文章目錄
- Hive基礎知識
- 一、Hive與HDFS的資料映射
- 二、Hive轉換與MapReduce程序
- 三、元資料:metastore的功能和存盤方式
- 四、元資料:metastore共享問題
- 五、元資料:metastore服務
- 六、Hive客戶端與服務端
- 七、啟動腳本與SQL腳本
- 八、常用命令與日志配置
- 九、HQL語法:DDL
- 十、HQL語法:DML
- 十一、HQL語法:DQL
- 十二、表的分類
Hive基礎知識
一、Hive與HDFS的資料映射
1.Hive物件與HDFS關系
資料庫:每個資料庫在HDFS中對應一個目錄
目錄的名字:庫名.db
表:每張表在資料庫中對應的目錄下建立一個與表同名的目錄
表的資料:映射的是HDFS上的檔案
2.元資料映射
所有Hive中資料庫、表與HDFS的映射關系存盤在元資料中,Hive服務端會讀取元資料找到這張表對應的HDFS資料
3.元資料映射程序
1.先檢索資料庫的資訊
2.再檢索表的資訊
3.通過表的SD_ID來獲取這張表映射的HDFS的地址
4.將整個表的目錄中的 所有資料進行讀取并回傳
二、Hive轉換與MapReduce程序
1.基本映射關系
| MapReduce | SQL |
|---|---|
| Input | from |
| Map | select,from |
| Shuffle | group by,order by |
| Reduce | having,limit |
| Output | 將SQL結果保存 |
2.執行決議
select region,count(*) as numb from tb_house where region != '浦東' group by region order by numb;
3.查看執行計劃
explain select region,count(*) as numb from tb_house where region != '浦東' group by region order by numb;
三、元資料:metastore的功能和存盤方式
1.metastore功能
Hive中的元資料記錄了Hive中所有物件資訊,包括資料庫資訊,表的資訊,欄位的資訊,重點記錄了Hive表和HDFS檔案的映射關系
每次創建表關聯檔案,Hive都會自動創建表的元資料
每次查詢表的資料,Hive都會從元資料中獲取表的對應的HDFS資訊
2.metastore的存盤方式
方式:
嵌入式資料庫:Local/Embedded Metastore Database(Derby)
存盤在derby
本地資料庫
存盤在MySQL中,可以直接訪問
遠程Metastore服務
存盤在MySQL中,但是通過一個行程來訪問
位置:
默認位置:Hive自帶的Derby資料庫
缺點:不能共享,不能啟動多個實體,一般不用
自定義位置:自定義將元資料存盤到其他資料庫中
型別:MySQl、Oracle、PostGrepSQL,作業中一般存盤到MySQL中
3.metastore的功能?
存盤Hive中所有物件的資訊:資料庫、表、列
存盤Hive中表與HDFS的映射關系
四、元資料:metastore共享問題
1.作業中的應用場景
作業中不使用Hive來實作資料倉庫中的分布式計算,
使用替代品:SparkSQL、Impala、Presto,因為他們計算更快,性能更好,語法都兼容Hive的語法
2.如果用SparkSQL來處理Hive資料倉庫中的表,SparkSQL怎么知道Hive中有哪些表?
讓SparkSQL讀取Hive元資料
3.如何SparkSQL獲取了Hive的元資料,SparkSQL怎么知道這個元資料的含義是什么?
決議元資料的含義
4.如果多個框架都需要訪問Hive的元資料,每個框架都封裝決議代碼,就非常冗余,如何解決這個問題?
