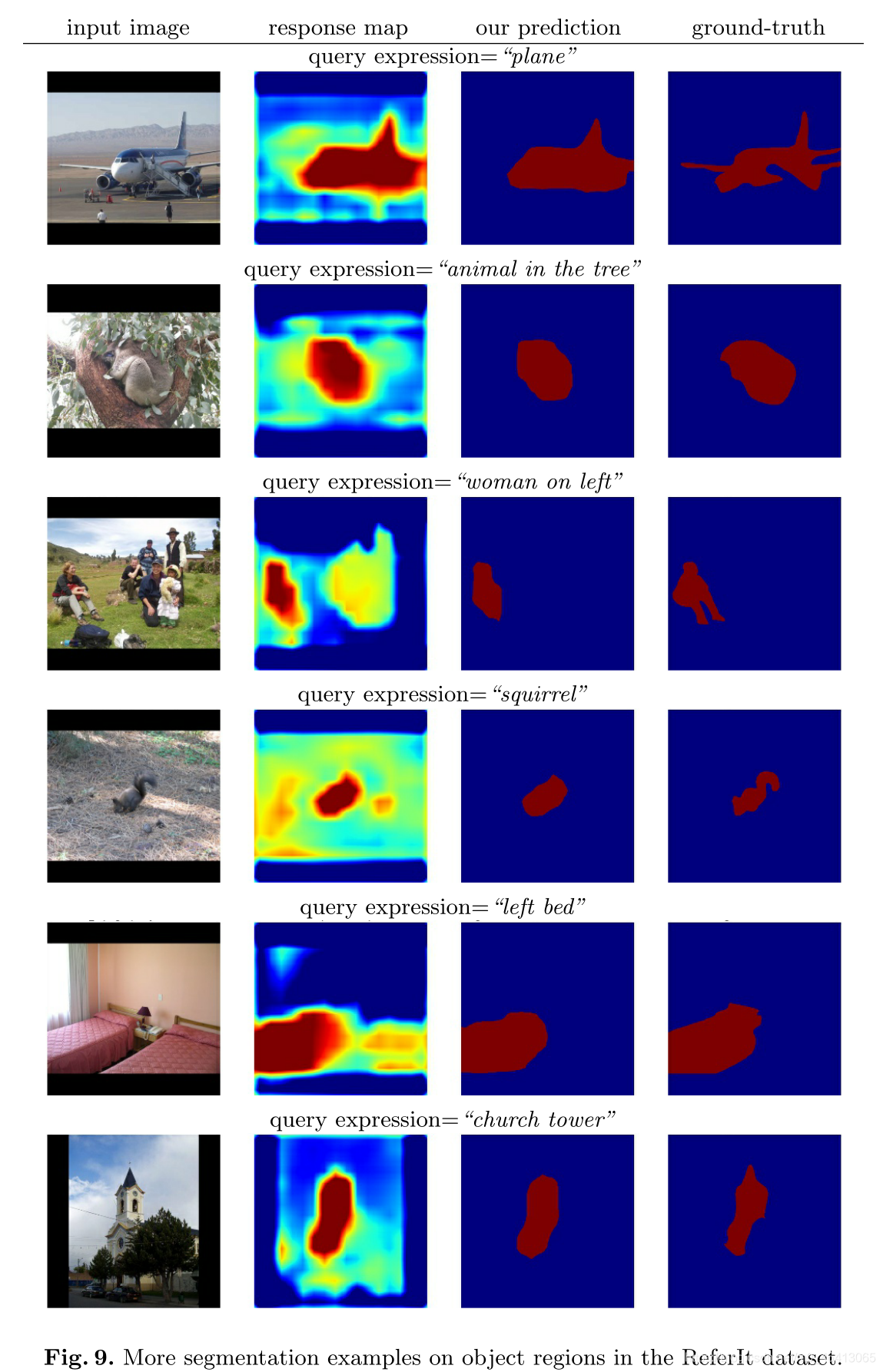
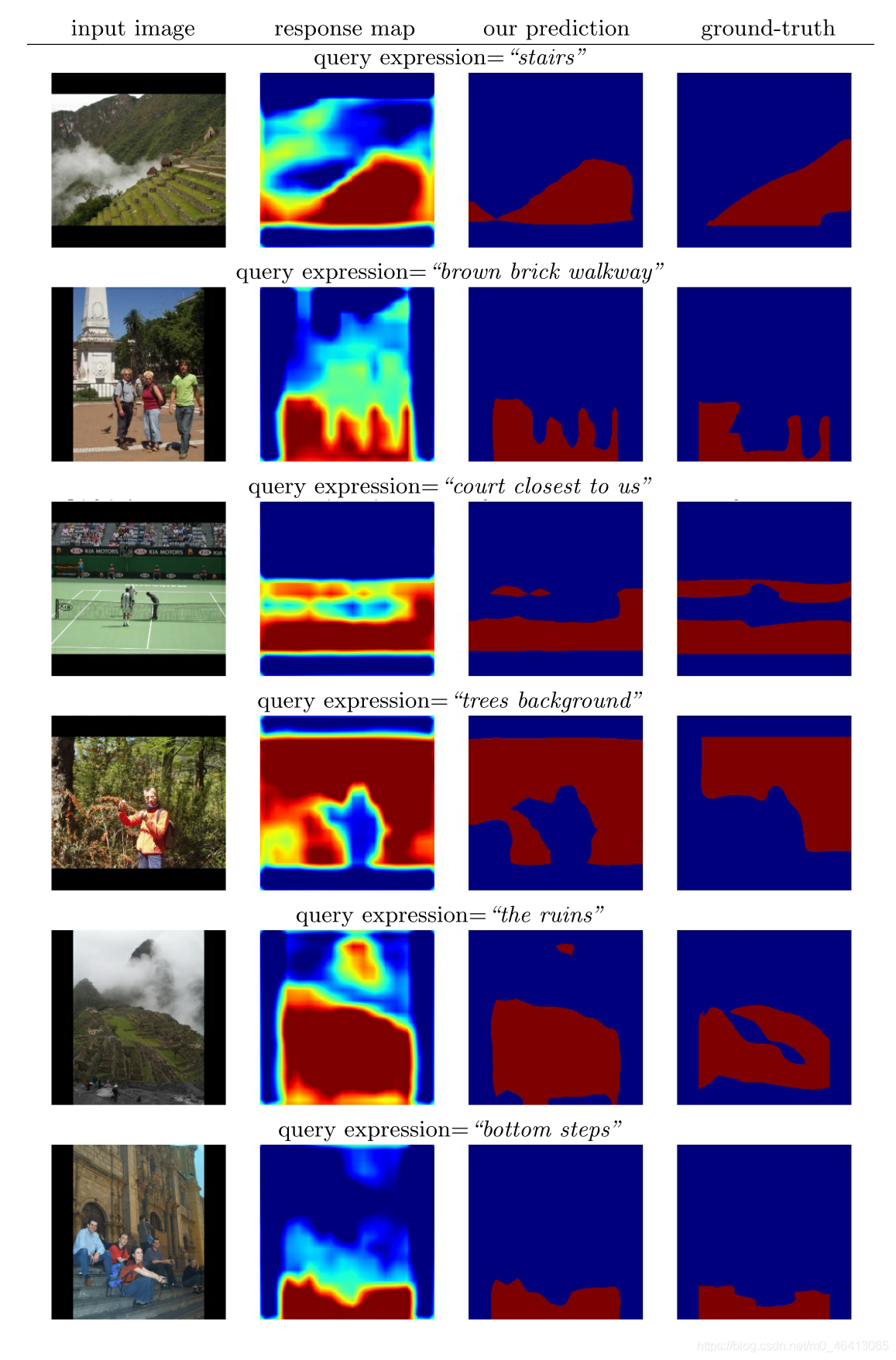
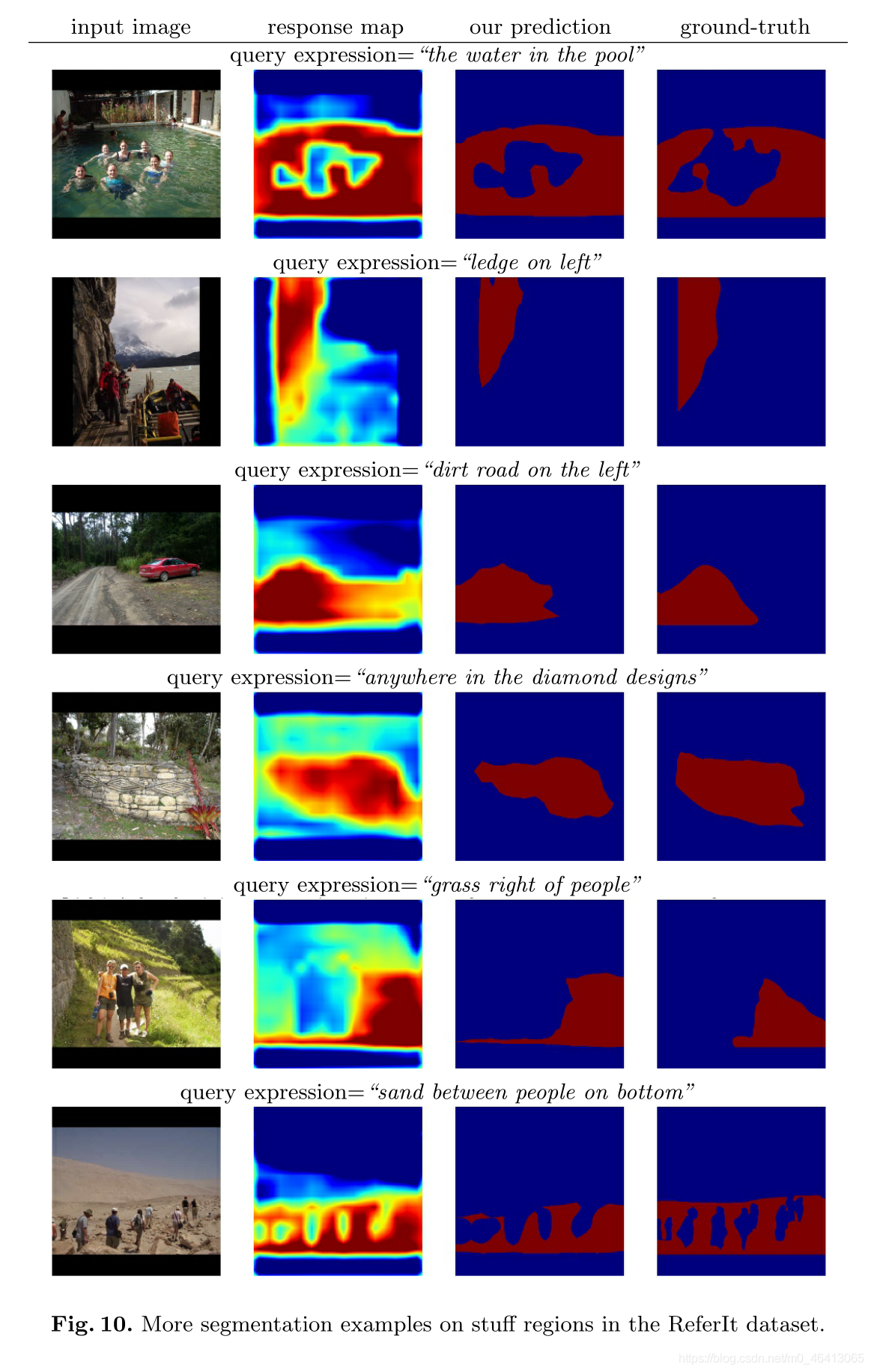
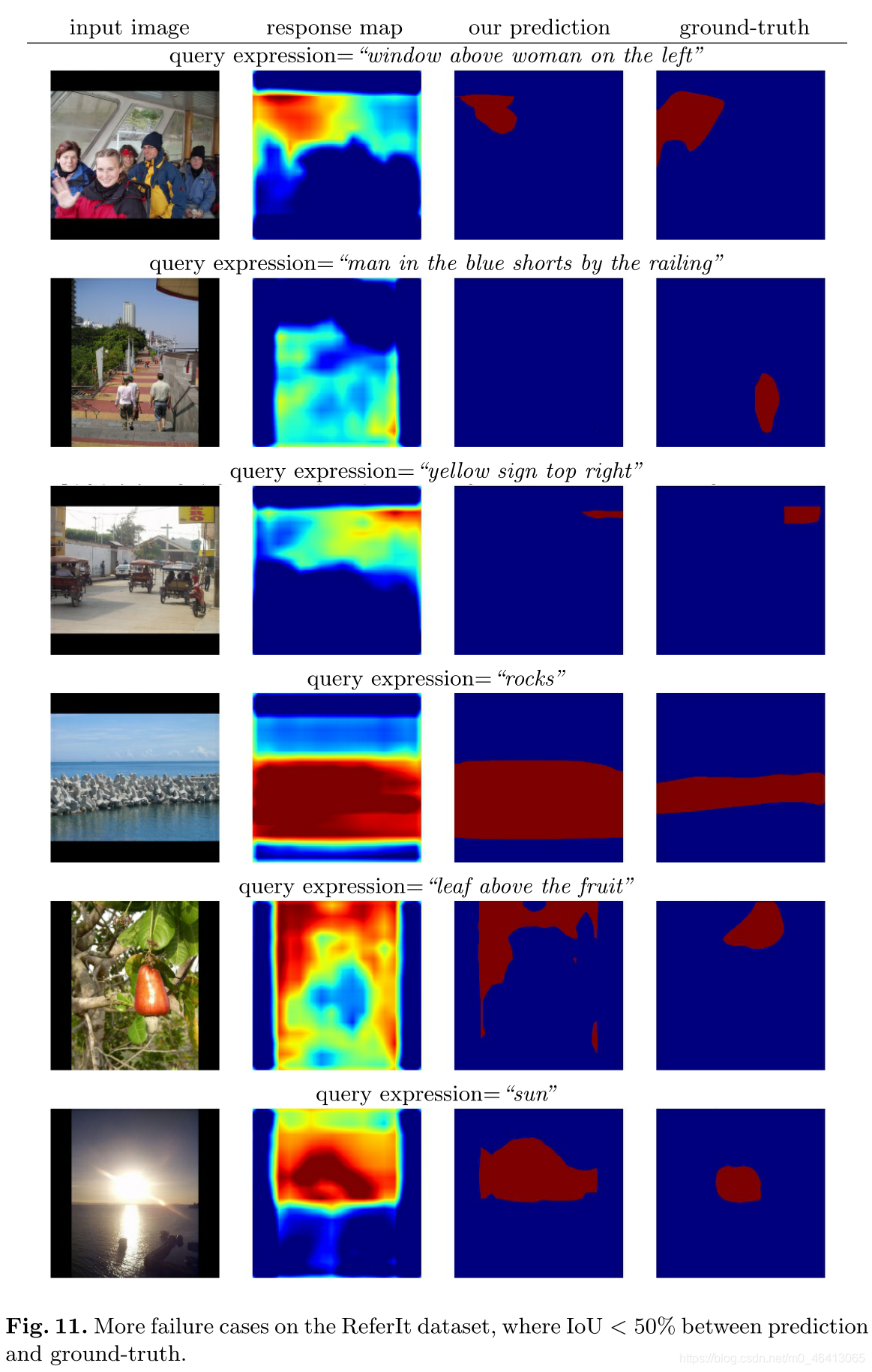
