🍦前幾天的課程我們學習了Hive資料的匯入、匯出、查詢和排序,有興趣的小伙伴可以查看以往的文章👇:
- 第一篇: Hadoop之Hive資料的匯入與匯出(DML).
- 第二篇: Hadoop之Hive查詢陳述句.
- 第三篇:Hadoop之Hive的7種Join陳述句.
- 第四篇: Hadoop之Hive的排序.
?????? 今天要介紹的內容在Hive中非常重要,即磁區表
磁區表
- 1.磁區表
- 1.1 磁區表的建立
- 1.2 查詢磁區表中資料
- 1.3 增加磁區
- 1.4 洗掉磁區
- 1.5 查看磁區
- 1.6 查看磁區表結構
- 2. 二級磁區
- 2.1 建立二級磁區磁區
- 2.2 查詢二級磁區
- 3. HDFS資料與磁區表關聯的方法
- 3.1 修復磁區
- 3.2 添加磁區
- 3.3 創建檔案夾后load資料
- 4. 動態磁區
- 參考資料
1.磁區表
磁區表實際上就是對應一個 HDFS 檔案系統上的獨立的檔案夾,該檔案夾下是該磁區所有的資料檔案,Hive 中的磁區就是分目錄,把一個大的資料集根據業務需要分割成小的資料集,在查詢時通過 WHERE 子句中的運算式選擇查詢所需要的指定的磁區,這樣的查詢效率會提高很多,
1.1 磁區表的建立
- 引入磁區表(一般情況下,企業中的磁區表都是以時間作為磁區的)
我們首先建立三個磁區表內所需要的檔案
--dept1.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
--dept2.txt
30 SALES 1900
40 OPERATIONS 1700
--dept3.txt
50 TEST 2000
60 DEV 1900
創建成功
- 創建磁區表
create table dept_par(deptno int, dname string, loc string)