通過metastore服務,實作元資料共享
五、元資料:metastore服務
1.metastore功能
實作元資料共享服務,專門負責管理Hive的元資料,接收所有需要訪問元資料的請求
2.metastore的配置
#編輯hive-site.xml檔案,添加以下內容
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
3.metastore的啟動
#1.先啟動metastore服務
hive --service metastore
#2.再啟動Hive的服務端和客戶端
hive
#3.查看metastore埠開放情況
netstat -atunlp | grep 9083
六、Hive客戶端與服務端
1.Hive Shell
功能:
Hive特殊的客戶端,啟動時會自動包含啟動服務端
命令:
hive
特點:
服務端客戶端一體,互動性不太友好
2.Beeline與hiveserver2
功能:
Beeline:純客戶端
hiveserver2:Hive中獨立的服務行程
命令:
beeline啟動Hive服務端:
#1.第一種方式
beeline -u jdbc地址 -n 用戶名 -p 密碼
#2.第二種方式
beeline
!connect jdbc地址
用戶名
密碼
hiveserver2啟動Hive服務端:
#1.第一種方式
hive --service hiveserver2
#2.第二種方式
hiveserver2
2.1啟動測驗1
#1.啟動metastore(9083埠)
hive --service metastore
#2.啟動Hive服務端(10000埠)
hiveserver2
#3.啟動客戶端,當前啟動會出現錯誤,需要做配置
beeline
!connect jdbc:hive2://node3:10000
root
123456
2.2配置
關閉hdfs和yarn
#1.關閉hdfs
stop-dfs.sh
#2.關閉yarn
stop-yarn.sh
編輯core.xml
#1.切換到指定目錄
cd /export/server/hadoop-2.7.5/etc/hadoop/
#2.編輯core-site.xml檔案
vim core-site.xml
#3.添加以下內容
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
分發core-site.xml檔案
#1.向node2分發
scp core-site.xml node2:$PWD
1.向node3分發
scp core-site.xml node3:$PWD
啟動hdfs和yarn
#1.啟動hdfs
start-dfs.sh
2.啟動yarn
start-dfs.sh
2.3復制standalone包
#1.切換到指定目錄
cd /export/server/hive-2.1.0-bin
#2.復制檔案
cp jdbc/hive-jdbc-2.1.0-standalone.jar lib/
2.4啟動測驗2
#1.啟動metastore,加&使其在后臺運行
hive --service metastore &
#2.啟動Hive服務端
hiveserver2
#3.啟動客戶端,方式1直接進入
beeline
!connect jdbc:hive2://node3:10000
root
123456
#4.啟動客戶端,方式2直接連接
beeline -u jdbc:hive2://node3:10000 -n root -p 123456
#5.退出
!q
特點:
互動性好,一般用于互動式查詢
3.JDBC
語法:
基本與MySQL的JDBC一致
#step1:指定驅動類
#step2:構建連接物件
#step3:構建SQL物件
#step4:執行SQL獲取結果
測驗:
package com.miao.hive.client.jdbc;
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
//宣告驅動
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
//構建連接
Connection con = DriverManager.getConnection("jdbc:hive2://node3:10000/default", "root", "123456");
//構建SQL物件
Statement stmt = con.createStatement();
String tableName = "tb_house";
String sql = "select region,t_price,s_price from " + tableName +" limit 100";
System.out.println("Running: " + sql);
