文章目錄
- 一.樹及其相關概念
- (1).樹的介紹
- (2).樹的表示
- 二.二叉樹概念及結構
- (1).二叉樹概念及特點
- (2).特殊的二叉樹
- (3).二叉樹的性質
- (4).二叉樹相關練習
- 三.二叉樹的順序結構及實作
- (1).堆的概念
- (2).堆的實作
- 向下調整演算法
- 建堆
- 堆的插入
- 堆的洗掉
- 堆的銷毀
- 取堆頂資料
- 堆的資料個數
- 堆的判空
- 完整代碼
- (3).堆排序
- 四.二叉樹的鏈式結構及實作
- (1).二叉樹鏈式結構
- (2).二叉樹的前中后序遍歷
一.樹及其相關概念
(1).樹的介紹
樹是一種非線性的資料結構,它是由n(n>=0)個有限結點組成一個具有層次關系的集合,
樹的特點 :
(1).有一個特殊的結點,稱為根結點,根節點沒有前驅結點
(2).除根節點外,其余結點被分成M(M>0)個互不相交的集合T1、T2、……、Tm,其中每一個集合Ti(1<= i <= m)又是一棵結構與樹類似的子樹,每棵子樹的根結點有且只有一個前驅,可以有0個或多個后繼,因此,樹是遞回定義的,
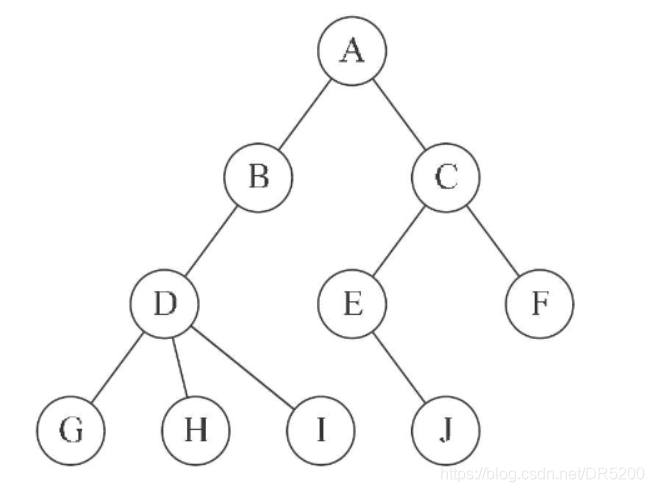
樹的相關概念
節點的度:一個節點含有的子樹的個數稱為該節點的度; 如上圖:A的為2
葉節點或終端節點:度為0的節點稱為葉節點; 如上圖:F,G,H,I,J 節點為葉節點
非終端節點或分支節點:度不為0的節點; 如上圖:A,B,C,D,E 節點為分支節點
雙親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點; 如上圖:A是B的父節點
孩子節點或子節點:一個節點含有的子樹的根節點稱為該節點的子節點; 如上圖:B是A的孩子節點
兄弟節點:具有相同父節點的節點互稱為兄弟節點; 如上圖:B、C是兄弟節點
樹的度:一棵樹中,最大的節點的度稱為樹的度; 如上圖:樹的度為3
節點的層次:從根開始定義起,根為第1層,根的子節點為第2層,以此類推;
樹的高度或深度:樹中節點的最大層次; 如上圖:樹的高度為 4
堂兄弟節點:雙親在同一層的節點互為堂兄弟;如上圖 : I ,J 互為兄弟節點