partitioned by (day string)--磁區表特有
row format delimited fields terminated by '\t';

- 各磁區表匯入資料
--第一天添加
load data local inpath '/opt/modul/datatest/dept1.txt'
into table dept_par
partition(day="2021-05-01");--指定磁區目錄
--第二天添加
load data local inpath '/opt/modul/datatest/dept2.txt'
into table dept_par
partition(day="2021-05-02");
--第三天添加
load data local inpath '/opt/modul/datatest/dept3.txt'
into table dept_par
partition(day="2021-05-03");
都按這種方式匯入

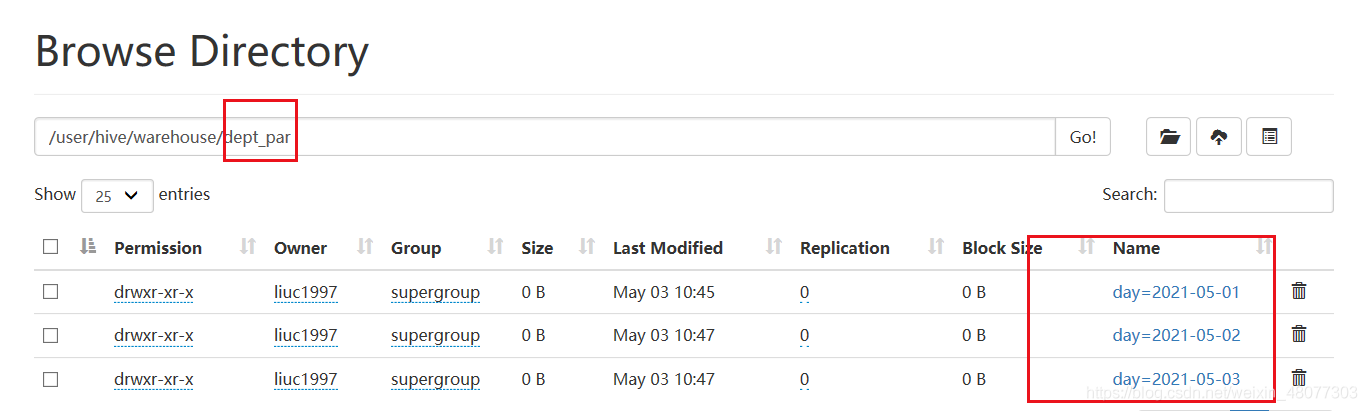
我們在web服務上看一下資料:我們發現磁區表可以理解為在資料表中創建了檔案夾來管理資料,
磁區資訊也是資料的一個欄位,用法和普通屬性用法一樣,
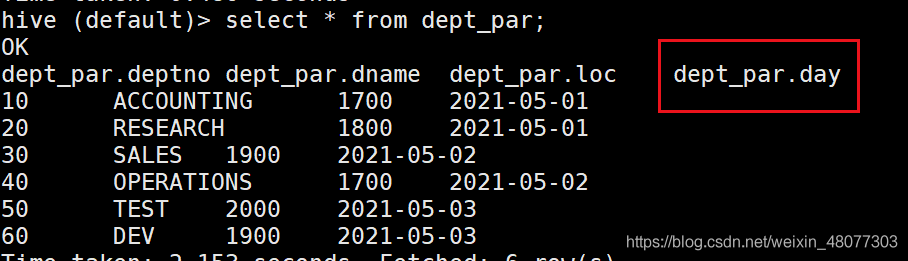
例如查詢某天的資料
select * from dept_par where day="2021-05-01";
查詢磁區資訊超級快!因為磁區表就相當于目錄,可以避免全表掃描,

1.2 查詢磁區表中資料
剛才其實演示過了,磁區查詢就相當于屬性就行
--單磁區查詢
select * from dept_par where day="2021-05-01";
--多個磁區查詢
