大小端存盤以及位元組對齊
- 一、大端存盤和小端存盤
- 1. 什么是大端存盤、小端存盤?
- 2. 為什么會有大端存盤、小端存盤?
- 3. 如何判斷是大端存盤還是小端存盤以及如何實作大小端轉換?
- 二、位元組對齊
- 1. 什么是位元組對齊
- 2. 為什么要位元組對齊
- 3. 結構體位元組對齊規則
- 4. 計算結構體的大小實體
- 總結
一、大端存盤和小端存盤
1. 什么是大端存盤、小端存盤?
- 大端存盤(Big endian):資料的低位(低位元組)存盤在記憶體中的高地址,資料的高位(高位元組)存盤在記憶體中的低地址,
即:低位 —> 高地址;高位 —> 低地址 - 小端存盤(Little endian):資料的低位(低位元組)存盤在記憶體中的低地址,資料的高位(高位元組)存盤在記憶體中的高地址,
即:低位 —> 低地址;高位 —> 高地址
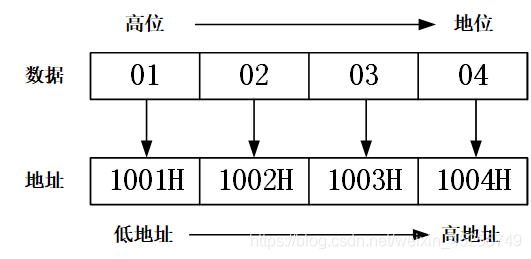
比如:int data = 0x01020304; 此時,變數data最高位是01,最低位是04,假設變數data存盤在計算機的首地址為1001H,
- 在大端存盤模式下,變數data在計算機記憶體地址1001H到1004H中為0x01020304
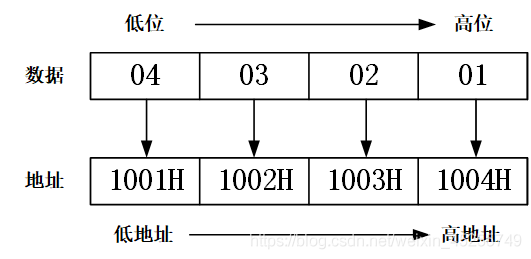
- 在小端存盤模式下,變數data在計算機記憶體地址1001H到1004H中為0x04030201,
2. 為什么會有大端存盤、小端存盤?
??在計算機系統中,規定:每個地址單元都會對應一個位元組,在C語言中,除了有一個位元組的char型別,也有多個位元組的資料型別,對于16位或者32位的處理器,由于暫存器的寬度大于一個位元組,那么就存在如何將一個多位元組變數的資料如何存放的問題——所以,就有了大小端之分,
3. 如何判斷是大端存盤還是小端存盤以及如何實作大小端轉換?
??大端模式還是小端模式主要取決于CPU處理架構,我們常用的x86架構是小端模式,很多的RAM開發板也是小端模式;而在網路編程中使用的網路位元組序指的就是大端模式,往往需要主機位元組序和網路位元組序的相互轉換(如:htons()、ntohs()、htonl()、ntohl()等),以下顯示了用代碼如何判斷大小端存盤以及大小端轉換,
// Test1.c
#include <stdio.h>
// 常規方法判斷大小端
// 強制轉換char*型別,*pData 獲取首地址的存盤內容
void Test01(){
int data = 1;
char *pData = (char *)&data;
if(*pData == 1){ // 首地址存盤內容是01,小端
printf("Little endian\n");
}else if(*pData == 0){ // 首地址存盤內容是00,大端
printf("Big endian\n");
}
}
// 利用聯合體判斷大小端,
// 聯合體中的所有資料成員共用同一塊記憶體(成員變數中最大的記憶體)
void Test02(){
union Endian{
int data;
char item;
};
union Endian check;
check.data = 1;
if(check.item == 1){
printf("Little endian\n");
}else if(check.item == 0){
printf("Big endian\n");
}
}
// int 型別的大小端相互轉換
int Test03(int Val){
int res = 0;
res = ((Val& 0x000000ff) << 24) + \
((Val& 0x0000ff00) << 8) + \
((Val& 0x00ff0000) >> 8) + \
((Val& 0xff000000) >> 24);
return res;
}
int main(){
Test01();
Test02();
printf("%d\n", Test03(1)); // 0x00000001 --> 0x01000000
return 0;
}
二、位元組對齊
1. 什么是位元組對齊
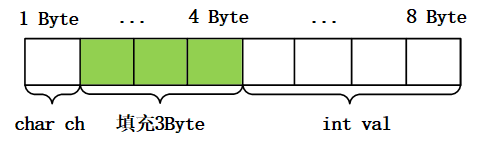
??我們先來看一個結構體,這個結構體一共占用多少位元組?
