
考點一:計算機基本組成
在一臺計算機中,主要有6種不見,分別是控制器、運算器、記憶體儲器、外存盤器、輸入輸出設備,他們之間的合作關系如圖所示:
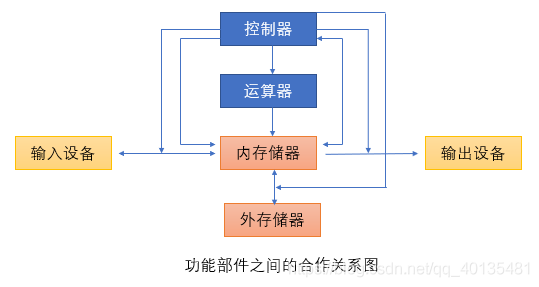
其中控制器和運算器共同構成中央處理器(CPU),CPU主要通過總線和其他設備進行聯系,另外在嵌入式系統設計中,外部設備也常常直接連接到CPU的外部I/O腳的中斷腳上,
(1)運算器
運算器的主要功能是在控制器的控制下完成各種算術運算、邏輯運算和其他操作,
運算器主要包括:算術邏輯單元(ALC)、加法器/累加器、資料緩沖暫存器、程式狀態暫存器四個子部分構成,
- 算術邏輯單元(ALU)主要完成對二進制資料的定點算術運算(加減乘除)、邏輯運算(與或非異或)以及移位操作,
- 累加暫存器(AC)通常簡稱為“累加器”,是一個通用暫存器,其功能是當運算器中的算術邏輯單元(ALU)執行算識訓邏輯運算時為ALU提供一個作業區,用于傳輸和暫存用戶資料,
- 資料緩沖暫存器用來暫時存放由記憶體存盤器讀出的一條指令或一個資料字,反之,當向記憶體存入一條指令或一個資料字時,也暫時將他們存放在資料緩沖暫存器中,緩沖暫存器的作用:

程式狀態暫存器用來存放兩類資訊,一是體現當前指令執行結果的各種狀態資訊,如有無進位(CF位)、有無溢位(OF位)、結果正負(SF位)、結果是否為零(ZF)位和標志位(PF位)等,二是控制資訊,如允許中斷(IF位)和眼蹤標志(TF位)等,
(2)控制器
控制器是有程式計數器(PC)、指令暫存器、指令譯碼器、時序產生器和操作控制器組成,完成整個計算機系統的操作,
程式計數器(PC)是專用奇存器,具有存盤和計數兩種功能,又稱為“指令計數器”,在程式開始執行前將程式的起始地址送入PC,在程式加載到記憶體時依此地址為基礎,因此PC的初始內容為程式第一條指令的地址,執行指令時CPU將自動修改PC的內容,以便使其保持的總是將要執行的下一條指令的地址,由于大多數指令都是按順序執行因此修改的程序通常只是簡單的將PC加1,當遇到轉移指令時后繼指令的地址與前指令的地址加上一個向前或向后轉移的位偏移量得到,或則根據轉移指令給出的直接轉移的地址得到,
指令暫存器存盤當前正在被CPU執行的指令,
指令譯碼器將指令中的操作碼解碼,告訴CPU該做什么,可以說指令暫存器的輸出是指令譯碼器的輸入,
時序產生器用以產生各種時序信號,以保證計算機能夠準確、迅速、有條不紊地作業,
(3)記憶體儲器
又稱記憶體或主存:存盤現場操作的資訊與中間結果,包括機器指令和資料,
(4)外存盤器
又稱為外存或輔助存盤器,在存盤需要長期保存的各種資訊,
(5)輸入設備(Input Devices)
輸入設備用以接收界向計算機輸入的資訊
(6)輸出設備(Output devices)
輸出設備用以將計算機中的資訊向外界輸送,
考點二:流水線與并行處理
流水線技術是通過并行硬體來提高系統性能的常用方法,它其實是一種任務分解的技術,把一件任務分解為若干順序執行的子任務,不同的子任務由不同的執行機構來負責執行,而這些執行機構可以同時并行作業,
在流水線這個知識點,主要考查流水線的概念、性能,以及有關引數的計算
(1)流水線執行計算
假定有某種型別的任務,共可分成n個子任務,每個子任務需要時間t,則完成該任務所需的時間即為nXt,若以傳統的方式,則完成k個任務所需的時間是knt;而使用流水線技術執行,則花費的時間是(n+k-1)×t,也就是說,除了第一個任務需要完整的時間外,其他都通過并行,節省下了大量的時間,只需一個子任務的單位時間就夠了另外要注意的是,如果每個子任務所需的時間不同,則其速度取決于其執行順序中最慢的那個(也就是流水線周期值等于最慢的那個指令周期),要根據實際情況進行調整,