節點的祖先:從根到該節點所經分支上的所有節點;如上圖:A是所有節點的祖先
子孫:以某節點為根的子樹中任一節點都稱為該節點的子孫,如上圖:所有節點都是A的子孫
森林:由m(m>0)棵互不相交的樹的集合稱為森林;
(2).樹的表示
我們可以通過左孩子右兄弟的表示法來表示整個樹
data域用來存盤樹結點的資料
child域指向該結點從左往右數的第一個孩子結點
brother域指向該結點從左往右數的第一個兄弟結點
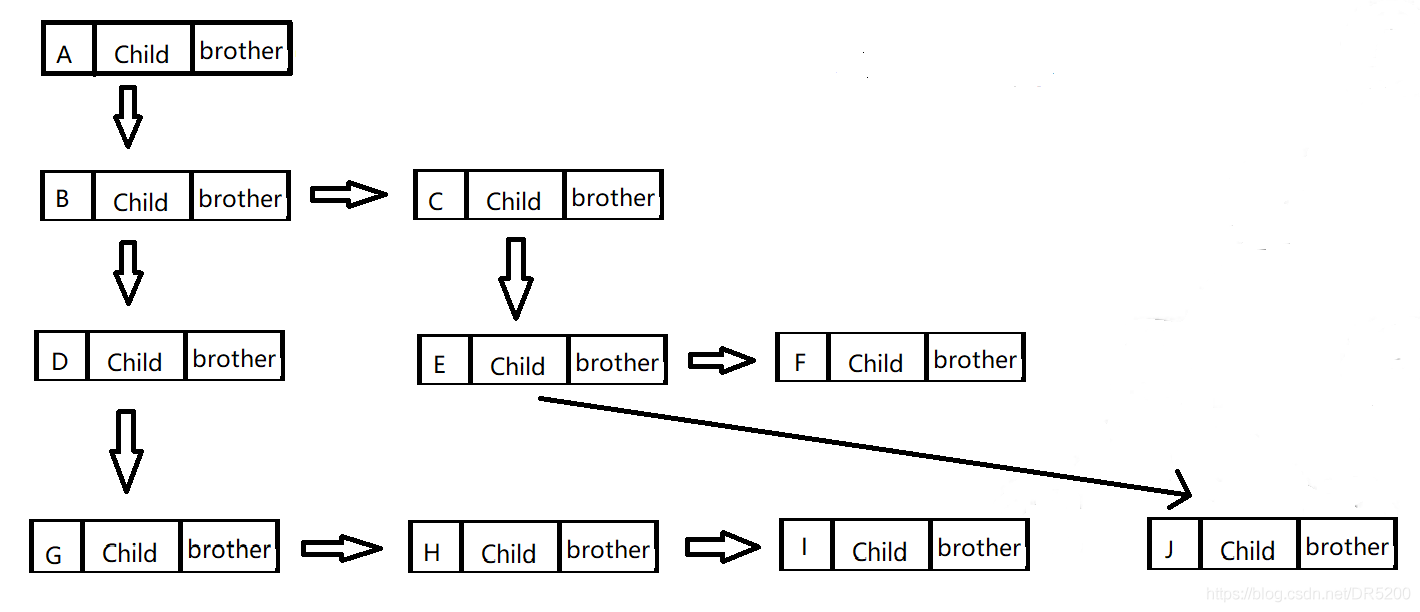 由此畫出上圖的左孩子右兄弟的示意圖
由此畫出上圖的左孩子右兄弟的示意圖
定義的結構體如下
typedef int DataType;
struct Node
{
struct Node* _firstChild1; // 第一個孩子結點
struct Node* _pNextBrother; // 指向其下一個兄弟結點
DataType _data; // 結點中的資料域
};
二.二叉樹概念及結構
(1).二叉樹概念及特點
概念:
一棵二叉樹是結點的一個有限集合,該集合或者為空,或者是由一個根節點加上兩棵別稱為左子樹和右子樹的二叉樹組成
二叉樹的特點:
(1). 每個結點最多有兩棵子樹,即二叉樹不存在度大于2的結點,
(2). 二叉樹的子樹有左右之分,其子樹的次序不能顛倒,
(2).特殊的二叉樹
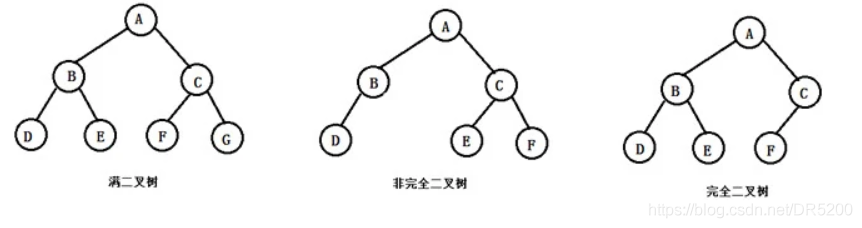
(1).滿二叉樹
如果每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹,也就是說,如果一個二叉樹的層數為K,且結點總數是(2^k) -1 ,則它就是滿二叉樹,
(2). 完全二叉樹
若一個二叉樹的層數為k,前 k - 1 層結點都是滿的,第k層結點取值范圍為[1,2^(k - 1)],結點從左到右是 連續 的,由定義可知滿二叉樹是第k層結點為 2^(k - 1)的完全二叉樹
(3).二叉樹的性質
- 若規定根節點的層數為1,則一棵非空二叉樹的第i層上最多有2^(i-1) 個結點.