select * from dept_par where day="2021-05-01"
union
select * from dept_par where day="2021-05-02"
union
select * from dept_par where day="2021-05-03"
--多表磁區的另一種寫法
select * from dept_par where day="2021-05-01" or day="2021-05-02" or day="2021-05-03";
結果如下:

1.3 增加磁區
也是使用alter…add…陳述句,需要添加多個磁區時需要用空格隔開,
--添加一個磁區
alter table dept_par add partition(day='2021-05-04');
--添加多個磁區
alter table dept_par add partition(day='2021-05-04') partition(day='2021-05-05');
添加磁區成功,但是里面沒有資料,
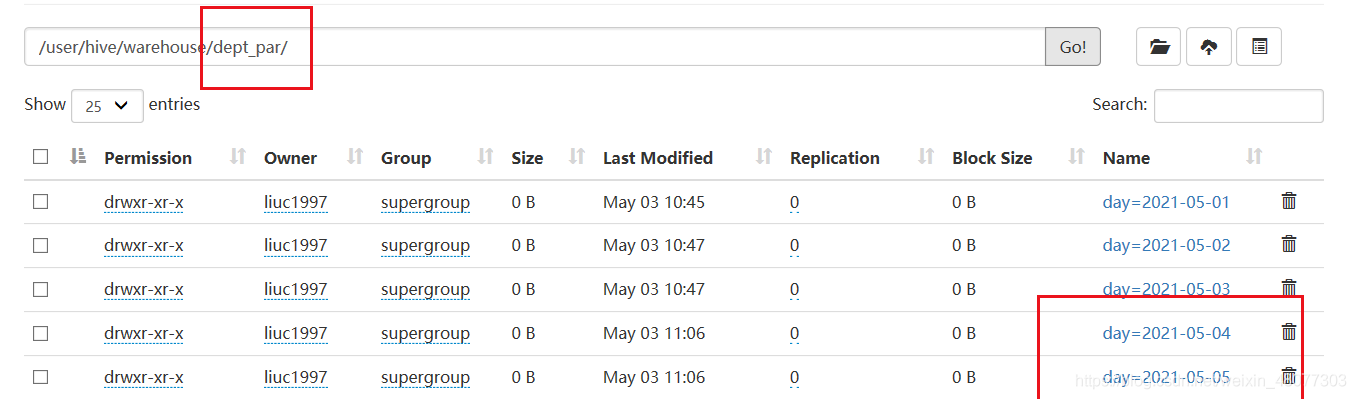
1.4 洗掉磁區
洗掉磁區用alter…drop…陳述句,洗掉多個磁區時需要用逗號隔開(吐槽它😟)
--洗掉一個
alter tabel dept_par drop partition(day='2021-05-04');
--洗掉多個磁區
alter table dept_par drop partition(day='2021-05-04'),partition(day='2021-05-05');
洗掉成功,
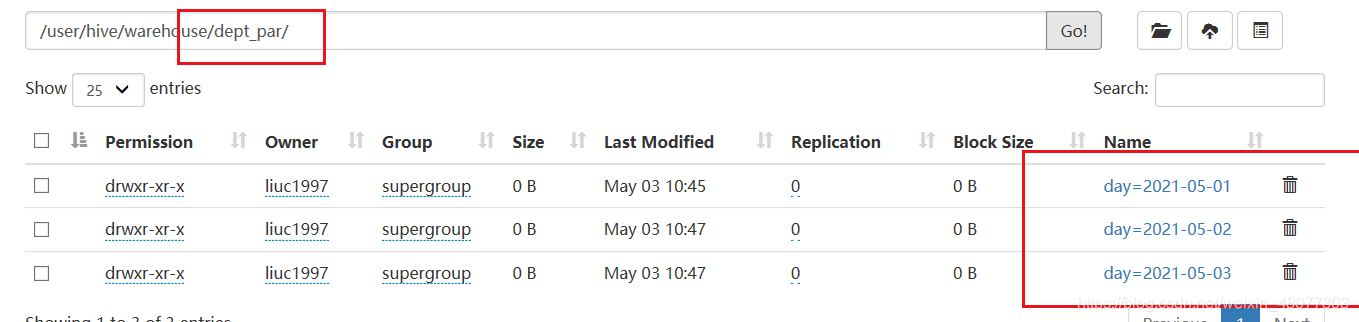
1.5 查看磁區
show partitions dept_par;
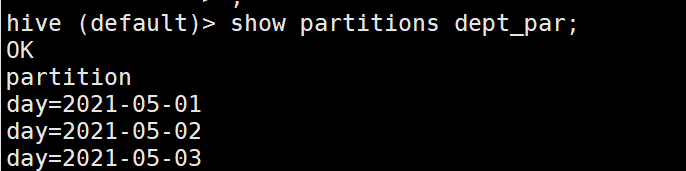
