磁區(partition)
kafka中的topic可以細分為不同的partition,一個topic可以將訊息存放在不同的partition中,
leader和follower
每個partition可以設定一個leader和多個follower,kafka的訊息沒有設定讀寫分離,每個訊息發送時,都是發送至對應的partition的leader-paertion,follower-partition主要是為了備份資料而存在,當leader-partition出現故障時,資料已經完全同步的follower-partition也會切換成leader-partition,
AR和ISR
AR:磁區中所有的副本統稱為AR,
ISR:所有與leader節點保持同步的副本(包括leader節點)組成的節點,生產者首先將訊息發送給leader副本,然后follower從leader中同步訊息,
ISR是AR的子集,
資料的存盤
在partition中,一個topic中的資料存放在不同的partition中,一個磁區的內容會存盤成一個log檔案,為了防止log過大,引入了日志分段,根據一定規則將log切分為多個logSegment,相當于一個巨型檔案被切分成了很多不同的檔案,log和logSegment關系如下:
Log在物理上只以檔案夾的形式存盤,日志檔案在磁盤的存盤如下:
主題的磁區數設定
在server.properties組態檔中可以指定一個全域的磁區數設定,這是對每個主題下的磁區數的默認設定,默認是1,

當然每個主題也可以自己設定磁區數量,如果創建主題的時候沒有指定磁區數量,則會使用server.properties中的設定,
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic --partitions 2 --replication-factor 1在創建主題的時候,可以使用--partitions選項指定主題的磁區數量
[root@localhost kafka_2.11-2.0.0]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic abc
Topic:abc PartitionCount:2 ReplicationFactor:1 Configs:
Topic: abc Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: abc Partition: 1 Leader: 0 Replicas: 0 Isr: 0磁區多的優點
kafka使用磁區將topic的訊息打散到多個磁區,分別保存在不同的broker上,實作了producer和consumer訊息處理的高吞吐量,
Kafka的producer和consumer都可以多執行緒地并行操作,而每個執行緒處理的是一個磁區的資料,因此磁區實際上是調優Kafka并行度的最小單元,對于producer而言,它實際上是用多個執行緒并發地向不同磁區所在的broker發起Socket連接同時給這些磁區發送訊息;而consumer,同一個消費組內的所有consumer執行緒都被指定topic的某一個磁區進行消費,
所以說,如果一個topic磁區越多,理論上整個集群所能達到的吞吐量就越大,
磁區不是越多越好
磁區是否越多越好呢?顯然也不是,因為每個磁區都有自己的開銷:
一、客戶端/服務器端需要使用的記憶體就越多