- 若規定根節點的層數為1,則深度為h的二叉樹的最大結點數是2^h- 1.
- 對任何一棵二叉樹, 如果度為0其葉結點個數為 n0, 度為2的分支結點個數為 n2,則有n0=n2+1
- 若規定根節點的層數為1,具有n個結點的滿二叉樹的深度,h=Log2(n+1). (ps:Log2(n+1)是log以2為底,n+1為對數)
- 對于具有n個結點的完全二叉樹,如果按照從上至下從左至右的陣列順序對所有節點從0開始編號,則對于序號為i的結點有:
若i>0,i位置節點的雙親序號:(i-1)/2;i=0,i為根節點編號,無雙親節點
若2i+1<n,左孩子序號:2i+1,2i+1>=n否則無左孩子
若2i+2<n,右孩子序號:2i+2,2i+2>=n否則無右孩子
(4).二叉樹相關練習
(1).某二叉樹共有 399 個結點,其中有 199 個度為 2 的結點,則該二叉樹中的葉子結點數為
由性質3可知 葉子結點有200個
(2).在具有 2n 個結點的完全二叉樹中,葉子結點個數為
設葉子結點個數有n0個,由性質3可知,度為2的結點個數有 n0 - 1 個,由完全二叉樹的定義可知,完全二叉樹度為1的結點個數為 1 個或 0 個
n0 + n0 - 1 + n1 = 2n
由于2n為偶數,所以n1 = 1,n0 = n
(3).一棵完全二叉樹的節點數為531個,那么這棵樹的高度為
高度為9的滿二叉樹的結點個數為 2^9 - 1 = 511個
高度為10的滿二叉樹的結點個數為2^10 - 1 = 1023個
因此高度為10
(4).一個具有767個節點的完全二叉樹,其葉子節點個數為
設葉子結點個數有n0個,由性質3可知,度為2的結點個數有 n0 - 1 個,由完全二叉樹的定義可知,完全二叉樹度為1的結點個數為 1 個或 0 個
n0 + n0 - 1 + n1 = 767
由于767為奇數,所以n1 = 0,n0 = 384個
三.二叉樹的順序結構及實作
(1).堆的概念
普通的二叉樹是不適合用陣列來存盤的,因為可能會存在大量的空間浪費,而完全二叉樹更適合使用順序結構存盤,現實中我們通常把堆(完全二叉樹)使用順序結構的陣列來存盤
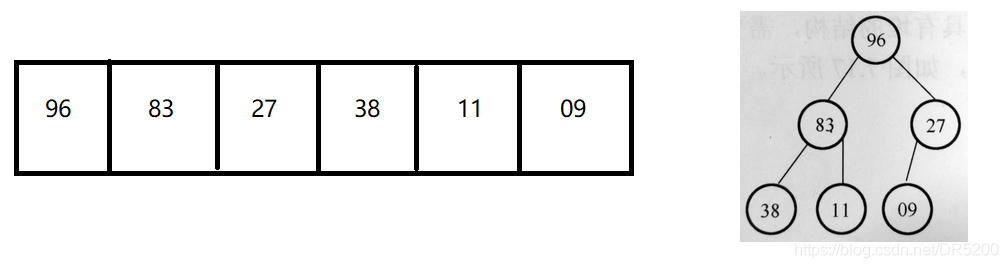
