目錄
YOLOv3的改進
1. YOLOv3的第一個改進是網路的結構的改變
2. YOLOv3的第二個改進是多尺度訓練
YOLOv3代碼實戰
1. 資料集標注
2. 資料預處理
YOLO系列總結
大家好,我是羽峰,今天要和大家分享的是YOLOv3演算法,YOLOv3演算法是在YOLOv2演算法的基礎上繼續進行改進的,本文章不僅包括YOLOv3的改進原理,而且還包括YOLOv3的代碼實體講解,希望通過本視頻講解,各位朋友能夠更好的應用YOLOv3去訓練自己的專案,
如果想要YOLOv3代碼,歡迎關注“羽峰碼字”公眾號,并回復“YOLOv3”獲取相應代碼,
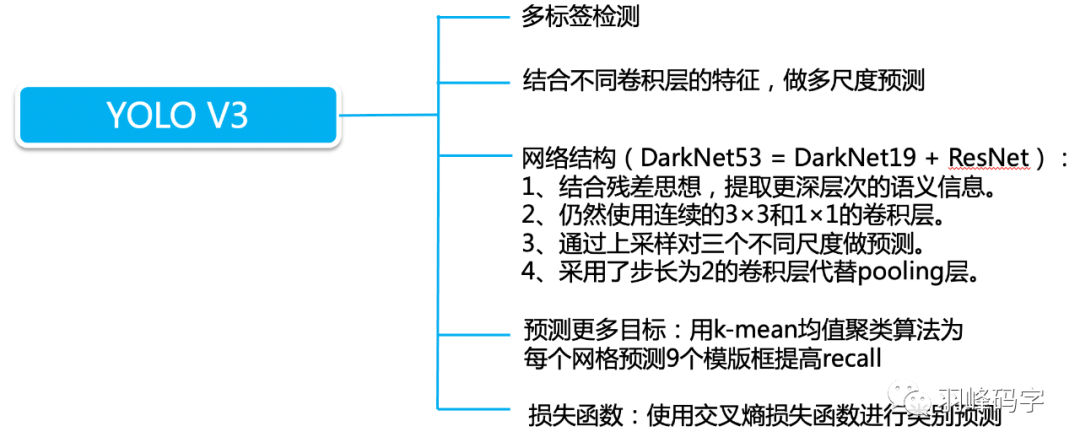
YOLOv3的改進
1. YOLOv3的第一個改進是網路的結構的改變
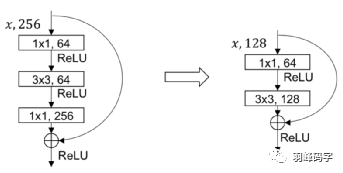
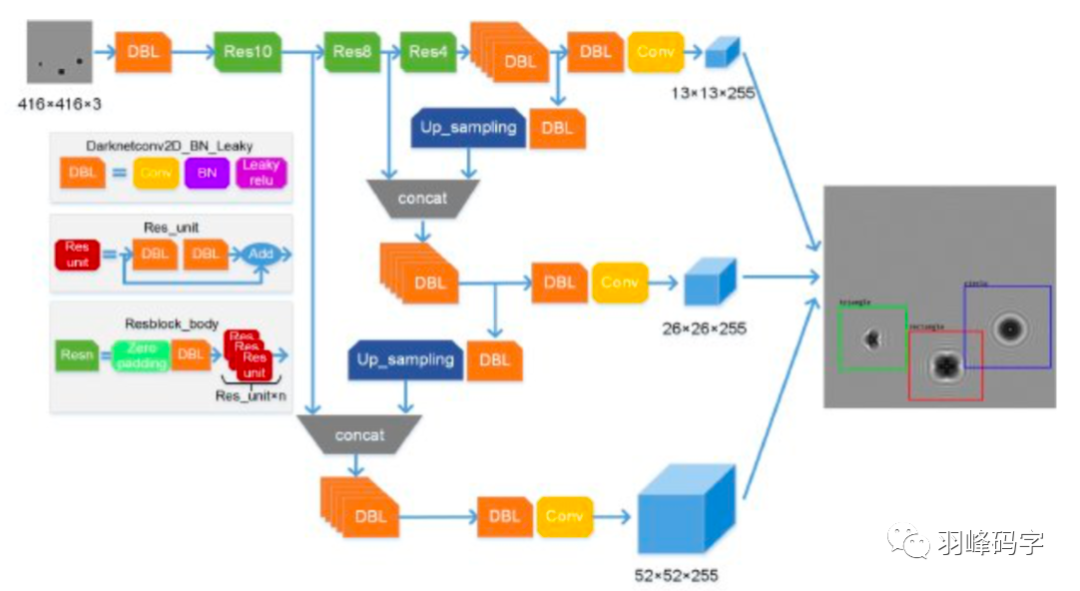