例如:若指令流水線把一條指令分為取指、分析和執行三部分,且三部分的時間分別是取指2ns,分析2ns,執行1ns,那么,最長的是2ns,因此100條指令全部執行完畢需要的時間就是:(2+2+1)+(100-1),×2=203ns,
另外,還應該掌握幾個關鍵的術語:流水線的吞吐率、加速比,流水線的吞吐率( Though Put Rate,TP)是指在單位時間內流水線所完成的任務數量或輸出的結果數量,
完成同樣一批任務,不使用流水線所用的時間與使用流水線所用的時間之比稱為流水線的加速比( Speed-up Ratio)
例如,在上述例子中,203ns的時間內完成了100條指令,則從指令的角度來看,該流水線的吞吐率為:(100×10°)/203-=4.93×105s(1s=10°ns),加速比為500/203=2.46(如果不采用流水線,則執行100條指令需要500s)
(2)影響流水線的主要因素
流水線的關鍵在于“重疊執行”,因此如果這個條件不能夠滿足,流水線就會被破壞,這種破壞主要來自3種情況,
①轉移指令
因為前面的轉移指令還沒有完成,流水線無法確定下一條指令的地址,因此也就無法向流水線中添加這條指令,從這里的分析可以看出,無條件跳轉指令是不會影響流水線的,
①共享資源訪間的沖突
它也就是后一條指令需要使用的資料,與前一條指令發生的沖突,或者相鄰的指令線的使用了相同的暫存器,這也會使流水線失敗,為了避免沖突,就需要把相互有關的指令進行阻塞,這樣就會引起流水線效率的下降,一般地,指令流水線級數越多,越容易導當然,也可以在編譯系統上進行設定,當發現相鄰的陳述句存在資源共享沖突的時候,致資料相關,阻塞流水線,
在兩者之間插入其他陳述句,將兩條指令進入流水線的時間拉開,以避免錯誤,
③回應中斷
當有中斷請求時,流水線也會停止,流水線回應中斷有兩種方式,一種是立即停止
現有的流水線,稱為精確斷點法,這種方法能夠立即回應中斷,縮短了中斷回應時間,但是增加了中央處理器的硬體復雜度,
還有一種是在中斷時,在流水線內的指令繼續執行,停止流水線的入回,當所有流水線內的指令全部執行后,再執行中斷處理程式,這種方式中斷回應時間較長,這種方式稱為不精確斷點法,優點是實作控制簡單,
【考點3】資料碼制的表示
本節主要掌握原碼、反碼、補碼和移碼的概念,以及各自的用途和優點個
(1)原碼
將最高位用作符號位(0表示正數,1表示負數),其余各位代表數值本身的絕對值的表示形式,這種方式是最容易理解的,例如,假設用8位表示1個數,則+11的原碼用二進制表示是00001011,-11的原碼用二進制表示是100,1011.
直接使用原碼在計算時會有麻煩,例如,在十進制中1+(-1)=0,如果直接使用二進制原碼來執行“1+(-1)”的操作,則運算式為:00000001+100000001=10000010.
這樣計算的結果是-2,也就是說,使用原碼直接參與計算可能會出現錯誤的結果,所以,原碼的符號位不能直接參與計算,必須和其他位分開,這樣會增加硬體的開銷和復雜性,
(2)反碼
正數的反碼與原碼相同,負數的反碼符號位為1,其余各位為該數絕對值的原碼按位取反,例如,-11的反碼為110100片關
同樣,對于“1+(-1)”加法,使用反碼的結果是:00000001+11111110=11111111
這樣的結果是負0,而在人們普遍的觀念中,0是不分正負的,反碼的符號位可以直接參與計算,而且減法也可以轉換為加法計算.