我們將根節點最大的堆叫做最大堆或大根堆,根節點最小的堆叫做最小堆或小根堆
堆的特點
(1).堆中某個節點的值總是不大于或不小于其父節點的值;
(2).堆總是一棵完全二叉樹
(2).堆的實作
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
當我們拿到一組資料以后,我們怎么把這組資料變成堆呢?首先我們先來了解一下向下調整演算法
向下調整演算法
注意 : 向下調整演算法的前提是左右子樹必須是堆(小堆/大堆)
我們在這里以int a[] = {27,15,19,18,28,34,65,49,25,37} 將其調整成小堆為例
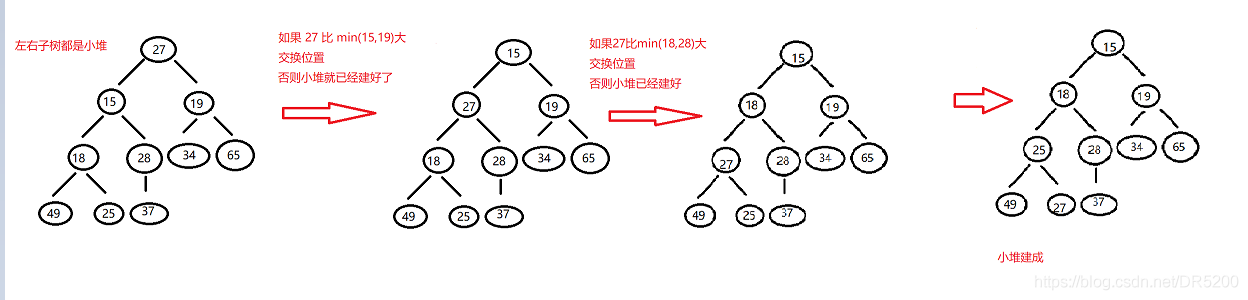 向下調整演算法實作(調整成小堆)
向下調整演算法實作(調整成小堆)
void AdjustDown(int* a,int parent,int n)
{
int child = 2 * parent + 1;
while(child < n)
{
// 注意判斷 child + 1 下標是否合法
if(child + 1 < n && a[child + 1] < a[child]) // a[child + 1] > a[child] 為調大堆
{
++child;
// 選出左右孩子中最小的那個
}
if(a[parent] > a[child]) // a[parent] < a[child] 為調大堆
{
Swap(&a[parent],&a[child]);
// 繼續回圈迭代
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
可我們拿到的資料不一定左右子樹都是堆,那么我們可以從第一個非葉子結點開始,進行向下調整演算法
建堆
以int a[] = {1,5,3,8,7,6} 建大堆為例
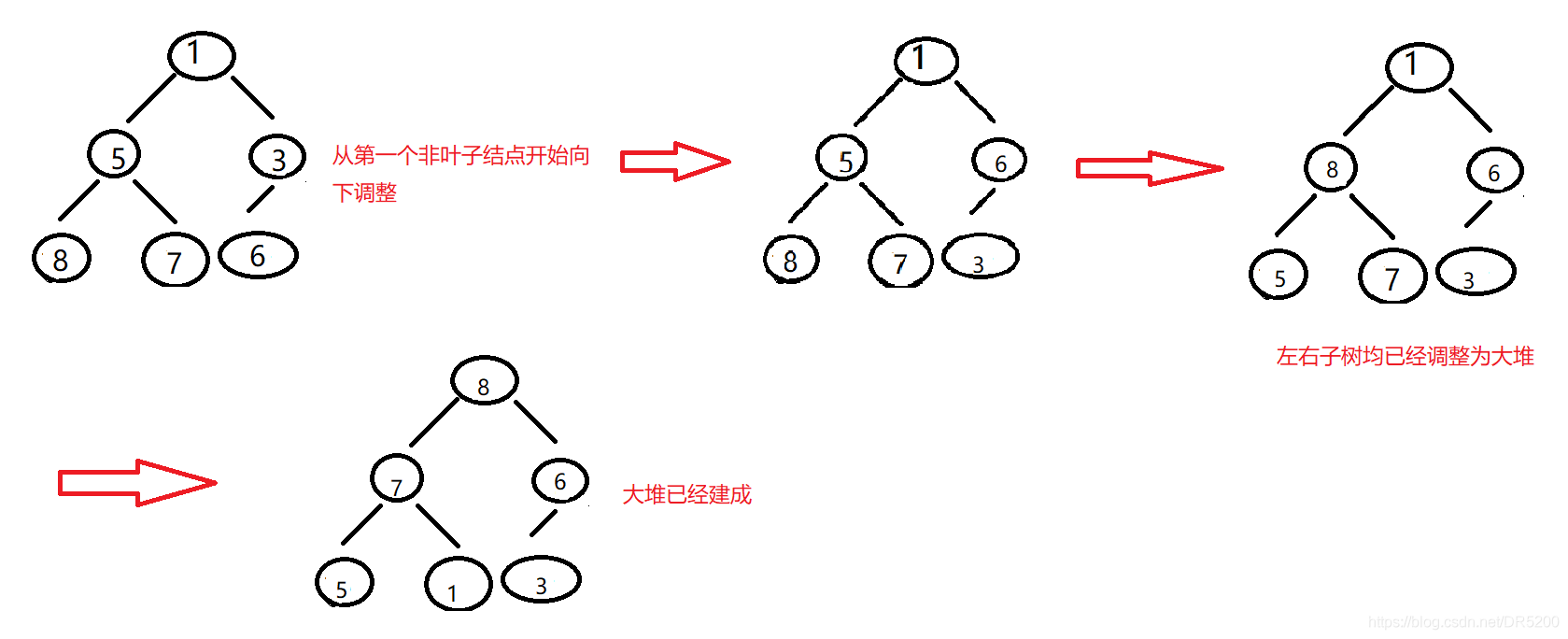
由上面二叉樹的性質5可知第一個非葉子結點的下標為 (n - 1 - 1) / 2, n - 1為最后一個結點的下標
(n - 1 - 1) / 2為最后一個結點的父結點的下標,即第一個非葉子結點下標