引入了ResNet思想,但是如果將ResNet模塊完全引進是整個模型就很大,所以直接將ResNet模塊的最后一層1*1*256去掉,而且將倒數第二層3*3*64直接改成3*3*128,整個網路結構如圖所示,輸入的是416*416*3的RGB影像,網路會輸出三種尺度的輸出,最后輸出每個目標物體的類別和邊框,
2. YOLOv3的第二個改進是多尺度訓練
這個多尺度訓練是真正的多尺度,一共有3種尺度,分別是13*13,26*26,52*52三種解析度,分別負責預測大,中,小的物體邊框,這種改進對小物體檢測更加友好,

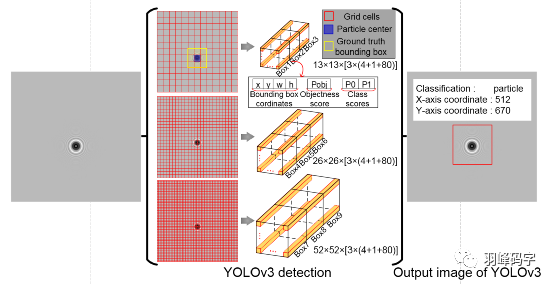
YOLOv3多尺度訓練的原理如圖所示,首先一個影像輸入,被YOLOv3分割成13*13,26*26,52*52的網格,每種解析度的每個網格分別對應一個包含255個引數的向量,每個向量包括三個邊框(,每個邊框中包含85個引數,分別是邊框的中心位置(x,y),邊框的寬和高(w,h)邊框的置信度,還有80個類別概率,最后輸出每個物體的類別概率和邊框,
YOLOv3代碼實戰
1. 資料集標注