//執行SQL陳述句
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getInt(2)+ "\t" + res.getInt(3));
}
}
}
應用:一般用于封裝互動式的程式:Navicat、DataGrip
4.關閉metastore和hiveserver2
#1.關閉metastore
kill -9 5014
#2.關閉hiveserver2
kill -9 5097
七、啟動腳本與SQL腳本
1.創建日志目錄
mkdir /export/server/hive-2.1.0-bin/logs
日志的四個級別:
DEBUG:詳細的日志級別
INFO:顯示的資訊會包含主要的日志資訊
WARN:只記錄警告級別的日志
ERROR:只記錄錯誤級別的日志
2.編輯Metastore啟動腳本
#1編輯metastore.sh檔案
vim /export/server/hive-2.1.0-bin/bin/start-metastore.sh
#2.添加以下內容
#!/bin/bash
#HIVE_HOME
HIVE_HOME=/export/server/hive-2.1.0-bin
#run metastore
$HIVE_HOME/bin/hive --service metastore >> $HIVE_HOME/logs/metastore.log 2>&1 &
3.編輯HiveServer2啟動腳本
#1.編輯hiveserver2.sh檔案
vim /export/server/hive-2.1.0-bin/bin/start-hiveserver2.sh
#2.添加以下內容
#!/bin/bash
#HIVE_HOME
HIVE_HOME=/export/server/hive-2.1.0-bin
#run hiveserver2
$HIVE_HOME/bin/hiveserver2 >> $HIVE_HOME/logs/hiveserver2.log 2>&1 &
4.編輯Beeline啟動腳本
#1.編輯beeline.sh檔案
vim /export/server/hive-2.1.0-bin/bin/start-beeline.sh
#2.添加以下內容
#!/bin/bash
#HIVE_HOME
HIVE_HOME=/export/server/hive-2.1.0-bin
#run beeline
$HIVE_HOME/bin/beeline -u jdbc:hive2://node3:10000 -n root -p 123456
5.修改權限
chmod u+x /export/server/hive-2.1.0-bin/bin/start-*
6.HiveSQL腳本的封裝
需求:每天00:01分自動對昨天的資料做分析
select count(*) from table where daystr = '2021-05-01';
問題1:每天的0點01分自動執行,怎么實作?
Linux Crontab:定時任務
* * * * * Linux command
實作
01 00 * * * hive -e 'select count(*) from table where daystr = '2021-05-01';'
問題2:怎么讓Hive的SQL陳述句在Linux的命令列執行?
解決:利用Hive Shell的客戶端來實作,查看客戶端的用法
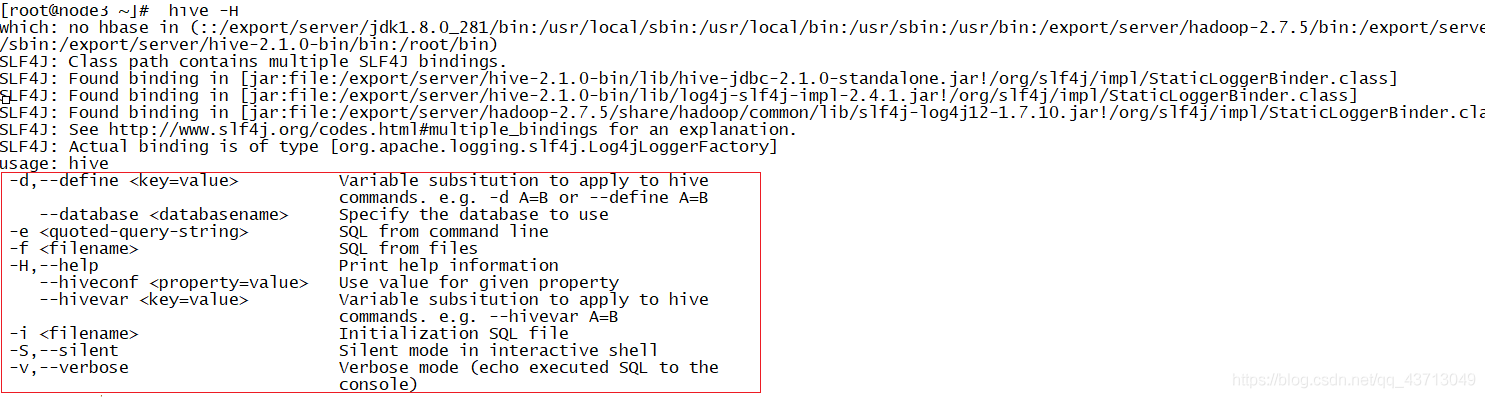
-e:執行命令列中的SQL陳述句
hive -e 'select count(*) from table where daystr = '2021-05-01;'
直接執行命令列中提供的SQL陳述句
應用:要執行比較少的單條SQL陳述句
-f:執行一個SQL檔案
#1.創建一個sql檔案
vim /export/data/hive.sql
#2.編輯sql陳述句
show databases;
use default;
select region,s_price,area from tb_house limit 10;
執行SQL檔案
hive -f /export/data/hive.sql
定時任務:
01 00 * * * bash /export/data/exec.sh
exec.sh
#!/bin/bash
#1.定義變數
HIVE_HOME=/export/server/hive-2.1.0-bin
#2.運行SQL陳述句
#$HIVE_HOME/bin/hive -e 'show databases;'
$HIVE_HOME/bin/hive -f /export/data/hive.sql
7.SQL腳本中傳遞變數
問題:如果運行的SQL檔案,SQL檔案中的SQL陳述句中的引數是動態變化的,如何解決?