建大堆實作
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);
hp->_a = (HPDataType*)malloc(sizeof(HPDataType) * n);
hp-_size = hp->_capacity = n;
memcpy(hp->_a,a,sizeof(HPDataType) * n);
int i = (n - 2) / 2;
for(i = (n - 2) / 2;i >= 0;i--)
{
AdjustDown(hp->_a,i,n);
}
}
建大堆時將向下調整演算法寫成調大堆即可
建小堆時將向下調整演算法寫成調小堆即可
堆的插入
堆的插入,我們可以將資料插入到堆陣列末尾,再進行向上調整堆
以int a[] = {8,7,6,5,1,3} 插入9為例
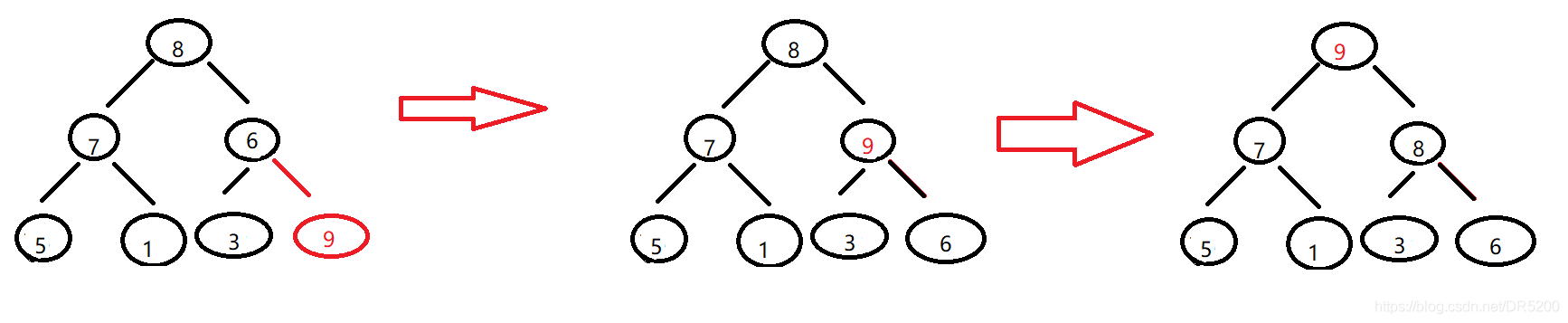
堆的插入實作
void AdjustUp(int* a,int child)
{
int parent = (child - 1) / 2;
while(child > 0)
{
if(a[child] > a[parent])
{
Swap(&a[child],&a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if(hp->_size == hp->_capacity)
{
hp->capacity *= 2;
HPDataType* tmp = (HPDataType*)realloc(hp->_a,sizeof(HPDataType) * hp->capacity);
if(tmp == NULL)
{
printf("realloc failed\n");
exit(-1);
}
hp->_a = tmp;
}
hp->_a[hp->_size] = x;
hp->size++;
AdjustUp(hp->_a,hp->size - 1);
}
堆的洗掉
洗掉堆是洗掉堆頂的資料,將堆頂的資料和最后一個資料一換,然后洗掉陣列最后一個資料,再進行向下調整演算法
以int a[] = {8,7,6,5,1,3} 洗掉8為例