訓練YOLOv3首先要進行LabelImg標注,
LabelImg的網址為:https://github.com/tzutalin/labelImg,
安裝程式如圖所示:

安裝好之后,界面如圖所示:
首先點擊”open”打開圖片,如圖所示,打開的是一個狗和貓的圖片,然后選擇邊框進行標注,
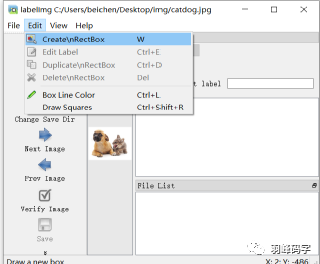
標注好之后應該,應該備注目標物體類別,如圖所示:
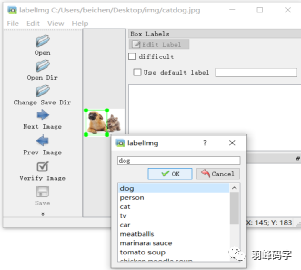
標注好之后會生成“catdog.xml”檔案,
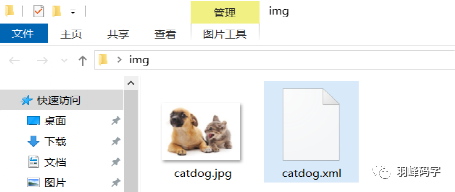
檔案內容如圖所示:

最后分別將圖片(catdog)放入./VOCdevkit/VOC2007/JpegImages, LabelImg標注影像放進“Annotations”中,如圖所示:

2. 資料預處理
當圖片和xml檔案都準備好之后 ,運行“voc2yolo3.py”程式,生成資料集串列檔案,將圖片上對應的”voc_classes.txt”換成你自己的分類標簽,如果有多個類別,請將每個類別單獨放一行,