解決:通過–hiveconf,將Shell腳本中變數轉換為一個Hive中的變數
–hiveconf:用于定義Hive中屬性的值或者定義Hive中的變數
shell腳本
#!/bin/bash
#1.獲取昨天的日期
yesterday=`date -d '-1 day' +%Y%m%d`
#2.定義變數
HIVE_HOME=/export/server/hive-2.1.0-bin
#3.運行SQL陳述句
#$HIVE_HOME/bin/hive -e 'select count(*) from table where daystr = '${yesterday}';'
$HIVE_HOME/bin/hive --hiveconf yester=${yesterday} -f /export/data/hive.sql
hive.sql檔案
select count(*) from table where daystr = '${hiveconf:yester}';
八、常用命令與日志配置
1.常用命令
dfs:用于直接在Hive執行HDFS的操作
set:查看或者臨時修改【只在當前的會話視窗有效】
add:添加jar包或者檔案到Hive的環境變數中
add jar xxx.jar;
add file xxx
list:列舉添加的檔案或者jar包
list files
list jars
delete:洗掉添加的檔案或者jar包
2.日志存盤配置
重命名日志組態檔
#1.切換到指定目錄
cd /export/server/hive-2.1.0-bin/conf/
#2.重命名log4j2.properties檔案
mv hive-log4j2.properties.template hive-log4j2.properties
修改配置
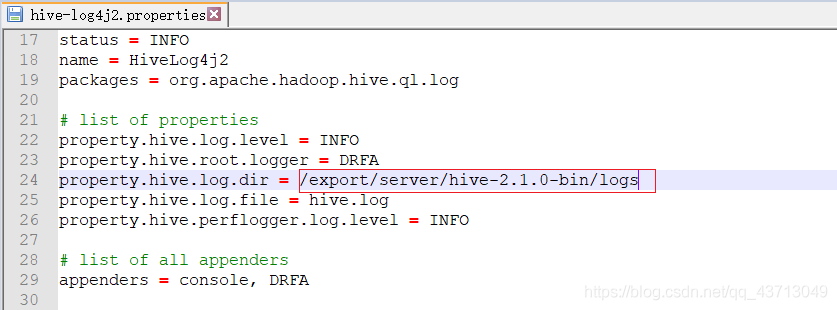
#1.編輯log4j2.properties檔案
vim hive-log4j2.properties
#2.修改第24行
property.hive.log.dir = /export/server/hive-2.1.0-bin/logs
重啟Hive的服務端
九、HQL語法:DDL
1.資料庫庫的管理
查看所有資料庫
show databases;
創建資料庫
create database [if not exists ] dbname [comment] [location]
使用資料庫
use dbname;
洗掉資料庫
drop database [if exists] dbname [cascade];
2.資料庫表的管理
查看所有表
show tables;
show tables in dbname;
創建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(
col1Name col1Type [COMMENT col_comment],
co21Name col2Type [COMMENT col_comment],
co31Name col3Type [COMMENT col_comment],
co41Name col4Type [COMMENT col_comment],
co51Name col5Type [COMMENT col_comment],
……
coN1Name colNType [COMMENT col_comment]
)
[PARTITIONED BY (col_name data_type ...)] --磁區表結構
[CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS] --分桶表結構
[ROW FORMAT row_format] -- 指定資料檔案的分隔符
row format delimited fields terminated by '列的分隔符' -- 列的分隔符,默認為\001
lines terminated by '行的分隔符' --行的分隔符,默認\n
[STORED AS file_format] -- 指定檔案的存盤格式
[LOCATION hdfs_path] -- 用于指定表的目錄所在位置,默認表的目錄在資料庫的目錄下面
創建表的三種方式
方式一:普通方式
功能:一般用于創建一張表加載資料檔案,將檔案構建表結構
例如:創建員工表
#1.創建員工表
create database db_emp;
use db_emp;