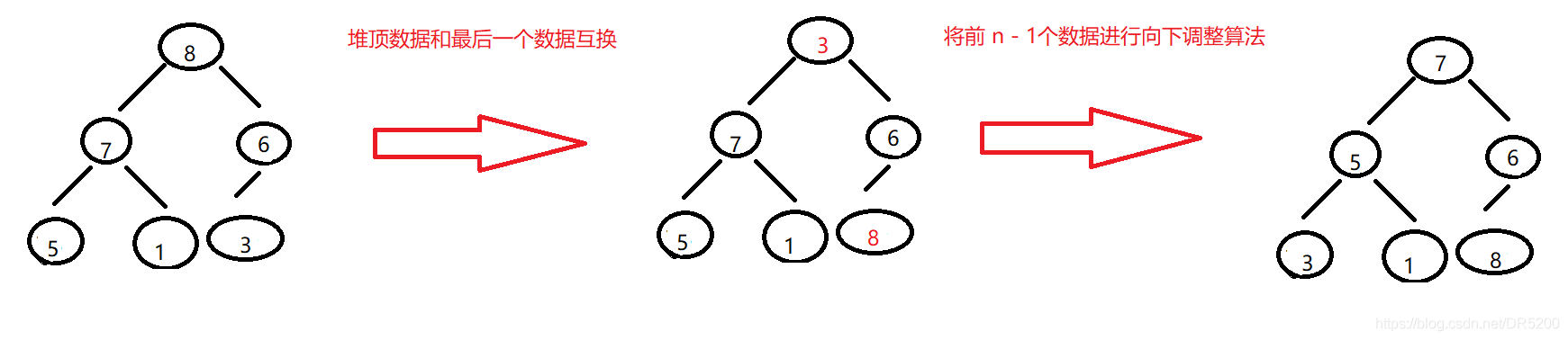 堆的洗掉實作
堆的洗掉實作
void HeapPop(Heap* hp)
{
assert(hp);
assert(hp->_size > 0);
Swap(&hp->_a[0],&hp->_a[hp->_size - 1]);
hp->size--;
AdjustDown(hp->_a,0,hp->size)
}
堆的銷毀
堆的銷毀實作
void HeapDestroy(Heap* hp)
{
assert(hp);
free(hp->_a);
free(hp);
}
取堆頂資料
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(hp->_size > 0);
return hp->_a[0];
}
堆的資料個數
int HeapSize(Heap* hp)
{
assert(hp);
return hp->_size;
}
堆的判空
bool HeapEmpty(Heap* hp)
{
assert(hp);
return hp->_size == 0;
}
完整代碼
鑒于篇幅原因,完整代碼放到gitee上,有需要的可以看一下
Heap
(3).堆排序
首先說明結論,排升序,建大堆,排降序,建小堆
可能有讀者會想排升序的話,建小堆選出最小的一個,再對剩下的元素建小堆不就好了嗎,這種方法雖然可行,但效率低下,每次都要重新建堆
排升序建大堆,每次選出最大的資料之后,和堆的最后一個資料交換,再對前 n - 1個資料進行向下調整演算法即可
排降序建小堆,每次選出最小的資料之后,和堆的最后一個資料交換,再對前 n - 1個資料進行向下調整演算法即可
// 排升序
void HeapSort(int* a,int n)
{
int i = (n - 2) / 2;
for(i = (n - 2) / 2;i >= 0;i--)
{
AdjustDown(a,i,n);
}
// 大堆已經建好
int end = n - 1;
while(end > 0)
{
Swap(&a[0],&a[end]);
AdjustDown(a,0,end);