由于我這里是零時加入進來的資料,不是本YOLOv3所執行的,后邊圖片中的資料都是原yolov3的資料,所以有些資料對應不上,但執行整個程序是接下來要說的,如果訓練自己的資料集,需要將自己的資料粘貼到對應位置,
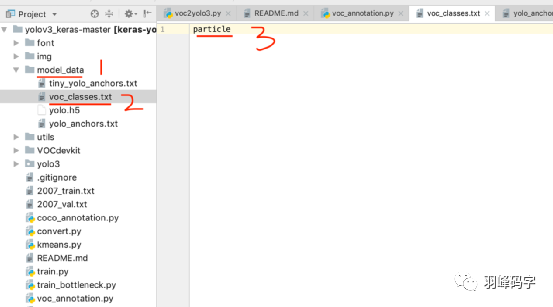
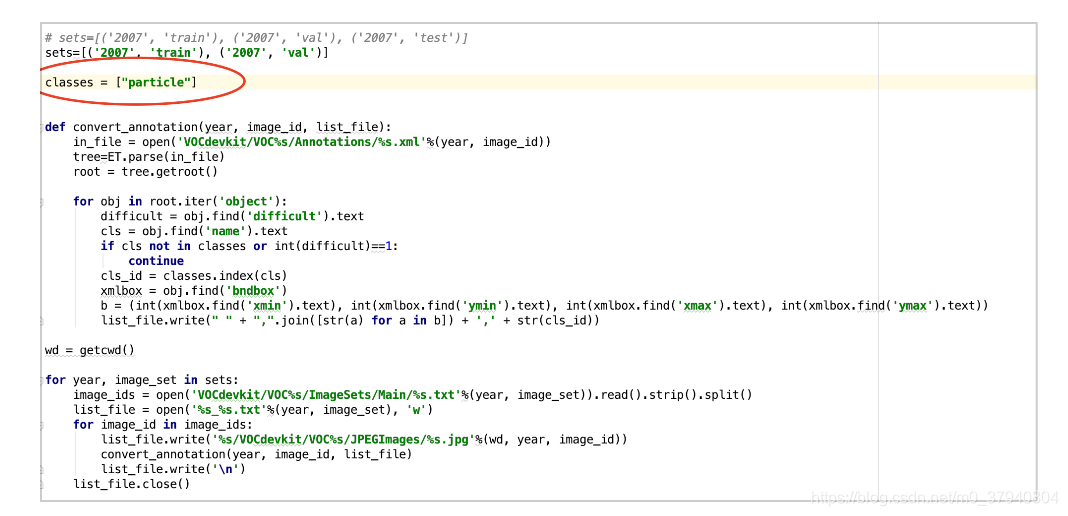
之后在運行“voc_annotation.py”程式,運行之前,首先將程式中的類別改成你自己的類別,我這里類別只有一個“particle”
之后在運行“kmeans.py”程式,運行好之后會生成k anchor,這些數字代表了你的預生成的標注框大小,將這些標注框資料首先放入如圖所示的位置,并按照“yolo_anchors.txt”原有格式進行修改,

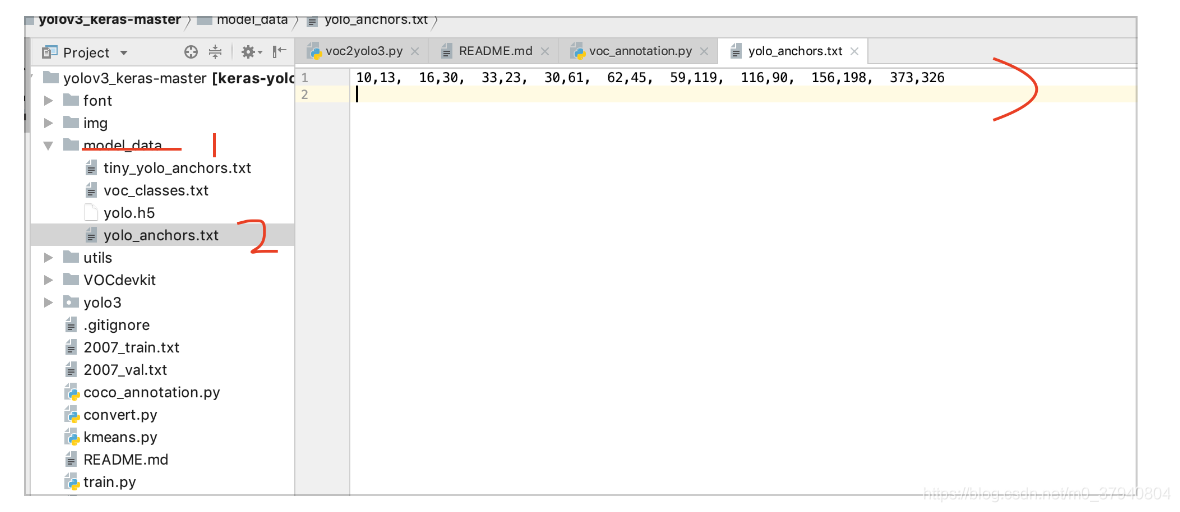