客戶端producer有個引數batch.size,默認是16KB,它會為每個磁區快取訊息,一旦滿了就打包將訊息批量發出,
磁區越多,consumer端獲取資料所需的記憶體越多,同時consumer執行緒數要匹配磁區數(大部分情況下是最佳的消費吞吐量配置)的話,那么這里面的執行緒切換的開銷本身已經不容小覷了,服務器端的很多組件都在記憶體中維護了磁區級別的快取,比如controller,FetcherManager等,因此磁區數越多,這種快取的成本就越大,
二、檔案句柄的開銷
每個磁區在底層檔案系統都有屬于自己的一個目錄,該目錄下通常會有兩個檔案: base_offset.log和base_offset.index,Kafak的controller和ReplicaManager會為每個broker都保存這兩個檔案句柄(file handler),很明顯,如果磁區數越多,所需要保持打開狀態的檔案句柄數也就越多,最終可能會突破你的ulimit -n的限制,
三、降低高可用性
Kafka通過副本(replica)機制來保證高可用,具體做法就是為每個磁區保存若干個副本(replica_factor指定副本數),每個副本保存在不同的broker上,
如果你有10000個磁區,10個broker,也就是說平均每個broker上有1000個磁區,此時這個broker掛掉了,那么zookeeper和controller需要立即對這1000個磁區進行leader選舉,比起很少的磁區leader選舉而言,這必然要花更長的時間,并且通常不是線性累加的,如果這個broker還同時是controller情況就更糟了,
如何確定磁區數量呢
可以遵循一定的步驟來嘗試確定磁區數:創建一個只有1個磁區的topic,然后測驗這個topic的producer吞吐量和consumer吞吐量,假設它們的值分別是Tp和Tc,單位可以是MB/s,然后假設總的目標吞吐量是Tt,那么磁區數 = Tt / max(Tp, Tc)
說明:Tp表示producer的吞吐量,測驗producer通常是很容易的,因為它的邏輯非常簡單,就是直接發送訊息到Kafka就好了,Tc表示consumer的吞吐量,測驗Tc通常與應用的關系更大, 因為Tc的值取決于你拿到訊息之后執行什么操作,因此Tc的測驗通常也要麻煩一些,
kafka磁區和消費者執行緒的關系
1、要使生產者磁區中的資料合理消費,消費者的執行緒物件和磁區數保持一致,多余的執行緒不會進行消費(會浪費)
2、消費者默認即為一個執行緒物件 ;
3、達到合理消費最好滿足公司:消費者服務器數*執行緒數 = partition個數
生產者與磁區(多對多)
默認的磁區策略是:
- 如果在發訊息的時候指定了磁區,則訊息投遞到指定的磁區
- 如果沒有指定磁區,但是訊息的key不為空,則基于key的哈希值來選擇一個磁區
- 如果既沒有指定磁區,且訊息的key也是空,則用輪詢的方式選擇一個磁區
磁區與消費者(多對一)
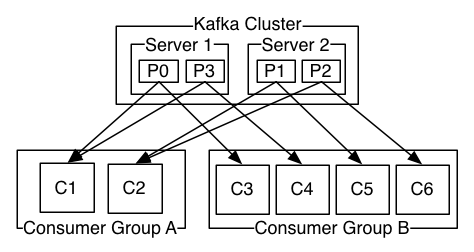
同一時刻,一條訊息只能被組中的一個消費者實體消費,
消費者組訂閱一個主題,意味著主題下的所有磁區都會被組中的消費者消費到,并且主題下的每個磁區只從屬于組中的一個消費者,不可能出現組中的兩個消費者負責同一個磁區,
如果磁區數大于或者等于組中的消費者實體數,那么一個消費者會負責多個磁區;如果消費者實體的數量大于磁區數,有一些消費者是多余的,一直接不到訊息而處于空閑狀態,
即:
- 若consumer數量大于partition數量,會造成限制的consumer,產生浪費,
- 若consumer數量小于partition數量,會導致均衡失效,其中的某個或某些consumer會消費更多的任務,
為什么一個消費者可以消費多個磁區,但是一個磁區不能被多個消費者消費呢?
就是要保證一個磁區下的訊息順序性,倘若,兩個消費者負責同一個磁區,那么就意味著兩個消費者同時讀取磁區的訊息,由于消費者自己可以控制讀取訊息的offset,就有可能C1才讀到2,而C1讀到1,C1還沒處理完,C2已經讀到3了,則會造成很多浪費,因為這就相當于多執行緒讀取同一個訊息,會造成訊息處理的重復,且不能保證訊息的順序,這就跟主動推送(push)無異,
所以說訊息積壓的時候,部署多臺消費者實體是不能加快消費原有磁區的訊息的,最多增加到和partition數量一致,超過的組員只會占用資源,而不起作用,
kafka官方檔案:https://kafka.apache.org/documentation.html#introduction
通過在主題中具有并行性--磁區--的概念,Kafka能夠為用戶行程池提供排序保證和負載平衡,這是通過將主題中的磁區分配給使用者組中的使用者來實作的,這樣每個磁區就會被組中的一個消費者使用,通過這樣做,我們確保使用者是該磁區的唯一讀者,并按順序使用資料,由于有許多磁區,這仍然平衡了許多使用者實體的負載,但是,請注意,不能有比磁區更多的使用者實體,
消費者(consumer)
分組(group)
消費者從partition中消費資料,consumer有group的概念,每個group可以消費完整的一份topic中的資料,
消費者磁區分配策略
range策略
是默認的分配策略,是基于每個主題的,
1、range分配策略針對的是主題(這里所說的磁區指的某個主題的磁區,消費者值的是訂閱這個主題的消費者組中的消費者實體)
2、首先,將磁區按數字順序排行序,消費者按消費者名稱的字典序排好序
3、然后,用磁區總數除以消費者總數,如果能夠除盡平均分配;若除不盡,則位于排序前面的消費者將多負責一個磁區
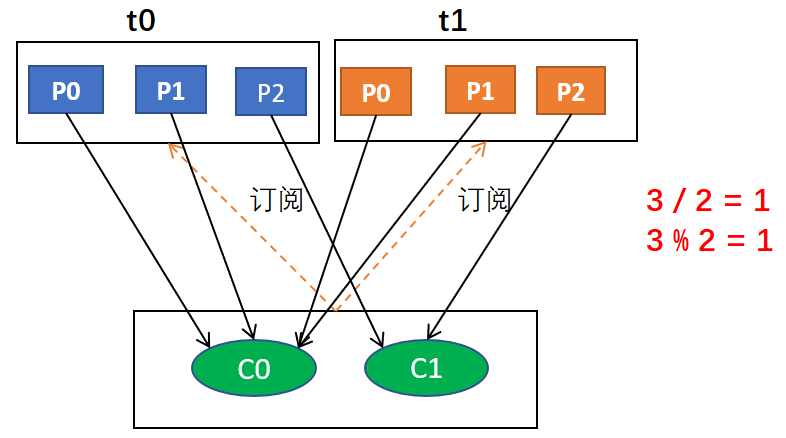
假設有3個主題(T1,T2,T3),都有7個磁區,那么按照咱們上面這種Range分配策略分配后的消費結果如下:
| 消費者執行緒 | 對應消費的磁區序號 |
|---|---|
| C0-0 | T1(0,1,2),T2(0,1,2),T3(0,1,2) |
| C1-0 | T1(3,4),T2(3,4),T3(3,4) |
| C1-1 | T1(5,6),T2(5,6),T3(5,6) |
roundrobin(輪詢)
RoundRobin策略的原理是將消費組內所有消費者以及消費者所訂閱的所有topic的partition按照字典序排序,然后通過輪詢演算法逐個將磁區以此分配給每個消費者,
使用RoundRobin分配策略時會出現兩種情況:
- 如果同一消費組內,所有的消費者訂閱的訊息都是相同的,那么 RoundRobin 策略的磁區分配會是均勻的,
- 如果同一消費者組內,所訂閱的訊息是不相同的,那么在執行磁區分配的時候,就不是完全的輪詢分配,有可能會導致磁區分配的不均勻,如果某個消費者沒有訂閱消費組內的某個 topic,那么在分配磁區的時候,此消費者將不會分配到這個 topic 的任何磁區,
因此在使用RoundRobin分配策略時,為了保證得均勻的磁區分配結果,需要滿足兩個條件:
- 同一個消費者組里的每個消費者訂閱的主題必須相同;
- 同一個消費者組里面的所有消費者的num.streams必須相等,
我們分別舉例說明:
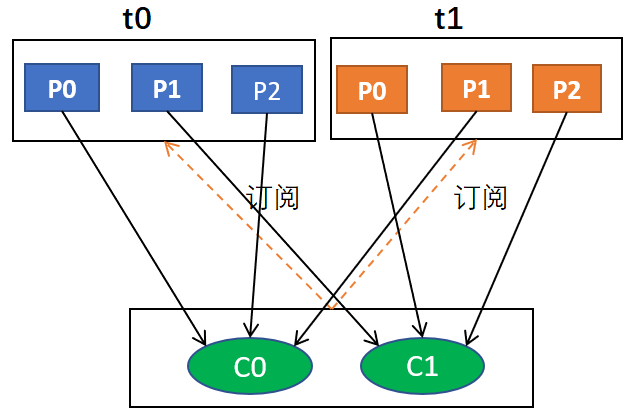
第一種:比如我們有3個消費者(C0,C1,C2),都訂閱了2個主題(T0 和 T1)并且每個主題都有 3 個磁區(p0、p1、p2),那么所訂閱的所有磁區可以標識為T0p0、T0p1、T0p2、T1p0、T1p1、T1p2,此時使用RoundRobin分配策略后,得到的磁區分配結果如下:
| 消費者執行緒 | 對應消費的磁區序號 |
|---|---|
| C0 | T0p0、T1p0 |
| C1 | T0p1、T1p1 |
| C2 | T0p2、T1p2 |
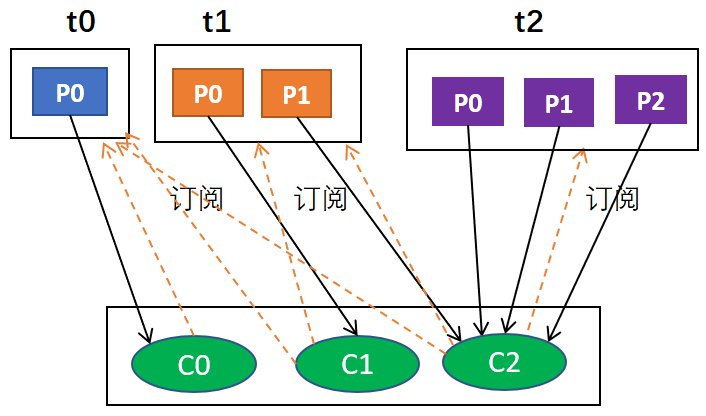
第二種:比如我們依然有3個消費者(C0,C1,C2),他們合在一起訂閱了 3 個主題:T0、T1 和 T2(C0訂閱的是主題T0,消費者C1訂閱的是主題T0和T1,消費者C2訂閱的是主題T0、T1和T2),這 3 個主題分別有 1、2、3 個磁區(即:T0有1個磁區(p0),T1有2個磁區(p0、p1),T2有3個磁區(p0、p1、p2)),即整個消費者所訂閱的所有磁區可以標識為 T0p0、T1p0、T1p1、T2p0、T2p1、T2p2,此時如果使用RoundRobin分配策略,得到的磁區分配結果如下:
| 消費者執行緒 | 對應消費的磁區序號 |
|---|---|
| C0 | T0p0 |
| C1 | T1p0 |
| C2 | T1p1、T2p0、T2p1、T2p2 |
Sticky分配策略
在kafka的0.11.X版本才開始引入的,是目前最復雜也是最優秀的分配策略,
S它的設計主要實作了兩個目的,如果這兩個目的發生了沖突,優先實作第一個目的:
- 磁區的分配要盡可能的均勻;
- 磁區的分配盡可能的與上次分配的保持相同,
我們有3個消費者(C0,C1,C2),都訂閱了2個主題(T0 和 T1)并且每個主題都有 3 個磁區(p0、p1、p2),那么所訂閱的所有磁區可以標識為T0p0、T0p1、T0p2、T1p0、T1p1、T1p2,此時使用Sticky分配策略后,得到的磁區分配結果如下:
| 消費者執行緒 | 對應消費的磁區序號 |
|---|---|
| C0 | T0p0、T1p0 |
| C1 | T0p1、T1p1 |
| C2 | T0p2、T1p2 |
看起來和前面RoundRobin分配策略一樣,但其實底層實作并不一樣,
這里假設C2故障退出了消費者組,然后需要對磁區進行再平衡操作,
如果使用的是RoundRobin分配策略,它會按照消費者C0和C1進行重新輪詢分配,再平衡后的結果如下:
| 消費者執行緒 | 對應消費的磁區序號 |
|---|---|
| C0 | T0p0、T0p2、T1p1 |
| C1 | T0p1、T1p0、T1p2 |
但是如果使用的是Sticky分配策略,再平衡后的結果會是這樣:
| 消費者執行緒 | 對應消費的磁區序號 |
|---|---|
| C0 | T0p0、T1p0、T0p2 |
| C1 | T0p1、T1p1、T1p2 |
Stiky分配策略保留了再平衡之前的消費分配結果,并將原來消費者C2的分配結果分配給了剩余的兩個消費者C0和C1,最終C0和C1的分配還保持了均衡,這時候再體會一下sticky(翻譯為:粘粘的)這個詞匯的意思,是不是豁然開朗了,