struct Data{
char ch; // 1 Byte
int val; // 4 Byte
};
printf("sizeof:%d\n", sizeof(struct Data)); // 8
sizeof 列印出這個結構體占用了8個位元組,其中包含5位元組的資料和3位元組的填充,這種情況就是記憶體對齊,它在記憶體中的分布情況如下(ch還是只占用1個位元組,val占用4位元組):
2. 為什么要位元組對齊
??計算機中的記憶體是以一個位元組為單位,但在讀取資料時是一段記憶體一段記憶體讀取,從而在保證位元組對齊時提升資料讀取效率,但也會消耗一部分的空間資源,如:對于上述的Data結構體,假設計算機讀取記憶體是4個位元組讀取,在位元組對齊時在訪問資料val時,只需要一次讀取4位元組;而在非位元組對齊時,需要一次讀取前4個位元組,獲取后3位元組,再一次讀取后4個位元組,獲取前1位元組,最后將3位元組的val資料和1位元組的val資料拼接而成,
3. 結構體位元組對齊規則
- 結構體第一個資料成員存盤在偏移為0的位置,后續每個資料成員存盤在偏移為對齊數的整數倍,
- 對齊數為該資料成員所占位元組數,也可以通過#pragma pack(n)設定編譯器對齊數,通過#pragam pack()關閉,
- 結構體的大小必須是結構體對齊數的整數倍,
- 結構體的對齊數為結構體內部成員中的最大對齊數,
4. 計算結構體的大小實體
// Test2.c
#include <stdio.h>
// #pragma pack(n)
// 對齊數分別為 1, 4, 1; 結構體對齊數為 4;
struct A{
char a; // 0-3 填充3Byte 規則2
int b; // 4-7
char c; // 8-11 填充3Byte 規則3
};
// #pragma pack()
// 對齊數分別為 1, 1, 4; 結構體對齊數為 4;
struct B{
char a; // 0
char c; // 1-3 填充2Byte 規則2
int b; // 4-7
};
// 對齊數分別為 1, 4, 4; 結構體對齊數為 4;
struct C{
char a; // 0-3 填充3Byte 規則2
struct A d; // 4-15
int b; // 16-19
};
// 對齊數分別為 4, 8, 1; 結構體對齊數為 8;
struct D{
int a; // 0-7 填充4Byte 規則2
double b[4];// 8-39
char ch[5]; // 40-47 填充3Byte 規則3
};
int main(){
printf("sizeof(A):%ld\n", sizeof(struct A)); // 12
printf("sizeof(B):%ld\n", sizeof(struct B)); // 8
printf("sizeof(C):%ld\n", sizeof(struct C)); // 20
printf("sizeof(D):%ld\n", sizeof(struct D)); // 48
return 0;
}
// 對于結構體A和B,資料成員型別均相同次序不同,結構體B更節省記憶體空間,
// 因此,定義結構體,將資料成員型別所占位元組數從小到大排列可以減少記憶體空間,
總結
- 大端模式:低位 —> 高地址;高位 —> 低地址
- 小端模式:低位 —> 高地址;高位 —> 低地址
- 位元組對齊是計算機一種空間換時間的方法,在定義結構體時,將資料成員型別所占位元組數從小到大排列,可以減少結構體所占記憶體,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/282921.html
標籤:其他
上一篇:【MBR病毒】實作與解決方案