1.6 查看磁區表結構
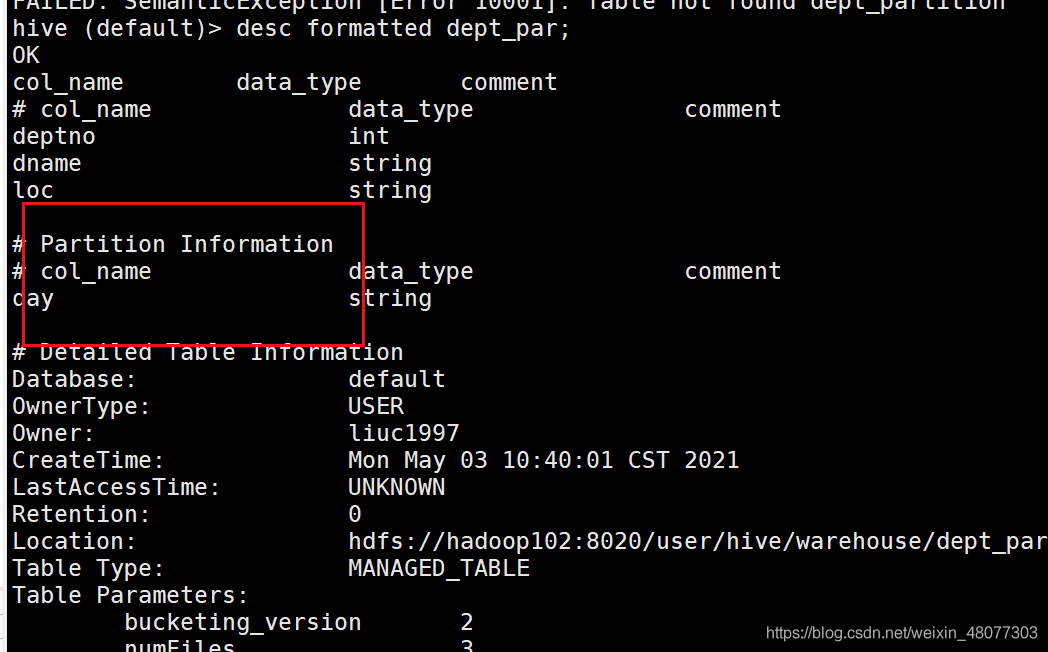
desc formatted dept_partition;
2. 二級磁區
上一章節講述了我們將天為單位進行磁區,可如果按天磁區資料量依然很大,我們這時就需要按照更小的范圍磁區,比如小時,
2.1 建立二級磁區磁區
--創建二級磁區表
create table dept_par2(deptno int, dname string, loc string)
partitioned by (day string,hour string)
row format delimited fields terminated by '\t';
- 匯入資料
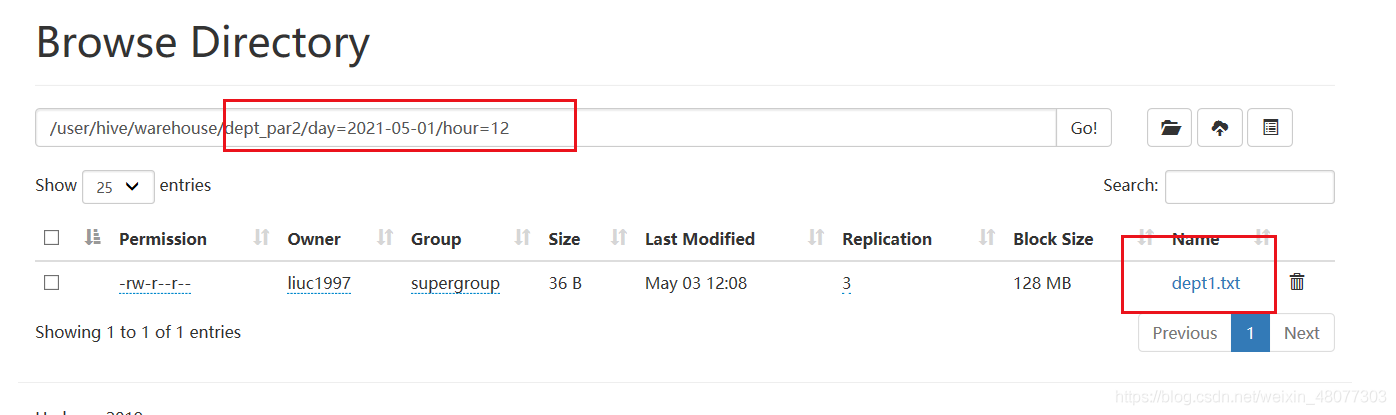
load data local inpath '/opt/modul/datatest/dept3.txt'
into table dept_par2
partition(day="2021-05-02",hour='12');--指定二級磁區資訊
創建成功
2.2 查詢二級磁區
這里查詢也是將磁區資訊當成屬性即可
--查詢所有資訊
select * from dept_par2;
--查詢某天的資訊
select * from dept_par2 where day='2021-05-01';
--查詢某天某時的資訊
select * from dept_par2 where day='2021-05-01' and hour='12';
結果:

3. HDFS資料與磁區表關聯的方法
在最開始的普通資料庫建表陳述句中我們說過,資料是存在HDFS上面的,也就是說,如果通過hdfs命令直接在檔案夾先存資料,后建表,都是可以查詢到的,但是磁區表也是這樣的嗎?