接下來在復制這些數字到“yolov3.cfg”中,搜索”yolo”將對應的anchors 和classes 進行修改,classes選擇你要分類的類別,我這里只有1個類別,就改成了1,一共有3個“yolo”,都要修改,修改之后就執行直接執行“train.py”了,
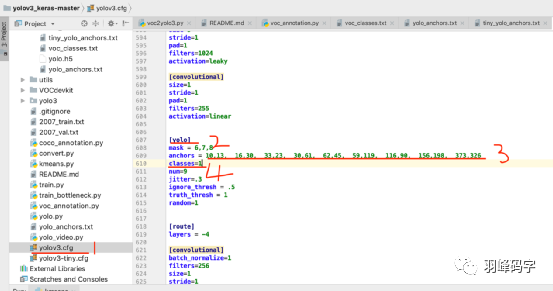
如果訓練完成之后,執行“yolo_video.py”進行測驗就行,如果是從我公眾號下載的yolov3,需要將yolo_video.py做如下修改:


YOLO系列總結
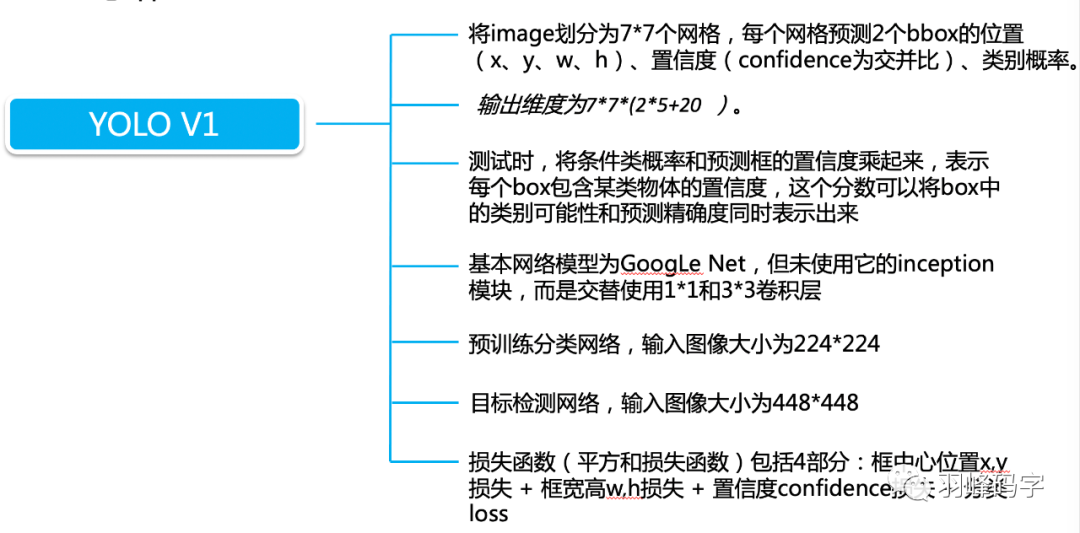
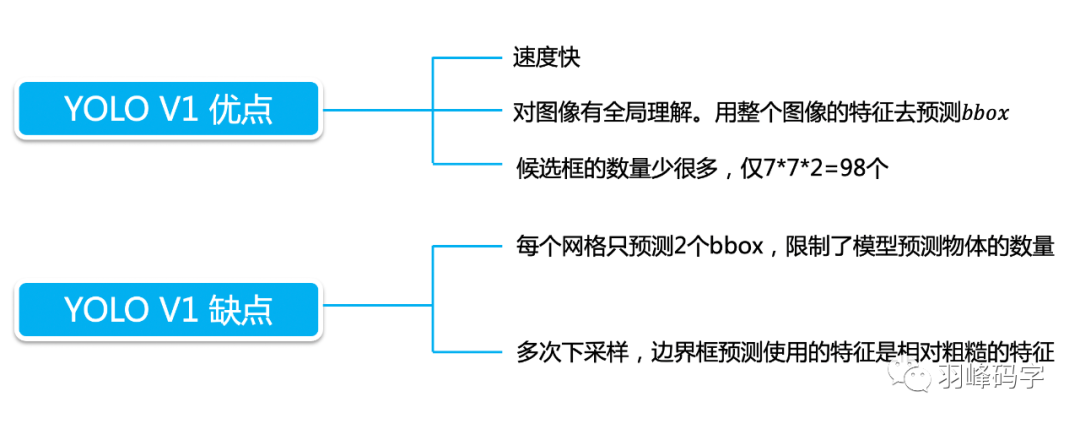
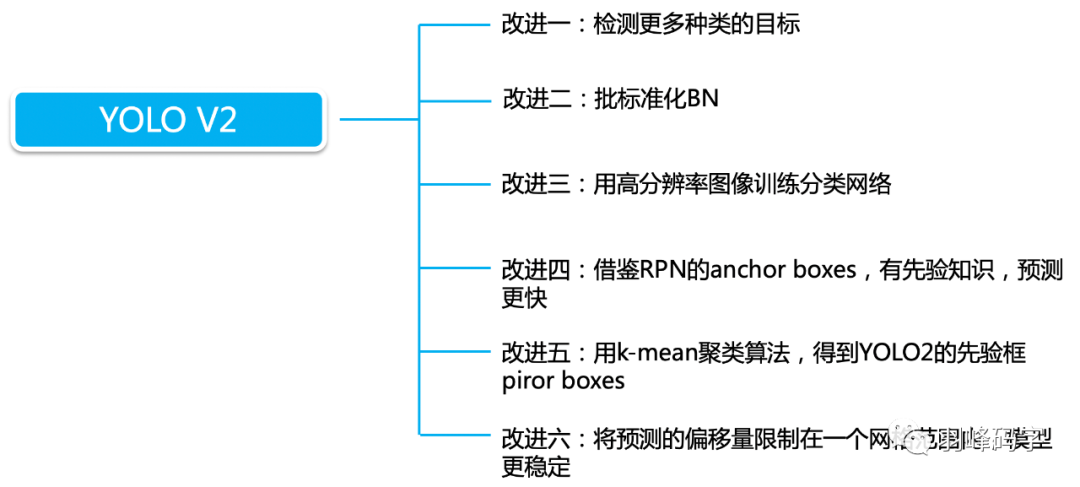
以上 就是我今天要分享的內容,謝謝各位,如有錯誤,歡迎批評指正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282838.html
標籤:AI