圖7顯示了參考資料集上的一些失敗案例,其中預測和基礎事實分割之間的IoU小于50%,在一些失敗的情況下(例如圖7,中間),我們的模型產生了合理的回應圖,覆寫了自然語言參考運算式的目標區域,但是不能精確地分割出物件或事物的邊界,
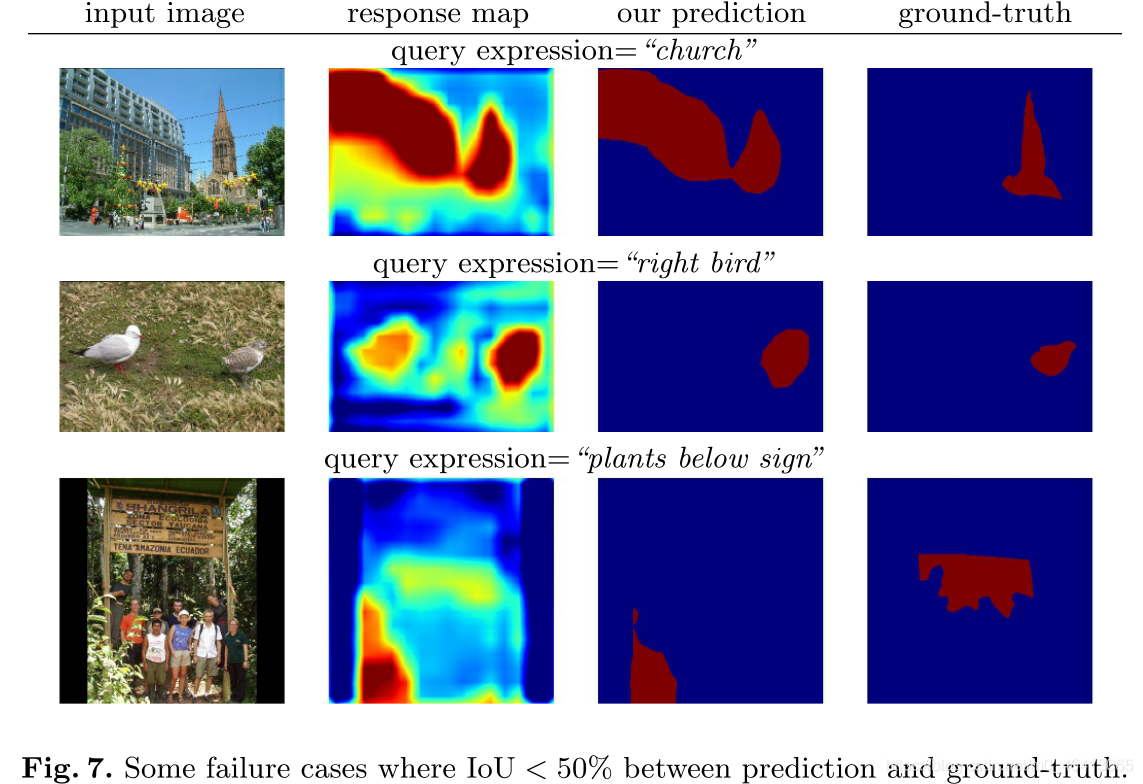
圖11顯示了更多的失敗案例,
Speed
我們還比較了我們的方法和基線方法的速度,表2顯示了在一臺帶有NVIDIA特斯拉K40 