(3)補碼
正數的補碼與原碼相同,負數的補碼是該數的反碼加1,這個加1就是“補”,例如11的補碼為11110100+1=11110101,
對于“1+(-1)”的加法,是這樣的:00000001+11111111=00000000這說明,直接使用補碼進行計算的結果是正確的,
對一個補碼表示的數,要計算其原碼,只要對它再次求補即可,由于補碼能使符號位與有效值部分一起參加運算,從而簡化了運算規則,同時它也使減法運算轉換為加法運算,進一步簡化計算機中運算器的電路,這使得在大部分計算機系統中,資料都使用補碼表示,
(4)移碼
移碼又稱為增碼,移碼的符號表示和補碼相反,1表示正數,0表示負數,也就是說,移碼是在補碼的基礎上把首位取反得到的,這樣使得移碼非常適合于階碼的運算,所以移碼常用于表示階碼,
通過四種碼制的學習,我們已經學會了它們相互之間的轉換,
【考點4】主存盤器
3.存盤體系和尋址方式
在存盤體系和尋址方式方面,涉及的考點有主存盤器(重點)、高速快取(重點)、尋址方式面
(1)主存盤器的種類,
①RAM:隨機存盤器,可讀寫,斷電后資料無法保存,只能暫存資料,
②SRAM:靜態隨機存盤器,在不斷電時資訊能夠一直保持,
③DRAM:動態隨機存盤器,需要定時重繪以維持資訊不丟失,
④ROM:只讀存盤器,出廠前用掩膜技術寫入,常用于存放BIOS和微程式控制,
⑤PROM:可編程ROM,只能夠一次寫入,需用特殊電子設備進行寫入多次,
⑥ EPROM:可擦除的PROM,用紫外線照射15~20分鐘可擦去所有資訊,可寫入多次,
⑦E2PROM:電可擦除 EPROM,可以寫入,但速度慢,
閃速存盤器
抓住幾個關鍵英文字母,A,Access,說明讀寫都行,O,Only,說明只讀,P,Programmable,說明可以通過特殊電子設備寫入;E,Erasable,說明可以擦寫;E,第二個E指電子,
(2)主存盤器的組成
實際的存盤器總是由一片或多片存盤器配以控制電路構成的,其容量為W×B,W是存盤單元(word,即字)的數量,B表示每個word由多少bit(位)組成,如果某芯片規格為w×b,則組成WXB的存盤器需要用(W/w)×(B/b)個芯片,
(3)主存盤器的地址編碼,
主存盤器(記憶體)采用的是隨機存取方式,需對每個資料塊進行編碼,而在主存盤器中,資料塊是以word為單位來標識的,即每個字一個地址,通常采用的是十六進制表示
例如,按位元組編址,地址從A4000H~ CBFFFH,則表示有( CBFFF--A4000+1)個位元組,即28000H個位元組,也就是163840個位元組,等于160KB,
要注意的是,編址的基礎可以是位元組,也可以是字(字是由1個或多個位元組組成如,上述記憶體的容量為160KB,則需要18位地址來表示(2^27=131072,2^18=262144)
在記憶體這個知識點的另外一個問題,就是求存盤芯片的組成問題,實際的存盤器總是由一片或多片存盤器配以控制電路構成的,設其容量為W×B,W是存盤單元的數量B表示每個單元由多少位組成,如果某一芯片規格為w×b,則組成W×B的存盤器需要用(Ww)×(B/b)塊芯片,例如,上述例子中的存盤器容量為160KB,若用存盤容量為32Kx8bit的存盤芯片構成,因為1B=8b(一個位元組由8位組成),則至少需要(160K32K)×(1B8b)=5塊,
【考點5】高速快取
Cache的功能是提高CPU資料輸入輸出的速率,突破所謂的“馮諾依曼瓶頸”,即CpU與存盤系筑間資料傳送帶寬限制,高速存盤器能以極高的速率進行資料的訪問,但因其價格高昂,如果計算機的記憶體完全由這種高速存盤器組成,則會大大增加計算機的成本,通常在CPU和記憶體之間設定小容量的高速存盤器 Cache, Cache容量小但速度快,記憶體速度較低但容量大,通過優化調度演算法,系統的性能會大大改善,其存盤系統容量與記憶體相當而訪問速度近似 Cache,
(1) Cache原理、命中率、失效率