我們試一試:我們在磁區表中建立一個day="2021-05-04"的目錄,里面給他資料dept1.txt
#創建一個類似磁區表的檔案夾
hadoop fs -mkdir /user/hive/warehouse/dept_par/day=2021-05-04
#給他資料
hadoop fs -put dept1.txt /user/hive/warehouse/dept_par/day=2021-05-04
結果如下:
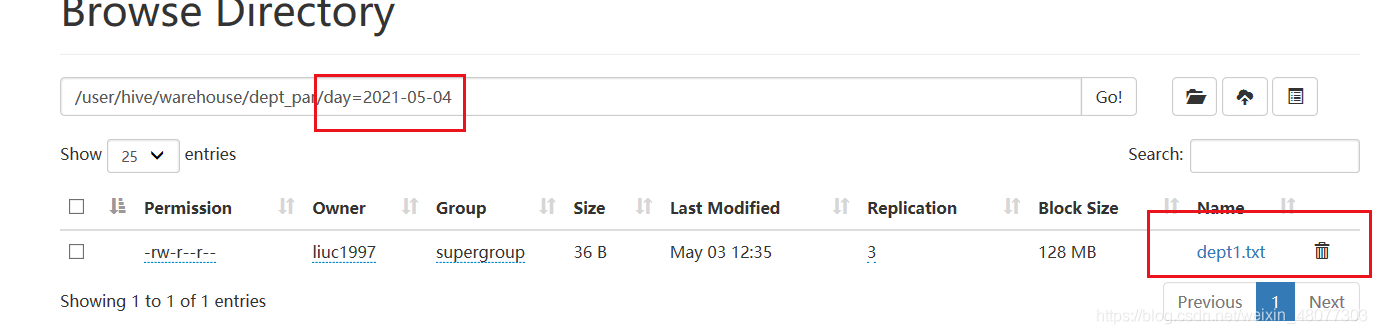
然后我們用陳述句查詢一下:發現找不2021-05-04的資料!!!
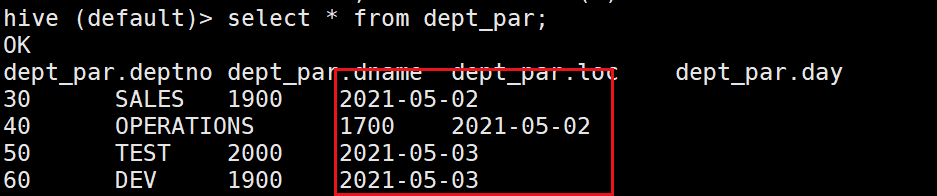
說明元資料中對磁區表也有資料的存盤,我們應該怎么樣才能將我們自建的目錄統一到元資料中呢?
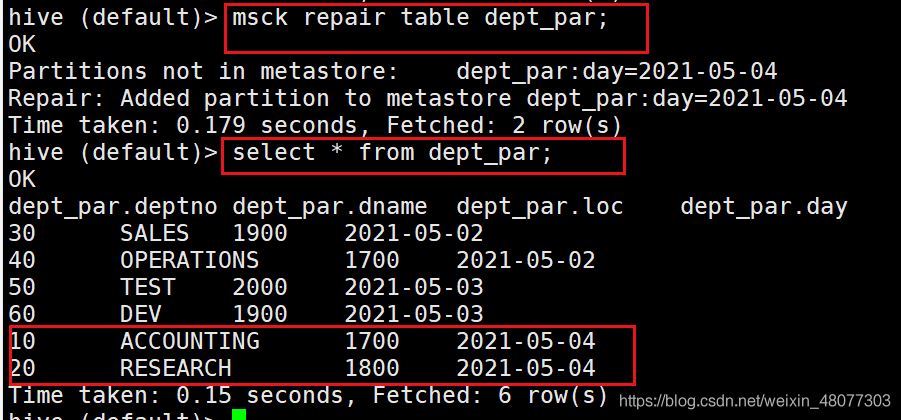
3.1 修復磁區
- 通過修復磁區
--修復磁區命令,該命令會匹配磁區資料表,補充元資料,
msck repair table dept_par;
修復完成后,成功找到,
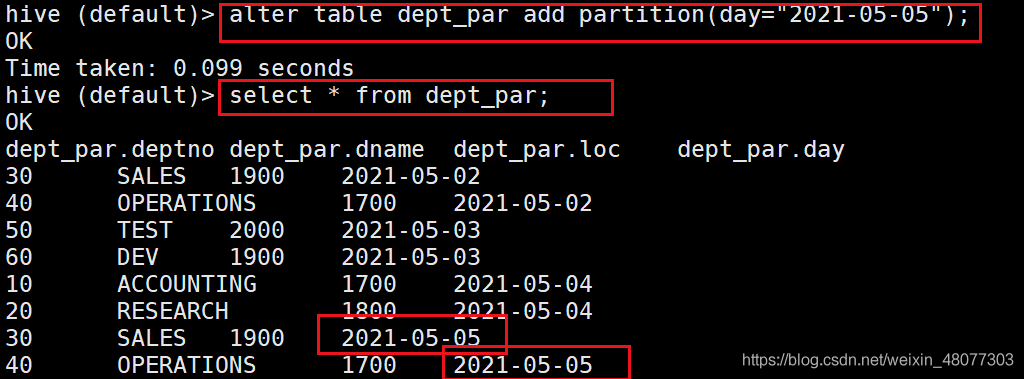
3.2 添加磁區
我們在hdfs上再創建目錄day=2021-05-05
#創建一個類似磁區表的檔案夾
hadoop fs -mkdir /user/hive/warehouse/dept_par/day=2021-05-05
#給他資料
hadoop fs -put dept2.txt /user/hive/warehouse/dept_par/day=2021-05-05
- 添加磁區
--添加對應磁區
alter table dept_par add partition(day="2021-05-05");
結果如下:
3.3 創建檔案夾后load資料
我們可以事先創建檔案夾后,然后再使用load資料
-- 創建檔案夾