create table tb_emp(
empno string,
ename string,
job string,
managerid string,
hiredate string,
salary double,
jiangjin double,
deptno string
) row format delimited fields terminated by '\t';
#2.加載資料
load data local inpath '/export/data/emp.txt' into table tb_emp;
方式二:將Select陳述句的結果保存到一張新表中
create table tb_emp_as as select empno,ename,salary,deptno from tb_emp;
方式三:復制表的結構到一張新表中
create table tb_emp_like like tb_emp;
只復制表結構,不復制資料內容
洗掉表
drop table [if exists] tbname;
查看表
#查看表的結構
desc tbname;
#查看表的元資料
desc formatted tbname;
清空表
truncate tbname;
十、HQL語法:DML
1.加載檔案load
用于將資料檔案關聯到Hive的表中
load data [local] inpath 'filePath' [overwrite] into tbname;
2.插入資料insert
將SQL陳述句的結果保存到一張已存在的表中或者目錄中
#1.格式1
INSERT OVERWRITE|INTO TABLE tablename1
select_statement1 FROM from_statement;
#2.格式2
FROM from_statement
INSERT OVERWRITE|INTO TABLE tablename1 select_statement1 ;
十一、HQL語法:DQL
1.基本查詢
例:查詢每個員工的編號、姓名、薪水及部門編號
select empno,ename,salary,deptno from tb_emp;
2.過濾查詢
例:查詢薪資大于2000的所有員工的姓名及薪水和部門編號
select ename,salary,deptno from tb_emp where salary > 2000;
3.分組查詢
例:查詢每個部門的人數
select deptno,count(*) as numb from tb_emp group by deptno;
4.排序查詢
例:查詢所有部門人數超過3人的部門編號并按照人數降序排序
select deptno,count(*) as numb from tb_emp group by deptno having numb > 3 order by numb desc;
5.關聯查詢
例:查詢所有員工的姓名、部門編號和部門名稱
select
a.ename,
a.deptno,
b.dname
from tb_emp a join tb_dept b on a.deptno = b.deptno;
6.子查詢
例;查詢除SALES部門以外的所有部門的員工資訊
#格式1
select * from tb_emp where deptno not in (select deptno from tb_dept where dname = 'SALES');
#格式2
with t1 as (
select deptno from tb_dept where dname = 'SALES'
)
select * from t1 ;
十二、表的分類
1.管理表
語法
create table ……
特點:Hive中默認的表型別,不手動洗掉,管理表一直存在,洗掉表時,元資料與HDFS映射的表的目錄一起被洗掉
2.臨時表
語法
create temporary table ……
特點:表是臨時存在,如果客戶端一旦斷開,表會自動被洗掉,類似于ZK中的臨時節點,是一種特殊的管理表,這種管理表的生命周期伴隨客戶端的,用于存放臨時資料
3.外部表
語法
create external table ……
特點:在洗掉表時,只洗掉元資料,資料是不會被洗掉,作業中大部分的表都是外部表型別
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282893.html
標籤:其他
上一篇:Hive入門(二)
下一篇:windows下安裝kafka