使用Cahe改善系統性能的主要依據是程式的區域性原理通俗地說,就是一段時間內,執行的陳述句常集中于某個區域,而 Cache正是通過將訪問集中的內容放在速度更快的 Cache上來提高性能的,引入 Cache后,CPU在需要資料時,先找 Cache,沒找到再到記憶體中找,
如果 Cache的訪問命中率為h(通常1-h就是 Cache的失效率),而 Cache的訪問周期時間是t1,主存盤器的訪問周期時間是t2,則整個系統的平均訪存時間就應該是t3=hXtl+(1-h)×t2
從公式可以看出,系統的平均訪存時間與命中率有很密切的關系,靈活地應用這個公式,可以計算出所有情況下的平均訪存時間,
例如:假設某流水線計算機主存的讀/寫時間為10m,有一個指令和資料合一的Cache,已知該 Cache的讀/寫時間為10ns,取指令的命中率為98%,取資料的命中率為95%,在執行某類程式時,約有15指令需要存取一個運算元,假設指令流水線在任何時候都不阻塞,則設定 Cache后,每條指令的平均訪存時間約為多少?其實這是應用公式的一道簡單數學題:
(29%×1008+98%×1ms)15×(5%6×10o5+95%×10ns)=14.7ns
2) Cache存盤器的映射機制
分配給 Cache的地址存放在一個相聯存盤器(CAM)中,CPU發生訪存請求時會先讓會先讓CAM判斷所要訪問的字的地址是否在 Cache中,如果命中就直接使用,
這個判斷的程序就是 Cache地址映射,這個速度應該盡可能快,常見的映射方法有直接映射、全相聯映射和組相聯映射三種,
①直接映射:是一種多對一的映射關系,但一個主存塊只能夠拷貝到 Cache的個特定位置上去, Cache的行號i和主存的塊號j有函式關系:i=j%m(其中m為 Cache總行數),
例如,某 Cache容量為16KB(即可用14位表示),每行的大小為16B(即可用4位表示),則說明其可分為1024行(可用10位表示),主存地址的最低4位為 Cache的行內地址,中間10位為 Cache行號,如果記憶體地址為1234E8F8H的話,那么最后4位就是1000對應十六進制數的最后一位),而中間10位,則應從E8F(111010001111)中獲取,得到1010001111,
②全相聯映射:將主存中一個塊的地址與塊的內容一起存于 Cache的行中,任一主存塊能映射到 Cache中任意行(主存塊的容量等于 Cache行容量),速度更快,但控制復雜,
③組相聯映射:是前兩種方式的折中方案,它將 Cache中的塊再分成組,然后通過直接映射方式決定組號,再通過全相聯映射的方式決定 ache中的塊號,
注意:在 Cache映射中,主存和 Cache存盤器均分成容量相同的塊,
個例如,容量為64塊的 Cache采用組相聯方式映射,字塊大小為128個字,每4塊為一組,若主存容量為4096塊,且以字編址,那么主存地址應該為多少位?主存區號為多少位?這樣的題目,首先根據主存塊與 Cache塊的容量需一致,得出記憶體塊也是128個字,因此共有128×4096個字,即2^19(2^7×2^12)個字,因此需19位主存地址;而記憶體需要分為4096/64塊,即26,因此主存區號需6位,
(3) Cache淘汰演算法,
當Cache資料已滿,并且出現未命中情況時,就要淘汰一些老的資料,更新一些新的資料,選擇淘汰什么資料的方法就是淘汰演算法常見的方法有三種:隨機淘汰,先進先出(FIFO)淘汰(即淘汰最早調入Cache的資料),最近最少使用(LRU)淘汰法,其中平均命中率最高的是LRU演算法,
(4)Cache存盤器的寫操作
在使用Cache時沒需要保證其資料與主存一致,因此在寫Cache時就需要考慮與主存間的同步問題,通常使用一下三種方法:寫直達(寫Cache時,同時寫主存)、寫回(寫Cache時不馬上寫主存,而是等起淘汰時回寫)、標記法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283089.html
標籤:其他
上一篇:如何將idea代碼提交到遠程倉庫
下一篇:離散數學小筆記