hadoop fs -mkdir /user/hive/warehouse/dept_par/day=2021-05-06
- load資料
--資料只能load方式,才會添加元資料
load data local inpath
'/opt/modul/datatest/dept3.txt'
into table dept_par
partition(day="2021-05-06");
4. 動態磁區
動態磁區是指磁區標準不確定,想依據表中的某個欄位進行磁區,例如,根據dept表中的deptno進行磁區
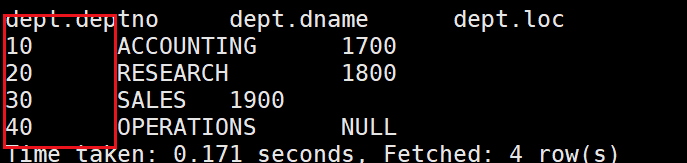
- 創建磁區表
--首先我們創建一個磁區表
create table dept_no_par(dname string, loc string)
partitioned by (deptno int)
row format delimited fields terminated by '\t';
- 傳遞資料
--動態磁區會默認將最后一個欄位名(deptno)作為磁區標準
insert into table dept_no_par
partition(deptno)
select dname,loc,deptno from dept;
--也可以這樣,這種不需要改嚴格模式
insert into table dept_no_par
select dname,loc,deptno from dept;
提示動態磁區要在非嚴格模式

- 設定非嚴格模式
set hive.exec.dynamic.partition.mode=nonstrict;
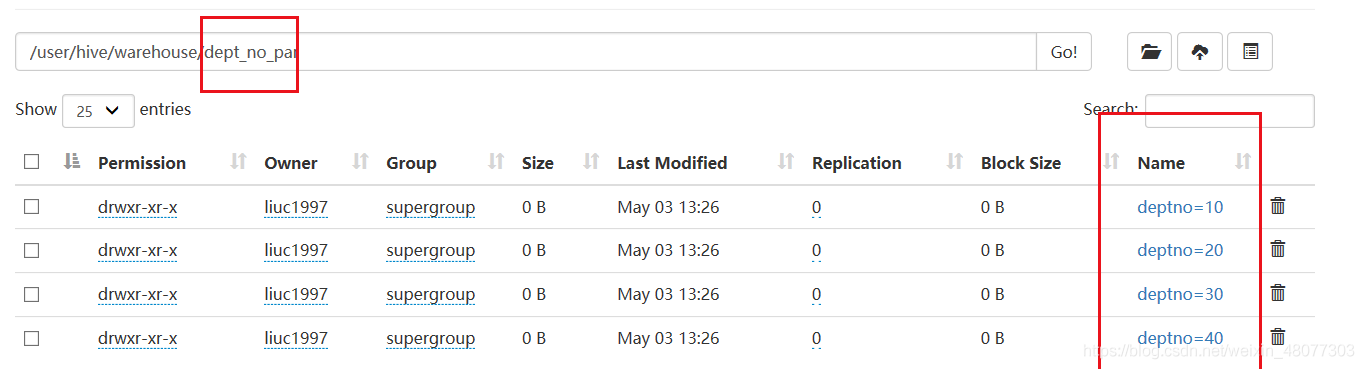
- 再此執行,結果如下:磁區成功,
參考資料
《大資料Hadoop3.X分布式處理實戰》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282889.html
標籤:其他
下一篇:一張圖搞懂華為介面型別!