對于同一個磁區而言有可能之前的消費者和新指派的消費者不是同一個,對于之前消費者進行到一半的處理還要在新指派的消費者中再次處理一遍,這時就會浪費系統資源,而使用Sticky策略就可以讓分配策略具備一定的“粘性”,盡可能地讓前后兩次分配相同,進而可以減少系統資源的損耗以及其它例外情況的發生,
磁區Rebalance(再均衡)場景
- 有新的消費者加入消費者群組
- 已有的消費者退出消費者群組
- 訂閱的主題的磁區發生變化
Rebalance給消費者群組帶來了高可用性與伸縮性,但是在Rebalance期間,消費者無法讀取訊息,整個群組一小段時間不可用,而且當磁區被重新分配給另一個消費者時,消費者當前的讀取狀態會丟失,
消費者組(廣播模式)
如果想實作廣播的模式就需要設定多個消費者組,這樣當一個消費者組消費完這個訊息后,絲毫不影響其他組內的消費者進行消費,這就是廣播的概念,
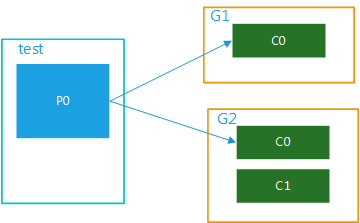
(1)多個消費者組,1個partition
該topic內的資料被多個消費者組同時消費,當某個消費者組有多個消費者時也只能被一個消費者消費,如圖4所示:
(2)多個消費者組,多個partition
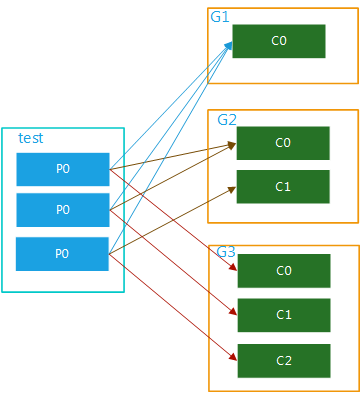
該topic內的資料可被多個消費者組多次消費,在一個消費者組內,每個消費者又可對應該topic內的一個或者多個partition并行消費,如圖5所示:
參考:
Kafka磁區與消費者的關系:https://www.cnblogs.com/cjsblog/p/9664536.html
Kafka磁區數與消費者個數:https://www.jianshu.com/p/dbbca800f607,https://blog.csdn.net/OiteBody/article/details/80595971
kafka磁區和消費者執行緒的關系:https://blog.csdn.net/tankun940507994/article/details/72781996
深入分析Kafka架構(三):消費者消費方式、三種磁區分配策略、offset維護:https://blog.csdn.net/qq_26803795/article/details/105562691
kafka中partition數量與消費者對應關系以及Java實踐:https://www.tqwba.com/x_d/jishu/279556.html
為什么不能有比磁區更多的使用者實體?:https://stackoverflow.com/questions/25896109/in-apache-kafka-why-cant-there-be-more-consumer-instances-than-partitions
kafka多個消費者消費一個topic_詳細決議kafka之 kafka消費者組與重平衡機制:https://blog.csdn.net/weixin_39737224/article/details/112073632
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282885.html
標籤:其他
上一篇:搭建第一個Dapp應用(2)——搭建WeBase-Front中間件——2021.5.3
下一篇:docker 安裝 lnmp環境