GPU的機器上,不同模型在測驗時預測分段的平均時間消耗,可以看出,雖然我們的方法比每個詞的切分基線慢,但它比基于建議的方法(如“SCRC grabcut”或“MCG分類”)快得多,

Conclusion
在本文中,我們解決了分割自然語言運算式的挑戰性問題,以生成參考運算式所描述的影像區域的像素化分割輸出,為了解決這個問題,我們提出了一個端到端的可訓練遞回卷積神經網路模型,將運算式編碼為向量表示,從影像中提取空間特征映射表示,并基于完全卷積分類器和上采樣輸出像素化分割, 我們的模型可以有效地預測描述單個或多個物件或事物的參考運算式的分割輸出,在基準資料集上的實驗結果表明,我們的模型比基線方法有很大的優勢,
Acknowledgments
作者感謝麗莎·亨德里克斯和馬塞爾·西蒙對草稿的反饋,這項作業得到了美國國防高級研究計劃局、AFRL、美國國防部MURI獎第000141110688號、美國國家科學基金會獎第1427425號和第1212798號以及伯克利視覺和學習中心的支持,馬庫斯·羅爾巴憾訓得了德國學術交流服務(DAAD)惠譽國際專案的獎學金,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282622.html
標籤:其他
下一篇:初識計算機作業系統與行程