end--;
}
}
四.二叉樹的鏈式結構及實作
(1).二叉樹鏈式結構
typedef int BTDataType;
typedef struct BinaryTreeNode
{
struct BinTreeNode* left; // 指向當前節點左孩子
struct BinTreeNode* right; // 指向當前節點右孩子
BTDataType data; // 當前節點值域
}BTNode;
(2).二叉樹的前中后序遍歷
前序遍歷的遍歷順序 : 根----左子樹-----右子樹
中序遍歷的遍歷順序 : 左子樹----根-----右子樹
后序遍歷的遍歷順序 : 左子樹----右子樹-----根
前序遍歷的遞回示意圖如下圖所示,中序和后序的結果類似,讀者可以自己去畫一下
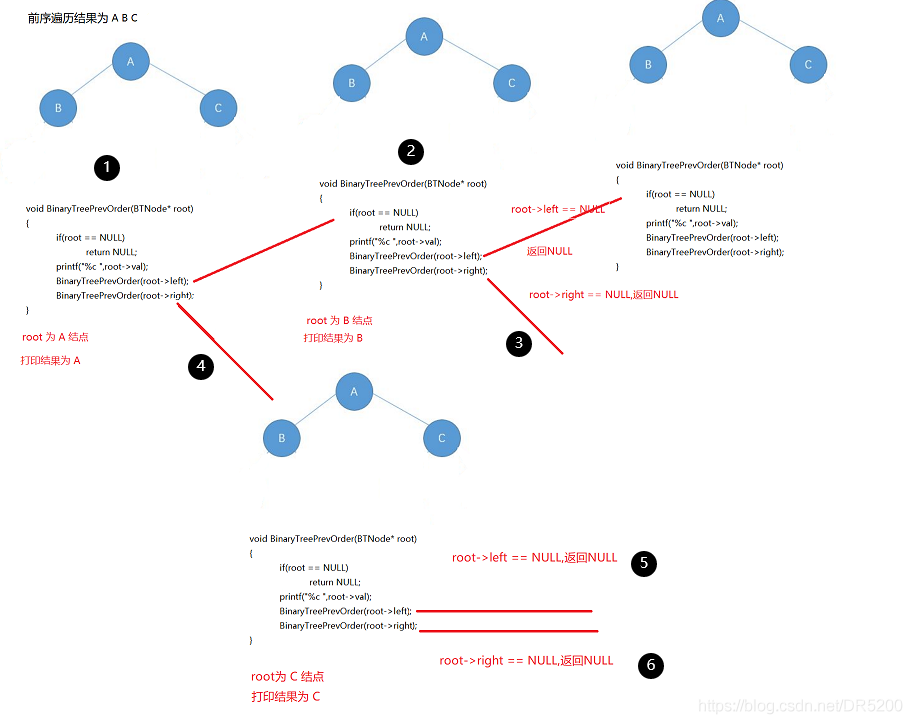
// 前序遍歷
void BinaryTreePrevOrder(BTNode* root)
{
if(root == NULL)
return;
printf("%c ",root->val);
BinaryTreePrevOrder(root->left);
BinaryTreePrevOrder(root->right);
}
// 中序遍歷
void BinaryTreePrevOrder(BTNode* root)
{
if(root == NULL)
return;
BinaryTreePrevOrder(root->left);
printf("%c ",root->val);
BinaryTreePrevOrder(root->right);
}
// 后序遍歷
void BinaryTreePrevOrder(BTNode* root)
{
if(root == NULL)
return;
BinaryTreePrevOrder(root->left);
BinaryTreePrevOrder(root->right);
printf("%c ",root->val);
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282840.html
標籤:AI